






-
考虑到OCR及物体信息会对image caption生成产生正向引导,我们抽取了OCR及目标检测类别信息,作为特征补充;
-
并不是所有的图像都含有OCR信息,我们采用多种模型互补融合,用视觉模态模型强化那些不含OCR的数据,用视觉+文本(OCR+物体类别)多模态模型强化含有OCR信息较丰富的数据;
-
针对多种模型生成的结果,考虑到最终的衡量指标是CIDEr,我们通过self-cider、ocr maximization 多种策略融合的方式进行结果融合。
▐ 可应用的场景
Image captioning需要视觉理解与文本生成,是视觉和NLP任务的结合,可应用于互联网产品的内容标题自动生成,另外也可以帮助盲人和视觉受损用户提升他们对世界的感知能力。
▐ 赛事链接
- workshop:
https://vizwiz.org/workshops/2021-workshop/
- challenge:
https://eval.ai/web/challenges/challenge-page/739/overview
??? 冠军 ???
Herbarium 2021 - Half-Earth Challenge
▐ 题目
Workshop:The Eight Workshop on Fine-Grained Visual Categorization
Task:fine-grained plant species identification
▐ 参赛者
元年,兰枻,琉潇,有邻,暖雨,济宇,篱悠
▐ 技术领域
大规模实例级物体识别
▐ 比赛背景介绍
Herbarium 2021属于 CVPR2021 FGVC8 workshop的一项比赛,该workshop针对实例级细粒度识别问题,已经连续举办第八届。
Herbarium 2021 比赛数据集为从多个大型植物园收集的美洲、大洋洲等半个地球的6.5W类2.5M张植物样本图片,用于训练植物识别算法,辅助植物学家进行植物识别,发现和保护新物种。
该数据集存在长尾分布,样本数目最少的类别仅有3张样本,同时,不同植物间视觉非常相似,同时同一植物的不同样本有较大差异,给实例级识别带来很大挑战。
▐ 我们的成绩
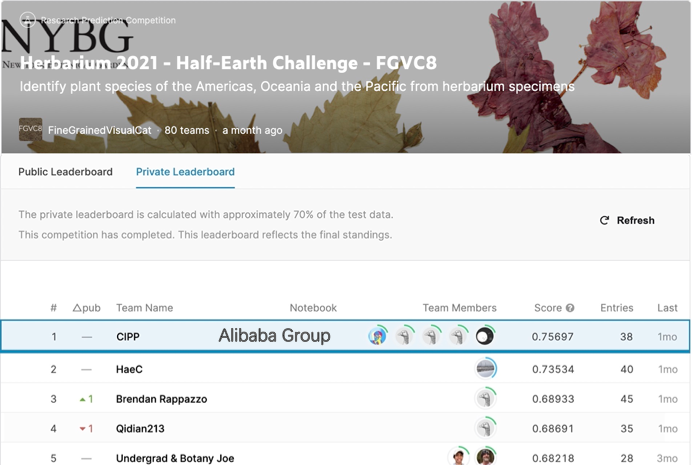
我们以F1 score 0.757的成绩在该项比赛上取得了第一名的成绩,远超第二名的0.735和第三名的 0.689。
▐ 任务难点
该任务主要存在以下两个难点:
-
植物种类多、类别细,不同植物间视觉非常相似,而同一植物的不同样本存在差异,导致类间易混淆,区分难度大;
-
数据集的样本分布不均衡,存在长尾分布,样本数目最少的类别仅有3张样本,如何提升长尾类别准确率至关重要。
▐ 我们通过以下途径解决这些困难
将自然场景中实例级植物识别问题转换成大规模细粒度特征表达问题,提出self-attention pooling进行局部特征增强提升特征表达能力;通过引入Imbalanced Sampler和自适应类别loss解决类别分布不平衡问题;此外,基于混合精度的大规模多机多卡训练能力,实现近三百万数据规模下的快速迭代能力。
实现高效万级在线难样本挖掘,极大提升了特征在复杂场景下的泛化能力。最终凭借领先亚军2.2%的优势,一举获得冠军。
▐ 可应用的场景
实例级的细粒度识别技术可辨别物体间细微的视觉差异从而实现精细的物体识别,广泛应用于商品识别、动植物识别、行人识别、地标识别等领域。
▐ 赛事链接
- Workshop:
https://sites.google.com/view/fgvc8/home
- Challenge:
https://sites.google.com/view/fgvc8/competitions/herbariumchallenge2021
- Kaggle leadboard:
https://www.kaggle.com/c/herbarium-2021-fgvc8/leaderboard
??? 冠军 ???
ActivityNet Home Action Genome Challenge
▐ 题目
Workshop:International Challenge on Activity Recognition
Task:Home Action Genome Challenge
▐ 参赛者
少麟,廖越(北航),咏亮,叶盈,篱悠,刘偲(北航)
▐ 技术领域
视频人物交互关系
▐ 比赛背景介绍
Home Action Genome Challenge今年首次在CVPR2021 ActivityNet Workshop举办, 由斯坦福大学李飞飞教授课题组主办,比赛提供了一个大规模多视角的视频数据集,通过多模态视频分析,检测视频中存在的人物交互关系。
▐ 我们的成绩
我们以准确率76.5%的成绩在该项比赛上取得了第一名的成绩,大幅领先第二名的68.4%和第三名的65.7%。

Home Action Genome Challenge 获奖证书
▐ 任务****难点
该任务主要有3个难点:
-
数据集的日常家居场景复杂,人体和物体的目标检测难度大
-
人物关系包含动作关系和空间关系,关注不同的视觉特征
-
每一组人体和物体都存在多个人物关系,评估时必须完全正确才计一次正确
▐ 我们通过以下途径解决这些困难
-
采用更好的检测模型:我们采用Swin-Transformer和ResNeSt为backbone的性能SOTA的检测模型,并通过多种数据增强策略训练和多尺度融合推理,提升目标检测的准确率。
-
强化人物关系的视觉特征:我们设计了融合两阶段和一阶段关系检测网络的方案,首先将Swin-Transformer融入两阶段关系检测网络进行端到端训练,然后改进一阶段关系检测网络,直接提取<人,物>二元组,再通过cascade结构判定关系,给出<人,物,关系>三元组。策略上,我们通过视觉特征判定动作关系,空间位置作为输入辅助判定空间关系。
-
基于统计偏置的生成策略:我们在生成最终的人物交互关系组时,采用了融合<人,物,关系>三者共生概率和统计偏置加权的多种策略。
▐ 可应用的场景
视频人物交互关系检测,检测视频中动态的<人,物,关系>的结构化信息,未来可应用于视频信息结构化,人机交互等应用场景。
▐ 赛事链接
分享
1、算法大厂——字节跳动面试题

2、2000页互联网Java面试题大全

3、高阶必备,算法学习

关系检测,检测视频中动态的<人,物,关系>的结构化信息,未来可应用于视频信息结构化,人机交互等应用场景。
▐ 赛事链接
分享
1、算法大厂——字节跳动面试题
[外链图片转存中…(img-ANe0IEvg-1719252785489)]
2、2000页互联网Java面试题大全
[外链图片转存中…(img-3d62okz4-1719252785490)]
3、高阶必备,算法学习
[外链图片转存中…(img-jGQTliEU-1719252785490)]















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









