






Qwen2.5新春模型三连发,分别发布了Qwen2.5-1M长上下文模型,Qwen2.5-VL视觉模型以及Qwen2.5-Max旗舰款模型。让我们分别展开讲解。
-
Qwen2.5-1M
-
指标评测
-
首先是Qwen2.5-1M,发布了7B和14B版本。在上下文长度为100万 Tokens 的大海捞针(Passkey Retrieval)任务中,Qwen2.5-1M 系列模型能够准确地从 1M 长度的文档中检索出隐藏信息,其中仅有7B模型出现了少量错误。顺带一提Qwen-Turbo的API也支持到了1M上下文。
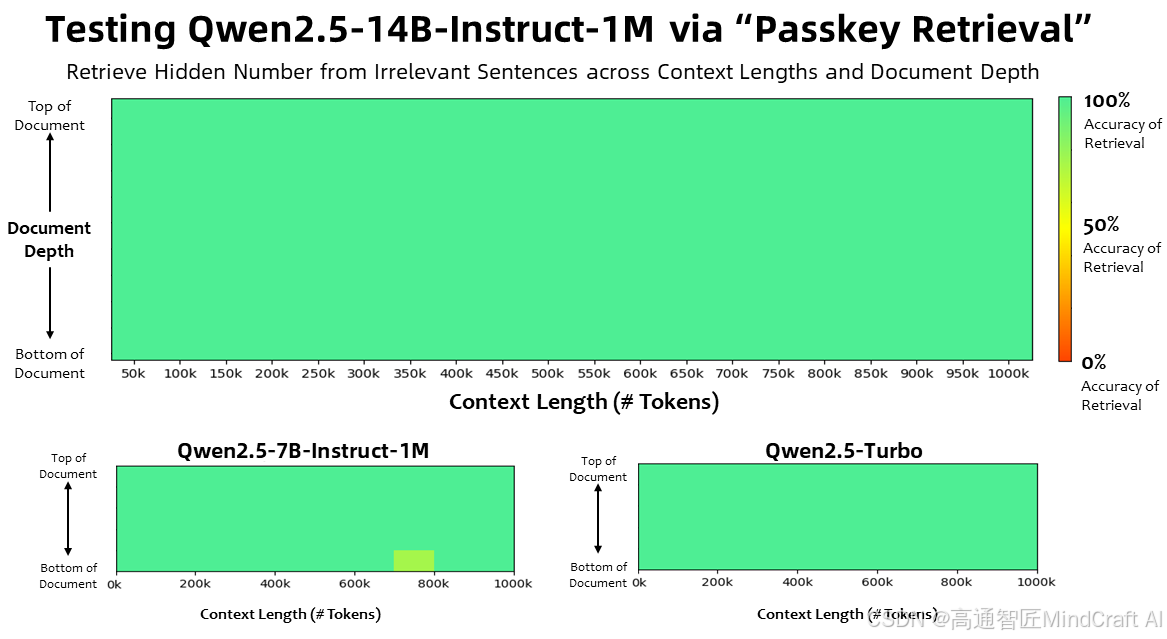
对于更复杂的长上下文理解任务,他们选择了RULER、LV-Eval 和 LongbenchChat这些指标。在这些指标对比中,qwen2.5-1M是占有优势的,但是他们选择的对比对象并不是长上下文能力最强的模型。
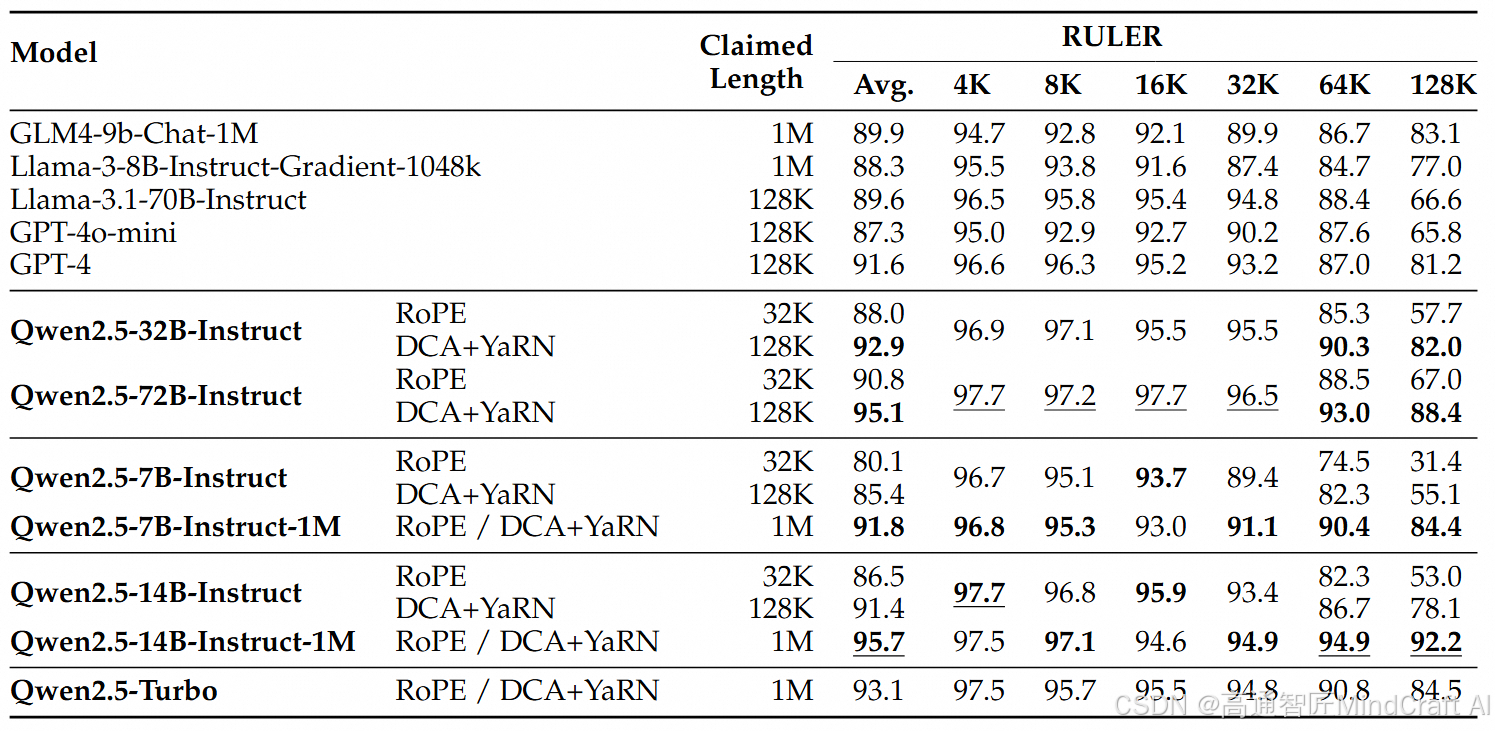
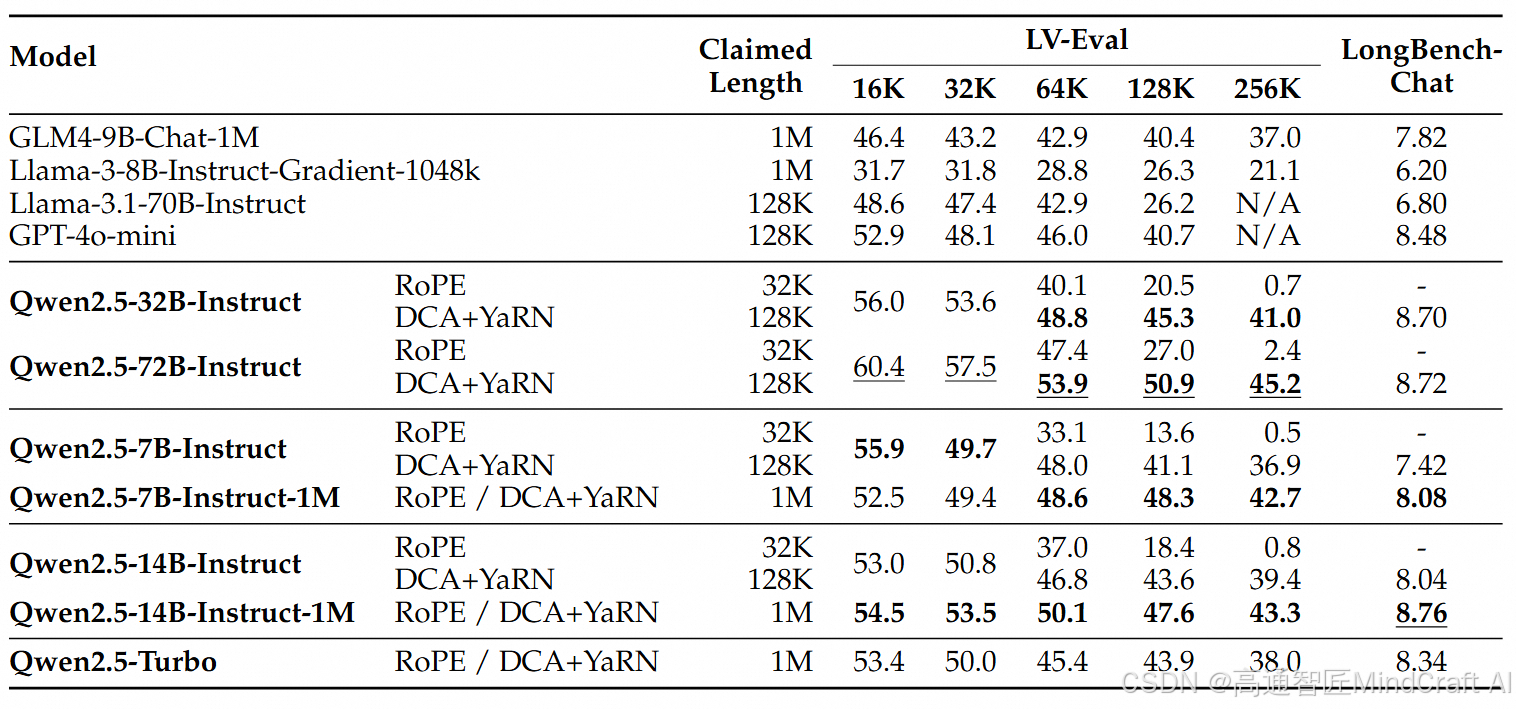
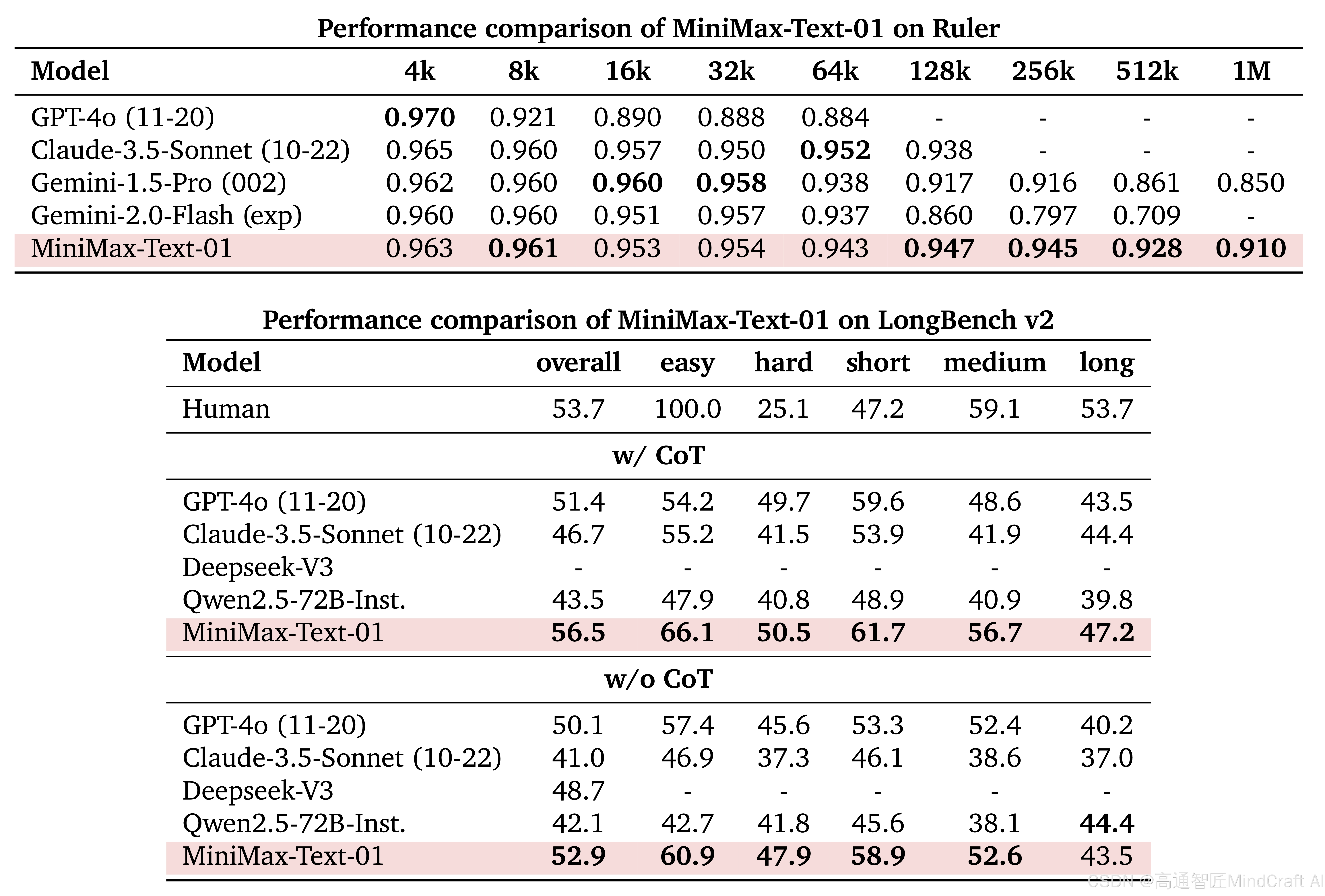
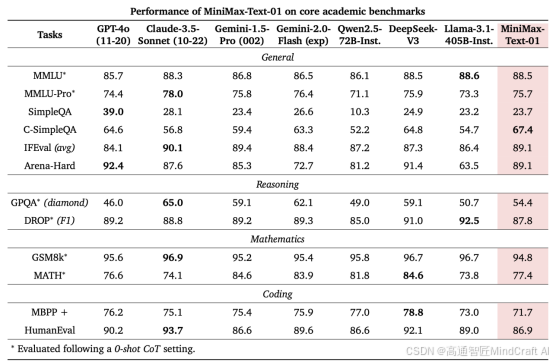
在之前minimax-text-01的评测中,我们得知目前minimax-text-01的长文本能力是最强的,gemini-1.5-pro和claude-3.5-sonnet的ruler测试都比较好。我们可以看到qwen2.5-14B-instruct-1M的水准大概是gemini-1.5-pro和claude-3.5-sonnet水准比gpt4o要强,最强的仍然是minimax-text-01。
-
计费
这里我们只录入Qwen2.5-14B-Instruct-1M,7B版本和Qwen2.5-Turbo性能差不多,而Qwen2.5-Turbo还便宜点。
Qwen2.5-14B-Instruct-1M:最大上下文1M,输入价格1元/百万tokens,输出价格3元/百万tokens。
Qwen2.5-Turbo:最大上下文1M,输入价格0.3元/百万tokens,输出价格0.6元/百万tokens。
性能虽然不如MiniMax-Text-01,但是价格确实便宜,是可以作为一个有效选择。
-
Qwen2.5-VL
-
指标评测
-
Qwen2.5-VL是Qwen家族最新的旗舰款视觉模型。这个版本主要有以下两个特点:
- 理解长视频和捕捉事件:Qwen2.5-VL 能够理解超过 1 小时的视频,并且这次它具备了通过精准定位相关视频片段来捕捉事件的新能力。
- 视觉定位:Qwen2.5-VL 可以通过生成 bounding boxes 或者 points 来准确定位图像中的物体,并能够为坐标和属性提供稳定的 JSON 输出。
这次发布了72B,7B和3B版本。72B是旗舰款的模型,7B和3B更加倾向于小模型本地部署的应用,其中7B可以达到gpt4o-mini的效果,3B在同参数级别的模型中比较有优势。由于现在视觉模型都很便宜了,对于API用户我们可能主要看72B这个模型。
这里列举了最先进的视觉模型进行对比。之前我们评测最好的视觉模型是doubao-1.5-vision-pro-32k和gemini-2.0-flash。我们在这个评测表中看到,在大学级别问题(College-level Problems)中,表现一般但处于同等级,其他都有一定优势,尤其是在文档和图表阅读(Document and Diagrams Reading),优势比较大。另外在视频理解(Video Understanding)和视觉智能体(Visual Agent)评测中,与SOTA模型有比较大的优势。
这样看来似乎确实比国外的视觉模型强了,这个也见怪不怪了现在,不过我们还没跟之前登顶的doubao1.5视觉模型比。如果跟doubao1.5的视觉模型比,大学问题doubao1.5大幅领先,数学推理方面MathVista和MathVison指标有重叠,doubao1.5也是强不少,通用视觉问答的评分在伯仲之间,文档与图表阅读doubao1.5略强,但是Qwen2.5-VL似乎在OCR方面下了大功夫,还支持多国语言。视频理解重叠的指标较少,在有限指标内doubao1.5略强。视觉智能体的评测,doubao1.5没做,空间与计数qwen2.5-vl没做。从有限的指标对比来看,通用功能可能还是doubao1.5的视觉模型略强,但是Qwen2.5-VL在一些指标方面很突出。现在感觉都没国外模型什么事了,都在内卷啊。
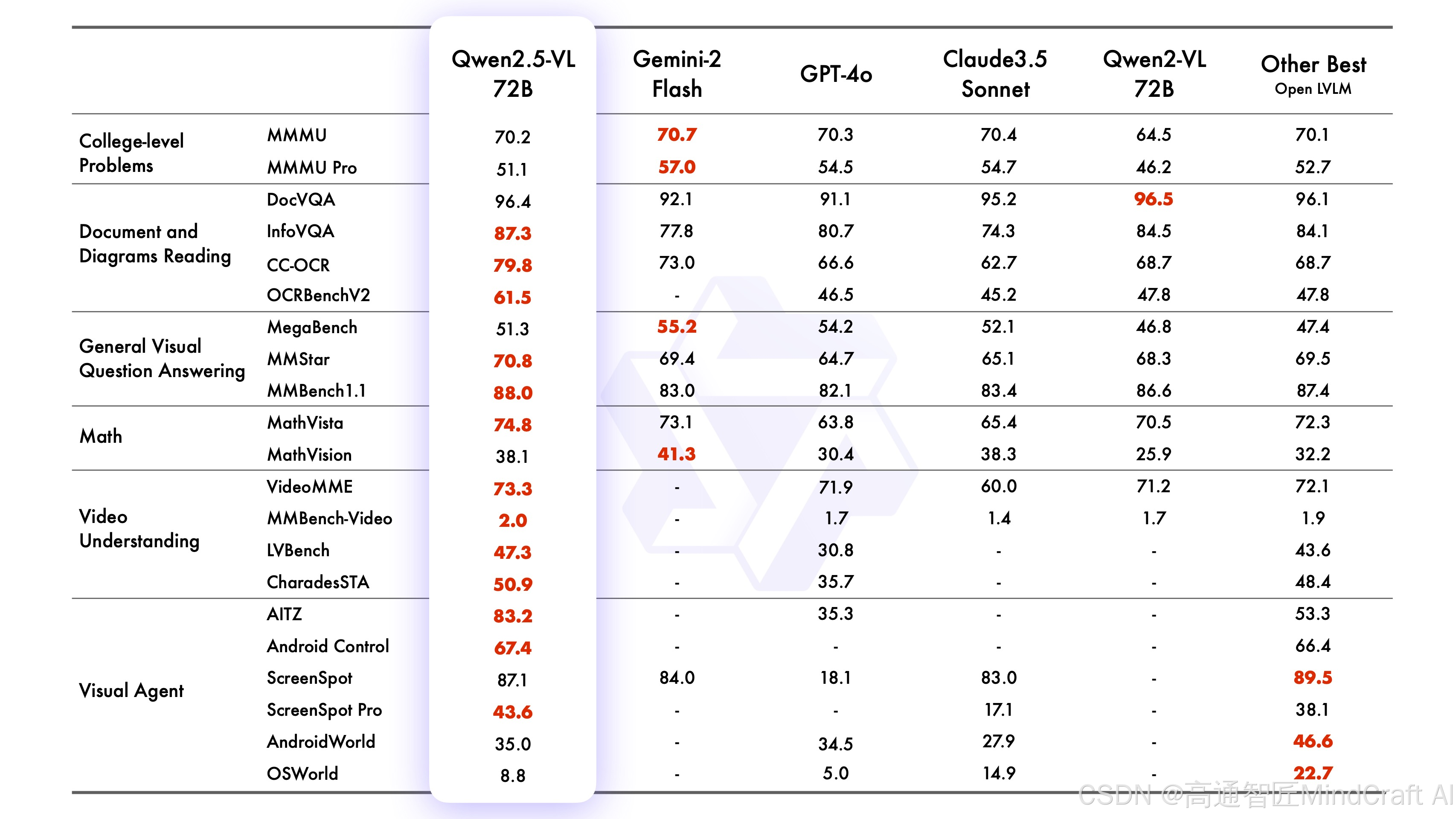
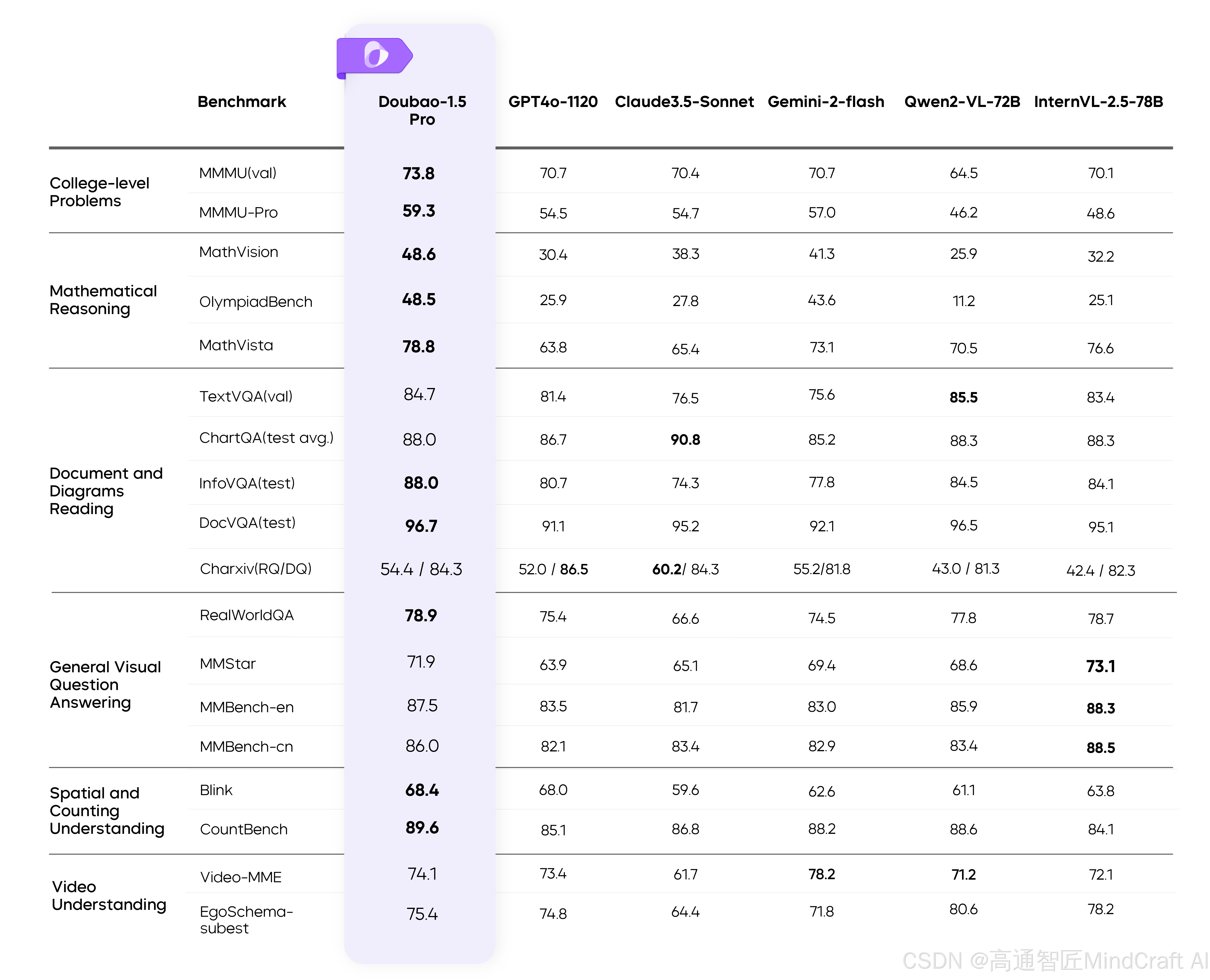
但在上下文方面,Qwen2.5-VL-72B还是有优势的,拥有128K的上下文,更适合做视频解读。
另外在标注坐标的任务中,国内似乎只有Qwen2.5-VL可以做,我试了下doubao1.5和minimax-text-01得出来的答案都不对。但是国外模型可以。

-
计费
Qwen2.5-VL-72B,最大上下文达到128K,可以读一个小时的视频。输入价格16元/百万tokens,输出价格48元/百万tokens。目前看来是偏贵的,但是能平替国外模型。在需要长视频理解或者坐标标注,视觉智能体的场景下,此模型有独特的优势空间。如果是一些通用场景,目前看来似乎不如doubao1.5pro划算。
-
Qwen2.5-Max
-
指标评测
-
接下来是Qwen2.5-Max,这个是通义千问旗舰款模型,API上对应的型号是Qwen-Max。我们先看官方的指标,这里对比了最优秀的模型,包括近期大火的DeepSeek V3,在MMLU-Pro和GPQA-Diamond这种复杂知识型指标上,略差于claude3.5-sonnet,livecodebench这种编程评测指标上优于国外模型。后面又列举了一些指标,所有都是优于DeepSeek V3。模型性能上还是比较顶级的,但我感觉评测有些针对性,一般其他评测会将指标分类来展示模型不同层面的能力,但这里感觉有点盯着某些特定指标展示。
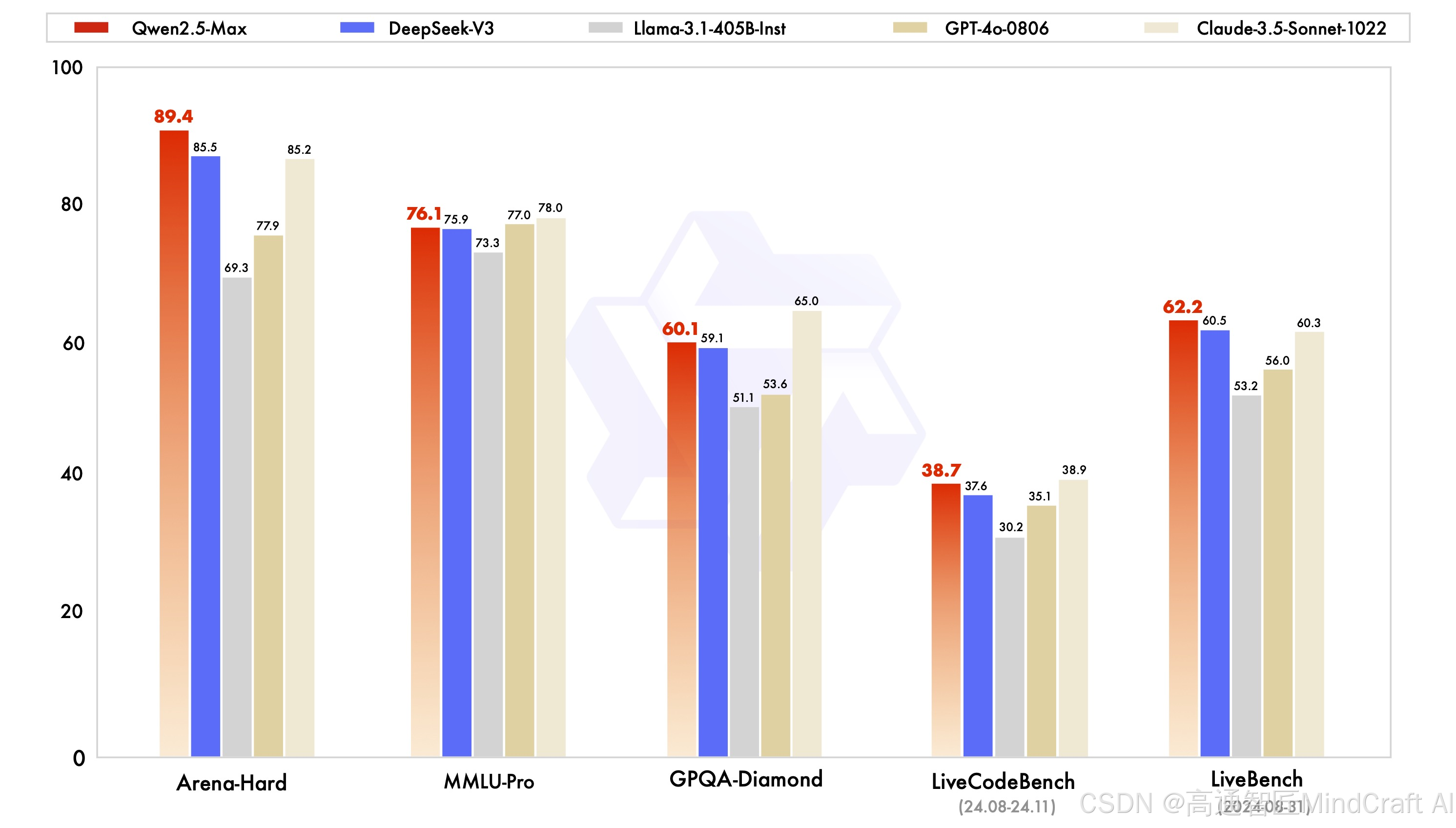
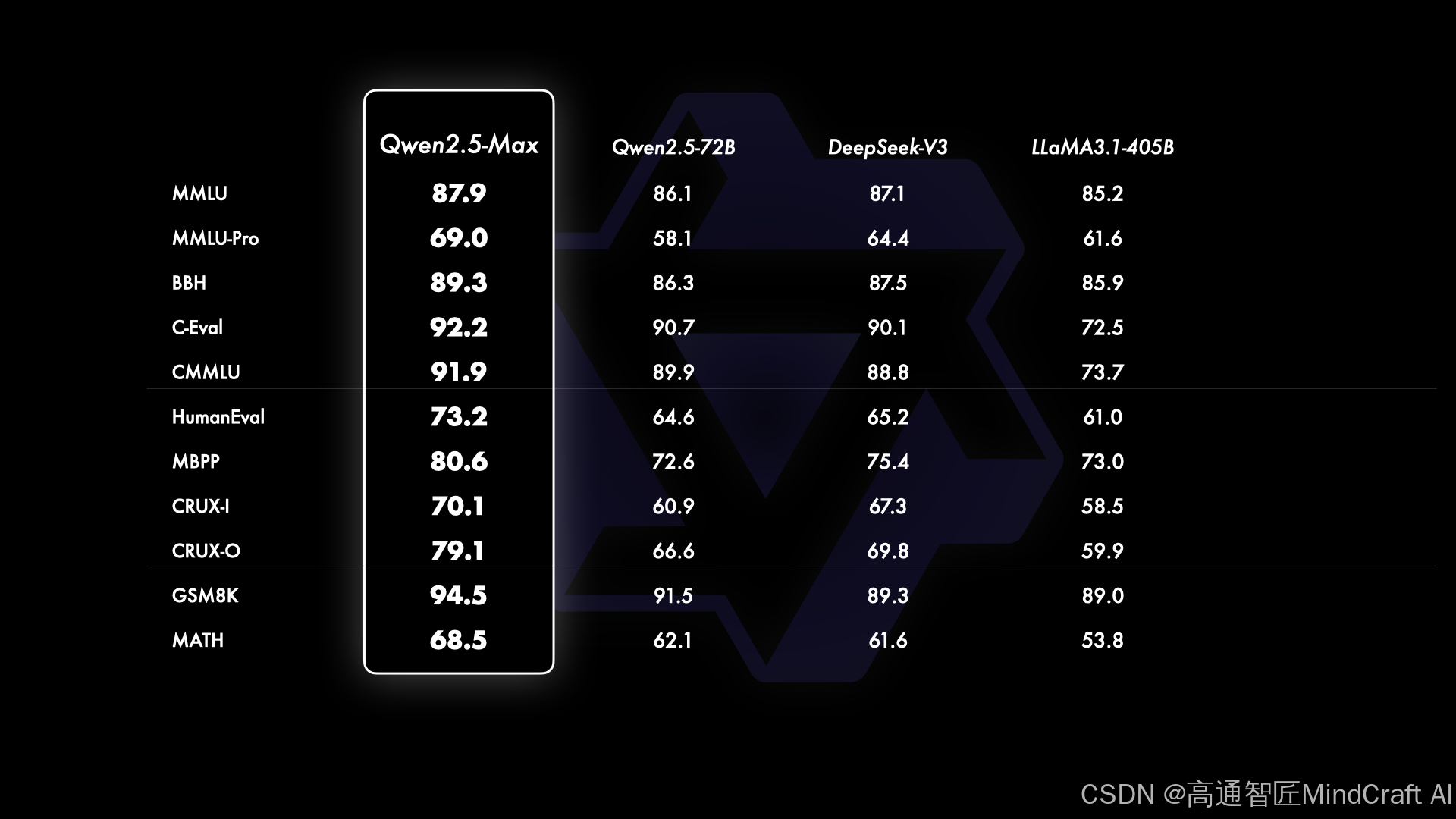
好,看完官方对比,我们再来看与doubao1.5pro的对比,在知识型指标上,doubao1.5pro是有明显优势的,中文能力竟然优于doubao1.5,其他指标就有点乱了。如果你跟豆包和minimax的评测指标去比,发现很多数据对不上的地方,比如说arenahard最强的是gpt4o-1120,但这里拿了gpt4o-0806对比,MATH和humaneval的数值有问题,反正各种对不上。doubao1.5pro和minimax的数值也有点误差,不过误差不大,也不知道这个评测指标是不是还有不同的标准,我是看不明白了,有没有更专业的来解释一下。
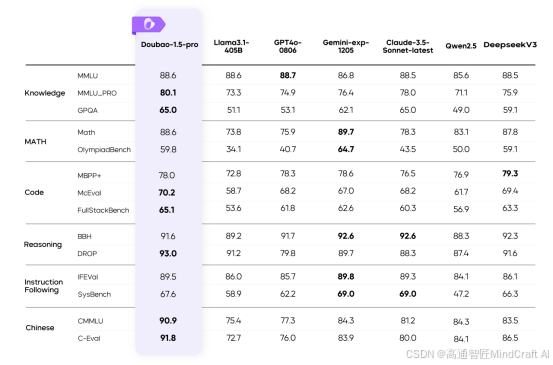
-
计费
Qwen2.5Max,最大上下文32K,输入2.4元/百万tokens,输出9.6元/百万tokens。价格基本对标涨价后的deepseek v3,性价比还行,但不是最好的,要知道doubao1.5pro的API价格仍然维持1元/百万tokens。
-
综评
- Qwen2.5-1M长文本能力不如MiniMax-text-01,但模型更小,价格更便宜
- Qwen2.5-VL-72B领先一众国外模型,与doubao1.5视觉模型互有优劣,价格略高
- Qwen2.5-Max评测指标上全面领先deepseek v3,指标评测存在不确定性,性价比不是最优
- 在高通智匠(MindCraft AI)上可以使用最新的Qwen2.5模型和API.


















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









