






作为开发人员,我们经常会陷入两难的局面:我们既希望在应用中使用闪亮的新工具或代码库,又忌惮在部署到生产环境之后可能出现的未知问题。毕竟,没有人希望自己的手机老是在半夜叮咚作响,更不用说来自为了保持应用能够以多少个9高可用性运行的压力了。这往往塑造了开发人员在应用构建和编程时具有创新精神,却在运营场景中过于保守的状况。

其中,一种最为典型的现象便是—“过度配置(overprovisioning)”,即:在云计算环境中,为应用的部署配备了过多的算力(通常是CPU和RAM),以确保应用拥有足够的资源,来启动或应对运行过程中出现的峰值。显然,既然是过度,我们就需要设法降低此类过度配置的需求,从而节省大量且宝贵的云服务资源的支出。下面,我将和您一起探讨在Java应用的环境中如何避免过度的配置。
应用负载从来都不稳定
正如大多数开发和DevOps人员切实感受的那样,在一天或一周之内,应用的流量负载随着时间的推移,从来就是不均匀的。在闲时,应用无需为不多的用户请求提供服务或处理数据,而在大量用户频繁对应用产生高利用率时,应用实例会在如下情况下,无法被及时推送给应用,进而出现不稳定的峰值:
- 响应延迟时间过长,无法满足服务级别协议(SLA)。
- 内存的过度使用,导致Java虚拟机(JVM)中的垃圾回收器(Garbage Collector,GC)出现抖动。
- 缺少CPU线程、网络或文件句柄等资源,导致传入的请求被拒绝,更不会被予以处理。
其中,后两个问题会导致应用出现毫无响应的状态,因此在测试过程中,开发人员很容易注意到应用的负载上限,以及时扩展所需要的CPU内核和内存数量。而为了避免再次出现峰值,他们通常会趋向于过度添加CPU和内存的数量,以求安全稳定地满足用户需求。例如,开发团队往往会配置比已发现的峰值高出5%到50%的额外云计算余量。
但是,过度的预配置也会增加应用在运行过程中的大量成本。毕竟对于正在运行的云虚拟机而言,固有的CPU(核心或虚拟CPU)和内存,通常并不会自我弹性调整。这就意味着无论应用是否会完全使用到已配置的容量与算力,您都需要为此付费。
为此,我们需要使用合适的策略,来管控过度的预配,以节省不必要的云计算支出。下面,我将向您介绍“垂直扩展(Vertical Scaling)”和“水平扩展(Horizontal Scaling)”这两种扩展模型,以及每种模型的具体策略。而且此类策略和技术既可以适用于跑在云端的应用,也能够适合本地运行的环境。
垂直扩展
垂直扩展旨在让应用通过简单的策略扩展,以处理更多的负载请求。不过它不如后面讲到的水平扩展那么灵活。垂直扩展意味着向物理或虚拟服务器上的应用,添加更多的CPU内核和更多的内存(如果应用属于I/O密集型,则需要添加更多、更快的SSD存储)。当然,此类扩展往往需要停止并重启应用。而有时候这对于应用来说是不可接受的。
水平扩展
多年来,弹性计算(Elastic Compute)一直被奉为可扩展应用开发的“圣杯”。而水平扩展是弹性计算的基础。水平扩展意味着通过添加更多的服务器(各自具有一套完备的CPU和内存)来增加应用的承载能力,而不是向现有服务器添加更多的CPU内核和内存。
不过,与垂直扩展相比,水平扩展更为复杂,需要更多的规划和更多的外部(对应用而言)设置。而且,由于必须引入路由层,这就意味着会产生更多的处理和网络开销,因此其效率不如垂直扩展。
在针对Java应用的水平扩展部署中,我们可以通过自动检测负载,和启停应用节点实例的方式,按需增减资源,进而避免过度的配置。而且,就算在较短的时间内,出现了被过度预置的资源,其数量也会很少(主要取决于您的配置方式)。
更好的负载测试和估计
性能测试通常被认为是一种最困难的测试类型。它需要开发团队对整个应用及其所有连接的服务,具有深入的了解。他们往往需要通过全面思考和反复调整,才能正确地生成模拟生产环境的负载、以及应用数据。显然,为了与生产环境的特征保持同步,测试环境的性能设置是一项劳动密集型工作。
就Java应用而言,开发人员经常会在确定应用峰值性能要求时,通过执行三项操作,来实现更加贴近真实情况的配置调整:
1. 测量服务器和JVM的CPU和内存的利用率
通常,开发人员需要查看服务器(或虚拟机)的CPU与内存的利用率,以确定二者为处理峰值负载所需的数字。其中,在JVM中,他们可以使用工具去监控如下两项指标,以设置正确的级别:
- JVM GC监控:它有助于检测那些由于内存太少所导致的、在JVM进入GC场景时CPU的使用率过高的情况。同时,它也有助于检测被分配了过多内存的位置。这些位置因引发GC的暂停时间过长,从而导致延迟时间明显长于预期。对此,减少不需要的内存可以节省此方面的开销。
- JVM线程监控:它有助于检测何时出现由于CPU不足而导致的响应时间过长或无响应的情况。同时,它也有助于检测那些过多的空闲线程,并能通过减少分配的内核数量,以节省开销。
2. 新的JVM版本比旧版本提供更好的性能
在从JDK 11到17,再到21的测试中,我们发现每个JVM版本的CPU使用率都有所提升。与之相对的应用代码则可能需要稍作调整,特别是当您的应用原先基于早于Java 11的版本时。
同时,不同的GC算法也能提升云端VM的效率,虽然这在很大程度上取决于应用的内存利用率。例如,那些执行大数据处理与转换的应用,会具有与RESTful应用不同的GC配置文件。
3. 了解JVM的工作原理
下图显示了一个典型Java应用,从JVM的启动到它是如何随时间推移而执行的过程。在启动时,由于需要启动JVM、加载各种类,所以其CPU的使用率较高。之后,该应用框架(如,Spring Boot)相继进入启动、初始化并达到“准备处理请求”的状态。
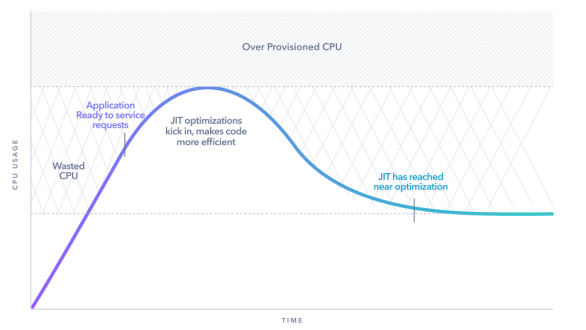
请注意图中峰值上方一行的区域。该区域显示了有多少颗CPU被过度预配置给了该应用的VM部署,以应对突发性高负载。随着JVM的实时(just-in-time,JIT)编译器优化代码的生效,该应用的性能会逐渐提高。也就是说,它能够使用更少的CPU来处理相同数量的负载。最终,在JIT编译器的优化效果下,JVM达到了较低的CPU利用率基准。那么,为应用保留下来的富余资源,就浪费了您为其分配的CPU。显然,这些资金本来是有机会可以被节省的。
鉴于使用高性能JVM可以让您减少(或完全消除)过度配置的可能性,我们有必要通过了解此曲线及其对应用的影响,来减少分配给应用VM实例的资源。也就是说,一旦知晓了长尾峰值的所在位置,我们就可以降低其顶线(即“过度配置”),以便分配更少的CPU内核,并节省云计算的租用成本。
减小应用的体积
我们的应用架构随着从单体模式转为微服务(甚至更小的云服务功能),应用的体积规模也变得越来越小。虽然这些不同的架构各有利弊,但在云服务成本优化的背景下,使用水平扩展来达到弹性计算的缩减无疑是最好的实现方式。
应用体积的缩减,也能够减少需要分配给应用每个实例的CPU和内存的数量。而且,这种增量扩展方式不但实现了更高效的资源使用,也反过来达到了对云计算成本更精细化的控制效果。可以说,部署的单元越小,在纵向扩展时所支付的费用就越少。当然,这里主要讨论的是自动化的扩展方式。
使用自动化扩展
说到自动化扩展,它是一种根据应用负载的增加或减少,自动化地增减应用实例节点的能力。通过云服务成本的优化,我们可以根据所构建的应用群集环境的不同,采用不同的自动化扩展选项。目前,最流行的自动化扩展平台当属Kubernetes。当然,它也给标准的固定分布式集群(fixed-distributed-cluster)部署带来了不小的复杂性。
比Kubernetes更为简单的替代方案是容器即服务(CaaS),例如AWS的Fargate、Google的Cloud Run、以及Microsoft的Azure 容器。这些部署服务提供了一些更加简单的应用部署方法,并通过将Docker容器中的应用提供给服务,来自动处理向上和向下扩缩容。CaaS解决方案的缺点在于,它们的成本会高于标准的VM,并且可能会比托管式的Kubernetes部署的成本还要高。
结论
总的说来,减少过度配置可以帮助我们节省应用在云服务中的成本开销。无论您使用上述哪种策略来减少过度配置,了解Java应用的CPU和内存配置文件,无疑将有助于您掌握应用在启动和运行时的性能状况。目前,有一种Azul Platform Prime不但可以为大中型Java应用部署提供更为高效的高性能JVM,而且具有如下特点:
- 由于具有先进的C4 GC、底层优化和先进的Falcon JIT编译器,它比其他JVM能够更好地处理峰值负载。
- 使用ReadyNow以避免JIT加速(即由JIT带来的高CPU使用率)。
- 其处理峰值方式不但可以处理更高的峰值负载,而且能够提供更低的延迟。















 5992
5992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









