






前言
前两周,黑森林工作室发布了他们的FLUX Tools,一共有4款全新的控制模型:canny,depth,Fill和Redux。
模型简介
我们知道在原来的SD中的ControlNet中有也有canny和Depth,分别是线稿控制,深度控制。而在Flux Tools中的Canny和Depth是内嵌在大模型中的控制模型,是通过加载Lora来控制图像生成,不需要像SD中调用Controlnet来得这么麻烦。
而Fill模型同样也是通过内嵌在大模型中的方式,以Lora的形式调用即可,而且还嵌入了inpaint的功能,直接可以对图像进行局部重绘和图像扩展。
Redux模型和上述三个同理,也是通过调用Lora方式进行引用,其作用是类似之前sd的ip-adapter风格迁移的功能。
模型安装
首先说明的是这次Flux Tools模型相对比较大,占用的显存也比较高,如果电脑配置在24G以上显存可以下载到本地使用,如果是低显存容易报错,可以考虑云端使用。(推荐端脑云-CG迷 大佬的云端镜像)
以上是涉及到的模型和对应素材,已打包,文末自取~
模型位置:
FLUX内嵌的Canny、Deth、Fill大模型放在:ComfyUI/models/diffusion_models/ 文件夹内
FLUX Redux 大模型放在:ComfyUI/models/style_models/文件夹内
通过调用的Lora模型可以放在:ComfyUI/models/Loras/文件夹内
sigclip_vision模型放在:ComfyUI/models/clip_vision/文件夹内
模型讲解演示
我们通过测试Flux模型内嵌的和引用Lora的形式进行对比测试如下:
Deth:左边上传的是参考图,对比Deth,在右侧的两个图中,上面是通过Flux模型内嵌的方式得到的图像,下面是通过引用Lora的方式生成得到的图像。
这是连接Deth模型节点:
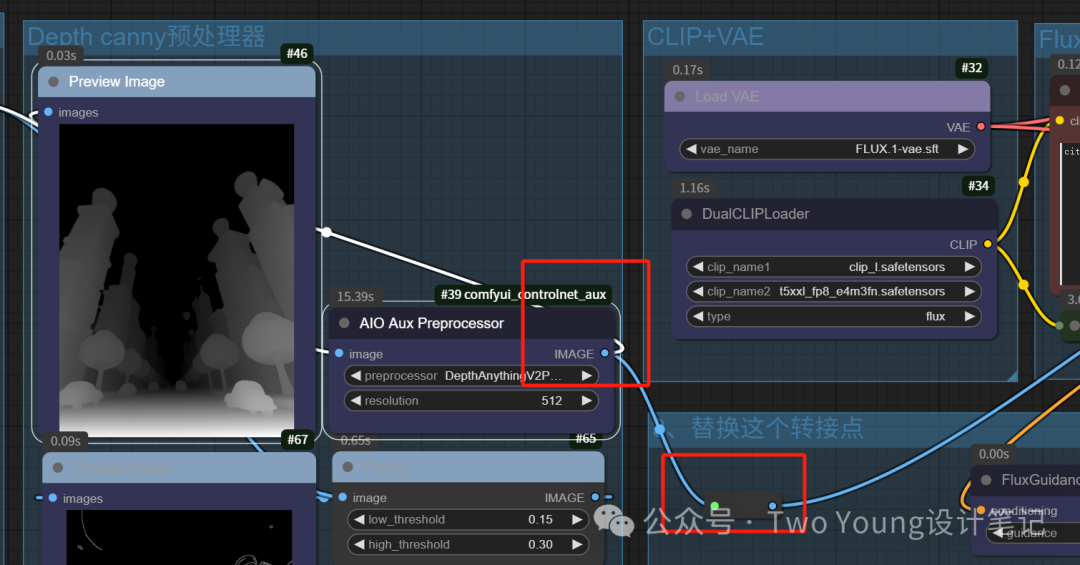
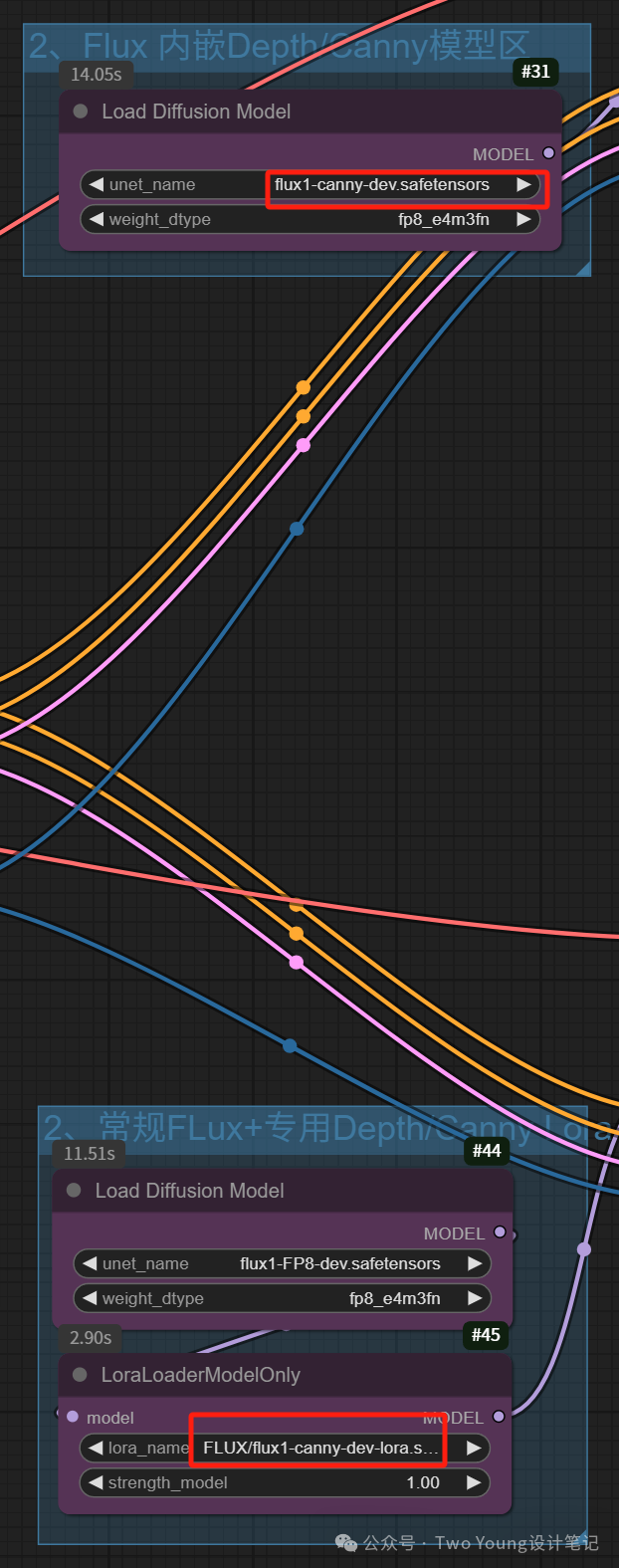
这是选择Deth的内嵌模型(上)和Lora模型(下):

对比之下,上面的图像细节,对比更加好一些,下面的图还有一些瑕疵,以及房子的细节和地面的细节都没有上图的好。
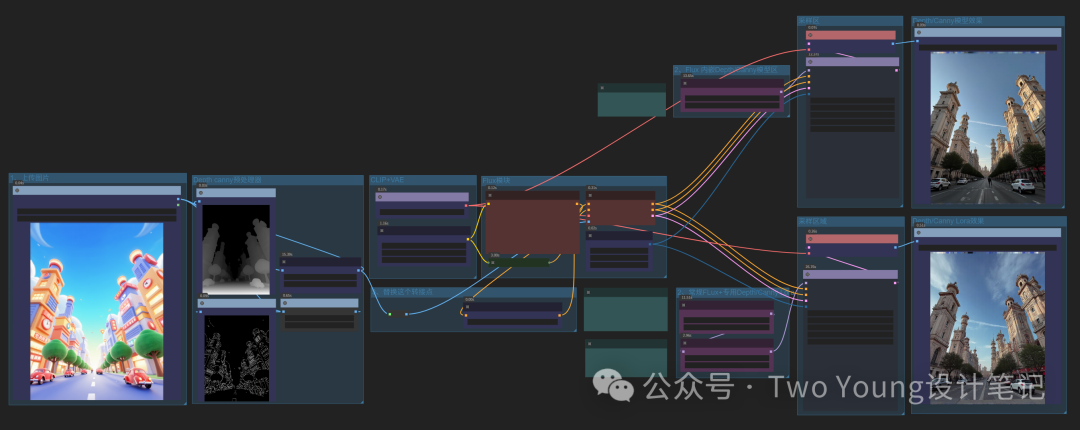
Canny:这里同理,左边还是上传城市这张图,通过canny预处理生成
这里需要将这个节点切换成canny的连接点
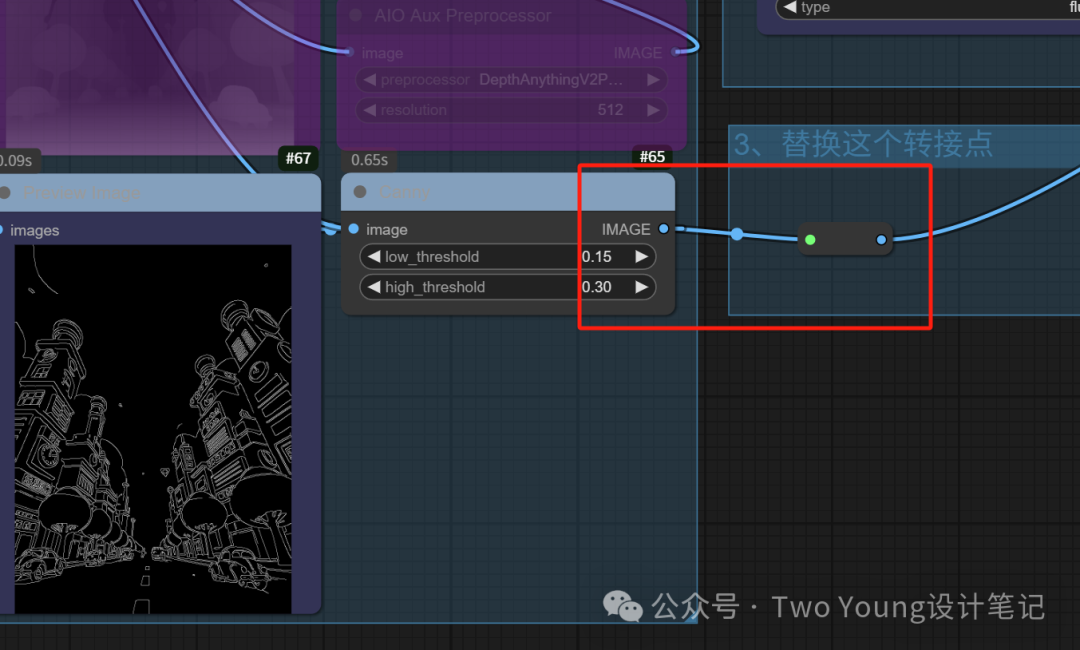
这是选择canny的内嵌模型(上)和Lora模型(下)
同理,上面的图还是用内嵌的Flux canny模型,下面的图调用的是Lora,整体看,虽然两个都很好了,但是上面的是要好那么一点点的,细节也会好一点,出图也会更加清晰。
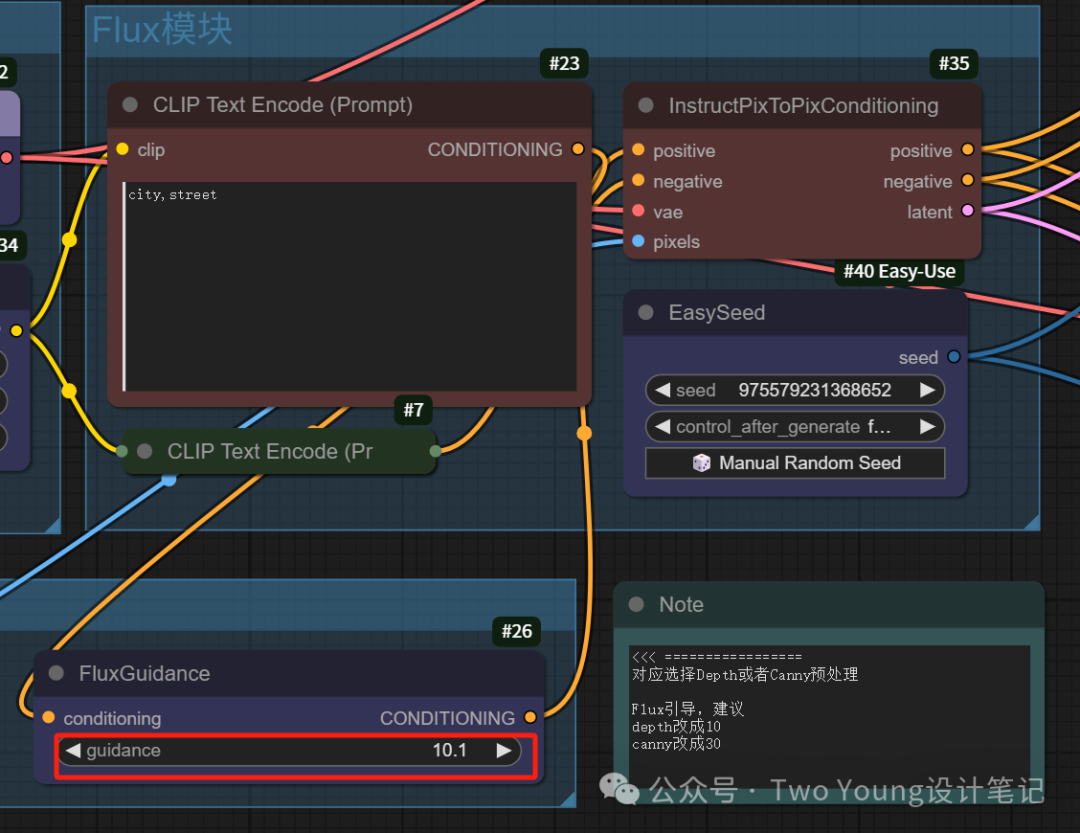
最后一点说明:deth和canny两个内嵌的模型,有一个节点FluxGuidance,参数需要单独调整,这个如果是deth,数值设置为10左右就ok,如果是canny,数值设置为30左右就ok。
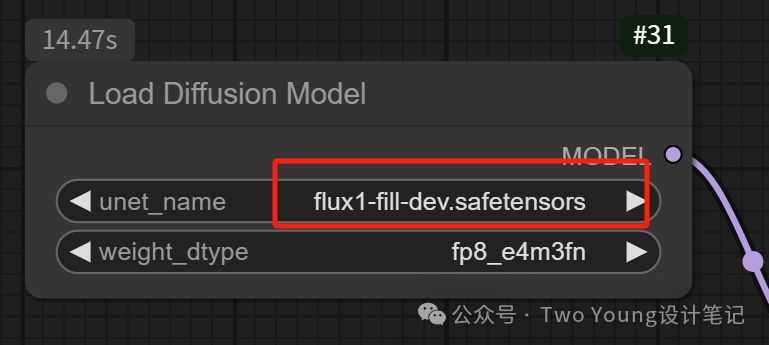
Fill:这个模型有两个功能:一是扩图,二是局部重绘。
Fill模型也是内嵌在Flux大模型中,在工作流中使用的时候,选择对应的Fill大模型,然后上传图像。(工作流在文末自取~)
扩图演示:
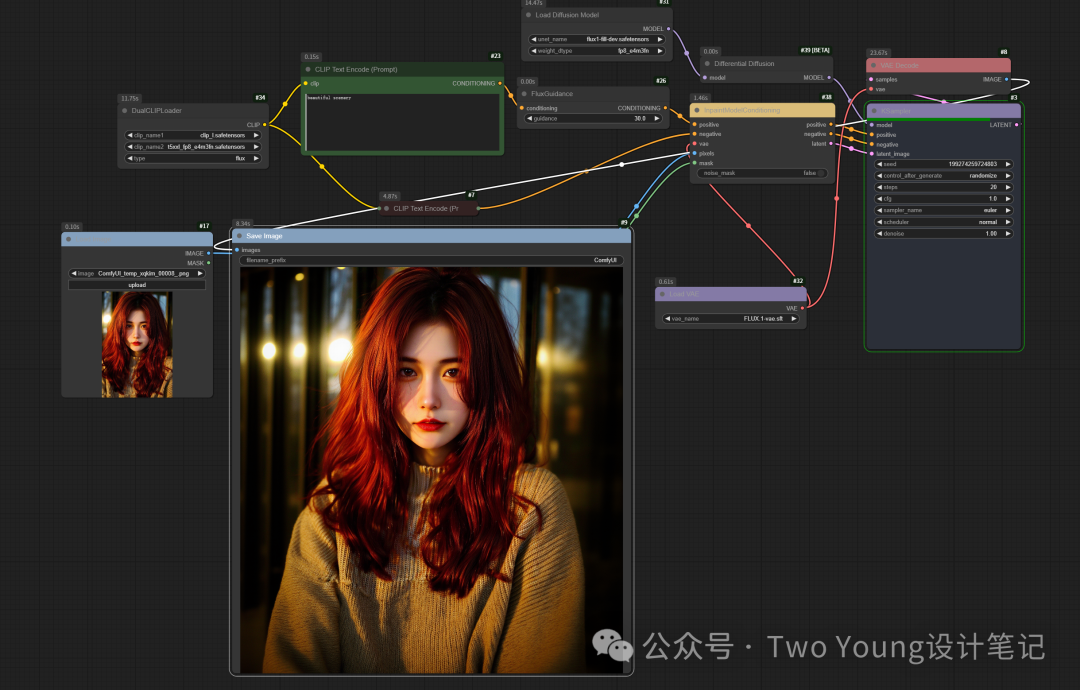
局部重绘演示:我们还是用这个妹纸,我们通过在这个妹纸的眼睛处进行涂抹,关键词输入:眼镜,就可以无缝给这个妹纸添加眼镜了。
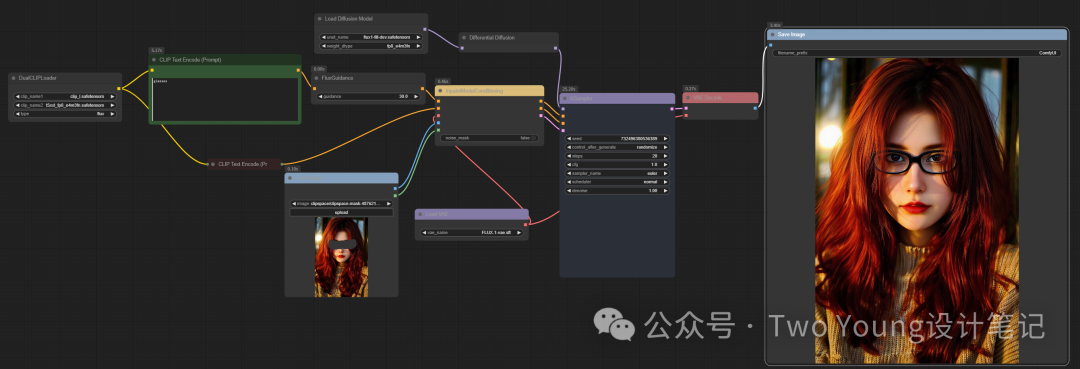
Redux-风格迁移:这个模形同样的是嵌入在Flux大模型中的,在工作流中只要选择对应的Redux风格模型即可
在工作流中,有三种方法控制图像:一是可以选择迁移一张风格,二是也可以进行多张图风格的融合,三是可以加上提示词控制图像画面内容。(工作流文末自取~)
第一种方式
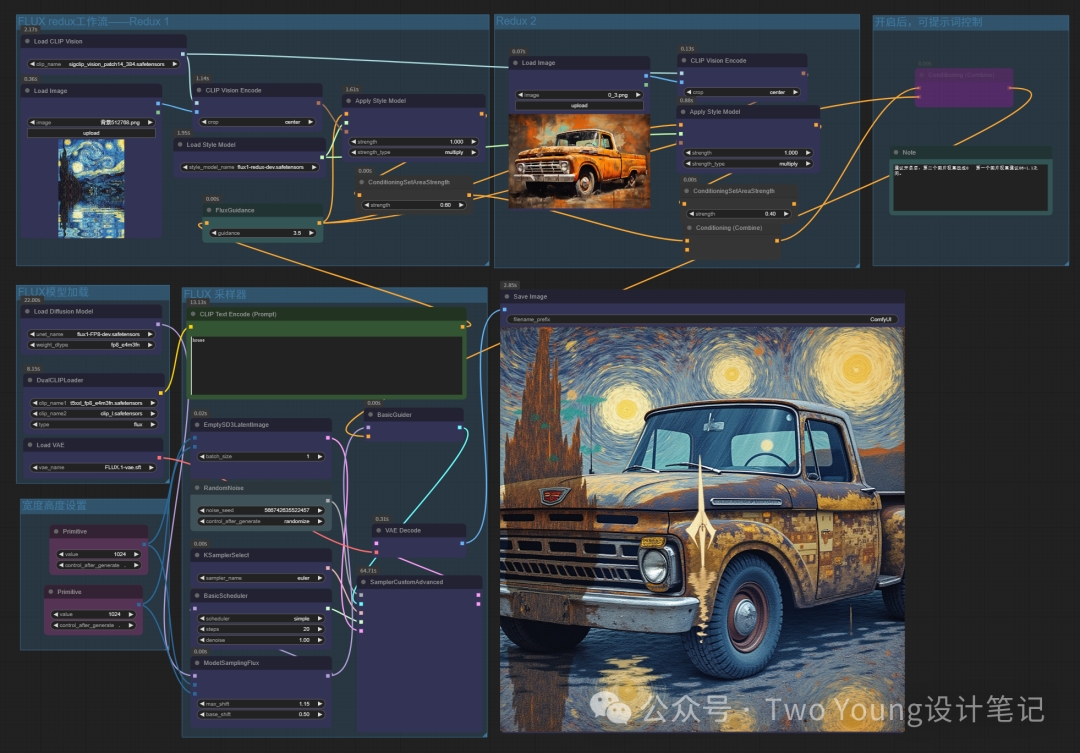
通过一张图控制,上传一张参考图,如梵高·星空,得到一张带有这参考图风格的图像:
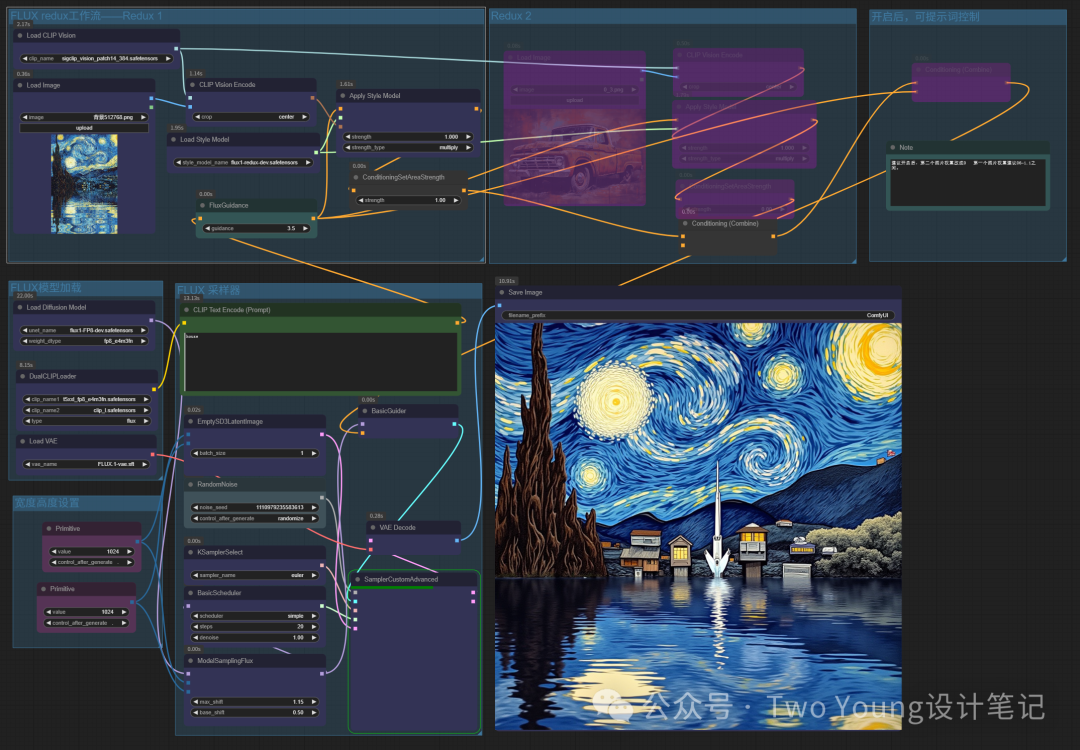
工作流来源:CG迷
第二种方式
多图控制:我们打开第二个图像节点,并且调整第一个图像节点权重为0.6,第二个图像节点权重为0.4
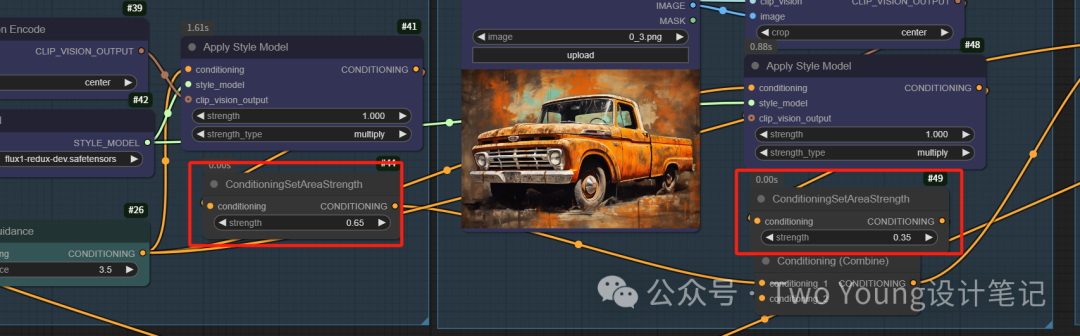
得到带有梵高风格的图像:
第三种方式
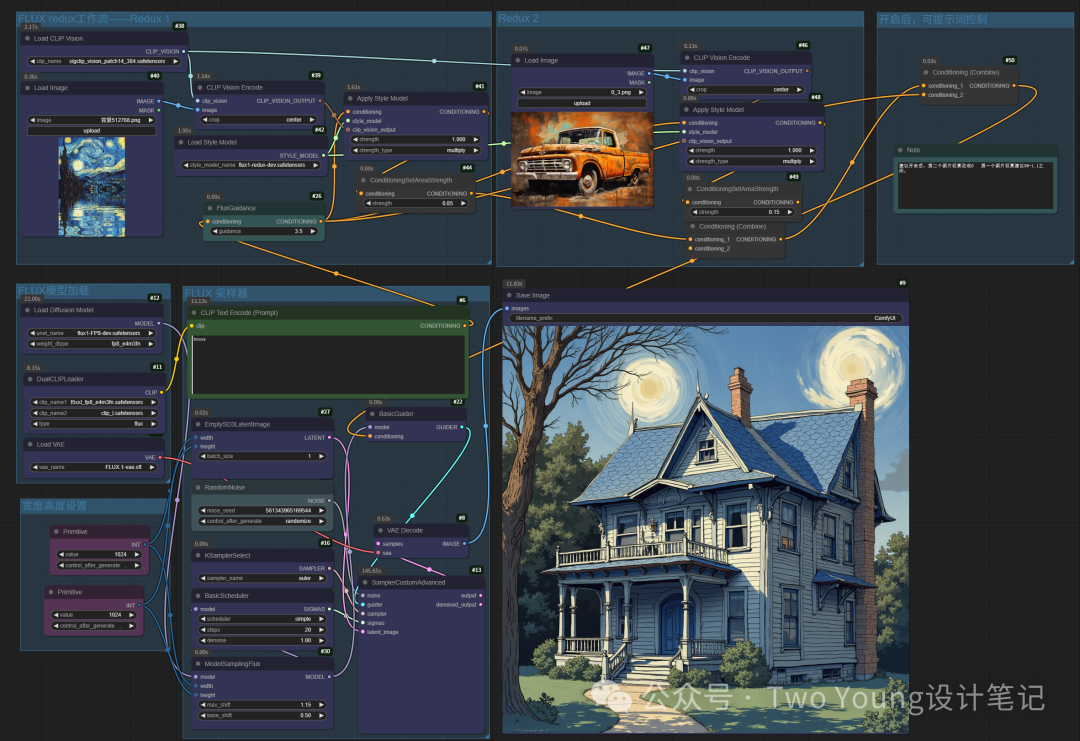
打开提示词控制节点,输入提示词:房子,然后前面两个步骤的图像权重调整为0.85和0.15
生成后得到一个带有梵高风格的新的图像:
如何训练LorA
对于很多刚学习AI绘画的小伙伴而言,想要提升、学习新技能,往往是自己摸索成长,不成体系的学习效果低效漫长且无助。
如果你苦于没有一份Lora模型训练学习系统完整的学习资料,这份网易的《Stable Diffusion LoRA模型训练指南》电子书,尽管拿去好了。
包知识脉络 + 诸多细节。节省大家在网上搜索资料的时间来学习,也可以分享给身边好友一起学习。
由于内容过多,下面以截图展示目录及部分内容,完整文档领取方式点击下方微信卡片,即可免费获取!

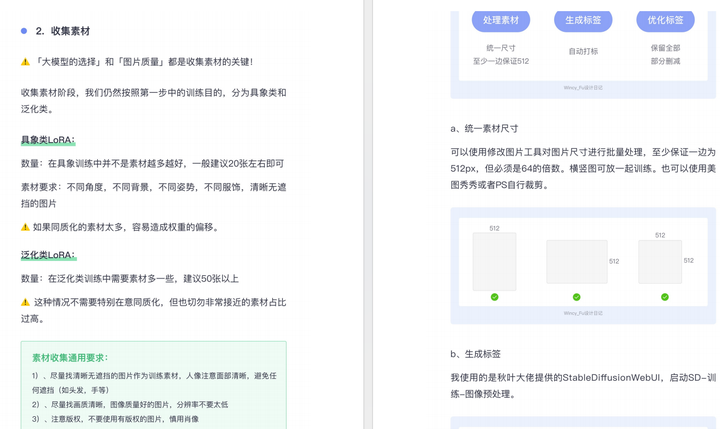
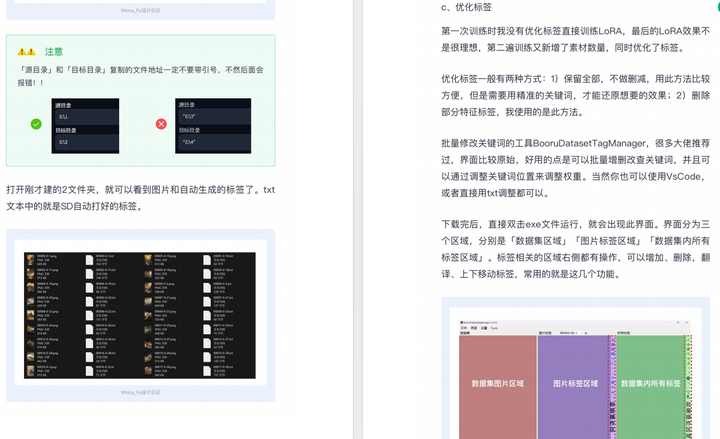
篇幅有限,这里就不一一展示了,有需要的朋友可以点击下方的卡片进行领取!

















 2628
2628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









