






下面内容就是就给大家分享一下这个RPA应用,如果你也有相关的素材收集诉求,可以尝试一下,希望会对各位同学有所帮助。
效果演示
RPA应用是从小红书的官网https://www.xiaohongshu.com来采集爆文素材,需要提前登录你的小红书账号,然后再启动RPA。

如何获得
如果你对这款RPA机器人感兴趣,想要搜集小红书素材,让你的内容创作变得更加轻松高效,可以关注船长的公众号“船长笔迹”,并回复“小红书笔记”,获取影刀RPA工具分享链接。或者也可以扫描下方二维码加船长VX来获取。

RPA设计思路
下面是船长在设计实现这个RPA机器人的一些总结,如果你对于RPA机器人的设计与实现比较感兴趣,可以继续往下看。
数据来源:小红书目前的采集途径主要有小红书APP和小红书网站两个来源,但是考虑到如果从APP采集数据会比较麻烦一些,要么需要连接手机,要么需要下载模拟器,所以放弃这个途径改为从小红书网站来获取数据。
*RPA***工具:常规的RPA或自动化脚本应用都是可以用的,无论是影刀、UiBot、或是Automa、其他RPA应用都是可以的,自己熟悉就好。这里船长用的是影刀。
采集流程:完全模仿正常用户的操作流程。
- 打开小红书网站(已登录状态)

- 在上方的搜索框输入搜索关键字
- 点击搜索按钮,延时几秒钟,等待搜索页面加载完成

- 获取搜索结果列表,循环每一条图文笔记

- 点击每一条图文笔记,获取封面、标题、笔记内容、笔记地址、点赞收藏数等等信息

- 将获取到的信息作为一行数据写入Excel中
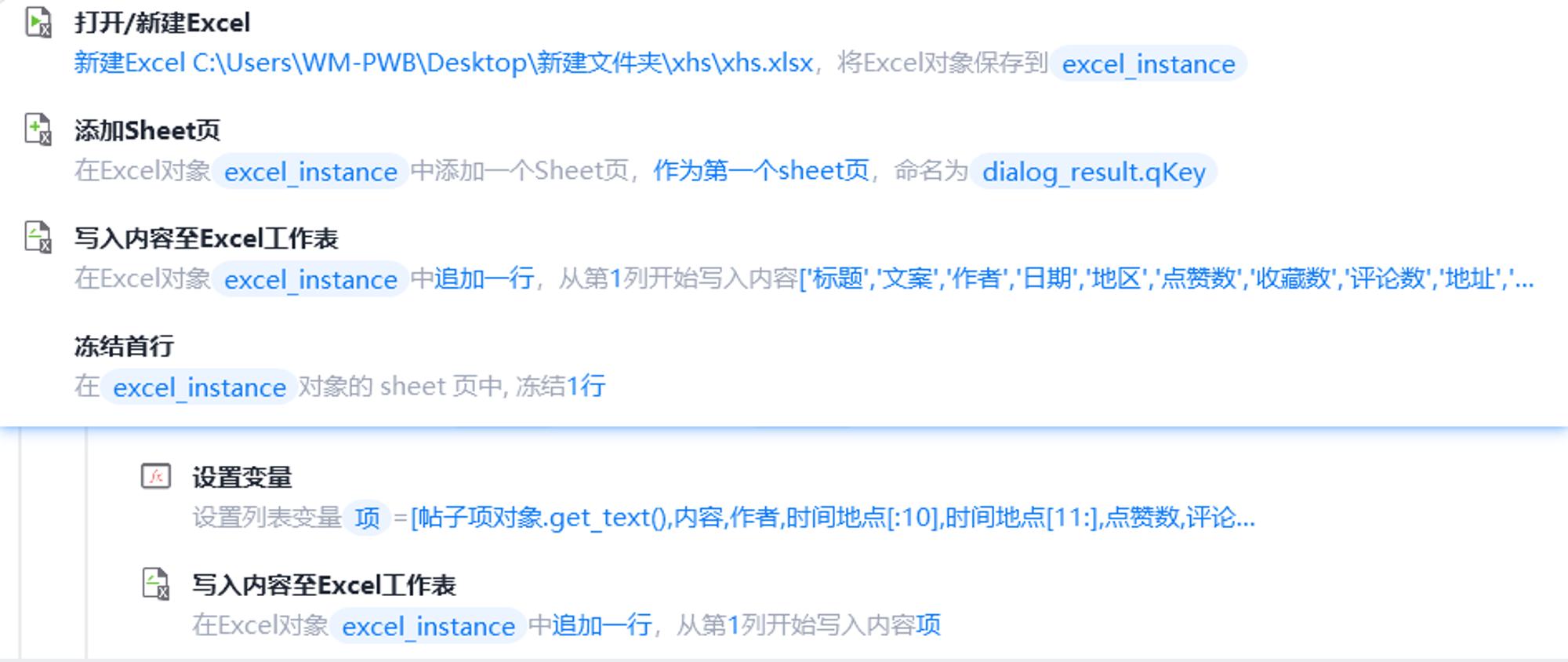
- 等待图文采集完成,关闭保存Excel
设计难点
- 小红书网页图文列表是动态变化的,会随着页面上下滚动而发生变化,不可以直接循环采集
解决思路:RPA工具对于这种动态加载的网站内容好像都没有太方便的解决方案,影刀也是如此。
因为网页会随着上下滚动不断变化,可能影刀获取到图文的标题是A,结果一滚动,页面动态加载了标题为B的图文,那么影刀还是按照之前标题A的图文去采集数据,那么就会报错,采集不到A的数据了。
为了解决这个问题,需要监控一个数据,那就是页面是否发生了动态加载。如果在采集数据时发现页面动态加载了,那么就需要重新获取一遍图文列表,取得动态加载后的页面数据再采集图文内容。
这里船长用于判断页面是否发生了动态加载的标准,是滚动条的位置。只要滚动条动了,那就重新抓取数据。

此外,重新抓取数据还会带来一个小问题,那就是可能产生重复数据,需要去重,这个问题大家可以自行探索解决。
- 小红书笔记存在图文和视频两种形式,页面结构是不一致的,获取封面时该如何兼容处理?
解决思路:因为影刀中提供了直接编写JS和Python脚本的功能,所以这里船长直接使用了JS脚本直接获取封面的地址。















 743
743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









