






今天给大家分享一个超强的算法模型,Transformer
Transformer 模型是目前自然语言处理(NLP)以及计算机视觉等领域中应用非常广泛的深度学习模型架构。
它由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中提出,并迅速取代了传统的循环神经网络(RNN)和长短期记忆网络(LSTM)在许多任务中的主导地位。

Transformer 模型的关键创新点是其自注意力机制,它通过自注意力机制解决了长期依赖问题,极大地提高了并行计算的效率。
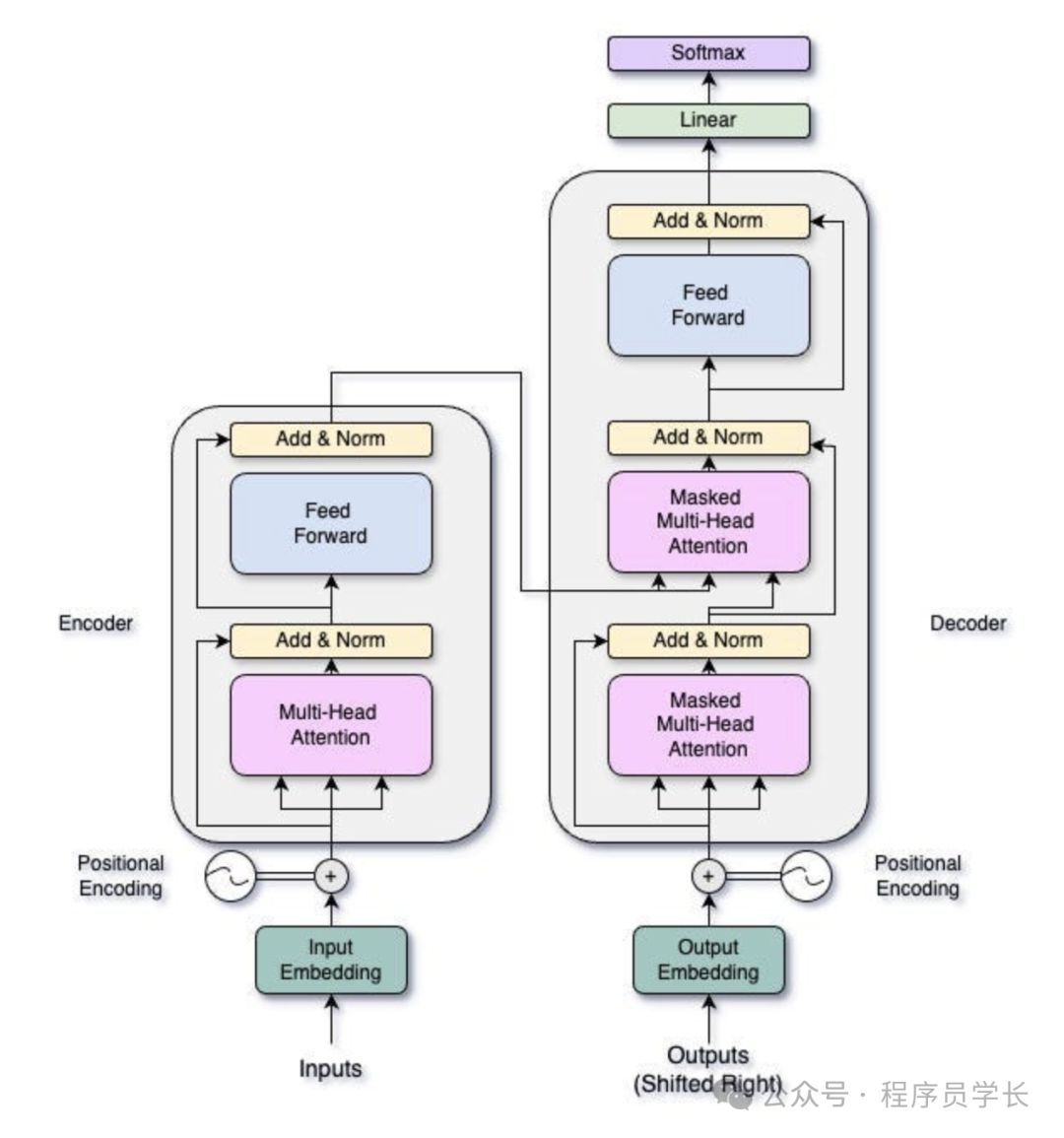
Transformer 模型架构
Transformer 模型主要由编码器(Encoder)和解码器(Decoder)两部分组成。
编码器
编码器主要负责将输入序列转化为一组上下文相关的高维表示。
它由多个相同的层组成,每个层都有两个主要子层:
- 多头自注意力层
- 前馈神经网络
此外,每个子层都包含残差连接和层归一化,以增强稳定性和性能。
解码器
解码器利用编码器的输出生成目标序列。
解码器的结构与编码器类似,包含多个相同的层,但解码器的每一层有三个子层
- 掩蔽自注意力层
- 编码器-解码器注意力层
- 前馈神经网络
核心组件
下面,我们一起来看一下 transformer 中的核心组件。
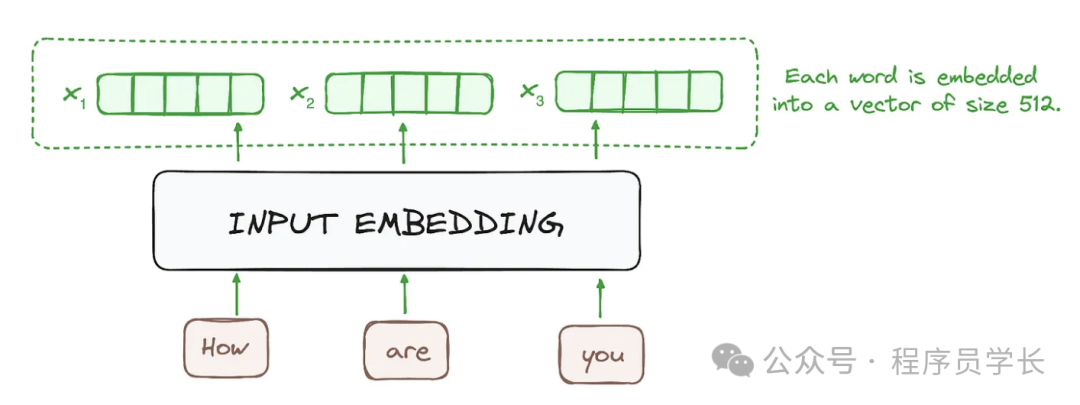
*1.输入嵌入*
输入嵌入层的作用是将输入序列的每个词转换为高维空间中的向量表示。
在自然语言处理中,通常使用预训练的词向量如 Word2Vec 或 GloVe,或者在训练过程中与模型一起学习嵌入。
这些嵌入能够捕捉词汇的语义信息并将其转换为固定大小的向量,通常大小为 512。
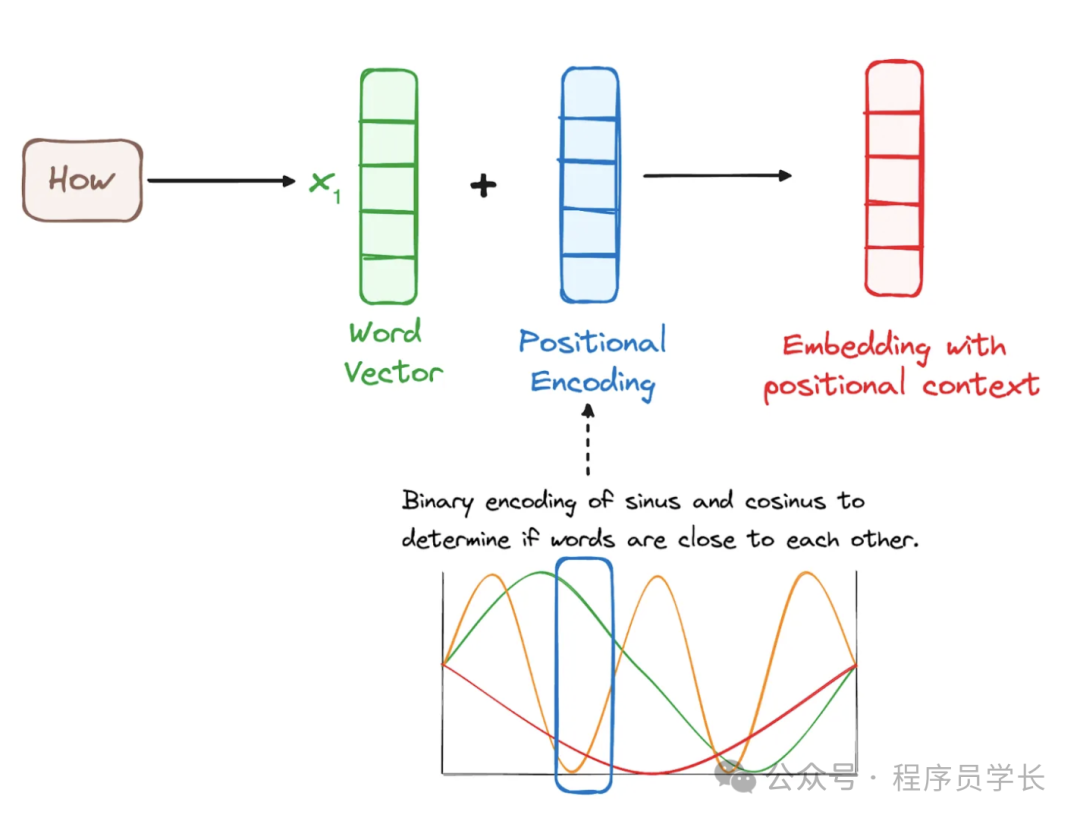
*2.位置编码*
由于 Transformer 完全基于注意力机制并且不使用任何循环结构,它需要一种方法来利用输入序列中词的顺序信息。
位置编码通过将一个相对或绝对位置的编码添加到输入嵌入中来实现。
位置编码常使用正弦和余弦函数,其公式如下所示:
这里,pos 表示词的位置, 表示维度索引, 是嵌入维度。
*3.多头自注意力机制*
多头自注意力机制是 Transformer 的核心,它允许模型在不同的表示空间中关注输入序列的不同部分。
它的主要思想是在同一时间通过多个独立的注意力头(Attention Head)来关注序列中不同部分的信息,然后将这些信息综合起来,生成更丰富的表示。

*自注意力机制*
在讨论多头自注意力机制之前,首先需要理解自注意力(Self-Attention)机制。
自注意力机制的目的是对输入序列中的每个元素计算一个输出,这个输出是其他所有元素的加权求和,权重由当前元素与序列中其他元素的相关度决定。
自注意力机制的计算过程包括以下几个步骤。
-
计算查询(Query)、键(Key)和值(Value)
对于序列中的每个元素 ,通过三个线性变换分别映射为查询向量 、键向量 和值向量 。
其中,、 和 是可学习的权重矩阵。
-
计算注意力分数
通过计算其查询向量 与所有键向量 的点积,得到该元素与其他元素的相关性(即注意力得分)
为了稳定训练过程,这些分数会除以 ,其中 是键向量的维度。
-
计算注意力权重
将注意力分数通过 Softmax 函数转换为注意力权重,使得它们和为1。
-
计算注意力输出
注意力输出是值向量的加权和。
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
多头注意力机制通过并行地计算多组查询、键和值,来捕捉输入序列中不同子空间的依赖关系。
具体来说,它将自注意力机制的计算过程复制 h 次,每次使用不同的查询、键、值的线性变换。
最后,将这些头的输出拼接起来,并通过一个线性变换得到最终的输出。
其中,每个 是自注意力机制的输出, 是一个可学习的线性变换矩阵。
*4.前馈神经网络*
每个编码器和解码器层中,除了自注意力机制,还有一个独立的前馈神经网络(FFN),它用于对自注意力输出的结果进行进一步的非线性变换。
FFN 由两层线性变换和一个激活函数(通常是 ReLU)组成
其中
- 和 是线性变换的权重矩阵
- 和 是偏置向量
FFN 的作用是通过非线性映射提升模型的表达能力。

*5.层归一化和残差连接*
为了加速训练并解决梯度消失或爆炸的问题,Transformer 在每个子层(包括自注意力机制和前馈神经网络)后面引入了残差连接和层归一化。
-
残差连接
将输入直接加到子层的输出上,保持信息传递流畅
-
层归一化
对每个子层的输出进行归一化处理,提升模型的稳定性
其中, 和 分别是输入的均值和标准差

*6.Masked 多头自注意力子层*
Masked 多头自注意力子层用于解码器的生成任务。
在生成过程中,模型生成当前时间步的单词时,只能依赖之前生成的单词,而不能看到未来未生成的单词。
为了确保这一点,Masked 多头自注意力机制通过在注意力矩阵中对未来位置进行掩码,使其权重为负无穷,从而保证模型只能“关注”到之前的位置。
具体来说,在计算注意力得分时,对未来的位置进行屏蔽,将这些位置的得分设为负无穷大,使得 Softmax 归一化后的权重为零。

*7.编码器-解码器多头注意力子层*
编码器-解码器多头注意力子层在 Transformer 解码器中起到了关键作用,它使解码器能够有效地关注输入序列(编码器的输出),从而在生成序列时参考原始输入信息。
具体来说,编码器-解码器多头注意力的基本思想是通过对编码器输出(Key 和 Value)和解码器当前输入(Query)来生成新的表示。
这种机制使得解码器能够在生成序列时动态地选择性关注输入序列的不同部分。

示例代码
下面,我们从头开始构建一个 Transformer 模型。
首先,我们来创建一个 MultiHeadAttention 类,它实现了 Transformer 中的多头自注意力机制。
import numpy as np
class MultiHeadAttention:
def __init__(self, num_hiddens: int, num_heads: int, dropout: float = 0.0, bias: bool = False):
self.num_heads = num_heads
self.num_hiddens = num_hiddens
self.d_k = self.d_v = num_hiddens // num_heads
self.W_q = np.random.rand(num_hiddens, num_hiddens)
self.W_k = np.random.rand(num_hiddens, num_hiddens)
self.W_v = np.random.rand(num_hiddens, num_hiddens)
self.W_o = np.random.rand(num_hiddens, num_hiddens)
if bias:
self.b_q = np.random.rand(num_hiddens)
self.b_k = np.random.rand(num_hiddens)
self.b_v = np.random.rand(num_hiddens)
self.b_o = np.random.rand(num_hiddens)
else:
self.b_q = self.b_k = self.b_v = self.b_o = np.zeros(num_hiddens)
def transpose_qkv(self, X: np.ndarray) -> np.ndarray:
X = X.reshape(X.shape[0], X.shape[1], self.num_heads, -1)
X = X.transpose(0, 2, 1, 3)
return X.reshape(-1, X.shape[2], X.shape[3])
def transpose_output(self, X: np.ndarray) -> np.ndarray:
X = X.reshape(-1, self.num_heads, X.shape[1], X.shape[2])
X = X.transpose(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
def scaled_dot_product_attention(self, Q: np.ndarray, K: np.ndarray, V: np.ndarray, valid_lens: np.ndarray = None) -> np.ndarray:
d_k = Q.shape[-1]
scores = np.matmul(Q, K.transpose(0, 2, 1)) / np.sqrt(d_k)
if valid_lens is not None:
mask = np.arange(scores.shape[-1]) < valid_lens[:, None]
scores = np.where(mask[:, None, :], scores, -np.inf)
attention_weights = np.exp(scores - np.max(scores, axis=-1, keepdims=True))
attention_weights /= attention_weights.sum(axis=-1, keepdims=True)
return np.matmul(attention_weights, V)
def forward(self, queries: np.ndarray, keys: np.ndarray, values: np.ndarray, valid_lens: np.ndarray = None) -> np.ndarray:
queries = self.transpose_qkv(np.dot(queries, self.W_q) + self.b_q)
keys = self.transpose_qkv(np.dot(keys, self.W_k) + self.b_k)
values = self.transpose_qkv(np.dot(values, self.W_v) + self.b_v)
if valid_lens is not None:
valid_lens = np.repeat(valid_lens, self.num_heads, axis=0)
output = self.scaled_dot_product_attention(queries, keys, values, valid_lens)
output_concat = self.transpose_output(output)
return np.dot(output_concat, self.W_o) + self.b_o
在 forword 方法中,首先对 queries、keys 和 values 进行线性变换,分别生成查询、键和值向量。
然后通过 scaled_dot_product_attention 方法计算每个注意力头的输出。
接下来,调用 transpose_output 方法将多个注意力头的输出拼接起来。
最后,拼接后的输出通过 矩阵进行线性变换,并加上偏置 ,得到最终的输出。
下面,我们来看一下 位置编码的实现。
def positional_encoding(seq_len: int, d_model: int) -> np.ndarray:
pos = np.arange(seq_len)[:, np.newaxis]
i = np.arange(d_model)[np.newaxis, :]
angle_rates = 1 / np.power(10000, (2 * (i // 2)) / np.float32(d_model))
pos_encoding = pos * angle_rates
pos_encoding[:, 0::2] = np.sin(pos_encoding[:, 0::2])
pos_encoding[:, 1::2] = np.cos(pos_encoding[:, 1::2])
return pos_encoding
然后,我们创建一个前馈网络。
class FeedForward:
def __init__(self, d_model: int, d_ff: int):
self.W1 = np.random.randn(d_model, d_ff) * np.sqrt(2.0 / (d_model + d_ff))
self.b1 = np.zeros(d_ff)
self.W2 = np.random.randn(d_ff, d_model) * np.sqrt(2.0 / (d_ff + d_model))
self.b2 = np.zeros(d_model)
def __call__(self, x: np.ndarray) -> np.ndarray:
return self.forward(x)
def forward(self, x: np.ndarray) -> np.ndarray:
return np.dot(np.maximum(0, np.dot(x, self.W1) + self.b1), self.W2) + self.b2
接下来,我们构建一个编码器层,将多头注意力机制与前馈神经网络相结合,构成了 Transformer 模型的核心构建块之一。
class EncoderLayer:
def __init__(self, d_model: int, num_heads: int, d_ff: int, dropout: float = 0.0, bias: bool = False):
self.d_model = d_model
self.num_heads = num_heads
self.d_ff = d_ff
self.multi_head_attention = MultiHeadAttention(d_model, num_heads, dropout, bias)
self.feed_forward = FeedForward(d_model, d_ff)
def __call__(self, x: np.ndarray, mask: np.ndarray = None) -> np.ndarray:
return self.forward(x, mask)
def forward(self, x: np.ndarray, mask: np.ndarray = None) -> np.ndarray:
attn_output = self.multi_head_attention.forward(x, x, x, mask)
output = self.feed_forward(attn_output)
return output
然后,我们来构建一个解码器层,它包括两个多头注意力机制和一个前馈网络。
class DecoderLayer:
def __init__(self, d_model: int, num_heads: int, d_ff: int, dropout: float = 0.0, bias: bool = False):
self.d_model = d_model
self.num_heads = num_heads
self.d_ff = d_ff
self.multi_head_attention_1 = MultiHeadAttention(d_model, num_heads, dropout, bias)
self.multi_head_attention_2 = MultiHeadAttention(d_model, num_heads, dropout, bias)
self.feed_forward = FeedForward(d_model, d_ff)
def __call__(self, x: np.ndarray, enc_output: np.ndarray, mask: np.ndarray = None) -> np.ndarray:
return self.forward(x, enc_output, mask)
def forward(self, x: np.ndarray, enc_output: np.ndarray, mask: np.ndarray = None) -> np.ndarray:
attn_output1 = self.multi_head_attention_1.forward(x, x, x, mask)
attn_output2 = self.multi_head_attention_2.forward(attn_output1, enc_output, enc_output, mask)
output = self.feed_forward(attn_output2)
return output
最后,我们创建一个 Transformer 类 ,它集成了编码器和解码器层。
class Transformer:
def __init__(self, d_model: int, num_heads: int, d_ff: int, num_layers: int, input_vocab_size: int, target_vocab_size: int, max_seq_len: int):
self.d_model = d_model
self.num_heads = num_heads
self.d_ff = d_ff
self.num_layers = num_layers
self.input_vocab_size = input_vocab_size
self.target_vocab_size = target_vocab_size
self.max_seq_len = max_seq_len
self.encoder_layers = [EncoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)]
self.decoder_layers = [DecoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)]
self.embedding = np.random.randn(input_vocab_size, d_model) * np.sqrt(2.0 / (input_vocab_size + d_model))
self.pos_encoding = positional_encoding(max_seq_len, d_model)
self.output_layer = np.random.randn(d_model, target_vocab_size) * np.sqrt(2.0 / (d_model + target_vocab_size))
def __call__(self, input_seq: np.ndarray, target_seq: np.ndarray, mask: np.ndarray = None) -> np.ndarray:
return self.forward(input_seq, target_seq, mask)
def forward(self, input_seq: np.ndarray, target_seq: np.ndarray, mask: np.ndarray = None) -> np.ndarray:
enc_output = self.encode(input_seq, mask)
dec_output = self.decode(target_seq, enc_output, mask)
output = np.dot(dec_output, self.output_layer)
return output
def encode(self, input_seq: np.ndarray, mask: np.ndarray = None) -> np.ndarray:
seq_len = input_seq.shape[1]
x = self.embedding[input_seq] + self.pos_encoding[:seq_len, :]
for layer in self.encoder_layers:
x = layer(x, mask)
return x
def decode(self, target_seq: np.ndarray, enc_output: np.ndarray, mask: np.ndarray = None) -> np.ndarray:
seq_len = target_seq.shape[1]
x = self.embedding[target_seq] + self.pos_encoding[:seq_len, :]
for layer in self.decoder_layers:
x = layer(x, enc_output, mask)
return x
# Example
d_model = 512
num_heads = 8
d_ff = 2048
num_layers = 6
input_vocab_size = 10000
target_vocab_size = 10000
max_seq_len = 100
# Create a transformer model
transformer = Transformer(d_model, num_heads, d_ff, num_layers, input_vocab_size, target_vocab_size, max_seq_len)
# Dummy input and target sequences
input_seq = np.random.randint(0, input_vocab_size, (32, 50))
target_seq = np.random.randint(0, target_vocab_size, (32, 50))
# Forward pass through the model
output = transformer(input_seq, target_seq)
print(output.shape) # Should be (batch_size, target_seq_len, target_vocab_size)
#(32, 50, 10000)
最后
最后如果您也对AI大模型感兴趣想学习却苦于没有方向👀
小编给自己收藏整理好的学习资料分享出来给大家💖
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码关注免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉如何学习AI大模型?👈
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
















 445
445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









