








车辆数据集车牌数据集,全手工labelimg标注
图片清晰用于训练效果很好 xml格式
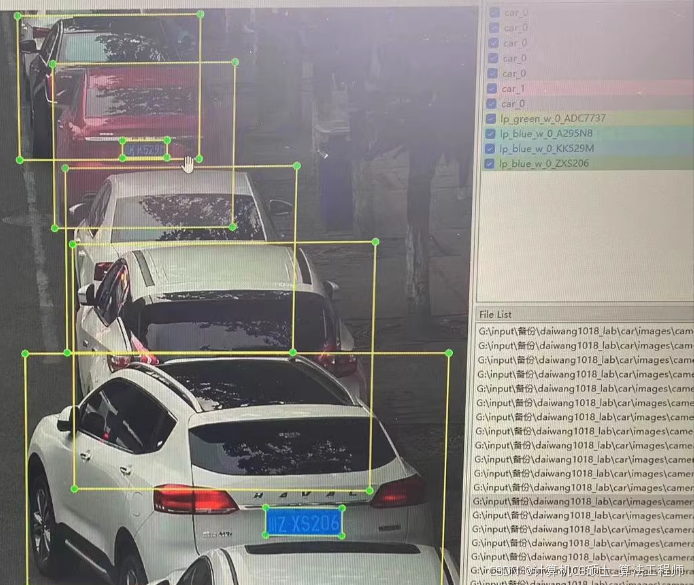
好的,我们来详细说明如何使用你手工标注的车辆车牌数据集(XML格式)来训练YOLOv8模型。以下是完整的步骤和代码示例。
项目结构
vehicle_plate_detection/
├── main.py
├── train.py
├── evaluate.py
├── infer.py
├── visualize.py
├── datasets/
│ ├── vehicle_plates/
│ │ ├── images/
│ │ ├── annotations/
│ │ ├── train.txt
│ │ └── val.txt
├── best_vehicle_plate.pt
├── requirements.txt
└── data.yaml
文件内容
requirements.txt
opencv-python==4.5.3.56
torch==2.0.0+cu117
matplotlib
numpy
pandas
albumentations
ultralytics
data.yaml
train: ./datasets/vehicle_plates/images/train
val: ./datasets/vehicle_plates/images/val
nc: 1
names: ['LicensePlate']
转换 XML 格式到 YOLO 格式
由于你的数据集是以 XML 格式存储的,我们需要将其转换为 YOLO 格式的 TXT 文件。下面是一个 Python 脚本来完成这个任务:
convert_xml_to_yolo.py
import os
import xml.etree.ElementTree as ET
import shutil
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(xml_file, txt_file, class_name):
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
with open(txt_file, 'w') as out_file:
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls != class_name or int(difficult) == 1:
continue
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write("0 " + " ".join([str(a) for a in bb]) + '\n')
def split_dataset(image_dir, annotation_dir, output_dir, class_name, train_ratio=0.8):
images = [f for f in os.listdir(image_dir) if f.endswith(('.bmp', '.jpg', '.jpeg', '.png'))]
num_train = int(len(images) * train_ratio)
train_images = images[:num_train]
val_images = images[num_train:]
if not os.path.exists(os.path.join(output_dir, 'images')):
os.makedirs(os.path.join(output_dir, 'images'))
if not os.path.exists(os.path.join(output_dir, 'labels')):
os.makedirs(os.path.join(output_dir, 'labels'))
with open(os.path.join(output_dir, 'train.txt'), 'w') as train_f:
with open(os.path.join(output_dir, 'val.txt'), 'w') as val_f:
for img_name in train_images:
src_img_path = os.path.join(image_dir, img_name)
dst_img_path = os.path.join(output_dir, 'images', img_name)
shutil.copy(src_img_path, dst_img_path)
train_f.write(dst_img_path + '\n')
xml_name = img_name.replace('.bmp', '.xml').replace('.jpg', '.xml').replace('.jpeg', '.xml').replace('.png', '.xml')
src_xml_path = os.path.join(annotation_dir, xml_name)
dst_txt_path = os.path.join(output_dir, 'labels', xml_name.replace('.xml', '.txt'))
convert_annotation(src_xml_path, dst_txt_path, class_name)
train_f.write(dst_txt_path + '\n')
for img_name in val_images:
src_img_path = os.path.join(image_dir, img_name)
dst_img_path = os.path.join(output_dir, 'images', img_name)
shutil.copy(src_img_path, dst_img_path)
val_f.write(dst_img_path + '\n')
xml_name = img_name.replace('.bmp', '.xml').replace('.jpg', '.xml').replace('.jpeg', '.xml').replace('.png', '.xml')
src_xml_path = os.path.join(annotation_dir, xml_name)
dst_txt_path = os.path.join(output_dir, 'labels', xml_name.replace('.xml', '.txt'))
convert_annotation(src_xml_path, dst_txt_path, class_name)
val_f.write(dst_txt_path + '\n')
# 示例用法
class_name = 'LicensePlate'
split_dataset('./datasets/vehicle_plates/images', './datasets/vehicle_plates/annotations', './datasets/vehicle_plates', class_name)
训练脚本
train.py
from ultralytics import YOLO
# 设置随机种子以保证可重复性
import torch
torch.manual_seed(42)
# 定义数据集路径
dataset_config = 'data.yaml'
# 加载预训练的YOLOv8模型
model = YOLO('yolov8n.pt')
# 训练模型
results = model.train(
imgsz=640,
batch=16,
epochs=50,
data=dataset_config,
weights='yolov8n.pt',
name='vehicle_plate',
project='runs/train'
)
# 打印训练结果
print(results)
评估脚本
evaluate.py
from ultralytics import YOLO
# 初始化YOLOv8模型
model_path = 'runs/train/vehicle_plate/weights/best.pt'
# 加载模型
model = YOLO(model_path)
# 评估模型
metrics = model.val(data='data.yaml', imgsz=640)
# 打印评估结果
print(metrics)
推理脚本
infer.py
from ultralytics import YOLO
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 初始化YOLOv8模型
model_path = 'runs/train/vehicle_plate/weights/best.pt'
model = YOLO(model_path)
def detect_and_visualize(image_path):
results = model.predict(source=image_path, conf=0.25, iou=0.45, agnostic_nms=False)
for result in results:
boxes = result.boxes.cpu().numpy()
im_array = result.orig_img
for box in boxes:
r = box.xyxy[0].astype(int)
cls = int(box.cls[0])
conf = box.conf[0]
label = f'{model.names[cls]} {conf:.2f}'
# 绘制边界框
cv2.rectangle(im_array, (r[0], r[1]), (r[2], r[3]), (0, 255, 0), 2)
# 绘制标签
cv2.putText(im_array, label, (r[0], r[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 显示图像
plt.imshow(cv2.cvtColor(im_array, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()
if __name__ == "__main__":
image_path = 'path/to/your/image.jpg' # 替换为你的图像路径
detect_and_visualize(image_path)
可视化脚本
visualize.py
from ultralytics import YOLO
import cv2
import numpy as np
import matplotlib.pyplot as plt
import random
# 初始化YOLOv8模型
model_path = 'runs/train/vehicle_plate/weights/best.pt'
model = YOLO(model_path)
def visualize_dataset(dataset_path, num_samples=5):
with open(dataset_path, 'r') as f:
lines = f.readlines()
sample_paths = random.sample(lines, num_samples)
for path in sample_paths:
path = path.strip()
results = model.predict(source=path, conf=0.25, iou=0.45, agnostic_nms=False)
for result in results:
boxes = result.boxes.cpu().numpy()
im_array = result.orig_img
for box in boxes:
r = box.xyxy[0].astype(int)
cls = int(box.cls[0])
conf = box.conf[0]
label = f'{model.names[cls]} {conf:.2f}'
# 绘制边界框
cv2.rectangle(im_array, (r[0], r[1]), (r[2], r[3]), (0, 255, 0), 2)
# 绘制标签
cv2.putText(im_array, label, (r[0], r[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 显示图像
plt.imshow(cv2.cvtColor(im_array, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()
if __name__ == "__main__":
dataset_path = 'datasets/vehicle_plates/train.txt' # 替换为你的训练集路径
visualize_dataset(dataset_path)
运行步骤总结
-
克隆项目仓库(如果有的话):
git clone https://github.com/yourusername/vehicle_plate_detection.git cd vehicle_plate_detection -
安装依赖项:
conda create --name vehicle_plate_env python=3.8 conda activate vehicle_plate_env pip install -r requirements.txt -
准备数据集:
- 将你的车辆车牌图像放入
datasets/vehicle_plates/images目录。 - 将对应的XML标注文件放入
datasets/vehicle_plates/annotations目录。 - 使用脚本划分数据集为训练集和验证集,并生成
train.txt和val.txt文件。
示例脚本
convert_xml_to_yolo.py已经提供在上面。运行转换脚本:
python convert_xml_to_yolo.py - 将你的车辆车牌图像放入
-
训练模型:
python train.py -
评估模型:
python evaluate.py -
运行推理:
python infer.py -
可视化数据集:
python visualize.py
操作界面
- 选择图片进行检测: 修改
infer.py中的image_path变量指向你要检测的图片路径,然后运行python infer.py。 - 批量检测: 在
visualize.py中设置dataset_path为你想要可视化的数据集路径,然后运行python visualize.py。
详细解释
requirements.txt
列出项目所需的所有Python包及其版本。
data.yaml
配置数据集路径和类别信息,用于YOLOv8模型训练。
convert_xml_to_yolo.py
将Pascal VOC格式的XML标注文件转换为YOLO格式的TXT文件,并划分数据集为训练集和验证集。
train.py
加载预训练的YOLOv8模型并使用自定义数据集进行训练。训练完成后打印训练结果。
evaluate.py
加载训练好的YOLOv8模型并对验证集进行评估,打印评估结果。
infer.py
对单张图像进行预测并可视化检测结果。
visualize.py
对数据集中的一些样本进行预测并可视化检测结果。
希望这些详细的信息和代码能够帮助你顺利实施和优化你的车辆车牌检测系统。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









