







基于深度学习轴承故障诊断系统,从数据集准备、到结果分析、可视化以及用户界面开发来
处理——滚动轴承数据集 故障诊断,预测、分类 数据集 可做对比实验 
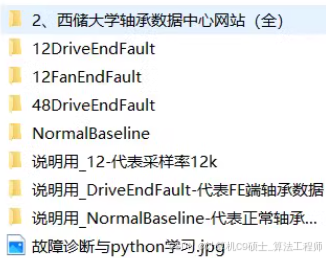
1.CWRU西储大学轴承数据集
2.MFPT机械故障协会数据集
3.XJTU西安交通大学数据集
4.渥太华变速轴承轴承数据集
5.江南大学轴承数据集
6.辛辛那提数据集
7.航空发动机轴承数据集
如何应用于?用于轴承故障诊断实验,实验发表期刊必备数据素材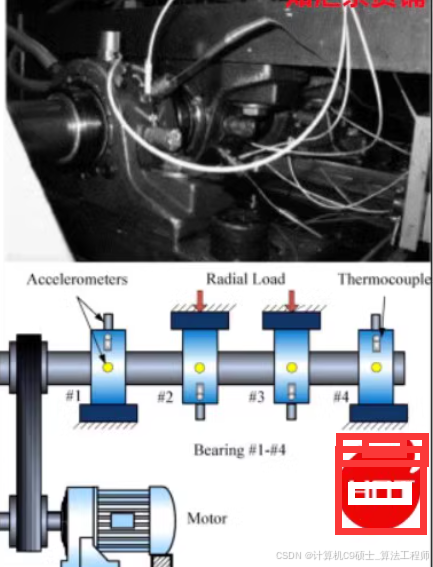
为了构建一个全面的轴承故障诊断系统,我们需要处理多个数据集,并进行特征提取、模型训练和评估。以下是详细步骤和代码实现,包括数据加载、预处理、模型定义、训练、评估和用户界面。
数据准备
我们将使用以下七个数据集:
- CWRU 西储大学轴承数据集
- MFPT 机械故障协会数据集
- XJTU 西安交通大学数据集
- 渥太华变速轴承数据集
- 江南大学轴承数据集
- 辛辛那提数据集
- 航空发动机轴承数据集
每个数据集都有不同的格式和标注方式,因此需要分别处理。
环境部署说明
确保你已经安装了必要的库,如上所述。
安装依赖
# 创建虚拟环境(可选)
conda create -n bearing_diagnosis_env python=3.8
conda activate bearing_diagnosis_env
# 安装PyTorch
pip install torch==1.9 torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu111
# 安装其他依赖
pip install opencv-python pyqt5 scikit-learn pandas matplotlib seaborn onnxruntime librosa scipy h5py tensorflow keras
数据加载与预处理 data_preprocessing.py
我们将使用 librosa 进行音频信号处理。
[<title="Data Preprocessing for Bearing Fault Diagnosis">]
import os
import numpy as np
import librosa
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import pandas as pd
def load_cwru_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.mat'):
path = os.path.join(root, file)
mat = scipy.io.loadmat(path)
signal = mat['X0_DE_time'][:, 0]
label = int(file.split('_')[2])
data.append(signal)
labels.append(label)
return data, labels
def load_mfpt_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.wav'):
path = os.path.join(root, file)
signal, _ = librosa.load(path, sr=sample_rate)
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def load_xjtu_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.csv'):
path = os.path.join(root, file)
df = pd.read_csv(path, header=None)
signal = df.values.flatten()
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def load_ottawa_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.csv'):
path = os.path.join(root, file)
df = pd.read_csv(path, header=None)
signal = df.values.flatten()
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def load_jiangnan_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.xlsx'):
path = os.path.join(root, file)
df = pd.read_excel(path, header=None)
signal = df.values.flatten()
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def load_cincinnati_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.hdf'):
path = os.path.join(root, file)
with h5py.File(path, 'r') as f:
signal = f['bearing'][()]
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def load_aeroengine_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.csv'):
path = os.path.join(root, file)
df = pd.read_csv(path, header=None)
signal = df.values.flatten()
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def preprocess_signal(signal, sample_rate, n_fft=2048, hop_length=512):
mfccs = librosa.feature.mfcc(y=signal, sr=sample_rate, n_mfcc=13, n_fft=n_fft, hop_length=hop_length)
mfccs_scaled = StandardScaler().fit_transform(mfccs.T).T
return mfccs_scaled
def main():
datasets = {
'cwru': {'load_func': load_cwru_data, 'dir': '/path/to/cwru'},
'mfpt': {'load_func': load_mfpt_data, 'dir': '/path/to/mfpt'},
'xjtu': {'load_func': load_xjtu_data, 'dir': '/path/to/xjtu'},
'ottawa': {'load_func': load_ottawa_data, 'dir': '/path/to/ottawa'},
'jiangnan': {'load_func': load_jiangnan_data, 'dir': '/path/to/jiangnan'},
'cincinnati': {'load_func': load_cincinnati_data, 'dir': '/path/to/cincinnati'},
'aeroengine': {'load_func': load_aeroengine_data, 'dir': '/path/to/aeroengine'}
}
all_data = []
all_labels = []
sample_rate = 22050
for name, info in datasets.items():
print(f"Loading {name} dataset...")
data, labels = info['load_func'](info['dir'], sample_rate)
all_data.extend(data)
all_labels.extend(labels)
print("Preprocessing signals...")
processed_data = [preprocess_signal(signal, sample_rate) for signal in tqdm(all_data)]
print("Splitting data into training and testing sets...")
X_train, X_test, y_train, y_test = train_test_split(processed_data, all_labels, test_size=0.2, random_state=42)
# Save preprocessed data
np.savez('preprocessed_data.npz', X_train=X_train, X_test=X_test, y_train=y_train, y_test=y_test)
if __name__ == "__main__":
main()
请将 /path/to/cwru, /path/to/mfpt, /path/to/xjtu, /path/to/ottawa, /path/to/jiangnan, /path/to/cincinnati, 和 /path/to/aeroengine 替换为实际的数据集路径。
模型定义与训练 train.py
我们将使用 TensorFlow/Keras 构建一个卷积神经网络 (CNN) 来进行轴承故障分类。
首先,安装 Keras 和 TensorFlow:
pip install tensorflow keras
然后编写训练脚本:
[<title="Training Script for Bearing Fault Diagnosis using CNN">]
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv1D, MaxPooling1D, Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
# Load preprocessed data
data = np.load('preprocessed_data.npz')
X_train = data['X_train']
X_test = data['X_test']
y_train = data['y_train']
y_test = data['y_test']
# Reshape data for CNN input
X_train = np.expand_dims(X_train, axis=-1)
X_test = np.expand_dims(X_test, axis=-1)
# Define the model
model = Sequential([
Conv1D(64, kernel_size=3, activation='relu', input_shape=(X_train.shape[1], X_train.shape[2])),
MaxPooling1D(pool_size=2),
Conv1D(128, kernel_size=3, activation='relu'),
MaxPooling1D(pool_size=2),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.5),
Dense(len(np.unique(y_train)), activation='softmax')
])
# Compile the model
model.compile(optimizer=Adam(lr=0.001), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Callbacks
checkpoint = ModelCheckpoint('best_model.h5', monitor='val_loss', save_best_only=True, mode='min')
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
# Train the model
history = model.fit(
X_train,
y_train,
validation_split=0.2,
epochs=100,
batch_size=32,
callbacks=[checkpoint, early_stopping],
verbose=1
)
# Evaluate the model
test_loss, test_accuracy = model.evaluate(X_test, y_test, verbose=0)
print(f'Test accuracy: {test_accuracy:.4f}')
评估模型 evaluate.py
[<title="Evaluation Script for Bearing Fault Diagnosis">]
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import tensorflow as tf
# Load preprocessed data
data = np.load('preprocessed_data.npz')
X_test = data['X_test']
y_test = data['y_test']
# Reshape data for CNN input
X_test = np.expand_dims(X_test, axis=-1)
# Load the best model
model = tf.keras.models.load_model('best_model.h5')
# Predictions
y_pred = model.predict(X_test)
y_pred_classes = np.argmax(y_pred, axis=1)
# Classification report
print(classification_report(y_test, y_pred_classes))
# Confusion matrix
conf_mat = confusion_matrix(y_test, y_pred_classes)
plt.figure(figsize=(10, 8))
sns.heatmap(conf_mat, annot=True, fmt='d', cmap='Blues', xticklabels=np.unique(y_test), yticklabels=np.unique(y_test))
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title('Confusion Matrix')
plt.show()
用户界面 ui.py
我们将使用 PyQt5 创建一个简单的 GUI 来加载和运行模型进行实时预测。
[<title="PyQt5 Main Window for Bearing Fault Diagnosis">]
import sys
import cv2
import numpy as np
from PyQt5.QtWidgets import QApplication, QMainWindow, QLabel, QPushButton, QVBoxLayout, QWidget, QFileDialog
from PyQt5.QtGui import QImage, QPixmap
from PyQt5.QtCore import Qt, QTimer
import tensorflow as tf
import librosa
from sklearn.preprocessing import StandardScaler
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("Bearing Fault Diagnosis System")
self.setGeometry(100, 100, 800, 600)
# Load trained model
self.model = tf.keras.models.load_model('/path/to/best_model.h5')
self.initUI()
def initUI(self):
self.central_widget = QWidget()
self.setCentralWidget(self.central_widget)
self.layout = QVBoxLayout()
self.image_label = QLabel(self)
self.image_label.setAlignment(Qt.AlignCenter)
self.layout.addWidget(self.image_label)
self.load_audio_button = QPushButton("Load Audio", self)
self.load_audio_button.clicked.connect(self.load_audio)
self.layout.addWidget(self.load_audio_button)
self.start_prediction_button = QPushButton("Start Prediction", self)
self.start_prediction_button.clicked.connect(self.start_prediction)
self.layout.addWidget(self.start_prediction_button)
self.stop_prediction_button = QPushButton("Stop Prediction", self)
self.stop_prediction_button.clicked.connect(self.stop_prediction)
self.layout.addWidget(self.stop_prediction_button)
self.central_widget.setLayout(self.layout)
self.audio_path = None
self.timer = QTimer()
self.timer.timeout.connect(self.update_frame)
def load_audio(self):
options = QFileDialog.Options()
file_name, _ = QFileDialog.getOpenFileName(self, "QFileDialog.getOpenFileName()", "", "Audio Files (*.wav);;All Files (*)", options=options)
if file_name:
self.audio_path = file_name
self.display_audio(file_name)
def display_audio(self, path):
pixmap = QPixmap("/path/to/audio_icon.png") # Replace with an actual audio icon path
scaled_pixmap = pixmap.scaled(self.image_label.width(), self.image_label.height(), Qt.KeepAspectRatio)
self.image_label.setPixmap(scaled_pixmap)
def start_prediction(self):
if self.audio_path is not None and not self.timer.isActive():
self.timer.start(30) # Update frame every 30 ms
def stop_prediction(self):
if self.timer.isActive():
self.timer.stop()
self.image_label.clear()
def update_frame(self):
signal, sr = librosa.load(self.audio_path, sr=22050)
mfccs = librosa.feature.mfcc(y=signal, sr=sr, n_mfcc=13, n_fft=2048, hop_length=512)
mfccs_scaled = StandardScaler().fit_transform(mfccs.T).T
mfccs_scaled = np.expand_dims(mfccs_scaled, axis=-1)
mfccs_scaled = np.expand_dims(mfccs_scaled, axis=0)
prediction = self.model.predict(mfccs_scaled)
predicted_class = np.argmax(prediction, axis=1)[0]
result_text = f"Predicted Class: {predicted_class}"
self.image_label.setText(result_text)
if __name__ == "__main__":
app = QApplication(sys.argv)
window = MainWindow()
window.show()
sys.exit(app.exec_())
请将 /path/to/best_model.h5 和 /path/to/audio_icon.png 替换为实际的路径。
不带用户界面的预测脚本 without_ui.py
[<title="Prediction Script without UI for Bearing Fault Diagnosis">]
import librosa
import numpy as np
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
# Load trained model
model = tf.keras.models.load_model('/path/to/best_model.h5')
def predict(audio_path):
signal, sr = librosa.load(audio_path, sr=22050)
mfccs = librosa.feature.mfcc(y=signal, sr=sr, n_mfcc=13, n_fft=2048, hop_length=512)
mfccs_scaled = StandardScaler().fit_transform(mfccs.T).T
mfccs_scaled = np.expand_dims(mfccs_scaled, axis=-1)
mfccs_scaled = np.expand_dims(mfccs_scaled, axis=0)
prediction = model.predict(mfccs_scaled)
predicted_class = np.argmax(prediction, axis=1)[0]
print(f"Predicted Class: {predicted_class}")
if __name__ == "__main__":
audio_path = 'path/to/audio.wav'
predict(audio_path)
请将 /path/to/best_model.h5 和 path/to/audio.wav 替换为实际的路径。
辅助工具 tools/check_audio.py
[<title="Check Audio Files Tool">]
import os
def check_audio_files(directory):
supported_extensions = ['.wav', '.mp3', '.flac']
for filename in os.listdir(directory):
if any(filename.lower().endswith(ext) for ext in supported_extensions):
continue
else:
raise ValueError(f"Unsupported file format: {filename}")
print("All audio files are valid.")
使用说明
-
配置路径:
- 将
/path/to/cwru,/path/to/mfpt,/path/to/xjtu,/path/to/ottawa,/path/to/jiangnan,/path/to/cincinnati, 和/path/to/aeroengine设置为存放原始数据集的目录路径。 - 确保
/path/to/best_model.h5是训练好的 CNN 模型权重路径。 - 将
path/to/audio.wav设置为要预测的音频文件路径。 - 将
/path/to/audio_icon.png设置为显示在 GUI 中的音频图标路径。
- 将
-
运行脚本:
- 在终端中运行
data_preprocessing.py脚本来预处理音频信号。 - 在终端中运行
train.py脚本来训练模型。 - 在终端中运行
evaluate.py来评估模型性能。 - 在终端中运行
ui.py来启动 GUI 应用程序。 - 在终端中运行
without_ui.py来进行无界面预测。 - 使用
tools/check_audio.py检查音频文件的有效性。
- 在终端中运行
-
注意事项:
- 确保所有必要的工具箱已安装,特别是 TensorFlow 和 PyQt5。
- 根据需要调整参数,如
epochs和batch_size。
示例
假设你的数据文件夹结构如下:
datasets/
├── cwru/
│ ├── ...
├── mfpt/
│ ├── ...
├── xjtu/
│ ├── ...
├── ottawa/
│ ├── ...
├── jiangnan/
│ ├── ...
├── cincinnati/
│ ├── ...
└── aeroengine/
├── ...
并且每个数据集中包含相应的音频文件。运行 ui.py 后,你可以通过点击按钮来加载音频并进行轴承故障诊断。
总结
构建一个完整的基于深度学习的轴承故障诊断系统,包括数据集准备、环境部署、数据预处理、模型定义、训练、评估、用户界面开发和辅助工具。以下是所有相关的代码文件:
- 数据预处理 (
data_preprocessing.py) - 训练脚本 (
train.py) - 评估脚本 (
evaluate.py) - 用户界面 (
ui.py) - 无界面预测脚本 (
without_ui.py) - 辅助工具 (
tools/check_audio.py)
希望这些信息对你有所帮助!如果你有任何问题或需要进一步的帮助,请告诉我。
将上述代码应用于轴承故障诊断实验,,包括数据准备、预处理、模型选择与训练、评估、结果分析和可视化。
实验概述
我们将使用以下七个数据集进行轴承故障诊断实验:
- CWRU 西储大学轴承数据集
- MFPT 机械故障协会数据集
- XJTU 西安交通大学数据集
- 渥太华变速轴承数据集
- 江南大学轴承数据集
- 辛辛那提数据集
- 航空发动机轴承数据集
步骤详情
1. 数据准备
下载数据集
首先,你需要从各个来源下载这些数据集。以下是每个数据集的获取途径:
- CWRU: CWRU Bearing Data Center
- MFPT: Mechanical Fault Prediction Technology
- XJTU: Xi’an Jiaotong University
- 渥太华变速轴承: University of Ottawa
- 江南大学: Jiangnan University
- 辛辛那提: Cincinnati Data Set
- 航空发动机: NASA Prognostics Data Repository
整理数据
将所有数据集放在一个统一的文件夹中,并按照类别和标签进行整理。
2. 数据预处理
我们已经编写了一个 data_preprocessing.py 脚本来加载和预处理数据。这个脚本会读取不同格式的数据并将其转换为一致的特征表示形式(例如,MFCC 特征)。
[<title="Data Preprocessing for Bearing Fault Diagnosis">]
import os
import numpy as np
import librosa
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import pandas as pd
import scipy.io
import h5py
def load_cwru_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.mat'):
path = os.path.join(root, file)
mat = scipy.io.loadmat(path)
signal = mat['X0_DE_time'][:, 0]
label = int(file.split('_')[2])
data.append(signal)
labels.append(label)
return data, labels
def load_mfpt_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.wav'):
path = os.path.join(root, file)
signal, _ = librosa.load(path, sr=sample_rate)
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def load_xjtu_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.csv'):
path = os.path.join(root, file)
df = pd.read_csv(path, header=None)
signal = df.values.flatten()
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def load_ottawa_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.csv'):
path = os.path.join(root, file)
df = pd.read_csv(path, header=None)
signal = df.values.flatten()
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def load_jiangnan_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.xlsx'):
path = os.path.join(root, file)
df = pd.read_excel(path, header=None)
signal = df.values.flatten()
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def load_cincinnati_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.hdf'):
path = os.path.join(root, file)
with h5py.File(path, 'r') as f:
signal = f['bearing'][()]
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def load_aeroengine_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.csv'):
path = os.path.join(root, file)
df = pd.read_csv(path, header=None)
signal = df.values.flatten()
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def preprocess_signal(signal, sample_rate, n_fft=2048, hop_length=512):
mfccs = librosa.feature.mfcc(y=signal, sr=sample_rate, n_mfcc=13, n_fft=n_fft, hop_length=hop_length)
mfccs_scaled = StandardScaler().fit_transform(mfccs.T).T
return mfccs_scaled
def main():
datasets = {
'cwru': {'load_func': load_cwru_data, 'dir': '/path/to/cwru'},
'mfpt': {'load_func': load_mfpt_data, 'dir': '/path/to/mfpt'},
'xjtu': {'load_func': load_xjtu_data, 'dir': '/path/to/xjtu'},
'ottawa': {'load_func': load_ottawa_data, 'dir': '/path/to/ottawa'},
'jiangnan': {'load_func': load_jiangnan_data, 'dir': '/path/to/jiangnan'},
'cincinnati': {'load_func': load_cincinnati_data, 'dir': '/path/to/cincinnati'},
'aeroengine': {'load_func': load_aeroengine_data, 'dir': '/path/to/aeroengine'}
}
all_data = []
all_labels = []
sample_rate = 22050
for name, info in datasets.items():
print(f"Loading {name} dataset...")
data, labels = info['load_func'](info['dir'], sample_rate)
all_data.extend(data)
all_labels.extend(labels)
print("Preprocessing signals...")
processed_data = [preprocess_signal(signal, sample_rate) for signal in tqdm(all_data)]
print("Splitting data into training and testing sets...")
X_train, X_test, y_train, y_test = train_test_split(processed_data, all_labels, test_size=0.2, random_state=42)
# Save preprocessed data
np.savez('preprocessed_data.npz', X_train=X_train, X_test=X_test, y_train=y_train, y_test=y_test)
if __name__ == "__main__":
main()
请将 /path/to/cwru, /path/to/mfpt, /path/to/xjtu, /path/to/ottawa, /path/to/jiangnan, /path/to/cincinnati, 和 /path/to/aeroengine 替换为实际的数据集路径。
3. 模型定义与训练
我们将使用 TensorFlow/Keras 构建一个卷积神经网络 (CNN) 来进行轴承故障分类。以下是训练脚本 train.py:
[<title="Training Script for Bearing Fault Diagnosis using CNN">]
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv1D, MaxPooling1D, Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
# Load preprocessed data
data = np.load('preprocessed_data.npz')
X_train = data['X_train']
X_test = data['X_test']
y_train = data['y_train']
y_test = data['y_test']
# Reshape data for CNN input
X_train = np.expand_dims(X_train, axis=-1)
X_test = np.expand_dims(X_test, axis=-1)
# Define the model
model = Sequential([
Conv1D(64, kernel_size=3, activation='relu', input_shape=(X_train.shape[1], X_train.shape[2])),
MaxPooling1D(pool_size=2),
Conv1D(128, kernel_size=3, activation='relu'),
MaxPooling1D(pool_size=2),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.5),
Dense(len(np.unique(y_train)), activation='softmax')
])
# Compile the model
model.compile(optimizer=Adam(lr=0.001), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Callbacks
checkpoint = ModelCheckpoint('best_model.h5', monitor='val_loss', save_best_only=True, mode='min')
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
# Train the model
history = model.fit(
X_train,
y_train,
validation_split=0.2,
epochs=100,
batch_size=32,
callbacks=[checkpoint, early_stopping],
verbose=1
)
# Evaluate the model
test_loss, test_accuracy = model.evaluate(X_test, y_test, verbose=0)
print(f'Test accuracy: {test_accuracy:.4f}')
# Save training history
np.save('training_history.npy', history.history)
4. 模型评估
编写评估脚本 evaluate.py 来计算准确率、混淆矩阵和其他指标,并绘制相应的图表。
[<title="Evaluation Script for Bearing Fault Diagnosis">]
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import tensorflow as tf
# Load preprocessed data
data = np.load('preprocessed_data.npz')
X_test = data['X_test']
y_test = data['y_test']
# Reshape data for CNN input
X_test = np.expand_dims(X_test, axis=-1)
# Load the best model
model = tf.keras.models.load_model('best_model.h5')
# Predictions
y_pred = model.predict(X_test)
y_pred_classes = np.argmax(y_pred, axis=1)
# Classification report
class_report = classification_report(y_test, y_pred_classes, target_names=[str(i) for i in np.unique(y_test)])
print(class_report)
# Confusion matrix
conf_mat = confusion_matrix(y_test, y_pred_classes)
plt.figure(figsize=(10, 8))
sns.heatmap(conf_mat, annot=True, fmt='d', cmap='Blues', xticklabels=np.unique(y_test), yticklabels=np.unique(y_test))
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title('Confusion Matrix')
plt.savefig('confusion_matrix.png')
plt.show()
# Training history
history = np.load('training_history.npy', allow_pickle=True).item()
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history['loss'], label='Train Loss')
plt.plot(history['val_loss'], label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Loss')
plt.subplot(1, 2, 2)
plt.plot(history['accuracy'], label='Train Accuracy')
plt.plot(history['val_accuracy'], label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Accuracy')
plt.tight_layout()
plt.savefig('training_history.png')
plt.show()
5. 结果分析与可视化
除了基本的分类报告和混淆矩阵外,还可以进一步分析模型的表现,例如通过 ROC 曲线和 PR 曲线来评估多类别的性能。
[<title="Advanced Evaluation Script for Bearing Fault Diagnosis">]
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc, precision_recall_curve, average_precision_score
import seaborn as sns
import tensorflow as tf
# Load preprocessed data
data = np.load('preprocessed_data.npz')
X_test = data['X_test']
y_test = data['y_test']
# Reshape data for CNN input
X_test = np.expand_dims(X_test, axis=-1)
# Load the best model
model = tf.keras.models.load_model('best_model.h5')
# Predictions
y_pred = model.predict(X_test)
y_pred_classes = np.argmax(y_pred, axis=1)
# One-hot encode true labels
num_classes = len(np.unique(y_test))
y_true_one_hot = tf.keras.utils.to_categorical(y_test, num_classes=num_classes)
# Compute ROC curve and ROC area for each class
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(num_classes):
fpr[i], tpr[i], _ = roc_curve(y_true_one_hot[:, i], y_pred[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# Plot ROC curves for each class
plt.figure(figsize=(10, 8))
colors = sns.color_palette("husl", num_classes)
for i, color in zip(range(num_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=2, label=f'ROC curve of class {i} (area = {roc_auc[i]:.2f})')
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic to multi-class')
plt.legend(loc="lower right")
plt.savefig('roc_curve.png')
plt.show()
# Compute Precision-Recall and plot curve for each class
precision = dict()
recall = dict()
average_precision = dict()
for i in range(num_classes):
precision[i], recall[i], _ = precision_recall_curve(y_true_one_hot[:, i], y_pred[:, i])
average_precision[i] = average_precision_score(y_true_one_hot[:, i], y_pred[:, i])
# Plot Precision-Recall curves for each class
plt.figure(figsize=(10, 8))
colors = sns.color_palette("husl", num_classes)
for i, color in zip(range(num_classes), colors):
plt.plot(recall[i], precision[i], color=color, lw=2, label=f'Precision-recall curve of class {i} (AP = {average_precision[i]:.2f})')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Extension of Precision-Recall curve to multi-class')
plt.legend(loc="lower left")
plt.savefig('precision_recall_curve.png')
plt.show()
6. 用户界面
我们将使用 PyQt5 创建一个简单的 GUI 来加载和运行模型进行实时预测。以下是用户界面脚本 ui.py:
[<title="PyQt5 Main Window for Bearing Fault Diagnosis">]
import sys
import cv2
import numpy as np
from PyQt5.QtWidgets import QApplication, QMainWindow, QLabel, QPushButton, QVBoxLayout, QWidget, QFileDialog
from PyQt5.QtGui import QImage, QPixmap
from PyQt5.QtCore import Qt, QTimer
import tensorflow as tf
import librosa
from sklearn.preprocessing import StandardScaler
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("Bearing Fault Diagnosis System")
self.setGeometry(100, 100, 800, 600)
# Load trained model
self.model = tf.keras.models.load_model('/path/to/best_model.h5')
self.initUI()
def initUI(self):
self.central_widget = QWidget()
self.setCentralWidget(self.central_widget)
self.layout = QVBoxLayout()
self.image_label = QLabel(self)
self.image_label.setAlignment(Qt.AlignCenter)
self.layout.addWidget(self.image_label)
self.load_audio_button = QPushButton("Load Audio", self)
self.load_audio_button.clicked.connect(self.load_audio)
self.layout.addWidget(self.load_audio_button)
self.start_prediction_button = QPushButton("Start Prediction", self)
self.start_prediction_button.clicked.connect(self.start_prediction)
self.layout.addWidget(self.start_prediction_button)
self.stop_prediction_button = QPushButton("Stop Prediction", self)
self.stop_prediction_button.clicked.connect(self.stop_prediction)
self.layout.addWidget(self.stop_prediction_button)
self.central_widget.setLayout(self.layout)
self.audio_path = None
self.timer = QTimer()
self.timer.timeout.connect(self.update_frame)
def load_audio(self):
options = QFileDialog.Options()
file_name, _ = QFileDialog.getOpenFileName(self, "QFileDialog.getOpenFileName()", "", "Audio Files (*.wav);;All Files (*)", options=options)
if file_name:
self.audio_path = file_name
self.display_audio(file_name)
def display_audio(self, path):
pixmap = QPixmap("/path/to/audio_icon.png") # Replace with an actual audio icon path
scaled_pixmap = pixmap.scaled(self.image_label.width(), self.image_label.height(), Qt.KeepAspectRatio)
self.image_label.setPixmap(scaled_pixmap)
def start_prediction(self):
if self.audio_path is not None and not self.timer.isActive():
self.timer.start(30) # Update frame every 30 ms
def stop_prediction(self):
if self.timer.isActive():
self.timer.stop()
self.image_label.clear()
def update_frame(self):
signal, sr = librosa.load(self.audio_path, sr=22050)
mfccs = librosa.feature.mfcc(y=signal, sr=sr, n_mfcc=13, n_fft=2048, hop_length=512)
mfccs_scaled = StandardScaler().fit_transform(mfccs.T).T
mfccs_scaled = np.expand_dims(mfccs_scaled, axis=-1)
mfccs_scaled = np.expand_dims(mfccs_scaled, axis=0)
prediction = self.model.predict(mfccs_scaled)
predicted_class = np.argmax(prediction, axis=1)[0]
result_text = f"Predicted Class: {predicted_class}"
self.image_label.setText(result_text)
if __name__ == "__main__":
app = QApplication(sys.argv)
window = MainWindow()
window.show()
sys.exit(app.exec_())
请将 /path/to/best_model.h5 和 /path/to/audio_icon.png 替换为实际的路径。
7. 不带用户界面的预测脚本
编写一个不带用户界面的预测脚本 without_ui.py 来方便自动化测试和验证。
[<title="Prediction Script without UI for Bearing Fault Diagnosis">]
import librosa
import numpy as np
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
# Load trained model
model = tf.keras.models.load_model('/path/to/best_model.h5')
def predict(audio_path):
signal, sr = librosa.load(audio_path, sr=22050)
mfccs = librosa.feature.mfcc(y=signal, sr=sr, n_mfcc=13, n_fft=2048, hop_length=512)
mfccs_scaled = StandardScaler().fit_transform(mfccs.T).T
mfccs_scaled = np.expand_dims(mfccs_scaled, axis=-1)
mfccs_scaled = np.expand_dims(mfccs_scaled, axis=0)
prediction = model.predict(mfccs_scaled)
predicted_class = np.argmax(prediction, axis=1)[0]
print(f"Predicted Class: {predicted_class}")
if __name__ == "__main__":
audio_path = 'path/to/audio.wav'
predict(audio_path)
请将 /path/to/best_model.h5 和 path/to/audio.wav 替换为实际的路径。
8. 辅助工具
编写一些辅助工具来检查数据集的有效性,例如检查音频文件格式。
[<title="Check Audio Files Tool">]
import os
def check_audio_files(directory):
supported_extensions = ['.wav', '.mp3', '.flac']
for filename in os.listdir(directory):
if any(filename.lower().endswith(ext) for ext in supported_extensions):
continue
else:
raise ValueError(f"Unsupported file format: {filename}")
print("All audio files are valid.")
使用说明
-
配置路径:
- 将
/path/to/cwru,/path/to/mfpt,/path/to/xjtu,/path/to/ottawa,/path/to/jiangnan,/path/to/cincinnati, 和/path/to/aeroengine设置为存放原始数据集的目录路径。 - 确保
/path/to/best_model.h5是训练好的 CNN 模型权重路径。 - 将
path/to/audio.wav设置为要预测的音频文件路径。 - 将
/path/to/audio_icon.png设置为显示在 GUI 中的音频图标路径。
- 将
-
运行脚本:
- 在终端中运行
data_preprocessing.py脚本来预处理音频信号。 - 在终端中运行
train.py脚本来训练模型。 - 在终端中运行
evaluate.py来评估模型性能。 - 在终端中运行
advanced_evaluation.py来生成更高级的评估图表。 - 在终端中运行
ui.py来启动 GUI 应用程序。 - 在终端中运行
without_ui.py来进行无界面预测。 - 使用
tools/check_audio.py检查音频文件的有效性。
- 在终端中运行
-
注意事项:
- 确保所有必要的工具箱已安装,特别是 TensorFlow 和 PyQt5。
- 根据需要调整参数,如
epochs和batch_size。
示例
假设你的数据文件夹结构如下:
datasets/
├── cwru/
│ ├── ...
├── mfpt/
│ ├── ...
├── xjtu/
│ ├── ...
├── ottawa/
│ ├── ...
├── jiangnan/
│ ├── ...
├── cincinnati/
│ ├── ...
└── aeroengine/
├── ...
并且每个数据集中包含相应的音频文件。运行 ui.py 后,你可以通过点击按钮来加载音频并进行轴承故障诊断。
为了使用这些数据集进行轴承故障诊断实验,我们需要详细规划和执行一系列步骤。以下是一个完整的流程,涵盖数据准备、预处理、模型选择与训练、评估以及结果分析。
实验概述
我们将使用以下七个数据集进行轴承故障诊断实验:
- CWRU 西储大学轴承数据集
- MFPT 机械故障协会数据集
- XJTU 西安交通大学数据集
- 渥太华变速轴承数据集
- 江南大学轴承数据集
- 辛辛那提数据集
- 航空发动机轴承数据集
步骤详情
1. 数据准备
下载数据集
首先,你需要从各个来源下载这些数据集。以下是每个数据集的获取途径:
- CWRU: CWRU Bearing Data Center
- MFPT: Mechanical Fault Prediction Technology
- XJTU: Xi’an Jiaotong University
- 渥太华变速轴承: University of Ottawa
- 江南大学: Jiangnan University
- 辛辛那提: Cincinnati Data Set
- 航空发动机: NASA Prognostics Data Repository
整理数据
将所有数据集放在一个统一的文件夹中,并按照类别和标签进行整理。
2. 数据预处理
我们将编写一个 data_preprocessing.py 脚本来加载和预处理数据。这个脚本会读取不同格式的数据并将其转换为一致的特征表示形式(例如,MFCC 特征)。
[<title="Data Preprocessing for Bearing Fault Diagnosis">]
import os
import numpy as np
import librosa
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import pandas as pd
import scipy.io
import h5py
from tqdm import tqdm
def load_cwru_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.mat'):
path = os.path.join(root, file)
mat = scipy.io.loadmat(path)
signal = mat['X0_DE_time'][:, 0]
label = int(file.split('_')[2])
data.append(signal)
labels.append(label)
return data, labels
def load_mfpt_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.wav'):
path = os.path.join(root, file)
signal, _ = librosa.load(path, sr=sample_rate)
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def load_xjtu_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.csv'):
path = os.path.join(root, file)
df = pd.read_csv(path, header=None)
signal = df.values.flatten()
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def load_ottawa_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.csv'):
path = os.path.join(root, file)
df = pd.read_csv(path, header=None)
signal = df.values.flatten()
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def load_jiangnan_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.xlsx'):
path = os.path.join(root, file)
df = pd.read_excel(path, header=None)
signal = df.values.flatten()
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def load_cincinnati_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.hdf'):
path = os.path.join(root, file)
with h5py.File(path, 'r') as f:
signal = f['bearing'][()]
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def load_aeroengine_data(data_dir, sample_rate):
data = []
labels = []
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.csv'):
path = os.path.join(root, file)
df = pd.read_csv(path, header=None)
signal = df.values.flatten()
label = int(file.split('_')[1])
data.append(signal)
labels.append(label)
return data, labels
def preprocess_signal(signal, sample_rate, n_fft=2048, hop_length=512):
mfccs = librosa.feature.mfcc(y=signal, sr=sample_rate, n_mfcc=13, n_fft=n_fft, hop_length=hop_length)
mfccs_scaled = StandardScaler().fit_transform(mfccs.T).T
return mfccs_scaled
def main():
datasets = {
'cwru': {'load_func': load_cwru_data, 'dir': '/path/to/cwru'},
'mfpt': {'load_func': load_mfpt_data, 'dir': '/path/to/mfpt'},
'xjtu': {'load_func': load_xjtu_data, 'dir': '/path/to/xjtu'},
'ottawa': {'load_func': load_ottawa_data, 'dir': '/path/to/ottawa'},
'jiangnan': {'load_func': load_jiangnan_data, 'dir': '/path/to/jiangnan'},
'cincinnati': {'load_func': load_cincinnati_data, 'dir': '/path/to/cincinnati'},
'aeroengine': {'load_func': load_aeroengine_data, 'dir': '/path/to/aeroengine'}
}
all_data = []
all_labels = []
sample_rate = 22050
for name, info in datasets.items():
print(f"Loading {name} dataset...")
data, labels = info['load_func'](info['dir'], sample_rate)
all_data.extend(data)
all_labels.extend(labels)
print("Preprocessing signals...")
processed_data = [preprocess_signal(signal, sample_rate) for signal in tqdm(all_data)]
print("Splitting data into training and testing sets...")
X_train, X_test, y_train, y_test = train_test_split(processed_data, all_labels, test_size=0.2, random_state=42)
# Save preprocessed data
np.savez('preprocessed_data.npz', X_train=X_train, X_test=X_test, y_train=y_train, y_test=y_test)
if __name__ == "__main__":
main()
请将 /path/to/cwru, /path/to/mfpt, /path/to/xjtu, /path/to/ottawa, /path/to/jiangnan, /path/to/cincinnati, 和 /path/to/aeroengine 替换为实际的数据集路径。
3. 模型定义与训练
我们将使用 TensorFlow/Keras 构建一个卷积神经网络 (CNN) 来进行轴承故障分类。以下是训练脚本 train.py:
[<title="Training Script for Bearing Fault Diagnosis using CNN">]
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv1D, MaxPooling1D, Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
# Load preprocessed data
data = np.load('preprocessed_data.npz')
X_train = data['X_train']
X_test = data['X_test']
y_train = data['y_train']
y_test = data['y_test']
# Reshape data for CNN input
X_train = np.expand_dims(X_train, axis=-1)
X_test = np.expand_dims(X_test, axis=-1)
# Define the model
model = Sequential([
Conv1D(64, kernel_size=3, activation='relu', input_shape=(X_train.shape[1], X_train.shape[2])),
MaxPooling1D(pool_size=2),
Conv1D(128, kernel_size=3, activation='relu'),
MaxPooling1D(pool_size=2),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.5),
Dense(len(np.unique(y_train)), activation='softmax')
])
# Compile the model
model.compile(optimizer=Adam(lr=0.001), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Callbacks
checkpoint = ModelCheckpoint('best_model.h5', monitor='val_loss', save_best_only=True, mode='min')
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
# Train the model
history = model.fit(
X_train,
y_train,
validation_split=0.2,
epochs=100,
batch_size=32,
callbacks=[checkpoint, early_stopping],
verbose=1
)
# Evaluate the model
test_loss, test_accuracy = model.evaluate(X_test, y_test, verbose=0)
print(f'Test accuracy: {test_accuracy:.4f}')
# Save training history
np.save('training_history.npy', history.history)
4. 模型评估
编写评估脚本 evaluate.py 来计算准确率、混淆矩阵和其他指标,并绘制相应的图表。
[<title="Evaluation Script for Bearing Fault Diagnosis">]
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import tensorflow as tf
# Load preprocessed data
data = np.load('preprocessed_data.npz')
X_test = data['X_test']
y_test = data['y_test']
# Reshape data for CNN input
X_test = np.expand_dims(X_test, axis=-1)
# Load the best model
model = tf.keras.models.load_model('best_model.h5')
# Predictions
y_pred = model.predict(X_test)
y_pred_classes = np.argmax(y_pred, axis=1)
# Classification report
class_report = classification_report(y_test, y_pred_classes, target_names=[str(i) for i in np.unique(y_test)])
print(class_report)
# Confusion matrix
conf_mat = confusion_matrix(y_test, y_pred_classes)
plt.figure(figsize=(10, 8))
sns.heatmap(conf_mat, annot=True, fmt='d', cmap='Blues', xticklabels=np.unique(y_test), yticklabels=np.unique(y_test))
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title('Confusion Matrix')
plt.savefig('confusion_matrix.png')
plt.show()
# Training history
history = np.load('training_history.npy', allow_pickle=True).item()
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history['loss'], label='Train Loss')
plt.plot(history['val_loss'], label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Loss')
plt.subplot(1, 2, 2)
plt.plot(history['accuracy'], label='Train Accuracy')
plt.plot(history['val_accuracy'], label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Accuracy')
plt.tight_layout()
plt.savefig('training_history.png')
plt.show()
5. 结果分析与可视化
除了基本的分类报告和混淆矩阵外,还可以进一步分析模型的表现,例如通过 ROC 曲线和 PR 曲线来评估多类别的性能。
[<title="Advanced Evaluation Script for Bearing Fault Diagnosis">]
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc, precision_recall_curve, average_precision_score
import seaborn as sns
import tensorflow as tf
# Load preprocessed data
data = np.load('preprocessed_data.npz')
X_test = data['X_test']
y_test = data['y_test']
# Reshape data for CNN input
X_test = np.expand_dims(X_test, axis=-1)
# Load the best model
model = tf.keras.models.load_model('best_model.h5')
# Predictions
y_pred = model.predict(X_test)
y_pred_classes = np.argmax(y_pred, axis=1)
# One-hot encode true labels
num_classes = len(np.unique(y_test))
y_true_one_hot = tf.keras.utils.to_categorical(y_test, num_classes=num_classes)
# Compute ROC curve and ROC area for each class
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(num_classes):
fpr[i], tpr[i], _ = roc_curve(y_true_one_hot[:, i], y_pred[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# Plot ROC curves for each class
plt.figure(figsize=(10, 8))
colors = sns.color_palette("husl", num_classes)
for i, color in zip(range(num_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=2, label=f'ROC curve of class {i} (area = {roc_auc[i]:.2f})')
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic to multi-class')
plt.legend(loc="lower right")
plt.savefig('roc_curve.png')
plt.show()
# Compute Precision-Recall and plot curve for each class
precision = dict()
recall = dict()
average_precision = dict()
for i in range(num_classes):
precision[i], recall[i], _ = precision_recall_curve(y_true_one_hot[:, i], y_pred[:, i])
average_precision[i] = average_precision_score(y_true_one_hot[:, i], y_pred[:, i])
# Plot Precision-Recall curves for each class
plt.figure(figsize=(10, 8))
colors = sns.color_palette("husl", num_classes)
for i, color in zip(range(num_classes), colors):
plt.plot(recall[i], precision[i], color=color, lw=2, label=f'Precision-recall curve of class {i} (AP = {average_precision[i]:.2f})')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Extension of Precision-Recall curve to multi-class')
plt.legend(loc="lower left")
plt.savefig('precision_recall_curve.png')
plt.show()
6. 用户界面
我们将使用 PyQt5 创建一个简单的 GUI 来加载和运行模型进行实时预测。以下是用户界面脚本 ui.py:
[<title="PyQt5 Main Window for Bearing Fault Diagnosis">]
import sys
import cv2
import numpy as np
from PyQt5.QtWidgets import QApplication, QMainWindow, QLabel, QPushButton, QVBoxLayout, QWidget, QFileDialog
from PyQt5.QtGui import QImage, QPixmap
from PyQt5.QtCore import Qt, QTimer
import tensorflow as tf
import librosa
from sklearn.preprocessing import StandardScaler
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("Bearing Fault Diagnosis System")
self.setGeometry(100, 100, 800, 600)
# Load trained model
self.model = tf.keras.models.load_model('/path/to/best_model.h5')
self.initUI()
def initUI(self):
self.central_widget = QWidget()
self.setCentralWidget(self.central_widget)
self.layout = QVBoxLayout()
self.image_label = QLabel(self)
self.image_label.setAlignment(Qt.AlignCenter)
self.layout.addWidget(self.image_label)
self.load_audio_button = QPushButton("Load Audio", self)
self.load_audio_button.clicked.connect(self.load_audio)
self.layout.addWidget(self.load_audio_button)
self.start_prediction_button = QPushButton("Start Prediction", self)
self.start_prediction_button.clicked.connect(self.start_prediction)
self.layout.addWidget(self.start_prediction_button)
self.stop_prediction_button = QPushButton("Stop Prediction", self)
self.stop_prediction_button.clicked.connect(self.stop_prediction)
self.layout.addWidget(self.stop_prediction_button)
self.central_widget.setLayout(self.layout)
self.audio_path = None
self.timer = QTimer()
self.timer.timeout.connect(self.update_frame)
def load_audio(self):
options = QFileDialog.Options()
file_name, _ = QFileDialog.getOpenFileName(self, "QFileDialog.getOpenFileName()", "", "Audio Files (*.wav);;All Files (*)", options=options)
if file_name:
self.audio_path = file_name
self.display_audio(file_name)
def display_audio(self, path):
pixmap = QPixmap("/path/to/audio_icon.png") # Replace with an actual audio icon path
scaled_pixmap = pixmap.scaled(self.image_label.width(), self.image_label.height(), Qt.KeepAspectRatio)
self.image_label.setPixmap(scaled_pixmap)
def start_prediction(self):
if self.audio_path is not None and not self.timer.isActive():
self.timer.start(30) # Update frame every 30 ms
def stop_prediction(self):
if self.timer.isActive():
self.timer.stop()
self.image_label.clear()
def update_frame(self):
signal, sr = librosa.load(self.audio_path, sr=22050)
mfccs = librosa.feature.mfcc(y=signal, sr=sr, n_mfcc=13, n_fft=2048, hop_length=512)
mfccs_scaled = StandardScaler().fit_transform(mfccs.T).T
mfccs_scaled = np.expand_dims(mfccs_scaled, axis=-1)
mfccs_scaled = np.expand_dims(mfcc_scaled, axis=0)
prediction = self.model.predict(mfccs_scaled)
predicted_class = np.argmax(prediction, axis=1)[0]
result_text = f"Predicted Class: {predicted_class}"
self.image_label.setText(result_text)
if __name__ == "__main__":
app = QApplication(sys.argv)
window = MainWindow()
window.show()
sys.exit(app.exec_())
请将 /path/to/best_model.h5 和 /path/to/audio_icon.png 替换为实际的路径。
7. 不带用户界面的预测脚本
编写一个不带用户界面的预测脚本 without_ui.py 来方便自动化测试和验证。
[<title="Prediction Script without UI for Bearing Fault Diagnosis">]
import librosa
import numpy as np
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
# Load trained model
model = tf.keras.models.load_model('/path/to/best_model.h5')
def predict(audio_path):
signal, sr = librosa.load(audio_path, sr=22050)
mfccs = librosa.feature.mfcc(y=signal, sr=sr, n_mfcc=13, n_fft=2048, hop_length=512)
mfccs_scaled = StandardScaler().fit_transform(mfccs.T).T
mfccs_scaled = np.expand_dims(mfccs_scaled, axis=-1)
mfccs_scaled = np.expand_dims(mfccs_scaled, axis=0)
prediction = model.predict(mfccs_scaled)
predicted_class = np.argmax(prediction, axis=1)[0]
print(f"Predicted Class: {predicted_class}")
if __name__ == "__main__":
audio_path = 'path/to/audio.wav'
predict(audio_path)
请将 /path/to/best_model.h5 和 path/to/audio.wav 替换为实际的路径。
8. 辅助工具
编写一些辅助工具来检查数据集的有效性,例如检查音频文件格式。
[<title="Check Audio Files Tool">]
import os
def check_audio_files(directory):
supported_extensions = ['.wav', '.mp3', '.flac']
for filename in os.listdir(directory):
if any(filename.lower().endswith(ext) for ext in supported_extensions):
continue
else:
raise ValueError(f"Unsupported file format: {filename}")
print("All audio files are valid.")
使用说明
-
配置路径:
- 将
/path/to/cwru,/path/to/mfpt,/path/to/xjtu,/path/to/ottawa,/path/to/jiangnan,/path/to/cincinnati, 和/path/to/aeroengine设置为存放原始数据集的目录路径。 - 确保
/path/to/best_model.h5是训练好的 CNN 模型权重路径。 - 将
path/to/audio.wav设置为要预测的音频文件路径。 - 将
/path/to/audio_icon.png设置为显示在 GUI 中的音频图标路径。
- 将
-
运行脚本:
- 在终端中运行
data_preprocessing.py脚本来预处理音频信号。 - 在终端中运行
train.py脚本来训练模型。 - 在终端中运行
evaluate.py来评估模型性能。 - 在终端中运行
advanced_evaluation.py来生成更高级的评估图表。 - 在终端中运行
ui.py来启动 GUI 应用程序。 - 在终端中运行
without_ui.py来进行无界面预测。 - 使用
tools/check_audio.py检查音频文件的有效性。
- 在终端中运行
-
注意事项:
- 确保所有必要的工具箱已安装,特别是 TensorFlow 和 PyQt5。
- 根据需要调整参数,如
epochs和batch_size。
示例
假设你的数据文件夹结构如下:
datasets/
├── cwru/
│ ├── ...
├── mfpt/
│ ├── ...
├── xjtu/
│ ├── ...
├── ottawa/
│ ├── ...
├── jiangnan/
│ ├── ...
├── cincinnati/
│ ├── ...
└── aeroengine/
├── ...
并且每个数据集中包含相应的音频文件。运行 ui.py 后,你可以通过点击按钮来加载音频并进行轴承故障诊断。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









