






人的一生,无法避开的是死亡和税收。如果你是数据分析师,那得再加一个,数据可视化。
数据可视化是传达信息和辅助读者理解数据的关键。传统的 python 可视化库虽然功能强大,但需要编写大量代码,对那些代码不是很娴熟的业务型数据分析师来说,非常不友好。
今天要介绍的 PygWalker,是一个基于jupyter notebook应用的开源的数据可视化工具。它可以极大的简化数据可视化分析工作流。
重点是!几乎 0 代码,你准备好了数据后,一行代码就可以将 DataFrame 转化成可交互式的分析界面。
通过简单的拖拉拽和自然语言,进行数据可视化。 支持的图标也比较多,即有基础的条形图、折线图,还有复杂的热力图,散点图。
接下来,简单介绍一下PygWalker 的使用方法。你需要提前安装好的有 Jupyter Notebook 软件,提前安装好 pandas、 numpy等用于数据预处理 的包。因为不是本次的介绍重点,故不展开陈述。
一、安装和初始化
使用 pip 指令安装 PygWalker 。
pip install pygwalker快速入门,导入 PygWalke 并创建一个可视化界面。
这里,我模拟了一些虚拟销售数据,方便大家可以拷贝代码,快速上手。
这份数据包含了几个字段,Region 地区;Product 产品;Sales 销量;Date 日期;
import pandas as pdimport numpy as np# 创建虚拟销售数据np.random.seed(0)data = {'Region': np.random.choice(['North', 'South', 'East', 'West'], 100),'Product': np.random.choice(['A', 'B', 'C', 'D'], 100),'Sales': np.random.randint(100, 1000, 100),'Date': pd.date_range(start='1/1/2021', periods=100)}df_sales = pd.DataFrame(data)
接下来,导入 PygWalker,并创建可视化界面。见证奇迹的时刻到了!
import pygwalker as pyggwalker = pyg.walk(df_sales)
df_sales 是我们刚才虚拟的 dataframe,只需要导入这个包,然后引用 pyg.walk 函数,函数输入填入你需要进行可视化的 dataframe,就Ok 了。
二、核心操作指南
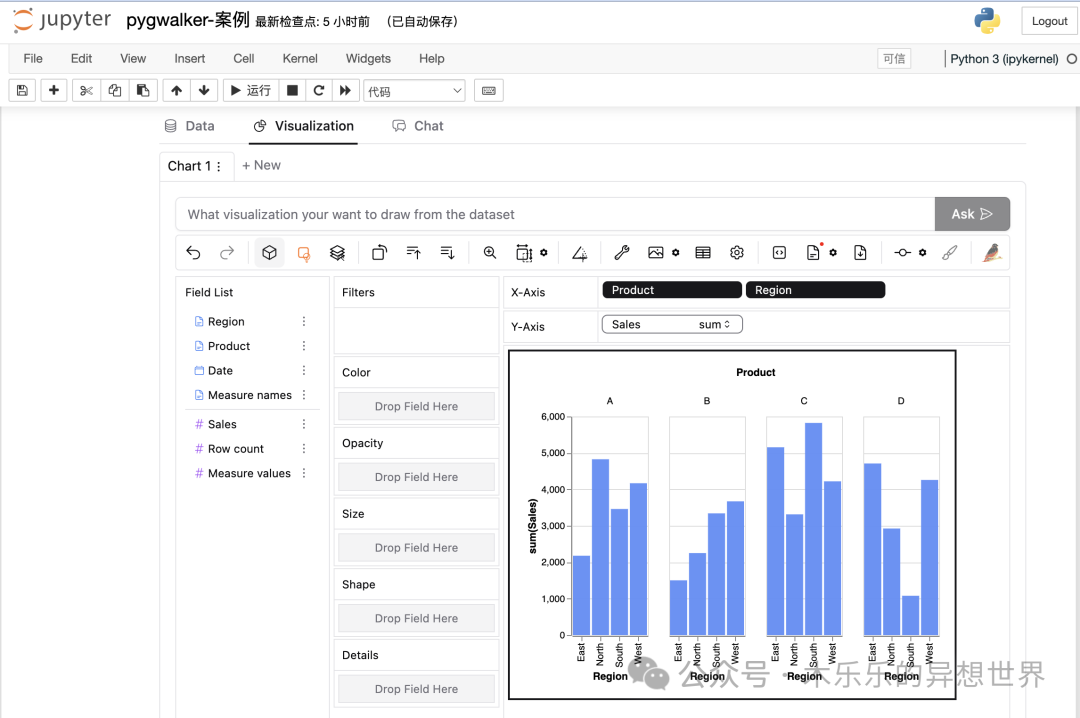
执行完 gwalker = pyg.walk(df_sales) 这个代码,系统展示的是一个空白的可视化页面。我截图展示的,是一个简单的案例。在使用前,我必须要先给大家介绍一些关键按钮和操作方式。
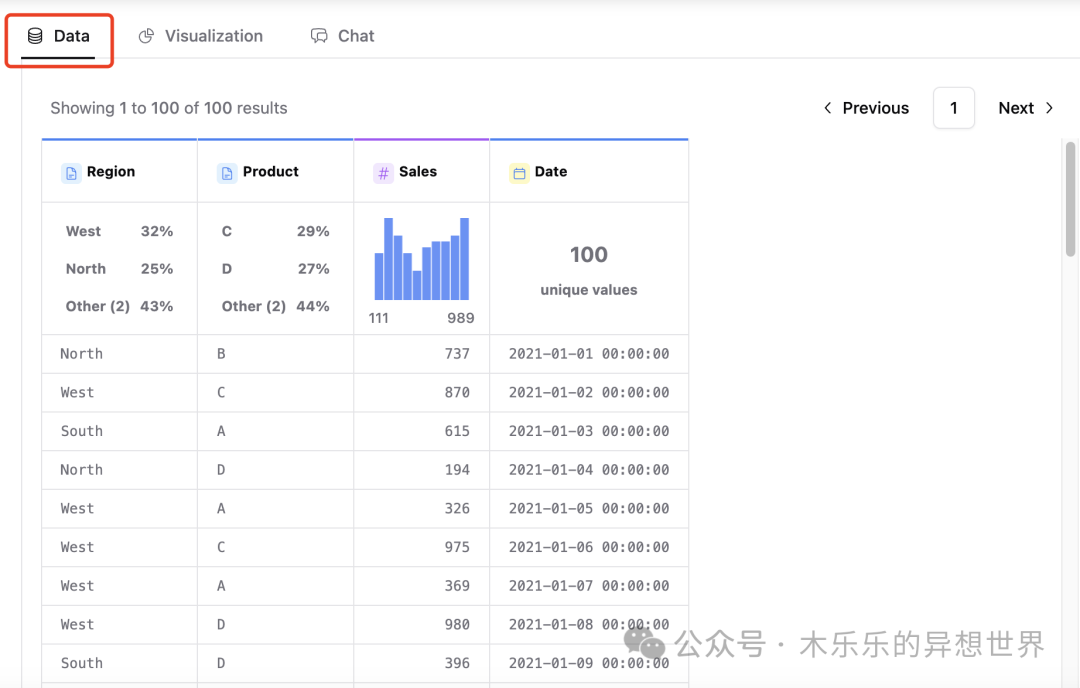
1 、数据概览
点击 Data,可以看到你导入的 dataframe 各个字段的描述性统计。
2 、可视化主界面
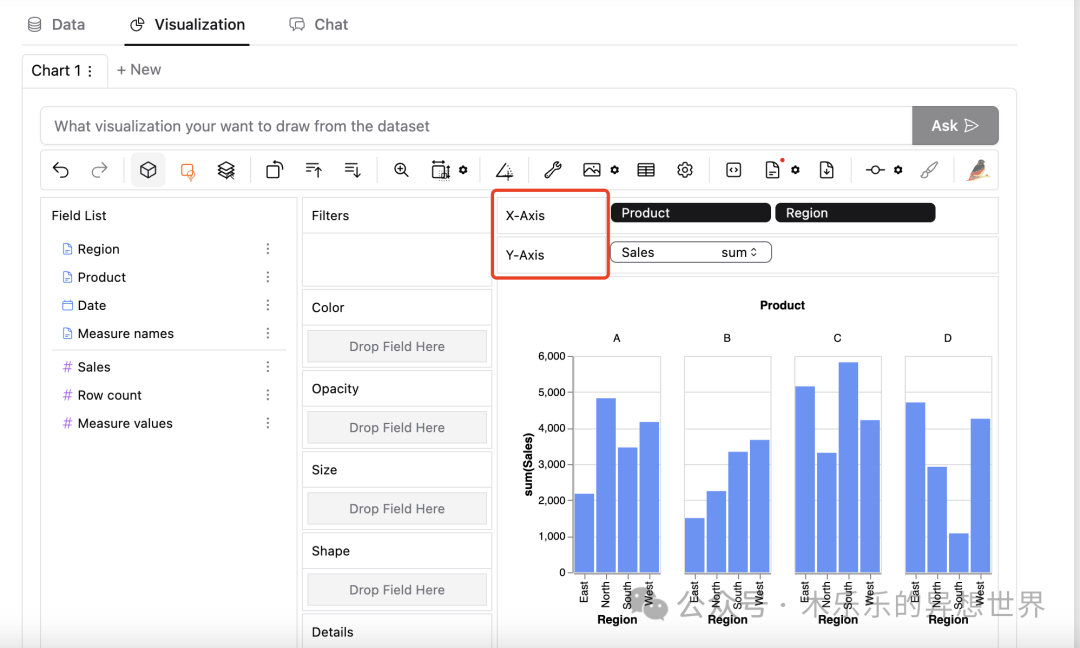
你需要配置的可视化图标的 x轴和 y 轴。只需要拉着左侧 Field List 里的字段到 X-Axis 和 Y-Axis 位置处,就Ok 了。其中,如果需要拆分多个图标进行横向对比,或者纵向对比,则可以在对应的位置增加变量。
下面这个图里,我想分开看A 、 B 、 C 、 D 四个产品在各区域内的销售表现。所以,在 X-Axis 里,我拉入了两个变量,分别是Product和 Region。纵坐标则拖入的是 Sales 。
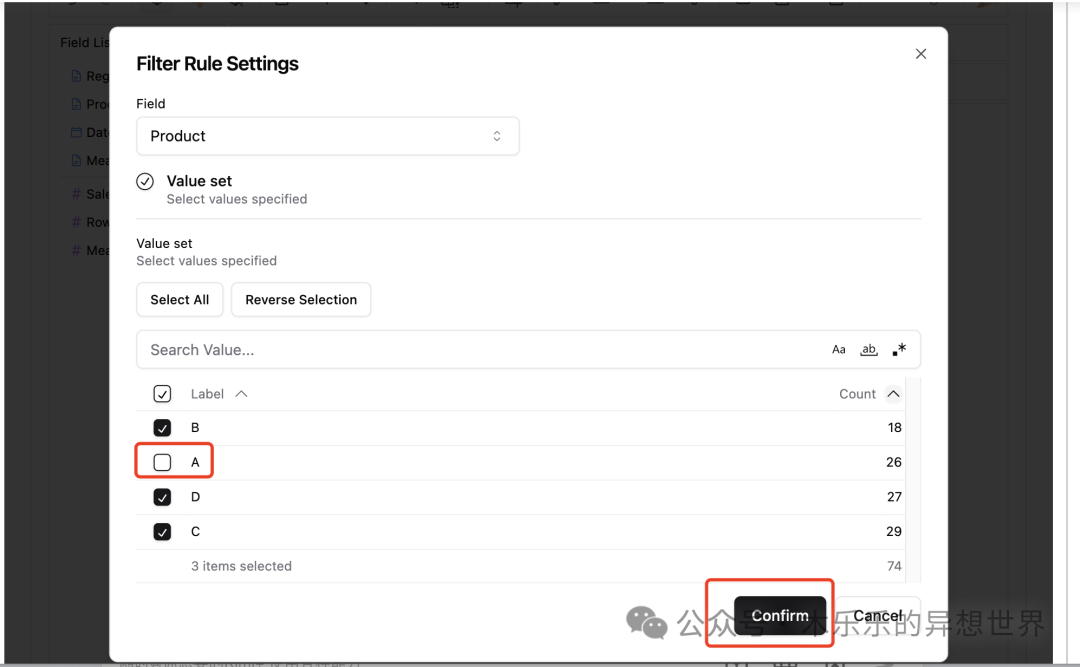
如果要限制不看指定的商品数据,可以通过 Filters 筛选剔除数据。
把待筛选的字段 Product 拖入 Filters 区域;
然后,勾选不需要看的商品 A ,就可以完成了数据筛选限制展示。
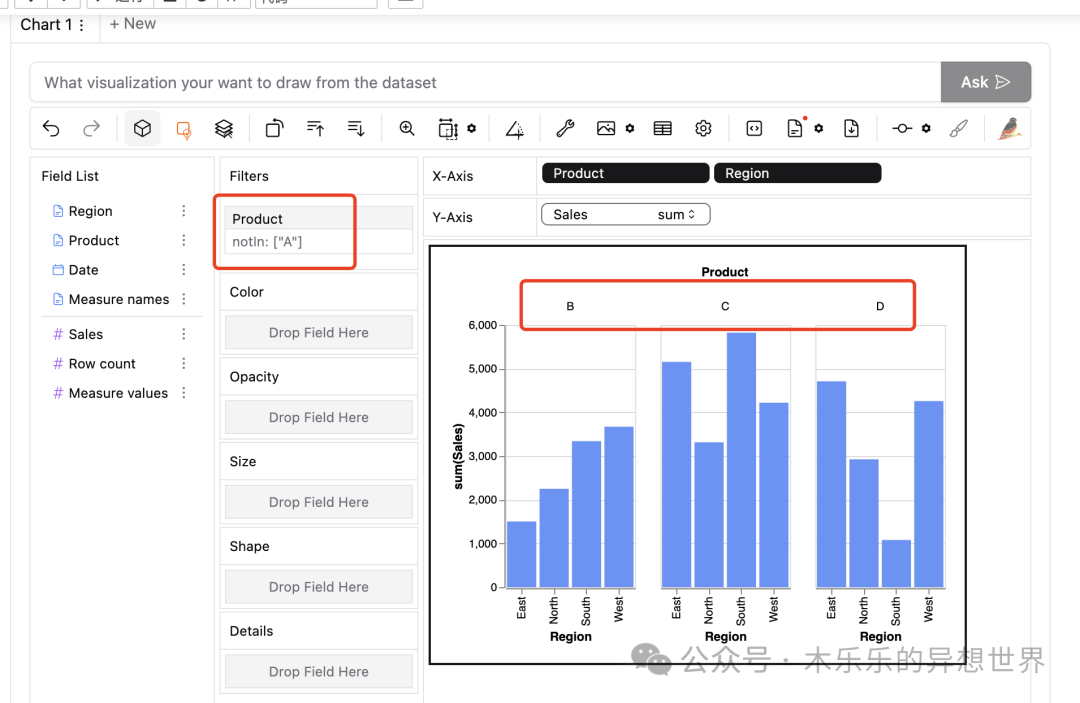
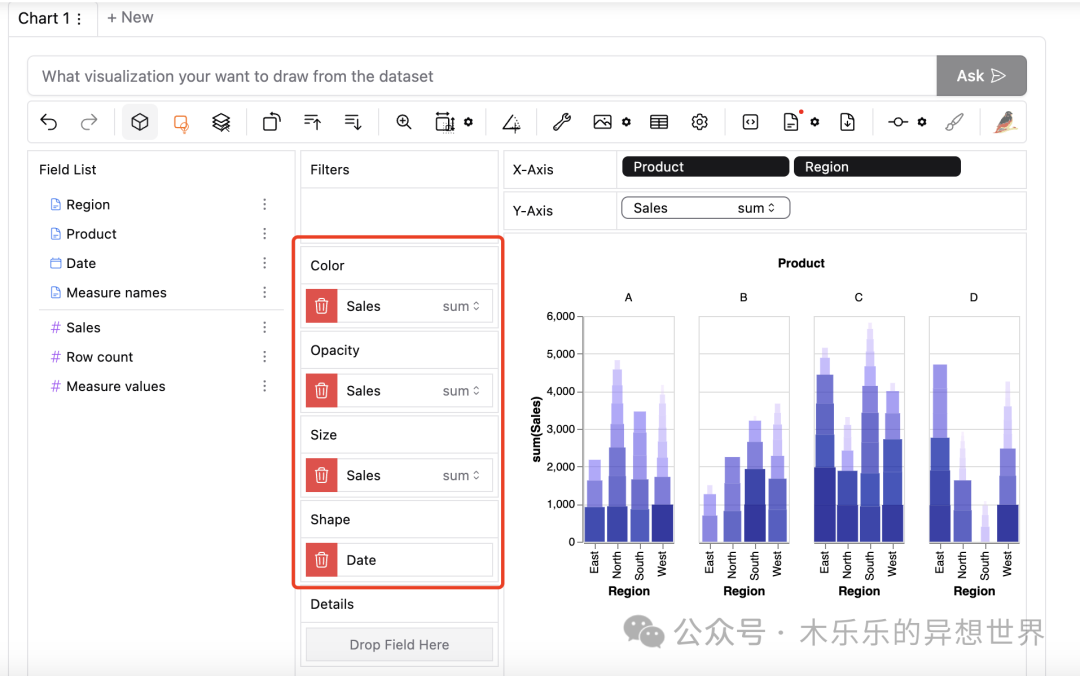
同样的,如果需要按照不同的信息设置颜色Color、透明度 Opacity、大小 Size 、形状 Shape 和展示数据细节 Details,则往下看。
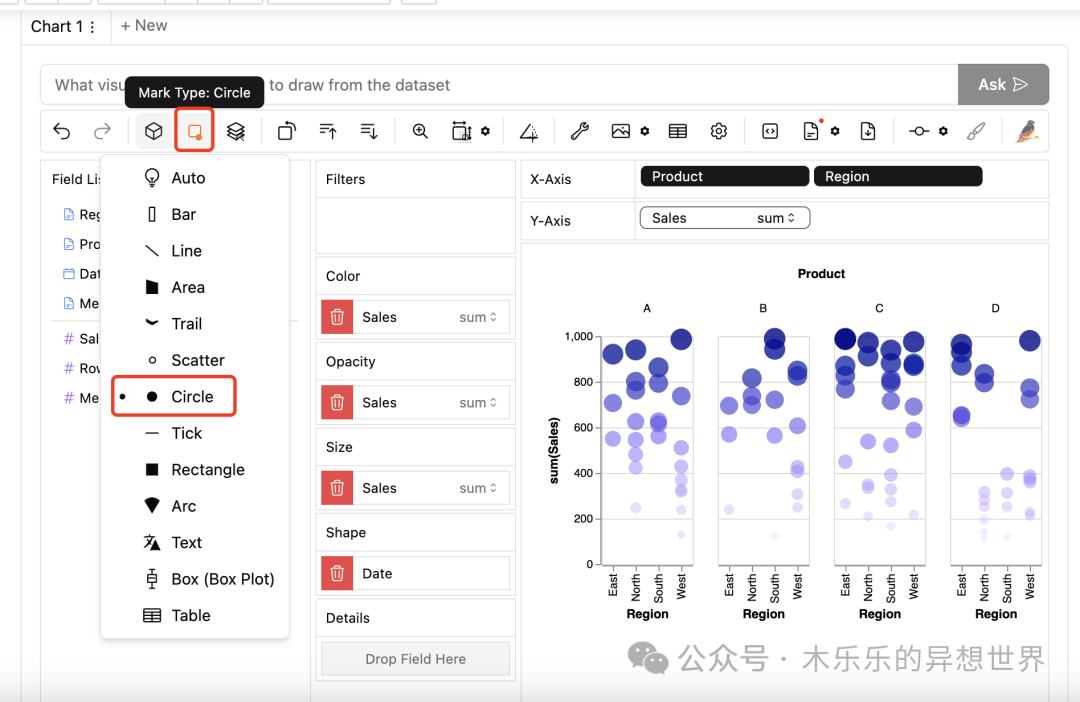
3 、配置需要展示的可视化类型
点Mark Type,可以自由选择需要展示的可视化形式,可以是柱形图 Bar 、折线图 Line 、散点图 Scatter 等。
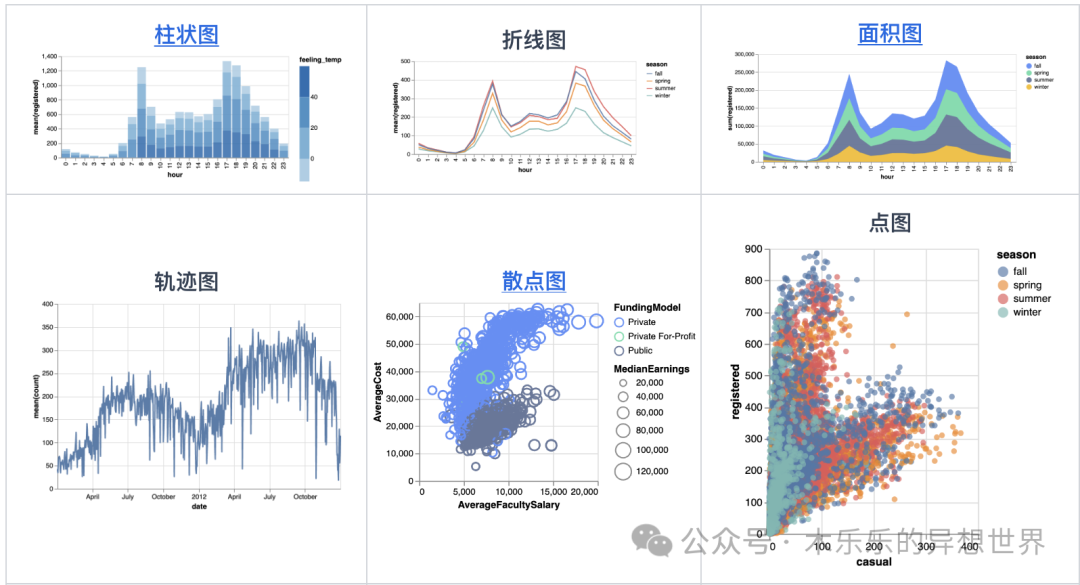
除此之外,还能画哪些类型的图呢?附上官网教程里的文档链接,感兴趣的可以点击探索。
传送门:https://docs.kanaries.net/zh/graphic-walker/data-viz/create-data-viz
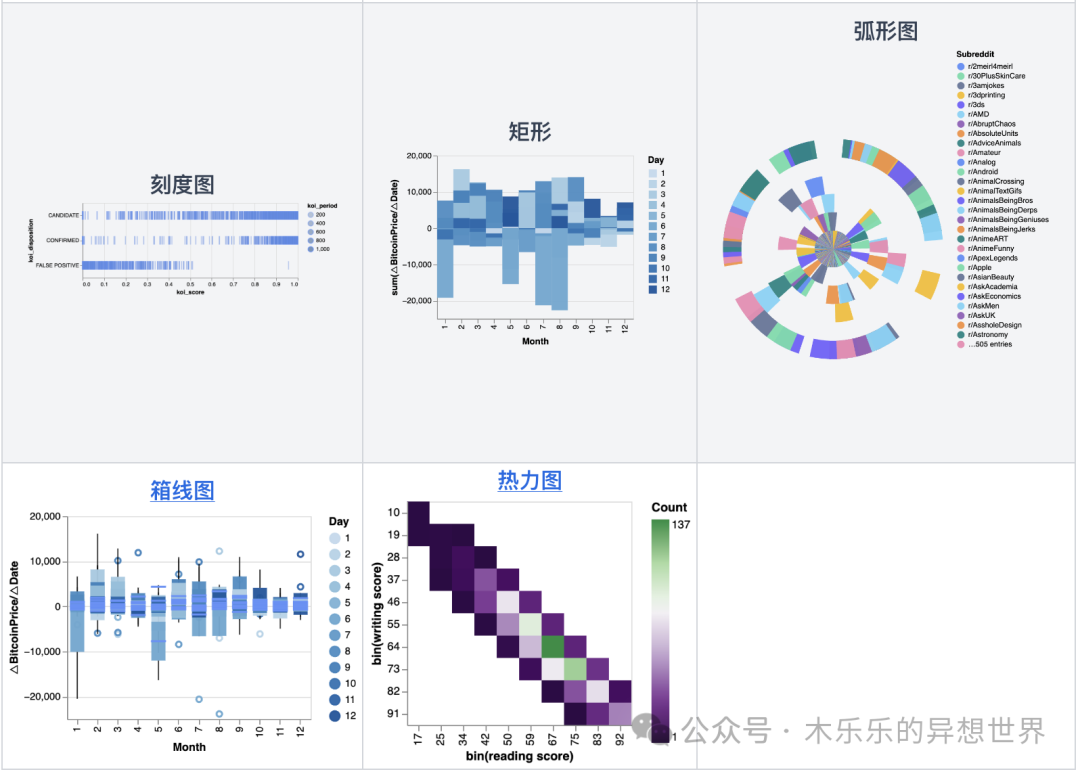
好的,极简 PygWalker 入门指引写完了。因为篇幅原因,还有很多强大的功能未能一一介绍,比如橡皮擦(清除异常数据)、保存可视化探索结果数据,再次导入做二次应用等。
正所谓,知识虽宝贵,但实践更无价。一起探索吧。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









