







前言
环境使用
- Python 3.8
- Pycharm
模块使用
- import requests —> 数据请求模块 pip install requests
- import parsel —> 数据解析模块 pip install parsel
- from selenium import webdriver —> 自动测试模块 pip install selenium==3.141.0
本次案例代码实现思路:
- 打开考试网站
- selenium --> 浏览器驱动 --> 操作浏览器 <模拟人的行为做操作浏览器>
- 获取答案
- 获取答案网站链接
- 获取问题以及答案内容
- 对比题目以及答案 选出正确答案
- 获取问题答案选项
- 和正确的答案进行对比
- 如果正确答案和选择答案一致, 那就进行点击
- 进行点击答题
最终效果
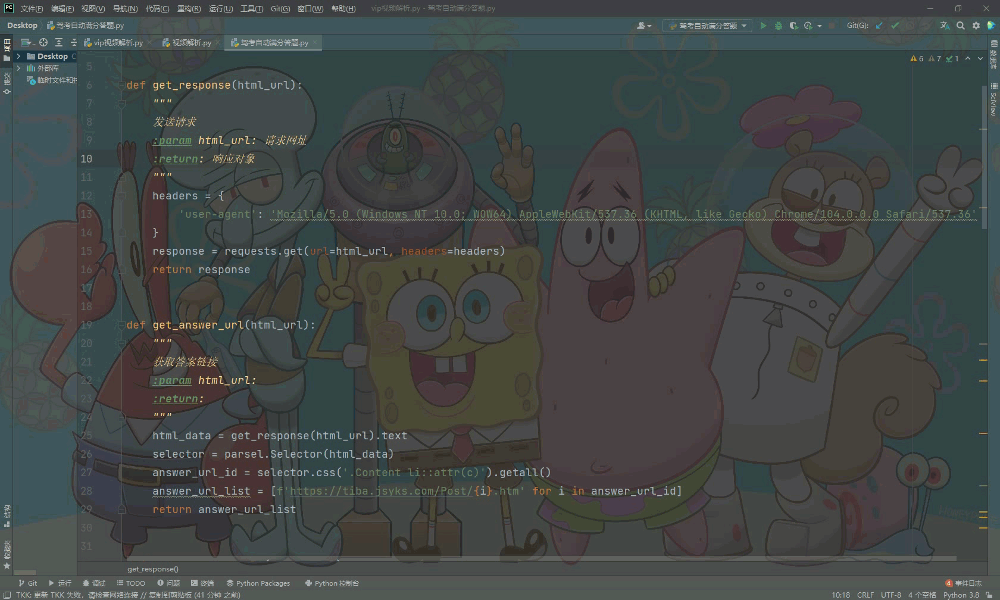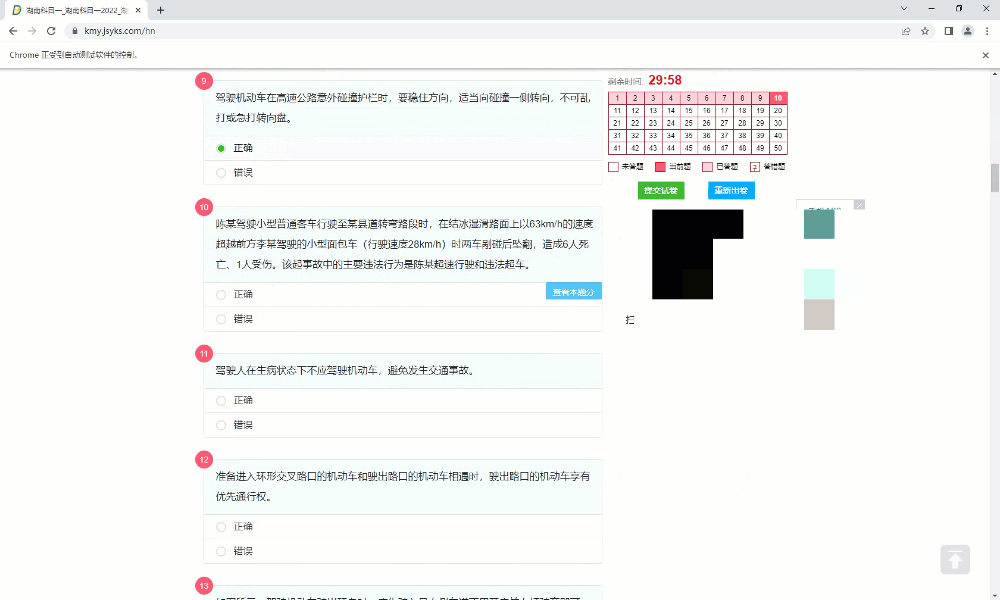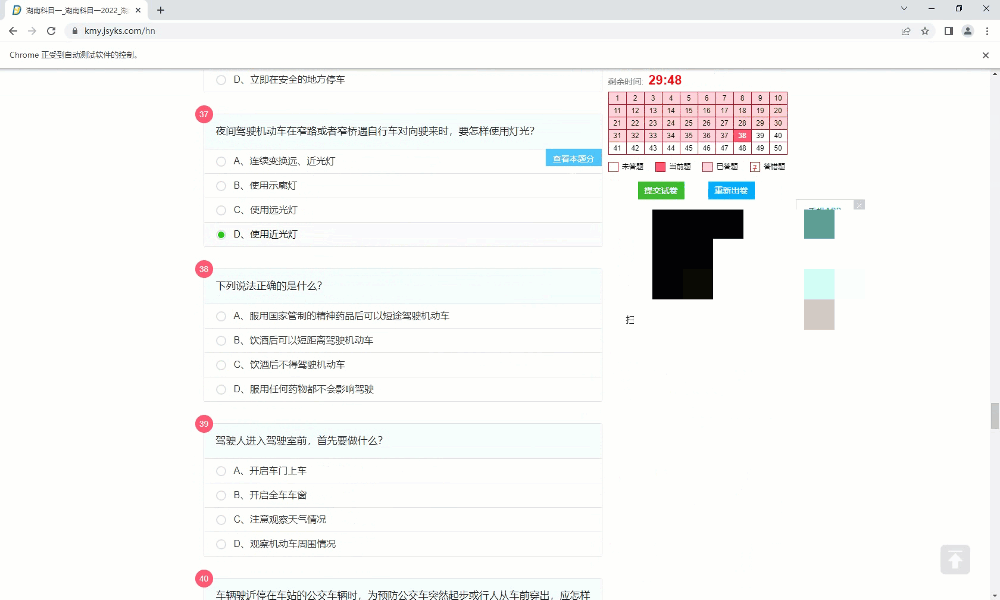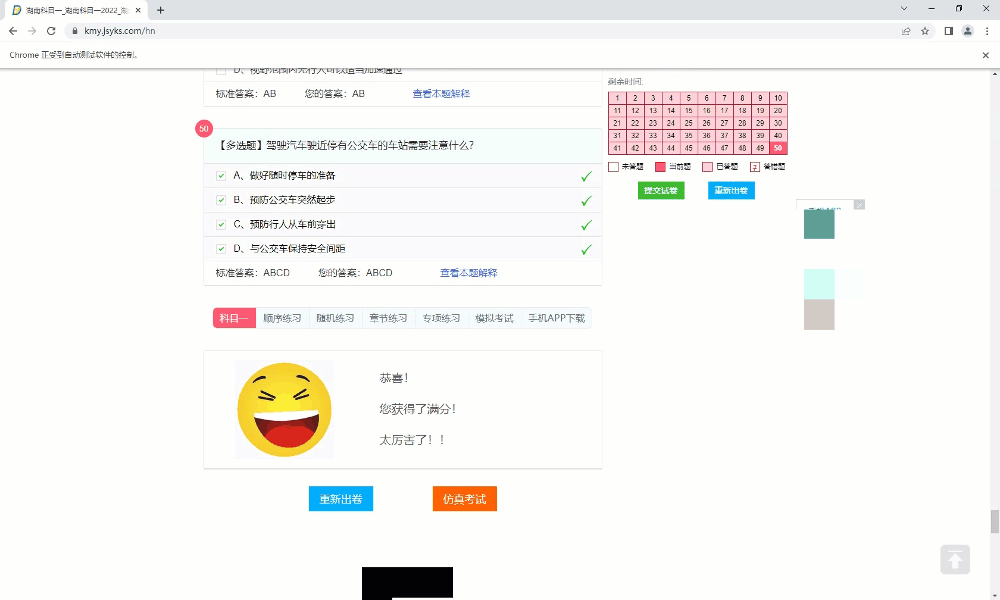
导入模块
from selenium import webdriver
# 导入数据请求模块
import requests
# 导入数据解析模块
import p 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2155
2155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









