







咱们今天继续学习 Pandas,开始之前,先回顾一下一个数据分析过程中,第一步,你需要先拿到你的数据。

这里就涉及到复杂情况:
-
单来源数据读入,可能是 csv 、 excel 、也可能是 json 文件
-
多来源多数据文件读入,或许是收集回来的多份文件,需要合并处理
这些情况,巧了,Pandas非常擅长。它在数据读取和数据合并方面具有以下优势。
-
灵活:Pandas 支持多种数据源的读取,包括 CSV、Excel、SQL 数据库、JSON 等,几乎涵盖了所有常见的数据格式。
-
合并功能强大:Pandas 提供了多种数据合并的方法,如
merge()和concat(),支持内连接、外连接、左连接和右连接等多种连接方式,可以满足各种复杂的数据合并需求。 -
性能高效:Pandas 底层使用 C 语言编写,提供了高效的数据处理能力,特别是在处理大型数据集时,性能优势明显。
接下来,俩部分咱分开来聊。
01
数据读取
1. 读取 CSV 文件
import pandas as pd# 读取CSV文件df = pd.read_csv('path_to_file.csv')# 显示前几行数据print(df.head())
2. 读取 Excel 文件
# 读取Excel文件,指定sheetdf = pd.read_excel('path_to_file.xlsx', sheet_name='Sheet1')# 显示前几行数据print(df.head())
3. 读取 SQL 数据库
# 需要安装 sqlalchemy 库import sqlalchemy as safrom sqlalchemy import create_engine# 创建数据库引擎engine = create_engine('mysql+pymysql://user:password@host:port/dbname')# 读取数据df = pd.read_sql('SELECT * FROM table_name', engine)# 显示前几行数据print(df.head())
4. 读取 JSON 文件
# 读取JSON文件df = pd.read_json('path_to_file.json')# 显示前几行数据print(df.head())
02
数据合并
先导知识,Pandas库提供了两种基础的数据格式:DataFrame和Series,它们是进行数据分析时最常用的数据结构。
忘记的小伙伴,可以点击这篇文章,快速回顾:
1. 按索引合并
# 假设df1和df2是已经存在的DataFramedf1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})df2 = pd.DataFrame({'A': [3, 4, 5], 'B': [6, 7, 8]})# 按索引合并merged_df = pd.concat([df1, df2], ignore_index=True)print(merged_df)
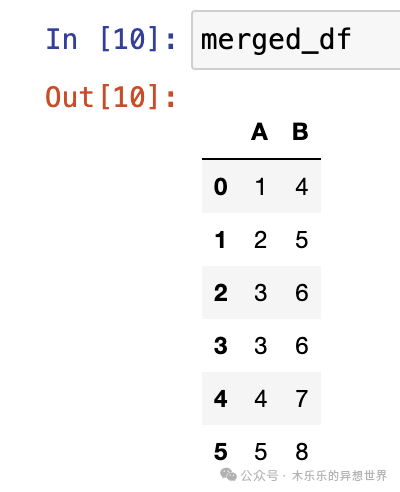
2. 按列合并
# 按列合并,使用外连接merged_df = pd.merge(df1, df2, on='A', how='outer')print(merged_df)
3. 连接数据
# 纵向连接concatenated_df = pd.concat([df1, df2], axis=0)# 横向连接concatenated_df = pd.concat([df1, df2], axis=1, join='inner')print(concatenated_df)
4. 更新数据
# 更新数据,df1中的更新会覆盖df2中的相同键的值updated_df = df1.update(df2)print(updated_df)
案例:合并两个数据集
假设我们有两个数据集,一个是客户信息,另一个是客户的购买记录。
客户信息数据集
| CustomerID | Name |
|---|---|
| 1 | Alice |
| 2 | Bob |
购买记录数据集
| PurchaseID | CustomerID | Amount |
|---|---|---|
| 1 | 1 | 50.00 |
| 2 | 2 | 20.00 |
| 3 | 1 | 30.00 |
合并数据集
# 客户信息customers = pd.DataFrame({'CustomerID': [1, 2],'Name': ['Alice', 'Bob']})# 购买记录purchases = pd.DataFrame({'PurchaseID': [1, 2, 3],'CustomerID': [1, 2, 1],'Amount': [50.00, 20.00, 30.00]})# 按CustomerID合并数据集merged_data = pd.merge(customers, purchases, on='CustomerID')print(merged_data)
输出结果将是:
复制
CustomerID Name PurchaseID Amount
0 1 Alice 1 50.00
1 1 Alice 3 30.00
2 2 Bob 2 20.00
好的,简单小结一下,今天给大家介绍了 Pandas 用于数据读取和合并的函数。后续,会有其他的专栏文章,对 Pandas的数据清洗、转换、分组、聚合等复杂操作进行专项讲解。
感兴趣的小伙伴,欢迎关注、点赞、评论转发。您的每一份互动,都是我肝下去的动力。















 928
928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









