






PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
对爬虫爬取数据时的分页进行一下总结。分页是爬取到所有数据的关键,一般有这样几种形式:
1、已知记录数,分页大小(pagesize, 一页有多少条记录)
-
已知总页数(在页面上显示出总页数)
-
页面上没有总记录数,总页数,但能从分页条中找到总页数
-
滚动分页,知道总页数
-
滚动分页,不知道总页数
以上前三种情况比较简单,基本上看一下加载分页数据时的地址栏,或者稍微用Chrome – network分析一下,就可以了解分页的URL。
一、页面分析,获取分页URL
典型的如豆瓣图书、电影排行榜的分页。
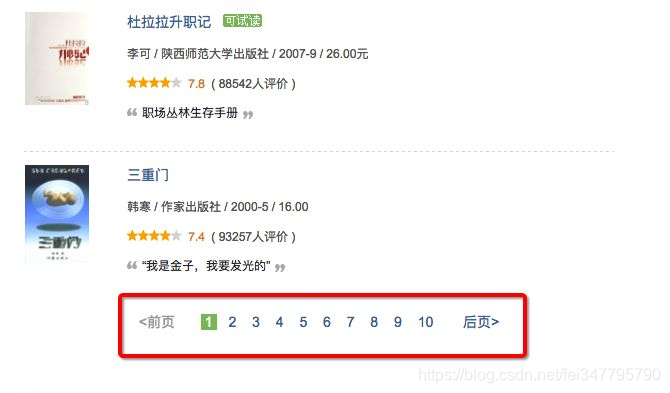
对于像以下这种分页,没有显示总记录数,但从分页条上看到有多少页的,一般的处理方法有两种:一是先把最后一页的页码抓取下来;二是一页一页的访问抓取,直到没有“下一页”。
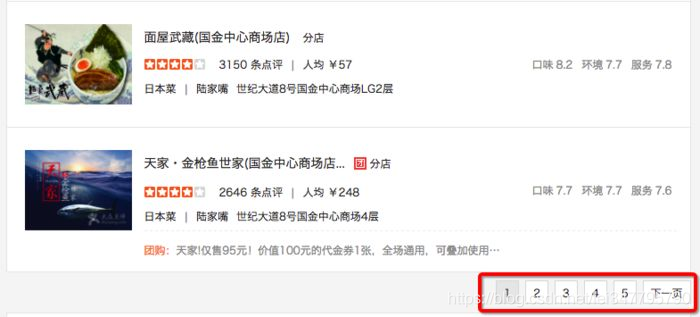
二、用抓包工具,查看分页URL
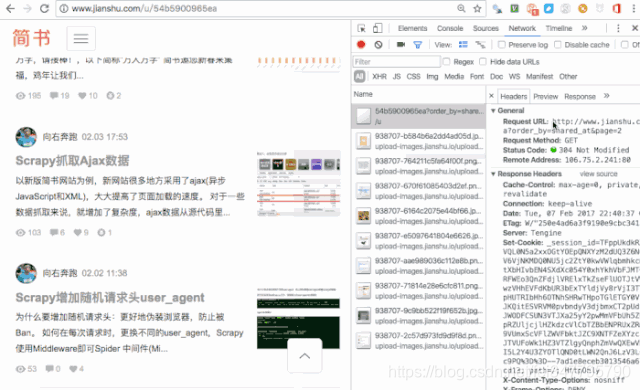
通过抓包工具,获取了分页的URL,再进行总页数的分析,一般是进行计算,如这里,有文章总数量,每页显示的文章数(页大小),就可以计算出总页数。
看一下这个,七日热门文章的分页,比较有意思。这么一长串,是不是比较崩溃。
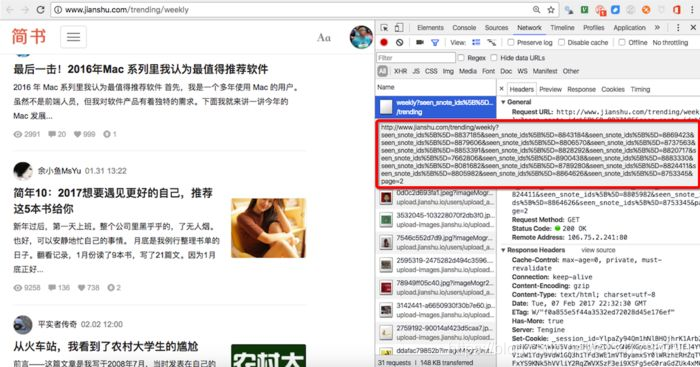
这时候一般要缩短参数,确定关键参数。分页关键的参数是page=2,直接把url减少成这样:

感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
加入社区:https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









