






本文介绍了如何通过火山引擎持续交付的 AI 应用功能,完全屏蔽 Kubernetes 底层细节,一键拉起 Stable Diffusion 模型,轻松拥有属于自己的 AI 应用。
近年来,AI 技术发展迅猛,深度学习、自然语言处理、计算机视觉等领域取得了突破性进展。AI 已在各行各业中广泛应用,如智能客服、智能驾驶、智慧城市等,越来越多的企业和组织希望将 AI 应用落地到实际业务中。
在 AI 绘画领域,Stable Diffusion 当仁不让成为开源社区中最具影响力的核心模型,让 AIGC 的 ToC 可能性比肩移动互联网的产品,每个人都可以近距离接触和使用 AI。
Stable Diffusion 主要用于根据文本的描述产生详细图像,也就是 Texttoimage 的场景。通过给定文本提示词,生成一张匹配提示词的图片。例如输入文本提示词『a cute cat』,Stable Diffusion 会生成可爱猫咪的图片。
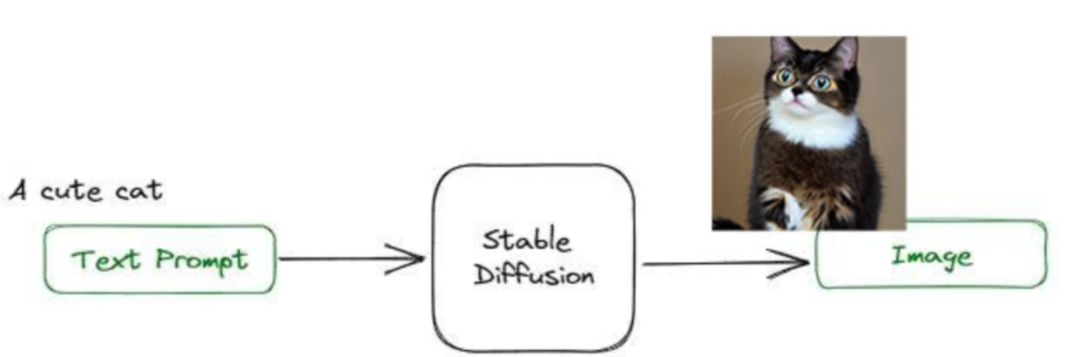
自 2023 年推出至今,Stable Diffusion 已吸引了大量用户前往 Stability AI 等网站进行体验,但考虑到外网访问不够便捷、数据隐私等问题,部署一个自己的 Stable Diffusion 成了越来越多用户的选择。
因此从去年开始,业界出现了海量关于如何部署 Stable Diffusion 的教程。本文将介绍一种全新的企业级方案——通过持续交付 CP 实现 5 分钟拉起 Stable-Diffusion-WebUI 服务。
AI 模型的开发部署困境
在此前火山引擎云原生团队推出的《如何在火山引擎云上部署 Stable Diffusion》中,我们为用户提供部署 Stable Diffusion 的操作手册,但这种方案更多的是一种最佳实践,并没有提供封装的、更完善的产品化能力,仍然需要用户对 AI、对云原生有更深的理解。
AI 模型的开发和部署是系统工程,用户经常会遇到以下问题:
环境搭建:根据 AI 模型的硬件和软件依赖,开发人员需要部署模型所需的运行环境,例如 CPU/GPU、操作系统、驱动、CUDA、常用框架 Python/PyTorch/Tensorflow 等。采购资源、处理硬件/软件兼容性问题、调试不同版本组合的性能问题会消耗开发人员大量时间;
模型部署:如果采用传统主机部署方式,每次模型升级、部署变更或主机迁移,都需要人工介入服务器的应用部署,开发人员需要经常处理过程中出现的依赖库丢失和不兼容等问题;
服务编排:使用传统主机和容器部署 AI 应用,容易出现资源配置不当、服务拓扑设计不合理等问题,导致模型优化效果不理想、推理延迟高;
服务外部访问:如果需要将 AI 应用暴露接口给集群内其他服务访问,或者用户可以直接通过浏览器访问服务,开发人员需要了解如何申请公网访问、配置负载均衡等网络知识和技能。
对于不熟悉云计算基础设施的用户,上述学习成本无疑会阻碍用户进一步体验最新的 AI。而对于企业级用户,在 AI 技术火爆的今天,随着内部流水线数量急剧增加,企业也希望能将工程师从繁重的 DevOps 工程中解放出来,聚焦于业务开发、敏捷响应市场需求和引入学界创新。
AI 应用:内置模板,一键拉起
针对这些问题,火山引擎云原生团队在持续交付 CP(Code Pipeline)中推出了应用交付全新能力:AI 应用。它主要包含以下功能:
-
预置模版:集成了主流的 AI 框架,包括 Stable Diffusion ComfyUI、Stable Diffusion WebUI、LLaMa Factory、Triton、PyTorch 等,封装了操作系统、AI 框架、依赖库等应用环境,可以帮助用户快速部署 AI 应用,降低开发难度;
-
支持 Serverless:支持对接火山引擎弹性容器实例 VCI,提供全托管、免运维的运行环境;
-
服务访问:集成了火山引擎 API 网关 APIG 和负载均衡 CLB,支出用户一键配置 AI 应用的外部访问能力;
-
一键回滚:提供可追溯的变更历史管理,帮助用户可以快速回滚到指定版本;
-
弹性伸缩:支持用户手动配置水平自动扩缩容,和基于资源使用率的自动扩缩容,显著提升算力资源利用率。

通过使用 AI 应用,用户可以完全屏蔽 Kubernetes 底层细节,轻松拥有属于自己的 AI 应用。下面我们以 Stable Diffusion 为例,演示如何在 5 分钟内快速拉起模型。
实战:5 分钟拉起 Stable Diffusion
前置准备
-
准备一个 VKE 集群,并已安装 csi-tos 和 nvidia-device-plugin 组件:https://www.volcengine.com/docs/6460/101014;
-
通过制品仓库创建仓库实例,同时存放 Stable Diffusion 模型和文生图的输出文件 ,演示使用模型为 stable-diffusion-v1-5 模型;
-
点击控制台右上角头像创建 API 访问秘钥,用于应用读取制品仓库模型文件;
-
创建 API 网关实例,选择标准网关:https://www.volcengine.com/docs/6569/85693。
部署 Stable-Diffusion-WebUI 服务
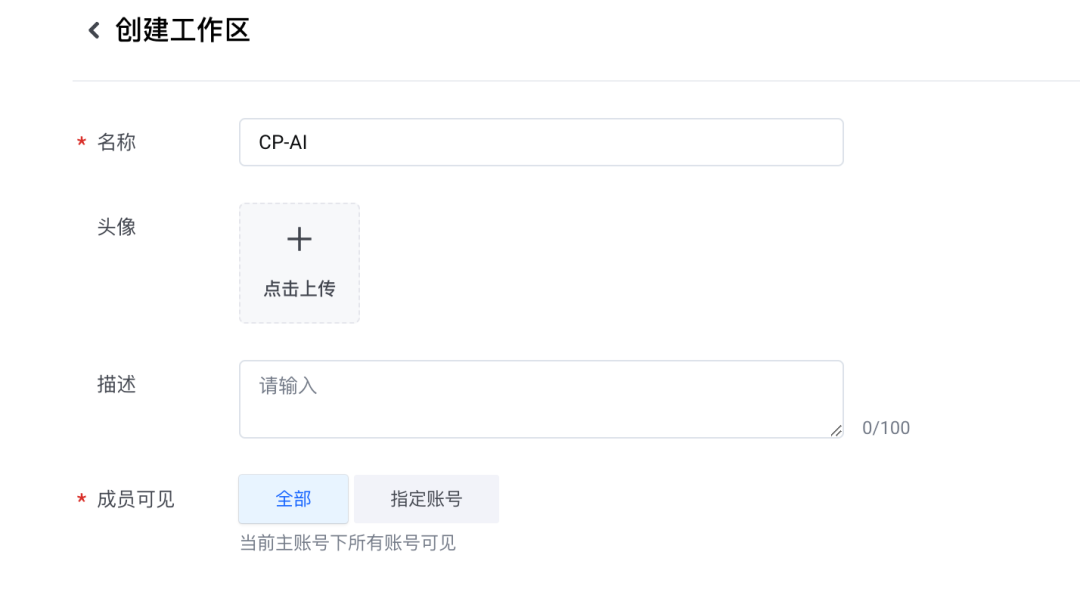
1. 首先,登录持续交付 CP 控制台:https://console.volcengine.com/cp/v2/overview,点击【创建工作区】,为工作区取一个名称,并指定工作区的成员列表。
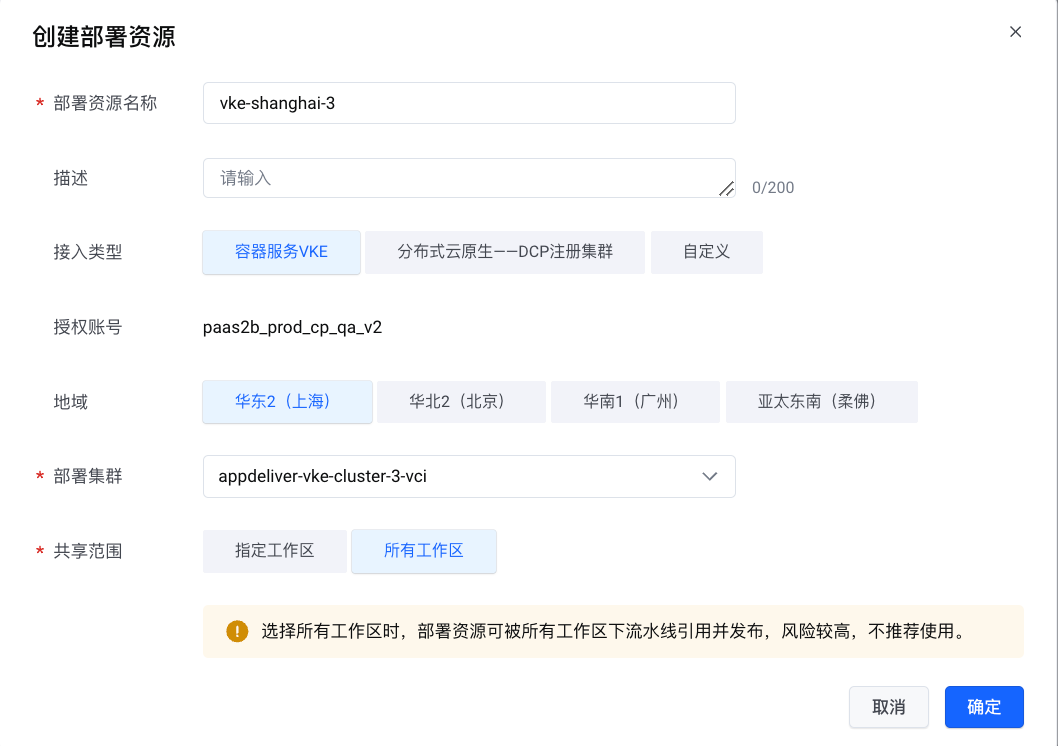
2. 打开【资源管理】-【Kubernetes 集群】页面,点击【创建部署资源】,导入 VKE 集群,并可以指定集群共享的工作区列表。
3. 进入创建的工作区,在【应用管理】页面点击【创建应用】,并选择【AI 应用】,开始配置我们的应用信息。
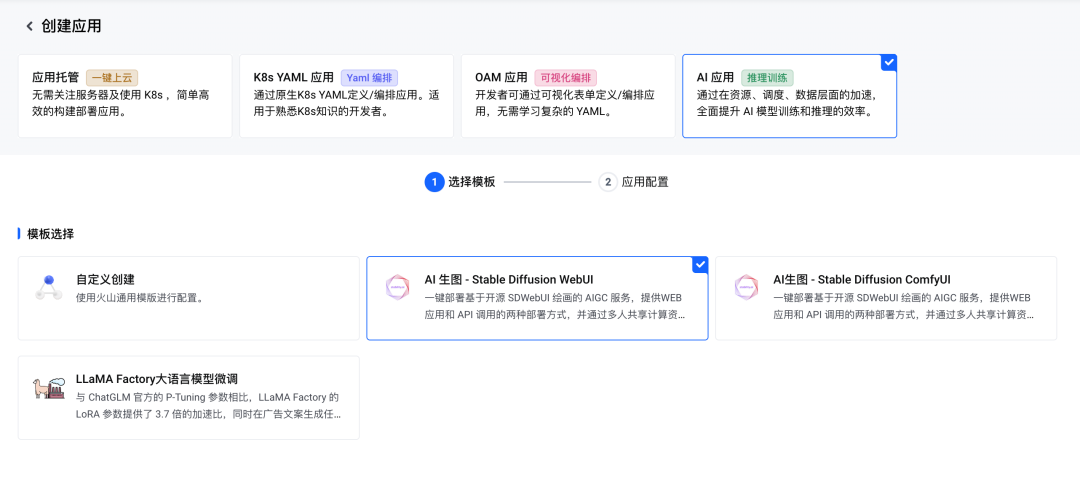
AI 应用提供了多种部署模式,其中 AI 生图、LLaMa Factroy 是预置的应用模版,支持预置模版的一键拉起,最大化降低用户的使用难度。自定义创建模式为用户提供了相对灵活的应用创建模式,能适配用户的绝大部分自定义场景。
这里我们选择 AI 生图 - Stable Diffuison WebUI 应用模版,然后点击“下一步:应用配置”。在【基本信息】模块,为我们的应用添加应用名称和标识。

1723257222383)
4. 【模型配置】模块,选择【制品库挂载】,并填入我们 SD 模型的存放路径;【挂载路径】输入“/stable-diffusion-webui/models/Stable-diffusion/”,这是 SD 模型默认的加载路径。
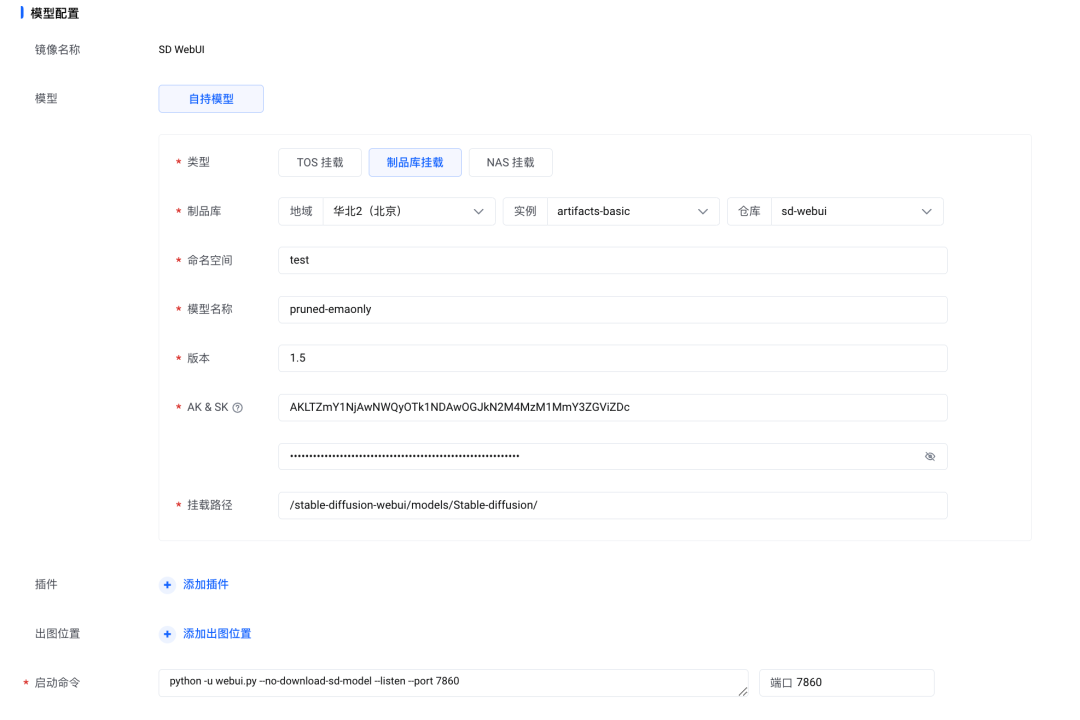
火山引擎制品仓库 Artifacts 支持对 AI 模型的管理,支持版本化管理模型,对模型/仓库进行精细化的权限管控。同时也支持代理外部公开仓库(proxy 仓库),能提升从海外下载模型的速度,同时缓存到本地仓库,方便下次的使用。
由于 AI 模型下载耗时久,未来我们也会在 AI 应用集成存储加速的功能,一键开启模型的加速,将模型进行缓存预热,大大提升推理服务下载模型的速度。
5. 在【部署集群】模块,选择已创建的部署资源和部署环境的命名空间。
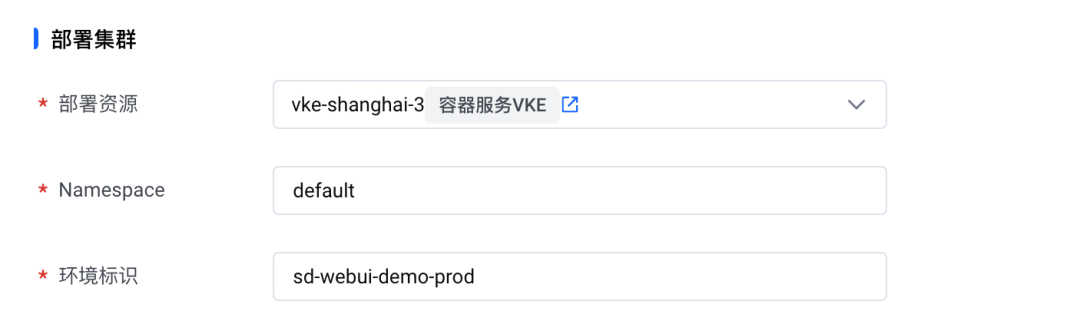
6. 在【服务规格】模块,【资源配置类型】选择 “GPU 计算型”,选择一个合适的 GPU 类型规格。其他配置保持默认。
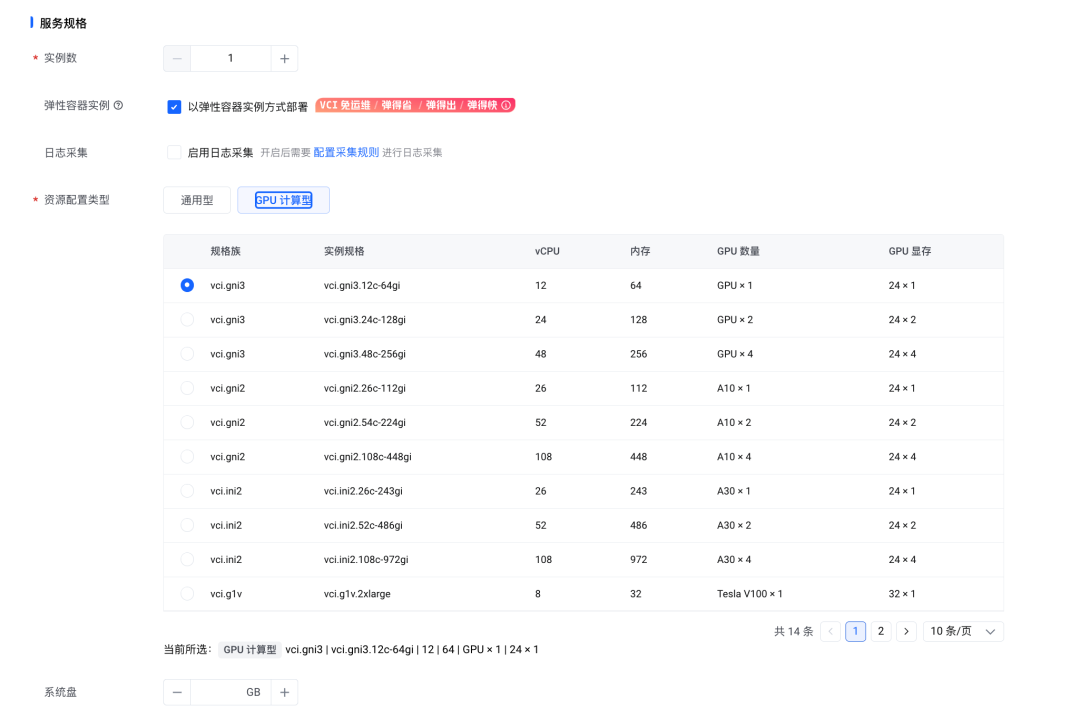
AI 应用支持以弹性容器 VCI 的方式部署,这意味着用户能以 Serverless 的方式启动推理服务,而无需固定申请 ECS 节点。这一方面可以显著提升资源利用率,降低资源成本,另一方面,用户的运维成本也会大大降低。
同时,如果选择 VCI,用户还可以体验其独有的镜像缓存功能——由于 AI 的镜像一般都非常大,容器启动时下载镜像非常耗时,在 VCI 部署模式下 AI 应用将默认开启镜像缓存进行加速,根据客户真实实践,这可以将原来接近 2****0 分钟的镜像下载时间降低到****秒级。
7. 在【访问配置】模块,访问入口类型选择【API 网关】并选择我们的网关实例。
通过集成 API 网关、负载均衡的功能,我们支持用户通过一个入口完成推理服务发布运维所需要的操作,极大增强了易用性。
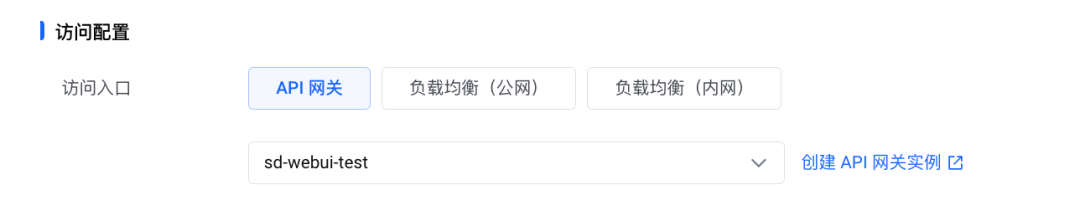
在完成配置后,点击【确定】,将会创建应用。并会立刻触发应用部署,预计等待 1-2 分钟完成部署。
8. 在【基本信息】页面的【概要】栏看到实例已经处于“运行中”状态,【资源配置】栏可以点击“实时日志”和“事件”查看应用详细的启动和运行信息。
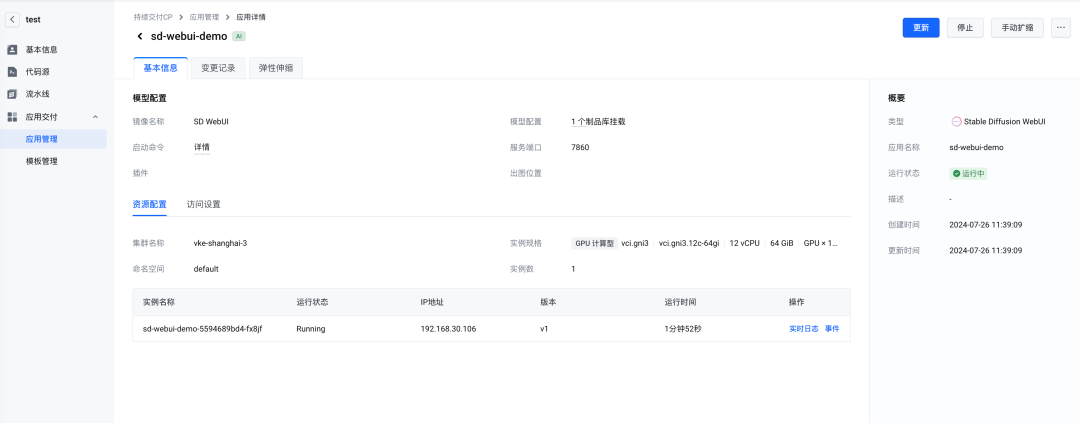
通过【事件】查看应用实例的启动信息:
通过【实时日志】查看应用的运行信息,例如加载模型,生成图片等:

在【基本信息】页面的【访问配置】栏,我们可以看到已经在 API 网关生成了应用的“公网访问域名”和“私网访问域名”:
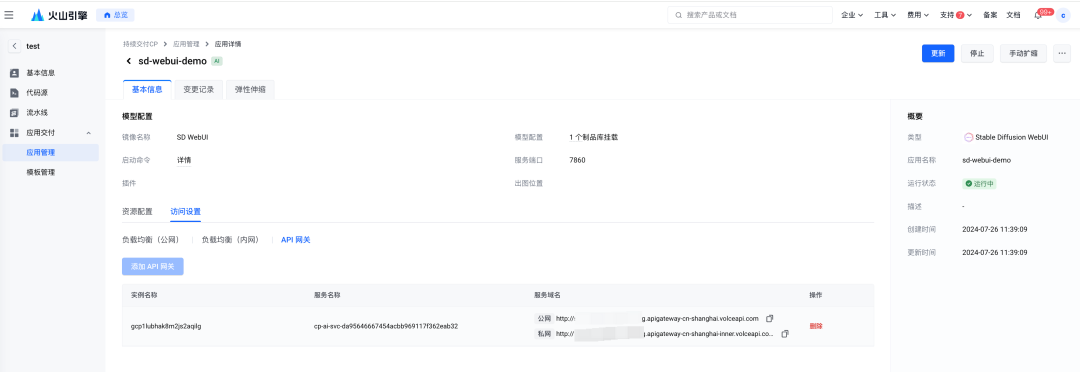
通过提供日志、事件、运行状态、访问信息等能力,对推理服务的应用运行状态进行全方位的管理,用户可以屏蔽底层资源即可完成对应用的完整生命周期管理。
9. 【可选】如需要对应用进行扩缩容,可支持手动扩缩,或者配置弹性伸缩策略。
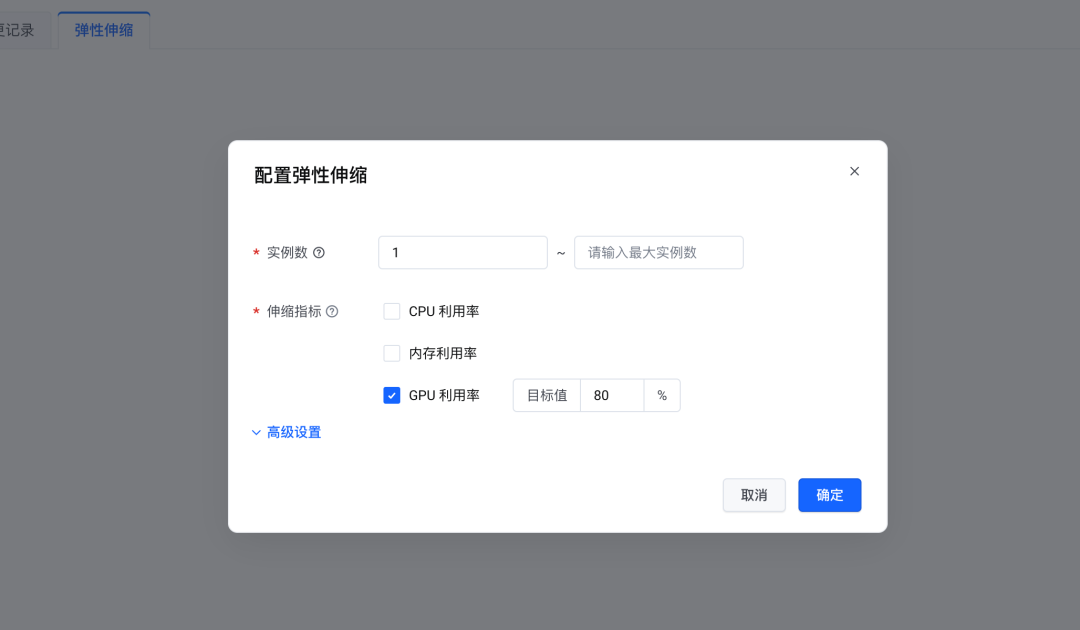
我们支持多种伸缩指标,其中 GPU 利用率指标经过字节跳动的优化,提供了更适合 GPU 场景的预置指标(使用 DCGM_FI_PROF_SM_ACTIVE 指标,可更好地反映 GPU 内部计算单元的使用情况,特别是 SM 的利用效率,而不仅仅表明 GPU 是否被占用),对 AI 应用的指标监控更加合理。
验证
现在开始验证我们的应用,在我们的浏览器地址栏输入【基本信息】页面【访问配置】栏的“公网访问域名”,可以看到 Stable Diffusion WebUI 已经成功运行起来。
我们尝试输入正向和反向的提示词生成一张图片,效果如下:
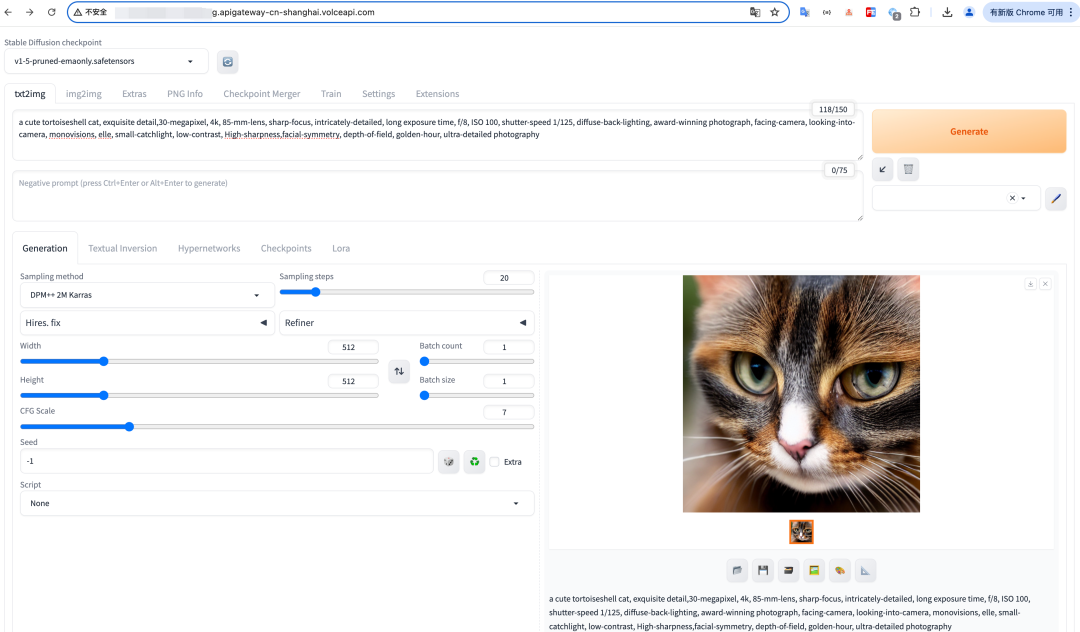
除了通过浏览器访问,我们也可以通过 API 的方式访问。
创建一个 client.py 的 python 脚本:
from datetime import datetime``import urllib.request``import base64``import json``import time``import os``import requests`` ``webui_server_url = os.environ.get('SD_WEB_UI_URL', 'http://127.0.0.1:7860')`` `` ``out_dir = os.environ.get('API_OUT_DIR', 'api_out')``out_dir_t2i = os.path.join(out_dir, 'txt2img')``out_dir_i2i = os.path.join(out_dir, 'img2img')``os.makedirs(out_dir_t2i, exist_ok=True)``os.makedirs(out_dir_i2i, exist_ok=True)`` `` ``def timestamp():` `return datetime.fromtimestamp(time.time()).strftime("%Y%m%d-%H%M%S")`` `` ``def encode_file_to_base64(path):` `with open(path, 'rb') as file:` `return base64.b64encode(file.read()).decode('utf-8')`` `` ``def decode_and_save_base64(base64_str, save_path):` `with open(save_path, "wb") as file:` `file.write(base64.b64decode(base64_str))`` `` ``def call_api(api_endpoint, **payload):` `data = json.dumps(payload).encode('utf-8')` `request = urllib.request.Request(` `f'{webui_server_url}/{api_endpoint}',` `headers={'Content-Type': 'application/json'},` `data=data,` `)` `response = requests.post(` `f'{webui_server_url}/{api_endpoint}',` `data=data,` `headers={'Content-Type': 'application/json'},` `timeout= 30,` `)` `return response.json()`` `` ``def call_txt2img_api(**payload):` `response = call_api('sdapi/v1/txt2img', **payload)` `for index, image in enumerate(response.get('images')):` `save_path = os.path.join(out_dir_t2i, f'txt2img-{timestamp()}-{index}.png')` `print("save to: ", save_path)` `decode_and_save_base64(image, save_path)`` `` ``def call_img2img_api(**payload):` `response = call_api('sdapi/v1/img2img', **payload)` `for index, image in enumerate(response.get('images')):` `save_path = os.path.join(out_dir_i2i, f'img2img-{timestamp()}-{index}.png')` `decode_and_save_base64(image, save_path)`` `` ``if __name__ == '__main__':` `payload = {` `"prompt": "masterpiece, (best quality:1.1), 1girl <lora:lora_model:1>", # extra networks also in prompts` `"negative_prompt": "",` `"seed": 1,` `"steps": 20,` `"width": 512,` `"height": 512,` `"cfg_scale": 7,` `"sampler_name": "DPM++ 2M",` `"n_iter": 1,` `"batch_size": 1,` `}` `call_txt2img_api(**payload)
输入【基本信息】页面【实例信息】栏 的“IP 地址”,添加到环境变量 SD_WEB_UI_URL,并执行脚本,可以看到已经生成图片并保存到本地文件。
SD_WEB_UI_URL="http://xxxxxxxx.apigateway-cn-shanghai.volceapi.com"``python3 client.py``# save to: api_out/txt2img/txt2img-20240726-073928-0.png

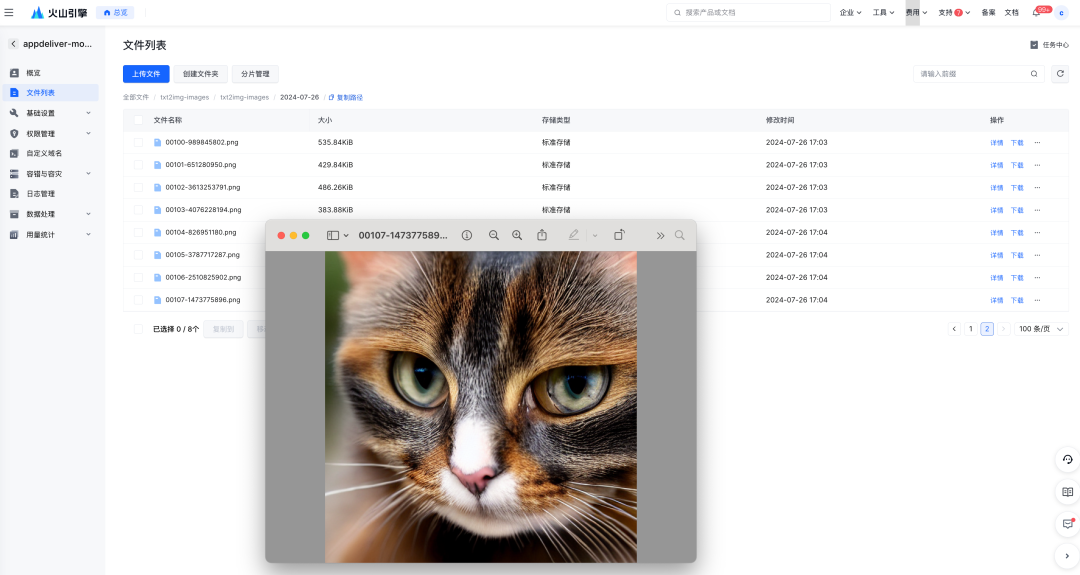
【可选】在应用配置中增加“出图位置”,可以直接将生成的图片上传到挂载的存储位置,例如 TOS 对象存储直接查看输出文件内容(SDWebUI 模型默认的输出路径是 /stable-diffusion-webui/outputs):
stable-diffusion-webui 配置优化
-
启动命令添加 --xformers 选项,使用 SDWebUI 自带的开源加速工具,提高图片生成速度;
-
增加 Lora 模型可以在不影响原始模型权重的情况下,为特定任务添加额外的参数。这样可以快速地针对特定风格、主题或者特点来微调模型,而无需重新训练整个模型。在【模型选择】中增加 Lora 模型的路径并挂载到默认的目录/stable-diffusion-webui/models/Lora。或者通过启动命令增加 --lora-dir 选项使用自定义挂载目录;
-
增加 embeddings 提高生成效率,同理可以在【模型选择】中增加 embeddings 文件的路径并挂载到默认的目录/stable-diffusion-webui/embeddings。或者通过启动命令增加 --embeddings-dir 选项使用自定义挂载目录;
-
尽量使用和容器服务 VKE 集群同地域的制品库和对象存储 TOS,这样将通过私网访问,可以明显提高模型加载和文件读写速度。
小结
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

















 1496
1496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









