










1.导读
随着企业数字化进程不断加速,PDF转Word的功能、纸质文本的电子化存储、文件复原与二次编辑、信息检索等应用都有着强烈的企业需求。目前市面上已有一些软件,但普遍需要繁琐的安装注册操作,大多还存在额度限制。此外,最终转换效果也依赖于版面形态,无法做到针对性适配。
针对开发者的需求,飞桨文字识别套件PaddleOCR全新发布PP-StructureV2智能文档分析系统,支持一行命令实现PDF转Word功能,文字、表格、标题、图片都可完整恢复,一键实现PDF编辑自由!

图1 PDF文件转Word文件效果图
PP-StructureV2智能文档分析系统升级点包括以下2方面:
-
系统功能升级 :新增图像矫正和版面复原模块,支持标准格式pdf和图片格式pdf解析!
-
系统性能优化 :
-
版面分析:发布轻量级版面分析模型,速度提升11倍,平均CPU耗时仅需41ms!
-
表格识别:设计3大优化策略,预测耗时不变情况下,模型精度提升6%。
-
关键信息抽取:设计视觉无关模型结构,语义实体识别精度提升2.8%,关系抽取精度提升超过9.1%。
GitHub传送门:https://github.com/PaddlePaddle/PaddleOCR
2.PP-StructureV2
智能文档分析系统优化策略概述
PP-StructureV2系统流程图如下所示,文档图像首先经过图像矫正模块,判断整图方向并完成转正,随后可以完成版面信息分析与关键信息抽取2类任务。
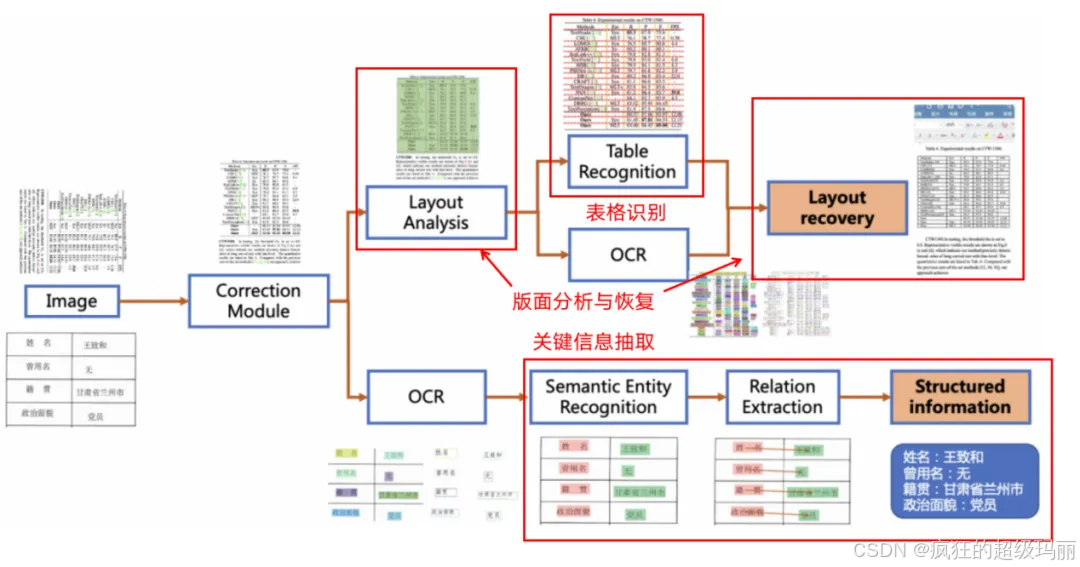
图2 PP-StructureV2系统流程图
从算法改进思路来看,对系统中的3个关键子模块,共进行了8个方面的改进:
☆版面分析
-
PP-PicoDet:轻量级版面分析模型
-
FGD:兼顾全局与局部特征的模型蒸馏算法
☆表格识别
-
PP-LCNet: CPU友好型轻量级骨干网络
-
CSP-PAN:轻量级高低层特征融合模块
-
SLAHead:结构与位置信息对齐的特征解码模块
☆关键信息抽取
-
VI-LayoutXLM:视觉特征无关的多模态预训练模型结构
-
TB-YX:考虑阅读顺序的文本行排序逻辑
-
UDML:联合互学习知识蒸馏策略
最终,与PP-StructureV1相比:
-
版面分析模型参数量减少95%,推理速度提升11倍,精度提升0.4%;
-
表格识别预测耗时不变,模型精度提升6%,端到端TEDS提升2%;
-
关键信息抽取模型速度提升2.8倍,语义实体识别模型精度提升2.8%;关系抽取模型精度提升9.1%。
3.PP-StructureV2
智能文档分析系统整体介绍
3.1 版面分析与恢复
版面分析指的是对图片形式的文档进行区域划分,定位其中的关键区域,如文字、标题、表格、图片等。在PP-StructureV1中,使用了PaddleDetection中开源的高效检测算法PP-YOLOv2完成版面分析的任务。在PP-StructureV2中,我们发布基于PP-PicoDet的轻量级版面分析模型,针对版面分析场景定制图像尺度,同时使用FGD知识蒸馏算法,进一步提升模型精度,最终CPU上41ms即可完成版面分析。


图3 版面分析效果图(分类为文字、图片、表格、图注、标注等)
3.2 表格识别
基于深度学习的表格识别算法种类丰富,PP-StructureV1基于文本识别算法RARE研发了端到端表格识别算法TableRec-RARE,模型输出为表格结构的HTML表示,进而可以方便地转化为Excel文件。TableRec-RARE中,图像输入到骨干网络后会得到四个不同尺度的特征图,分别为C2(1/4),C3(1/8),C4(1/16),C5(1/32),Head特征解码模块将C5作为输入,并输出表格结构信息和单元格坐标。
本次升级过程中,我们对模型结构和损失函数等5个方面进行升级,提出了 SLANet (Structure Location Alignment Network) ,模型结构如下图所示,详细解读请参考技术报告。
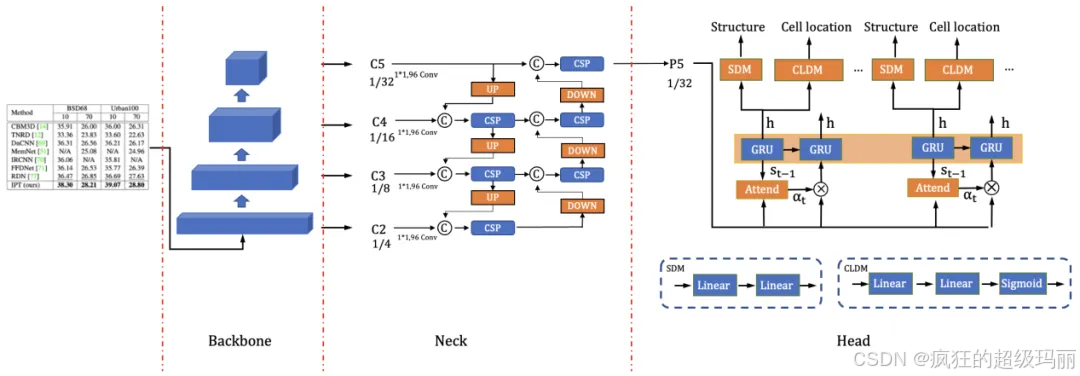
图4 SLANet模型结构图
可视化结果如下,左为输入图像[1],右为识别的HTML表格结果
图5 可视化结果
在PubtabNet英文表格识别数据集上,和其他方法对比如下。SLANet平衡精度与模型大小,推理速度最快,能够适配更多应用场景:
表1 SLANet模型与其他模型效果对比
| 策略 | Acc | TEDS | 推理速度(CPU+MKLDNN) | 模型大小 |
| TableMaster | 77.9% | 96.12% | 2144ms | 253M |
| TableRec-RARE | 73.8% | 95.3% | 1550ms | 8.7M |
| SLANet | 76.31% | 95.89% | 766ms | 9.2M |
测试环境:飞桨版本为2.3.1,CPU为Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz,开启mkldnn,线程数为10。
3.3关键信息抽取
关键信息抽取指的是针对文档图像的文字内容,提取出用户关注的关键信息,如身份证中的姓名、住址等字段。PP-Structure中支持了基于多模态LayoutLM系列模型的语义实体识别 (Semantic Entity Recognition, SER) 以及关系抽取 (Relation Extraction, RE) 任务。PP-StructureV2中,我们对模型结构以及下游任务训练方法进行升级,提出了VI-LayoutXLM(Visual-feature Independent LayoutXLM),具体流程图如下所示。
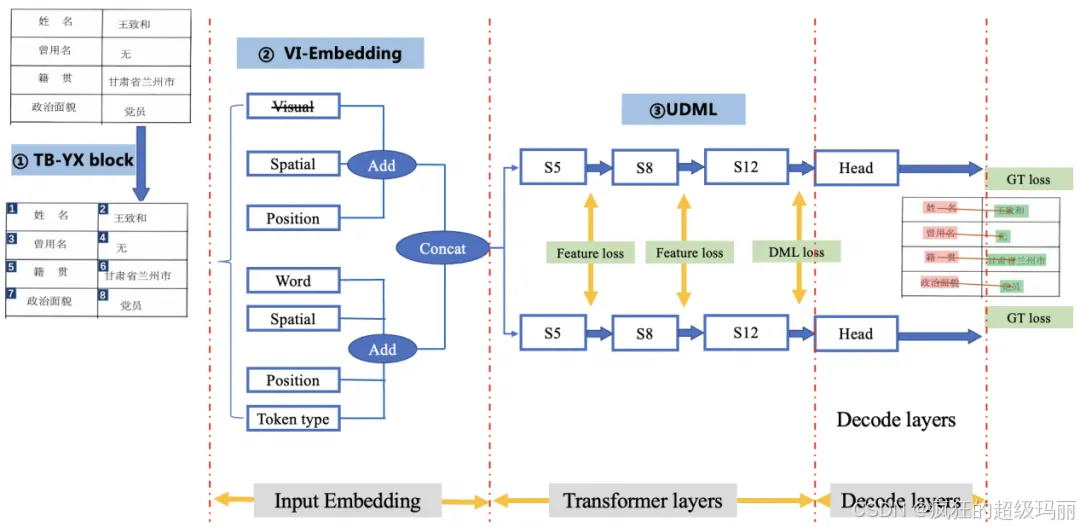
图6 关键信息抽取流程图

图7 语义实体识别与关系抽取效果图[2]
在XFUND数据集上,与其他方法的效果对比如下所示。
表2 VI-LayoutXLM模型与其他模型效果对比
| 模型 | SER Hmean | RE Hmean |
| LayoutLMv2-base | 85.44% | 67.77% |
| LayoutXLM-base | 89.24% | 70.73% |
| StrucTexT-large | 92.29% | 86.81% |
| VI-LayoutXLM-base (ours) | 93.19% | 83.92% |
4.社区开发者开发
PDF转Word应用程序
飞桨社区开发者吴泓晋(GitHubID:whjdark)基于最新发布的PP-StructureV2智能文档分析系统,开发了一款PDF转Word小工具,导入PDF文件可一键转换为可编辑Word,支持文字、表格、标题、图片的完整恢复。
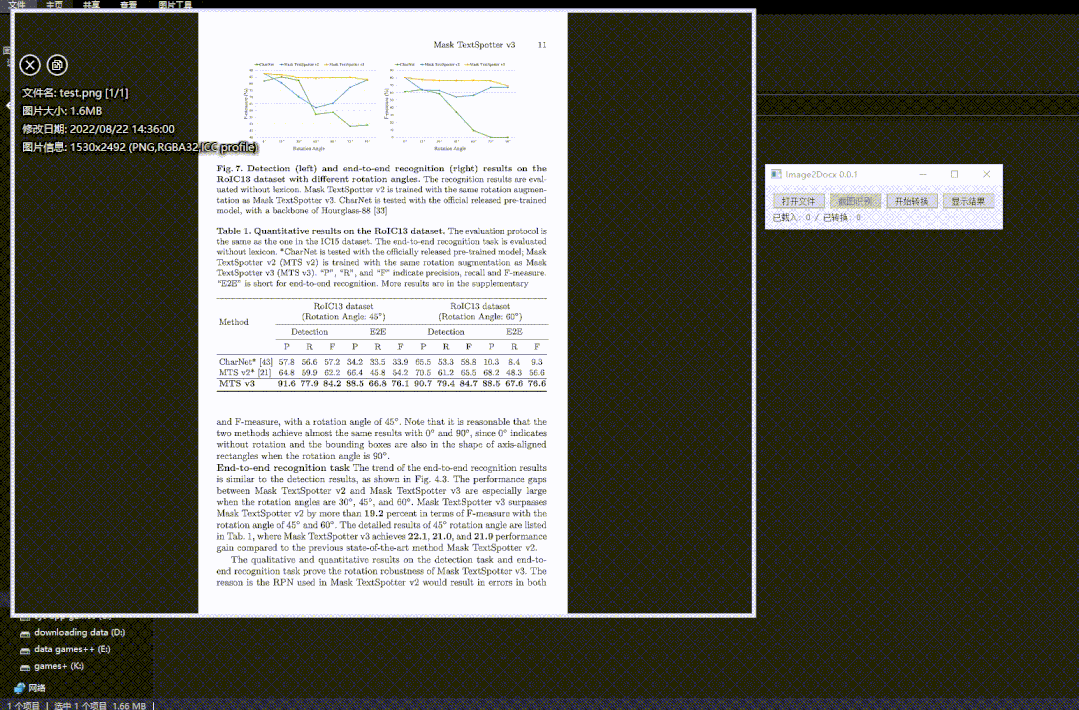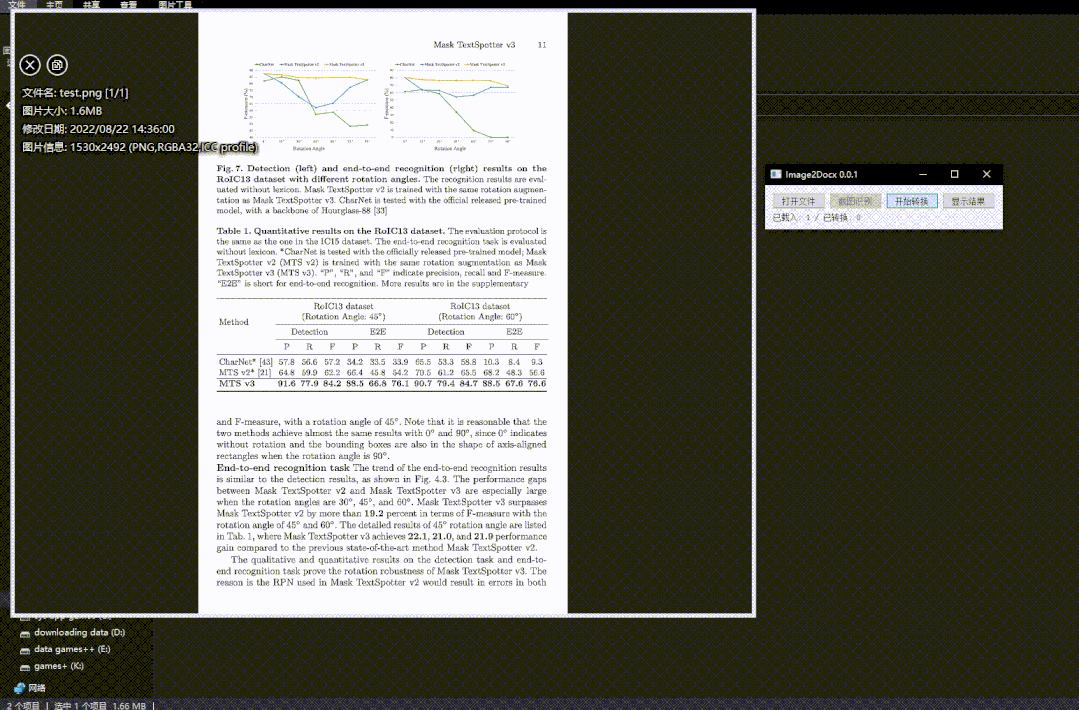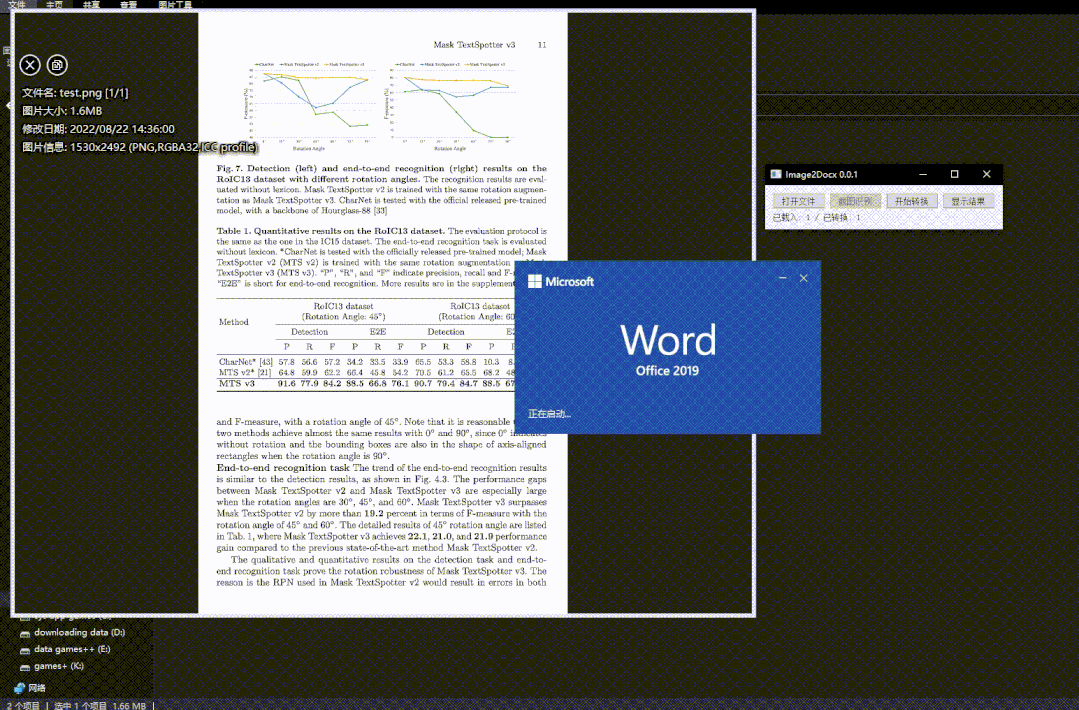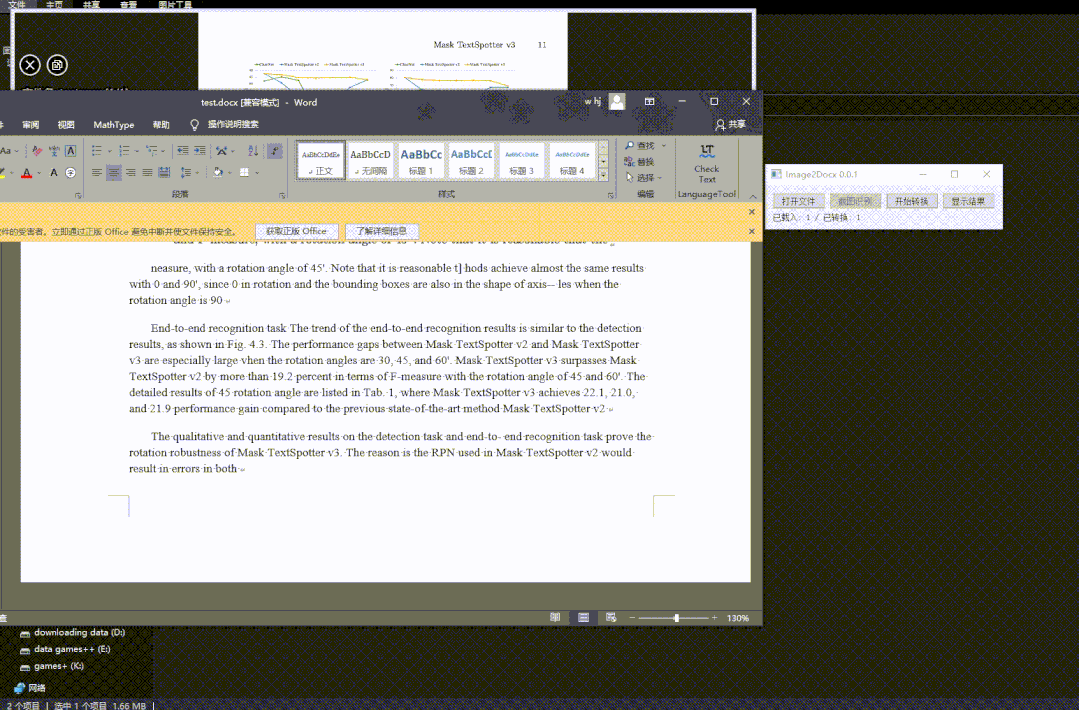
图8 PDF文件转Word文件操作流程演示
软件的使用十分简单,下载后解压exe文件,打开图片或PDF文件,点击转换后可对图片型PDF文件进行OCR识别得到Word文件,或者通过PDF解析功能直接获得转换后的Word。

包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习
⑤ 历年互联网企业Python面试真题,复习时非常方便****


















 2253
2253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









