






《python机器学习从入门到高级》分类算法:
引言
我们在之前的文章已经介绍了机器学习的一些基础概念,当拿到一个数据之后如何处理、如何评估一个模型、以及如何对模型调参等。接下来,我们正式开始学习如何实现机器学习的一些算法。 回归和分类是机器学习的两大最基本的问题,对于分类算法的详细理论部分。 本文主要从python代码的角度来实现分类算法。
# 导入相关库
import sklearn
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
- 数据准备
=========
下面我们以mnist数据集为例进行演示,这是一组由美国人口普查局的高中生和雇员手写的70000个数字图像。每个图像都用数字表示。也是分类问题非常经典的一个数据集
# 导入mnist数据集
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1, as_frame=False)
mnist.keys()
dict_keys(['data', 'target', 'frame', 'categories', 'feature_names', 'target_names', 'DESCR', 'details', 'url'])
其中data是我们输入的特征,target是0-9的数字
X, y = mnist["data"], mnist["target"]
X.shape,y.shape
((70000, 784), (70000,))
可以看出一共有70000图像,其中X一共有784个特征,这是因为图像是28×28的,每个特征是0-255之间的。下面我们通过imshow()函数将其进行还原
%matplotlib inline
import matplotlib as mpl
digit = X[0]
digit_image = digit.reshape((28, 28))#还原成28×28
plt.imshow(digit_image, cmap=mpl.cm.binary)
plt.axis("off")
plt.savefig("some_digit_plot")
plt.show()

从我们人类角度来看,我们很容易辨别它是5,我们要做的是,当给机器一张图片时,它能辨别出正确的数字吗?我们来看看y的值
我们要实现的就是,给我们一张图片,不难发现这是一个多分类任务,下面我们正式进入模型建立,首先将数据集划分为训练集和测试集,这里简单的将前60000个划分为训练集,后10000个为测试集,具体代码如下
y = y.astype(np.uint8)#将y转换成整数
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
2.简单二元分类实现
在实现多分类任务之前,我们先从一个简单的问题考虑,现在假设我只想知道给我一张图片,它是否是7(我最喜欢的数字)。这个时候就是一个简单的二分类问题,首先我们要将我们的目标变量进行转变,具体代码如下
y_train_7 = (y_train == 7)
y_test_7 = (y_test == 7)
现在,我们选择一个分类器并对其进行训练。我们先使用SGD(随机梯度下降)分类器
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(max_iter=1000, tol=1e-3, random_state=123)#设置random_state为了结果的重复性
sgd_clf.fit(X_train, y_train_7)
SGDClassifier(random_state=123)
训练好模型之后我们可以进行预测,以第一张图片为例,我们预测一下它是否是7(很显然我们知道不是)
sgd_clf.predict(X[0].reshape((1,-1)))
array([False])
可以看出判断正确了,在之前我们讨论了模型评估的方法,详细介绍看这篇文章:Python机器学习从入门到高级:模型评估和选择(含详细代码) 下面演示如何用代码实现各个评估指标
3.模型评估
我们根据分类评估指标来看看SGD分类器效果
3.1 准确率
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train_7, cv=3, scoring="accuracy")
array([0.97565, 0.97655, 0.963 ])
3.2 混淆矩阵
y_train_pred = sgd_clf.predict(X_train)
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train_7, y_train_pred)
array([[53304, 431],
[ 550, 5715]], dtype=int64)
3.3 召回率和精确度
from sklearn.metrics import precision_score, recall_score
print('precision:',precision_score(y_train_7, y_train_pred))
print('recall:',recall_score(y_train_7,y_train_pred))
precision: 0.929873088187439
recall: 0.9122106943335994
下面要用的matplotlib,想了解matplotlib可以看这篇文章:Python数据可视化大杀器之地阶技法:matplotlib(含详细代码)
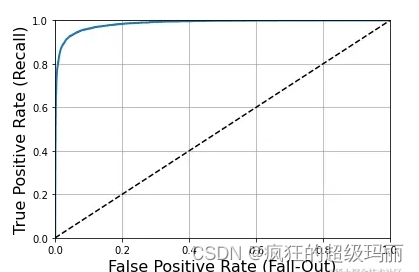
3.4 ROC曲线
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_7, y_scores)
plt.plot(fpr, tpr, linewidth=2)
plt.plot([0, 1], [0, 1], 'k--')
plt.axis([0, 1, 0, 1])
plt.xlabel('False Positive Rate (Fall-Out)', fontsize=16)
plt.ylabel('True Positive Rate (Recall)', fontsize=16)
plt.grid(True)
本章的介绍到此介绍,下一章介绍分类算法(下):如何完成多分类任务
本文借鉴网络,如有侵权,请联系删除。















 1345
1345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









