






哈喽,大家好!~
今天给大家介绍5篇最新发布的,大模型相关论文。
快速获取,点击名片,回复「论文」
T2Vid: Translating Long Text into Multi-Image is the Catalyst for Video-LLMs
The success of Multimodal Large Language Models (MLLMs) in the image domain has garnered wide attention from the research community.
多模态大语言模型(MLLM)在图像领域的成功引起了研究界的广泛关注。
Drawing on previous successful experiences, researchers have recently explored extending the success to the video understanding realms. Apart from training from scratch, an efficient way is to utilize the pre-trained image-LLMs, leading to two mainstream approaches, i.e. zero-shot inference and further fine-tuning with video data. In this work, our study of these approaches harvests an effective data augmentation method. We first make a deeper inspection of the zero-shot inference way and identify two limitations, i.e. limited generalization and lack of temporal understanding capabilities. Thus, we further investigate the fine-tuning approach and find a low learning efficiency when simply using all the video data samples, which can be attributed to a lack of instruction diversity.
借鉴以往的成功经验,研究人员最近探索将成功扩展到视频理解领域。除了从头开始训练之外,一种有效的方法是利用预先训练的图像LLMs ,从而产生了两种主流方法,即。零样本推理并利用视频数据进一步微调。在这项工作中,我们对这些方法的研究收获了一种有效的数据增强方法。我们首先对零样本推理方式进行更深入的检查,并确定两个局限性,即。概括性有限且缺乏时间理解能力。因此,我们进一步研究了微调方法,发现仅使用所有视频数据样本时学习效率较低,这可归因于缺乏指令多样性。
Aiming at this issue, we develop a method called T2Vid to synthesize video-like samples to enrich the instruction diversity in the training corpus. Integrating these data enables a simple and efficient training scheme, which achieves performance comparable to or even superior to using full video datasets by training with just 15% the sample size. Meanwhile, we find that the proposed scheme can boost the performance of long video understanding without training with long video samples. We hope our study will spark more thinking about using MLLMs for video understanding and curation of high-quality data.
针对这个问题,我们开发了一种名为T2Vid的方法来合成类视频样本,以丰富训练语料库中的指令多样性。集成这些数据可以实现简单而高效的训练方案,通过仅使用**15%**的样本量进行训练,即可获得与使用完整视频数据集相当甚至更好的性能。同时,我们发现所提出的方案可以提高长视频理解的性能,而无需使用长视频样本进行训练。我们希望我们的研究能够激发更多关于使用 MLLM 进行视频理解和高质量数据管理的思考。
The code is released at https://github.com/xjtupanda/T2Vid.
代码发布于https://github.com/xjtupanda/T2Vid 。

On Domain-Specific Post-Training for Multimodal Large Language Models
Recent years have witnessed the rapid development of general multimodal large language models (MLLMs). However, adapting general MLLMs to specific domains, such as scientific fields and industrial applications, remains less explored.
近年来,通用多模态大语言模型(MLLM)迅速发展。然而,将通用 MLLM 应用于特定领域(例如科学领域和工业应用)的探索仍然较少。
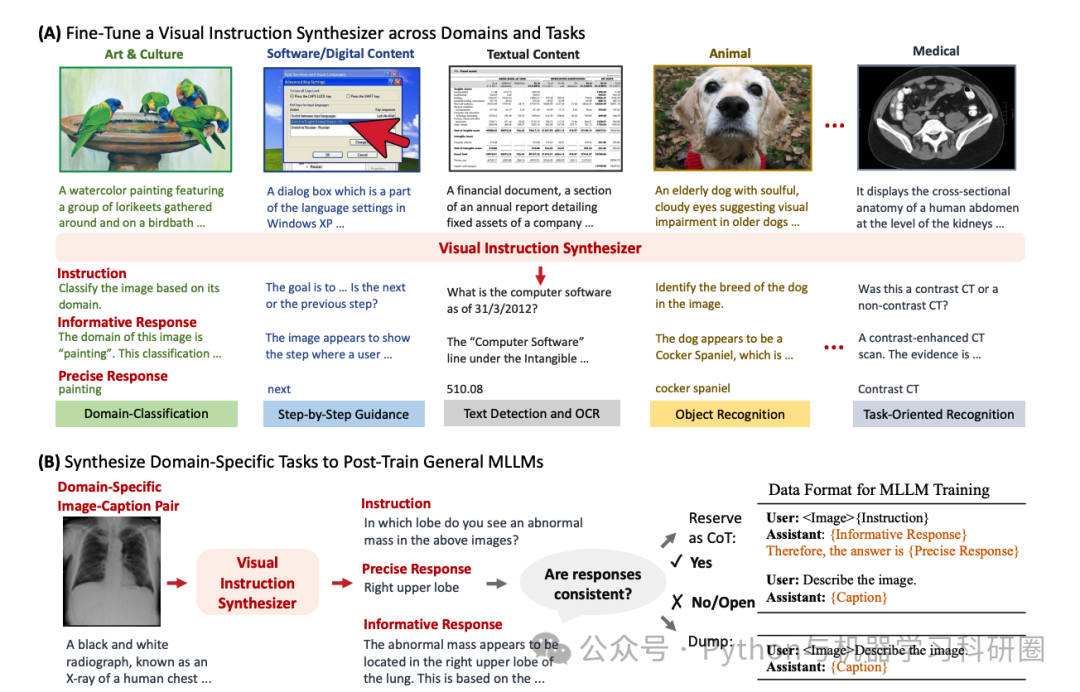
This paper systematically investigates domain adaptation of MLLMs through post-training, focusing on data synthesis, training pipelines, and task evaluation. (1) Data Synthesis: Using open-source models, we develop a visual instruction synthesizer that effectively generates diverse visual instruction tasks from domain-specific image-caption pairs.
本文通过后训练系统地研究了 MLLM 的领域适应,重点关注数据合成、训练流程和任务评估。(1)数据合成:使用开源模型,我们开发了一种视觉指令合成器,可以从特定领域的图像标题对有效地生成各种视觉指令任务。
Our synthetic tasks surpass those generated by manual rules, GPT-4, and GPT-4V in enhancing the domain-specific performance of MLLMs. (2) Training Pipeline: While the two-stage training—initially on image-caption pairs followed by visual instruction tasks—is commonly adopted for developing general MLLMs, we apply a single-stage training pipeline to enhance task diversity for domain-specific post-training. (3) Task Evaluation: We conduct experiments in two domains, biomedicine and food, by post-training MLLMs of different sources and scales (e.g., Qwen2-VL-2B, LLaVA-v1.6-8B, Llama-3.2-11B), and then evaluating MLLM performance on various domain-specific tasks. To support further research in MLLM domain adaptation, we will open-source our implementations.
在增强 MLLM 的特定领域性能方面,我们的综合任务超越了手动规则、GPT-4 和 GPT-4V 生成的任务。(2)训练管道:虽然两阶段训练(首先是图像标题对,然后是视觉指导任务)通常用于开发通用 MLLM,但我们应用单阶段训练管道来增强特定领域职位的任务多样性-训练。(3)任务评估:我们通过训练后不同来源和规模的MLLM(_例如_Qwen2-VL-2B,LLaVA-v1.6-8B,Llama-3.2-11B)在生物医学和食品两个领域进行实验),然后评估 MLLM 在各种特定领域任务上的性能。为了支持 MLLM 领域适应的进一步研究,我们将开源我们的实现。
CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation
The advancement of large Vision-Language-Action (VLA) models has significantly improved robotic manipulation in terms of language-guided task execution and generalization to unseen scenarios.
大型视觉-语言-动作(VLA)模型的进步在语言引导的任务执行和对未见过的场景的泛化方面显着改善了机器人操作。
While existing VLAs adapted from pretrained large Vision-Language-Models (VLM) have demonstrated promising generalizability, their task performance is still unsatisfactory as indicated by the low tasks success rates in different environments.
虽然现有的改编自预训练大型视觉语言模型(VLM)的 VLA 已表现出良好的通用性,但它们的任务性能仍然不能令人满意,不同环境中的任务成功率较低。
In this paper, we present a new advanced VLA architecture derived from VLM.
在本文中,我们提出了一种源自 VLM 的新的高级 VLA 架构。
Unlike previous works that directly repurpose VLM for action prediction by simple action quantization, we propose a componentized VLA architecture that has a specialized action module conditioned on VLM output.
与之前通过简单动作量化直接将 VLM 重新用于动作预测的工作不同,我们提出了一种组件化的 VLA 架构,该架构具有以 VLM 输出为条件的专门动作模块。
We systematically study the design of the action module and demonstrate the strong performance enhancement with diffusion action transformers for action sequence modeling, as well as their favorable scaling behaviors.
我们系统地研究了动作模块的设计,并展示了用于动作序列建模的扩散动作变压器的强大性能增强,以及它们有利的缩放行为。
We also conduct comprehensive experiments and ablation studies to evaluate the efficacy of our models with varied designs.
我们还进行全面的实验和消融研究,以评估我们具有不同设计的模型的功效。
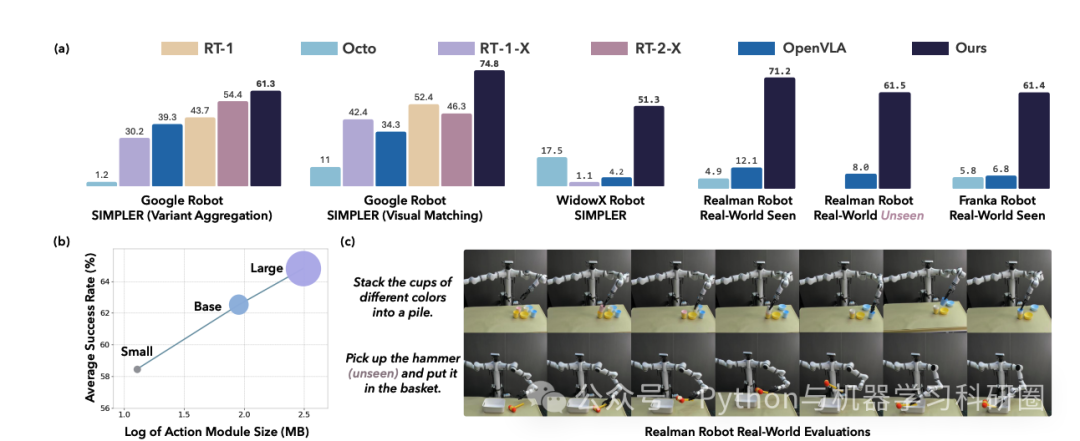
The evaluation on five robot embodiments in simulation and real work shows that our model not only significantly surpasses existing VLAs in task performance but also exhibits remarkable adaptation to new robots and generalization to unseen objects and backgrounds.
对仿真和实际工作中的五个机器人实施例的评估表明,我们的模型不仅在任务性能上显着超越现有的 VLA,而且还表现出对新机器人的显着适应以及对看不见的物体和背景的泛化能力。
It exceeds the average success rates of OpenVLA which has similar model size (7B) with ours by over 35% in simulated evaluation and 55% in real robot experiments. It also outperforms the large RT-2-X model (55B) by 18% absolute success rates in simulation.
它在模拟评估中比与我们的模型大小(7B)相似的 OpenVLA 的平均成功率高出 35% 以上,在真实机器人实验中高出 55%。它还比大型 RT-2-X 模型 (55B) 的模拟绝对成功率高出 18%。
Code and models can be found on our https://cogact.github.io/
代码和模型可以在 https://cogact.github.io/上找到。
Accelerating Multimodal Large Language Models via Dynamic Visual-Token Exit and the Empirical
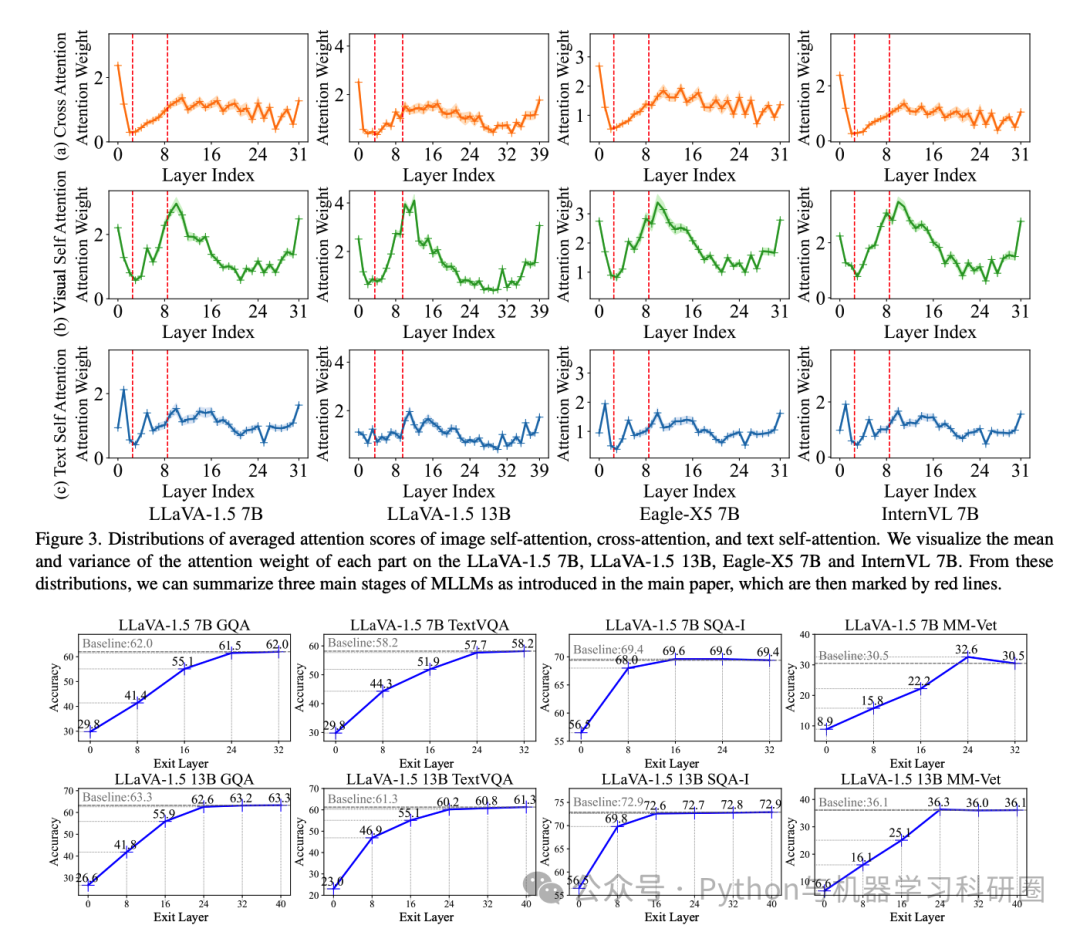
The excessive use of visual tokens in existing Multimoal Large Language Models (MLLMs) often exhibits obvious redundancy and brings in prohibitively expensive computation. To gain insights into this problem, we first conduct extensive empirical studies on the attention behaviors of MLLMs, and summarize three main inference stages in MLLMs: (i) Early fusion between tokens is first accomplished quickly. (ii) Intra-modality modeling then comes to play. (iii) Multimodal reasoning resumes and lasts until the end of inference. In particular, we reveal that visual tokens will stop contributing to reasoning when the text tokens receive enough image information, yielding obvious visual redundancy.
在现有的_多模态大型语言模型_(MLLM)中过度使用视觉标记通常会表现出明显的冗余并带来极其昂贵的计算。为了深入了解这个问题,我们首先对 MLLM 的注意力行为进行了广泛的实证研究,并总结了 MLLM 的三个主要推理阶段: _(i)_代币之间的_早期融合_首先快速完成。 _(ii)_然后_模态内建模_开始发挥作用。 _(iii)**多模态推理_恢复并持续到推理结束。特别是,我们发现,当文本标记接收到足够的图像信息时,视觉标记将停止对推理做出贡献,从而产生明显的视觉冗余。
Based on these generalized observations, we propose a simple yet effective method to improve the efficiency of MLLMs, termed dynamic visual-token exit (DyVTE). DyVTE uses lightweight hyper-networks to perceive the text token status and decide the removal of all visual tokens after a certain layer, thereby addressing the observed visual redundancy.
基于这些普遍的观察,我们提出了一种简单而有效的方法来提高 MLLM 的效率,称为_动态视觉令牌退出_(DyVTE)。DyVTE 使用轻量级超网络来感知文本标记状态,并决定删除某一层之后的所有视觉标记,从而解决观察到的视觉冗余问题。
To validate VTE, we apply it to a set of MLLMs, including LLaVA, VILA, Eagle and InternVL, and conduct extensive experiments on a bunch of benchmarks.
为了验证 VTE,我们将其应用于一组 MLLM,包括 LLaVA、VILA、Eagle 和 InternVL,并针对一系列基准进行了广泛的实验。
The experiment results not only show the effectiveness of our VTE in improving MLLMs’ efficiency, but also yield the general modeling patterns of MLLMs, well facilitating the in-depth understanding of MLLMs. Our code is anonymously released at https://github.com/DoubtedSteam/DyVTE.
实验结果不仅证明了我们的VTE在提高MLLM效率方面的有效性,而且还得出了MLLM的通用建模模式,有助于深入理解MLLM。我们的代码在https://github.com/DoubtedSteam/DyVTE匿名发布。
GEOBench-VLM: Benchmarking Vision-Language Models for Geospatial Tasks
While numerous recent benchmarks focus on evaluating generic Vision-Language Models (VLMs), they fall short in addressing the unique demands of geospatial applications.
虽然最近的许多基准测试都专注于评估通用视觉语言模型 (VLM),但它们在满足地理空间应用的独特需求方面存在不足。
Generic VLM benchmarks are not designed to handle the complexities of geospatial data, which is critical for applications such as environmental monitoring, urban planning, and disaster management.
通用 VLM 基准并非旨在处理地理空间数据的复杂性,而地理空间数据对于环境监测、城市规划和灾害管理等应用至关重要。
Some of the unique challenges in geospatial domain include temporal analysis for changes, counting objects in large quantities, detecting tiny objects, and understanding relationships between entities occurring in Remote Sensing imagery.
地理空间领域的一些独特挑战包括变化的时间分析、大量物体计数、检测微小物体以及理解遥感图像中实体之间的关系。
To address this gap in the geospatial domain, we present GEOBench-VLM, a comprehensive benchmark specifically designed to evaluate VLMs on geospatial tasks, including scene understanding, object counting, localization, fine-grained categorization, and temporal analysis.
为了解决地理空间领域的这一差距,我们推出了 GEOBench-VLM,这是一个综合基准,专门用于评估地理空间任务上的 VLM,包括场景理解、对象计数、定位、细粒度分类和时间分析。
Our benchmark features over 10,000 manually verified instructions and covers a diverse set of variations in visual conditions, object type, and scale. We evaluate several state-of-the-art VLMs to assess their accuracy within the geospatial context.
我们的基准测试包含 10,000 多个手动验证的指令,涵盖视觉条件、对象类型和规模的各种变化。我们评估了几种最先进的 VLM,以评估它们在地理空间背景下的准确性。
The results indicate that although existing VLMs demonstrate potential, they face challenges when dealing with geospatial-specific examples, highlighting the room for further improvements.
结果表明,尽管现有的 VLM 表现出了潜力,但它们在处理特定于地理空间的示例时面临挑战,凸显了进一步改进的空间。
Specifically, the best-performing GPT4o achieves only 40% accuracy on MCQs, which is only double the random guess performance. Our benchmark is publicly available at https://github.com/The-AI-Alliance/GEO-Bench-VLM.
具体来说,性能最好的 GPT4o 在 MCQ 上仅达到 40% 的准确率,这只是随机猜测性能的两倍。我们的基准测试可在https://github.com/The-AI-Alliance/GEO-Bench-VLM上公开获取。

零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码或者点击以下链接都可以免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









