






IOPaint 是由 SOTA AI 模型提供支持的免费开源修复和修复工具,可以轻松实现图片去水印,去除图片不需要的部分,是目前效果最好的一个项目!完全免费开源
从图片中删除任何不需要的对象、缺陷、人物或擦除和替换任何东西,这在以往是难以实现的,但是本期粼光分享的开源AI项目-IOPaint,一款免费的开源且完全可自托管的修复/修复工具,能够完美实现以上功能
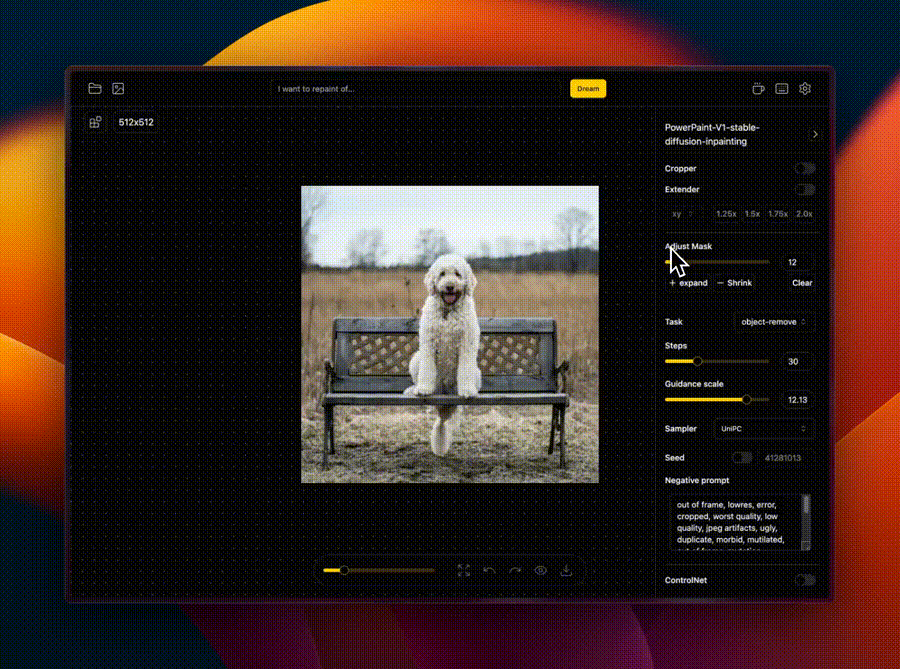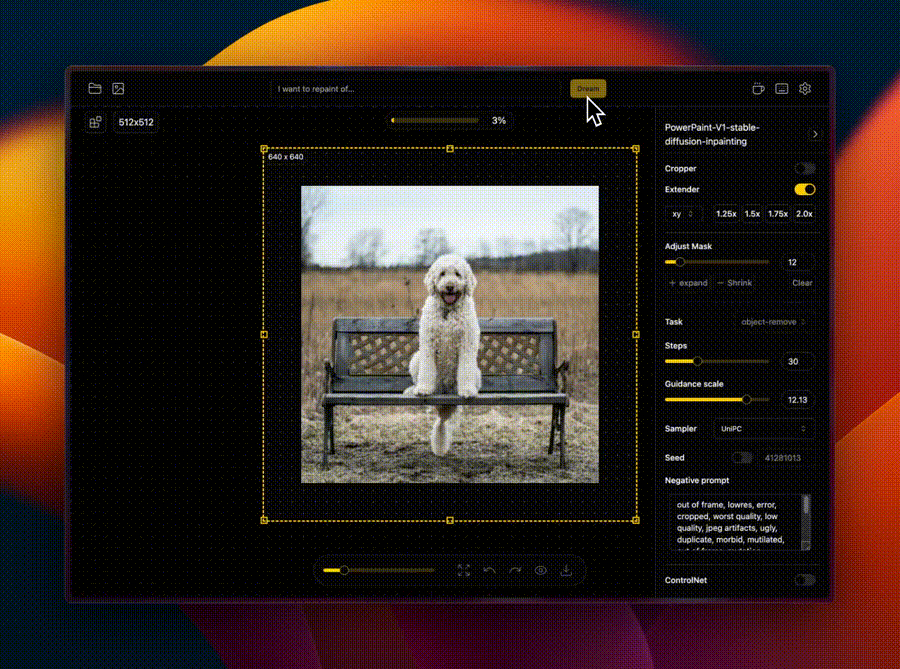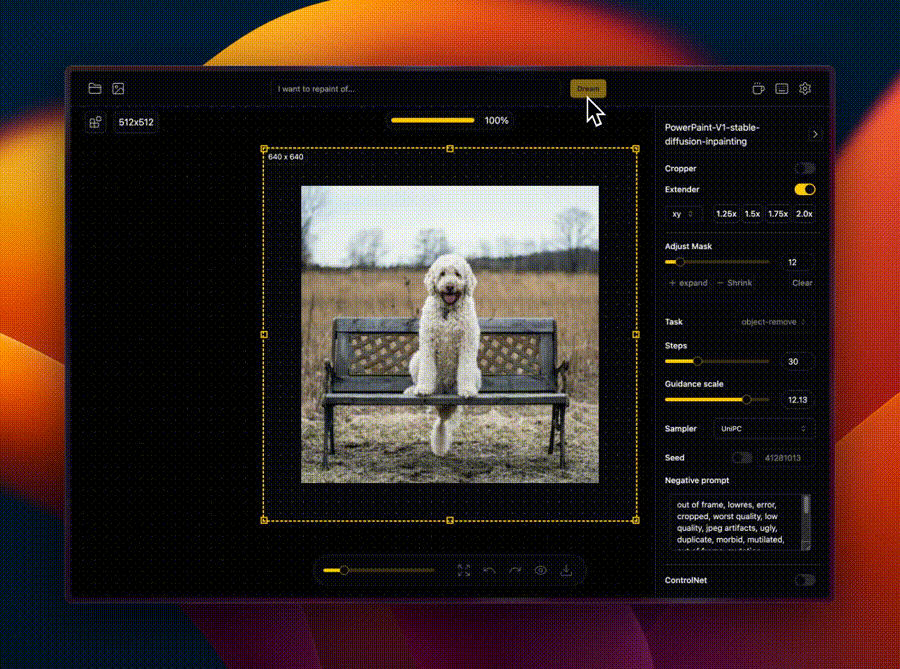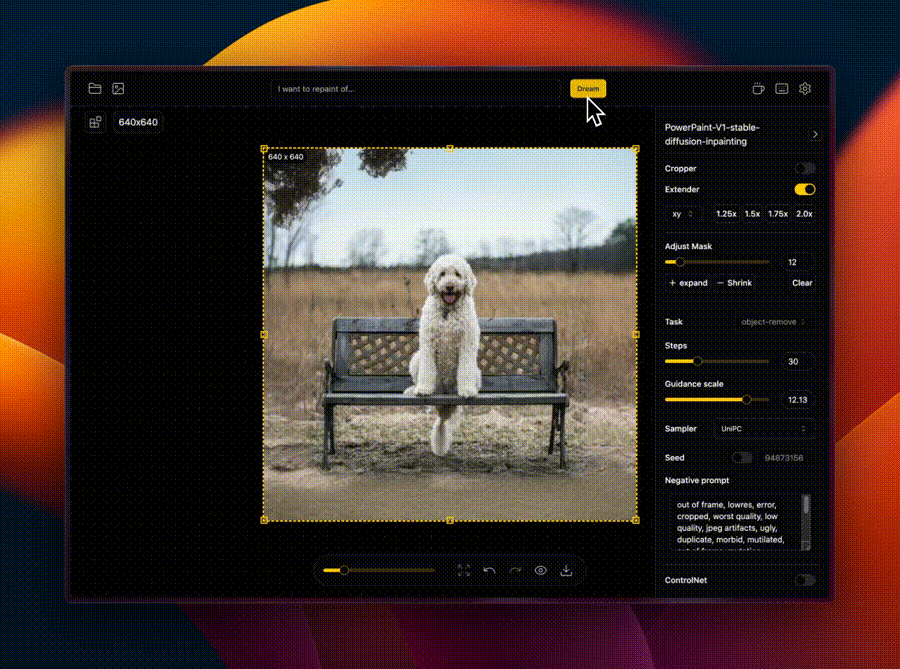
IOPaint原项目名是Lama Cleaner,这个项目就是SOTA人工智能模型支持的图像修复工具。

**项目简介
**
IOPaint 是一款由最新 AI 模型驱动的免费开源图像处理工具,专注于图像修复、去水印和智能扩展。其功能包括移除不需要的元素(如水印、瑕疵),智能修复画面缺失部分,以及基于 Stable Diffusion 实现的内容生成与图像扩展。IOPaint 的操作简单直观,无需专业背景,适合设计师、摄影师和普通用户自托管使用,兼容多平台(Windows、macOS、Linux)。
**快速上手
**
1、在线体验
您可以在 IOPaint 尝试HuggingFace 空间,HuggingFace 的免费 CPU 实例上运行,运行速度较慢
在线体验/模型下载:https://www.lgboxs.com/archives/app/iopaint
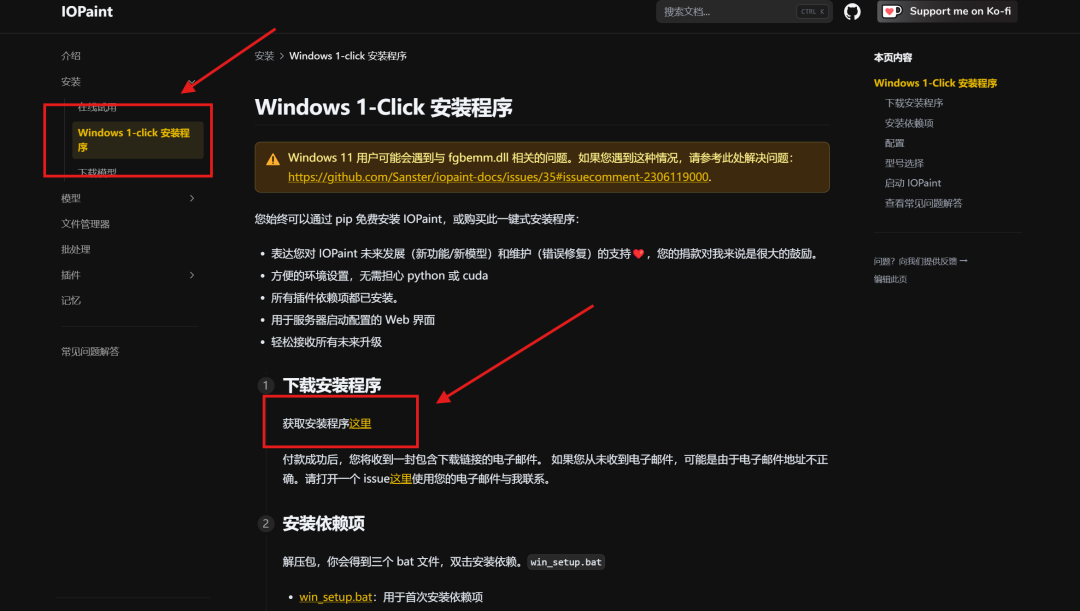
2、本地Windows部署
由于Windows本地部署操作门槛较高,良心的是官方也打包好了winsows一键安装包,不过需要支付5美元的辛苦费
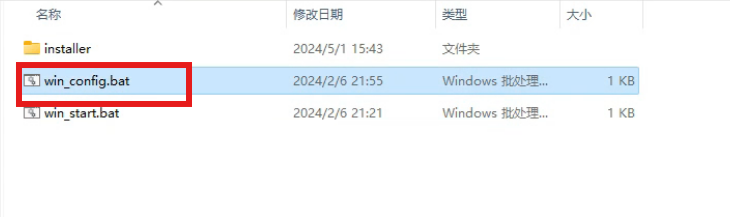
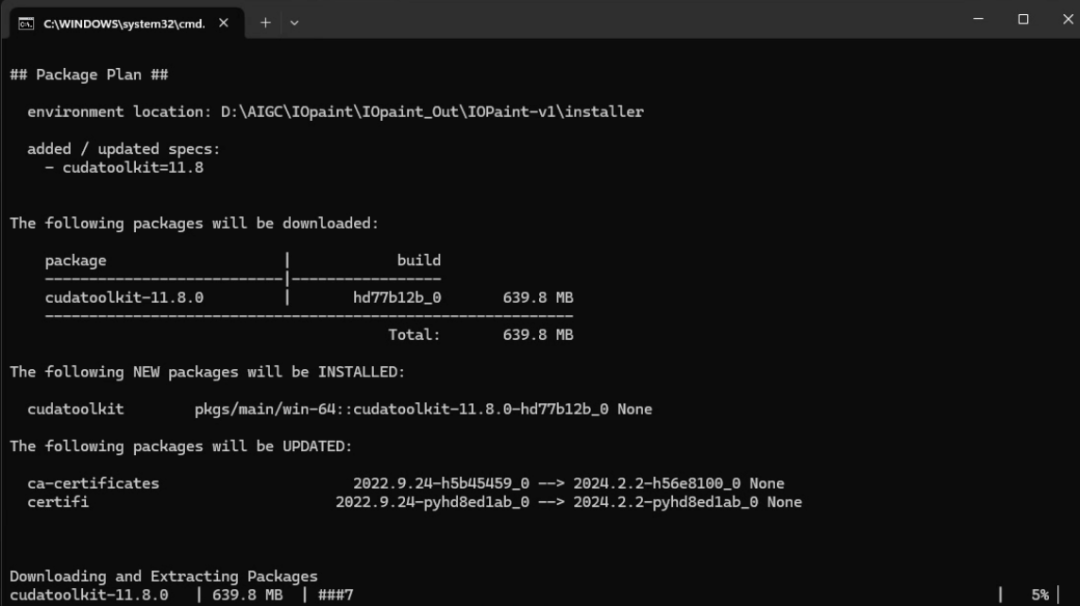
安装好后双击启动该win_config.bat,会弹出运行窗口,自动部署程序运行所需的环境以及大约3G模型包(需要魔法)
安装完成后,浏览器会自动弹出程序设置界面,相关设置请参考B站有关教程:
教程地址:https://www.bilibili.com/video/BV1Af421D7uv?vd\_source=9a6398737b3cdd496511bfa22368df39
基础设置完成之后在安装包内找到win_start.bat文件,双击启动运行窗口开启WebUI,开始首次启动需要等待较长时间
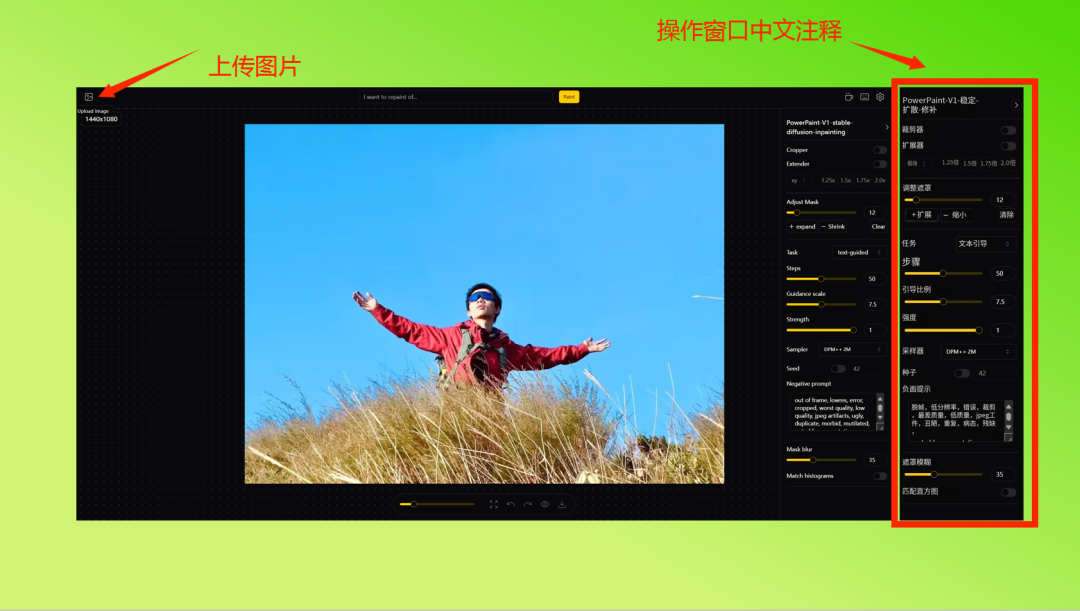
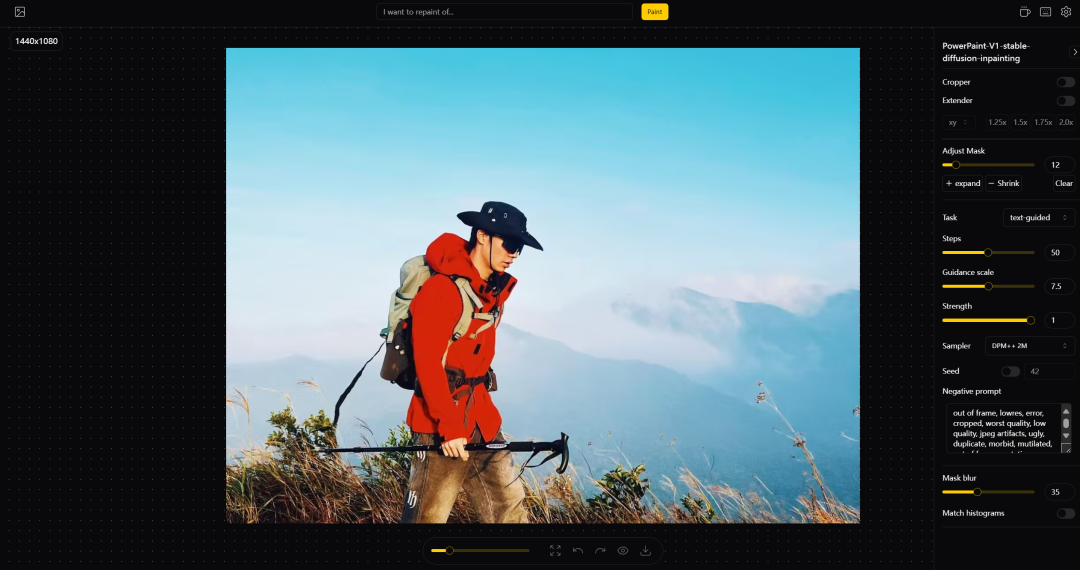
程序WebUI操作界面如下:
**软件特点
**
📸 图像擦除(Erase)
使用特定的AI模型(如LaMa)来移除图片中的不想要的对象、缺陷、水印或人物,帮助用户清理图片,使其看起来更加整洁或去除不需要的元素。
🖼️ 对象替换(Replace Object)
通过AI模型,用户可以替换图片中的某个对象,用于更改图片内容或修复错误。
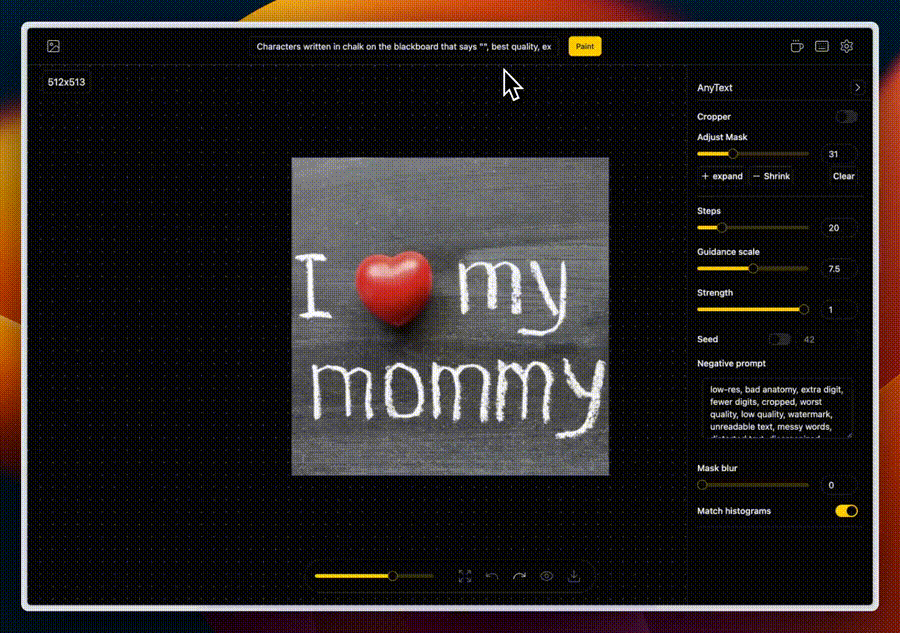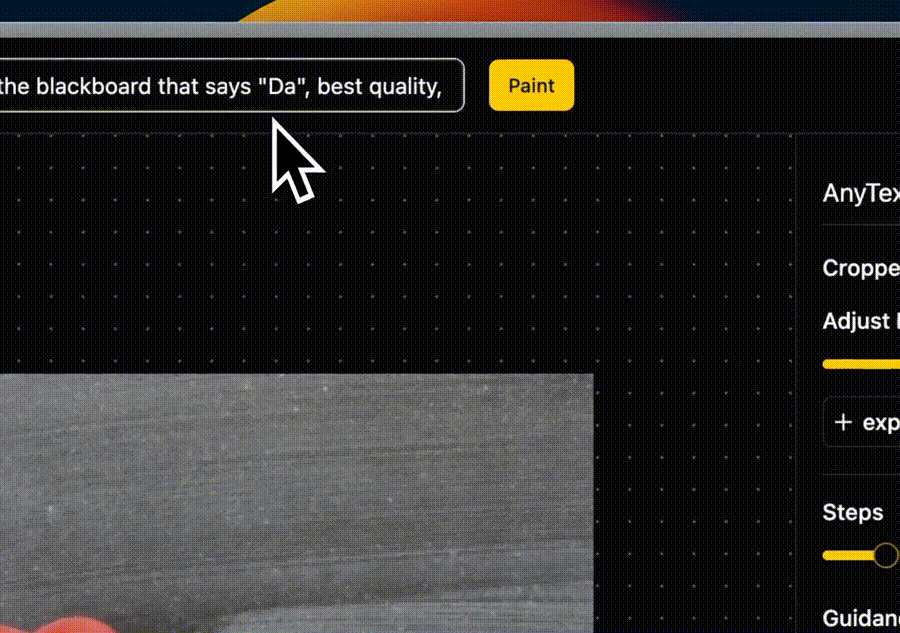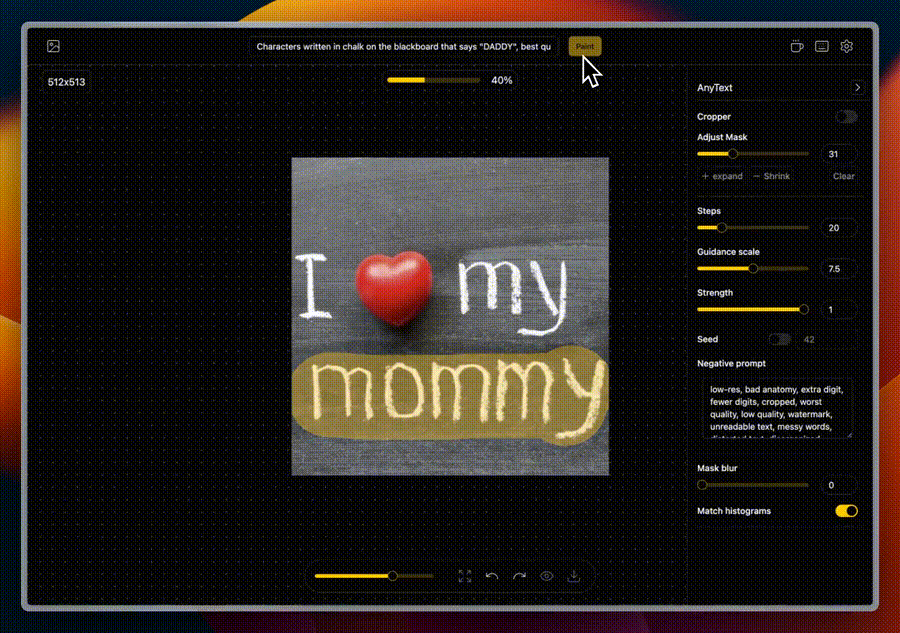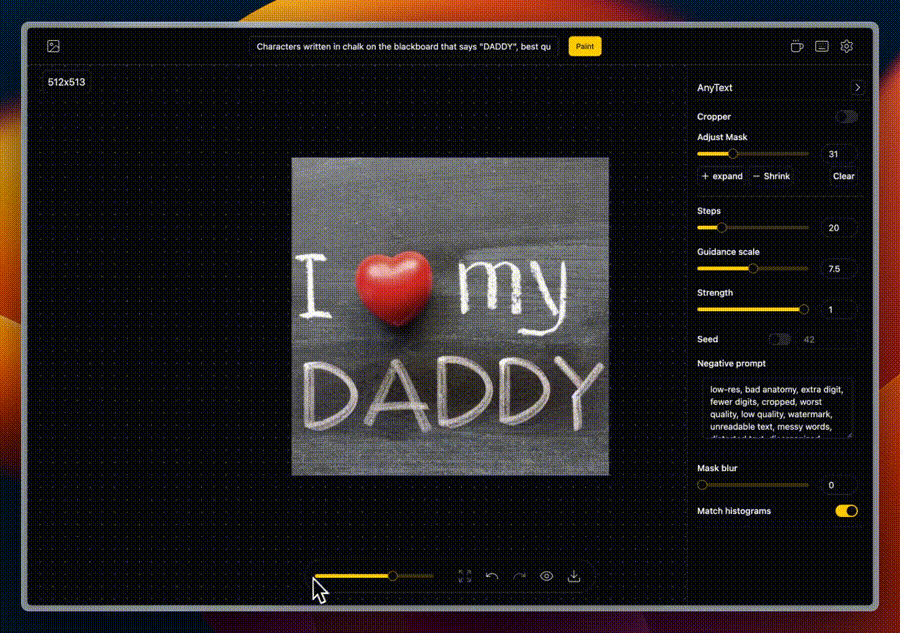
📝 文本绘制(Draw Text)
在图片上添加或编辑文本,该功能对于创建带有说明或标题的图像或者替换现有图像文字特别有用。
🖌️ 图像外扩(Out-painting)
扩展图像的画幅边界,AI会生成新的像素来填充扩展的部分,使得图像看起来自然且无缝。
🔌 插件支持
支持Segment Anything(提供准确的交互式对象分割)、RemoveBG(移除图像背景或生成前景对象的遮罩)和Anime Segmentation(针对动漫图像的模型训练,用于分割)等众多实用插件。
📁 批量处理
IOPaint允许用户批量处理图片,这在需要处理大量图片时可以显著提高效率。
🌐 自托管和跨平台
IOPaint是完全免费和开源的,支持在多种硬件上运行,包括CPU、GPU和Apple Silicon,并且提供了Windows一键安装器,方便用户在不同平台上使用。

粼光子交流社区
▼

本文转自 https://mp.weixin.qq.com/s/dSdbB1ZQOGKWFsDN_Vsy3w,如有侵权,请联系删除。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









