






在众多前沿成果都不再透露技术细节之际,Stable Diffusion 3 论文的发布显得相当珍贵。
Stable Diffusion 3 的论文终于来了!
这个模型于两周前发布,采用了与 Sora 相同的 DiT(Diffusion Transformer)架构,一经发布就引起了不小的轰动。
与之前的版本相比,Stable Diffusion 3 生成的图在质量上实现了很大改进,支持多主题提示,文字书写效果也更好了(明显不再乱码)。
Stability AI 表示,Stable Diffusion 3 是一个模型系列,参数量从 800M 到 8B 不等。这个参数量意味着,它可以在很多便携式设备上直接跑,大大降低了 AI 大模型的使用门槛。
在最新发布的论文中,Stability AI 表示,在基于人类偏好的评估中,Stable Diffusion 3 优于当前最先进的文本到图像生成系统,如 DALL・E 3、Midjourney v6 和 Ideogram v1。不久之后,他们将公开该研究的实验数据、代码和模型权重。

在论文中,Stability AI 透露了关于 Stable Diffusion 3 的更多细节。

-
论文标题:Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
-
论文链接:https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf
架构细节
对于文本到图像的生成,Stable Diffusion 3 模型必须同时考虑文本和图像两种模式。因此,论文作者称这种新架构为 MMDiT,意指其处理多种模态的能力。与之前版本的 Stable Diffusion 一样,作者使用预训练模型来推导合适的文本和图像表征。具体来说,他们使用了三种不同的文本嵌入模型 —— 两种 CLIP 模型和 T5—— 来编码文本表征,并使用改进的自编码模型来编码图像 token。
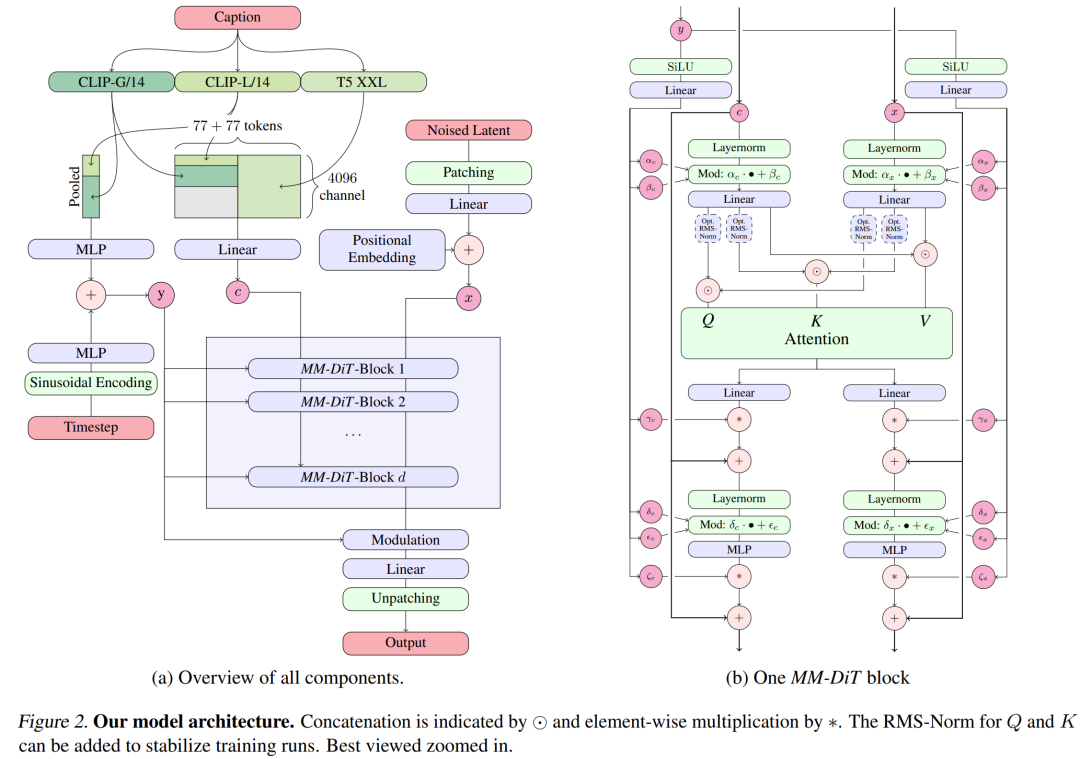
Stable Diffusion 3 模型架构。
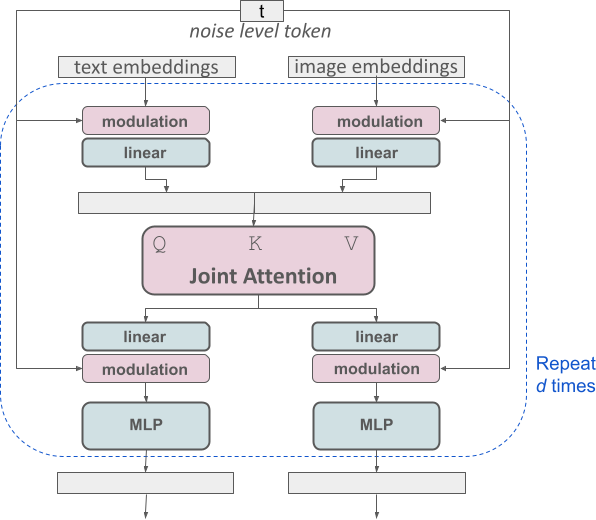
_改进的多模态扩散 transformer:MMDiT 块。
_
SD3 架构基于 Sora 核心研发成员 William Peebles 和纽约大学计算机科学助理教授谢赛宁合作提出的 DiT。由于文本嵌入和图像嵌入在概念上有很大不同,因此 SD3 的作者对两种模态使用两套不同的权重。如上图所示,这相当于为每种模态设置了两个独立的 transformer,但将两种模态的序列结合起来进行注意力运算,从而使两种表征都能在各自的空间内工作,同时也将另一种表征考虑在内。
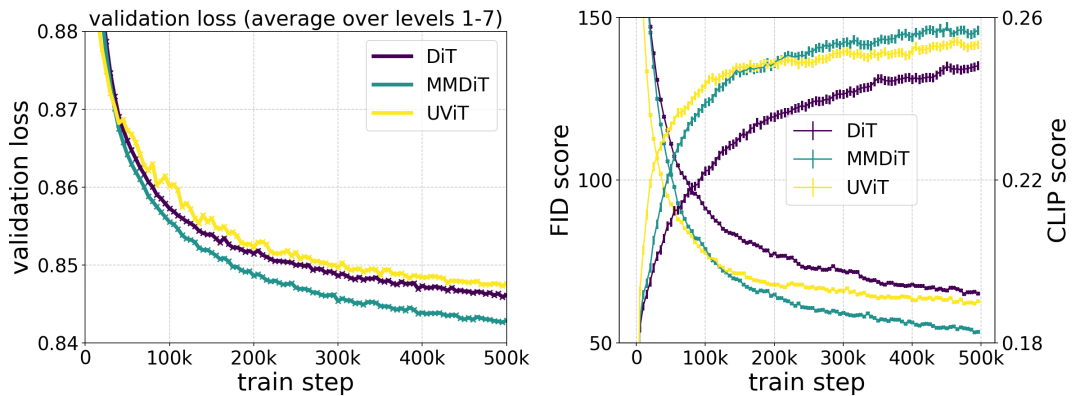
在训练过程中测量视觉保真度和文本对齐度时,作者提出的 MMDiT 架构优于 UViT 和 DiT 等成熟的文本到图像骨干。
通过这种方法,信息可以在图像和文本 token 之间流动,从而提高模型的整体理解能力,并改善所生成输出的文字排版。正如论文中所讨论的那样,这种架构也很容易扩展到视频等多种模式。

得益于 Stable Diffusion 3 改进的提示遵循能力,新模型有能力制作出聚焦于各种不同主题和质量的图像,同时还能高度灵活地处理图像本身的风格。

通过 re-weighting 改进 Rectified Flow
Stable Diffusion 3 采用 Rectified Flow(RF)公式,在训练过程中,数据和噪声以线性轨迹相连。这使得推理路径更加平直,从而减少了采样步骤。此外,作者还在训练过程中引入了一种新的轨迹采样计划。他们假设,轨迹的中间部分会带来更具挑战性的预测任务,因此该计划给予轨迹中间部分更多权重。他们使用多种数据集、指标和采样器设置进行比较,并将自己提出的方法与 LDM、EDM 和 ADM 等 60 种其他扩散轨迹进行了测试。结果表明,虽然以前的 RF 公式在少步采样情况下性能有所提高,但随着步数的增加,其相对性能会下降。相比之下,作者提出的重新加权 RF 变体能持续提高性能。
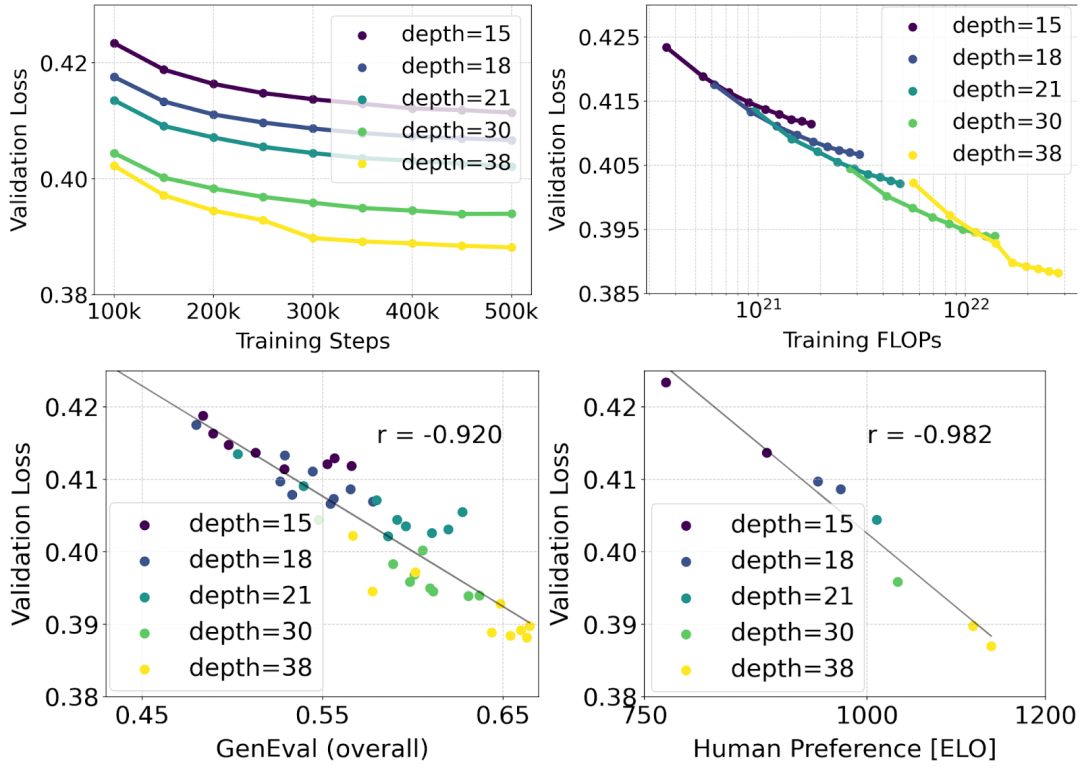
扩展 Rectified Flow Transformer 模型
作者利用重新加权的 Rectified Flow 公式和 MMDiT 骨干对文本到图像的合成进行了扩展(scaling)研究。他们训练的模型从带有 450M 个参数的 15 个块到带有 8B 个参数的 38 个块不等,并观察到验证损失随着模型大小和训练步骤的增加而平稳降低(上图的第一行)。为了检验这是否转化为对模型输出的有意义改进,作者还评估了自动图像对齐指标(GenEval)和人类偏好分数(ELO)(上图第二行)。结果表明,这些指标与验证损失之间存在很强的相关性,这表明后者可以很好地预测模型的整体性能。此外,scaling 趋势没有显示出饱和的迹象,这让作者对未来继续提高模型性能持乐观态度。
灵活的文本编码器
通过移除用于推理的内存密集型 4.7B 参数 T5 文本编码器,SD3 的内存需求可显著降低,而性能损失却很小。如图所示,移除该文本编码器不会影响视觉美感(不使用 T5 时的胜率为 50%),只会略微降低文本一致性(胜率为 46%)。不过,作者建议在生成书面文本时加入 T5,以充分发挥 SD3 的性能,因为他们观察到,如果不加入 T5,生成排版的性能下降幅度更大(胜率为 38%),如下图所示:

_只有在呈现涉及许多细节或大量书面文本的非常复杂的提示时,移除 T5 进行推理才会导致性能显著下降。上图显示了每个示例的三个随机样本。
_
模型性能
作者将 Stable Diffusion 3 的输出图像与其他各种开源模型(包括 SDXL、SDXL Turbo、Stable Cascade、Playground v2.5 和 Pixart-α)以及闭源模型(如 DALL-E 3、Midjourney v6 和 Ideogram v1)进行了比较,以便根据人类反馈来评估性能。在这些测试中,人类评估员从每个模型中获得输出示例,并根据模型输出在多大程度上遵循所给提示的上下文(prompt following)、在多大程度上根据提示渲染文本(typography)以及哪幅图像具有更高的美学质量(visual aesthetics)来选择最佳结果。
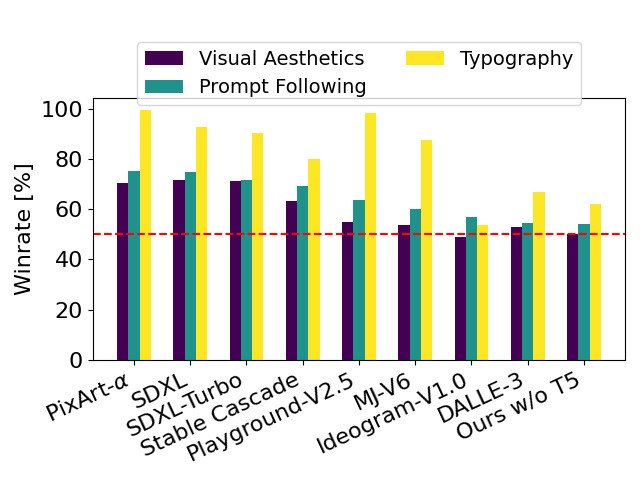
以 SD3 为基准,这个图表概述了它在基于人类对视觉美学、提示遵循和文字排版的评估中的胜率。
从测试结果来看,作者发现 Stable Diffusion 3 在上述所有方面都与当前最先进的文本到图像生成系统相当,甚至更胜一筹。
在消费级硬件上进行的早期未优化推理测试中,最大的 8B 参数 SD3 模型适合 RTX 4090 的 24GB VRAM,使用 50 个采样步骤生成分辨率为 1024x1024 的图像需要 34 秒。

此外,在最初发布时,Stable Diffusion 3 将有多种变体,从 800m 到 8B 参数模型不等,以进一步消除硬件障碍。


AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









