







深度学习通过训练自己的标注整理数据集使用YOLOv8训练打架数据集 训练学习构建yolov8打架暴力行为检测的深度学习系统
文章目录
以下文字及代码仅供参考。
打架检测数据集

数据集说明:(共计2831张)
样本分类输出(中文):打架
样本分类输出(英文):fight
样本分类输出数量:1
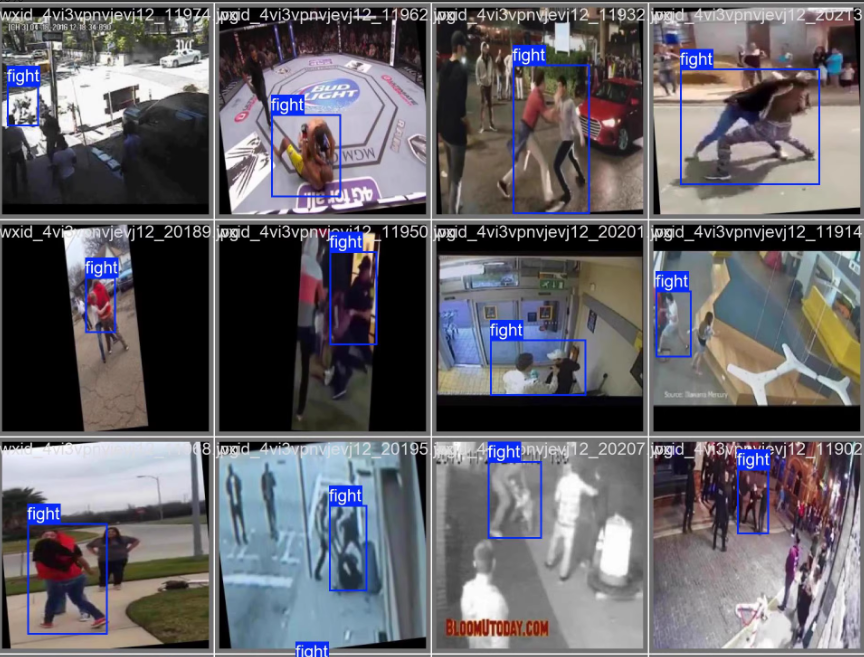
训练集train: 2359个样本
验证集valid: 472个样本

训练集和验证集样本比例:约5:1
yolo8训练命令行参考:yolo detect train model=yolov8n.pt data=detect_fight/data.yaml batch=16 epochs=1 imgsz=640 device=cuda
使用YOLOv8训练一个基于深度学习的打架暴力检测系统,以下是详细的步骤指南,包括数据准备、格式转换、数据划分、环境搭建、数据配置、模型训练、超参数配置、模型推理及性能评估。我们将数据集为例进行说明。
1. 数据准备与格式转换
首先确保你的数据集已准备好,并按照以下结构组织:
fight_dataset/
├── images/
│ ├── train/
│ └── val/
└── labels/
├── train/
└── val/
images/train/和images/val/分别存放训练和验证图像。labels/train/和labels/val/存放对应图像的标签文件(YOLO格式)。
每个标签文件包含一行信息,格式如下:class_id center_x center_y width height,所有坐标值都是相对于图像尺寸归一化的。
2. 环境搭建
安装必要的库:
pip install ultralytics
3. 数据配置
创建一个名为 data.yaml 的文件来描述数据集的路径和类别信息:
train: ./fight_dataset/images/train/
val: ./fight_dataset/images/val/
nc: 1 # 类别数量
names: ['fight'] # 类别名称
4. 模型训练
根据你提供的命令行参考,使用YOLOv8训练模型:
yolo detect train model=yolov8n.pt data=data.yaml batch=16 epochs=100 imgsz=640 device=cuda
这里,epochs 设置为100,可以根据需要调整。device=cuda 表示使用GPU加速训练。
5. 配置超参数
在训练过程中,可以通过修改 cfg/training/yolov8n.yaml 文件中的超参数来优化模型性能。例如,调整学习率、batch size等。
6. 模型推理
训练完成后,可以使用以下命令对新图像进行推理:
yolo detect predict model=runs/detect/train/weights/best.pt source=path/to/test/images/ imgsz=640 device=cuda
7. 批量推理代码示例
如果你想要编写自己的批量推理脚本,可以参考以下Python代码:
from ultralytics import YOLO
# 加载训练好的模型
model = YOLO('runs/detect/train/weights/best.pt')
# 定义测试图像目录
test_dir = 'path/to/test/images/'
# 执行批量推理
results = model.predict(source=test_dir, imgsz=640, save=True)
for r in results:
print(r.boxes) # 输出预测结果
8. 性能评估
YOLOv8自带了性能评估工具,可以在训练结束后自动计算mAP(mean Average Precision)、Precision、Recall等指标。你也可以手动运行评估:
yolo detect val model=runs/detect/train/weights/best.pt data=data.yaml imgsz=640
这将输出详细的性能评估报告,帮助你了解模型在验证集上的表现。
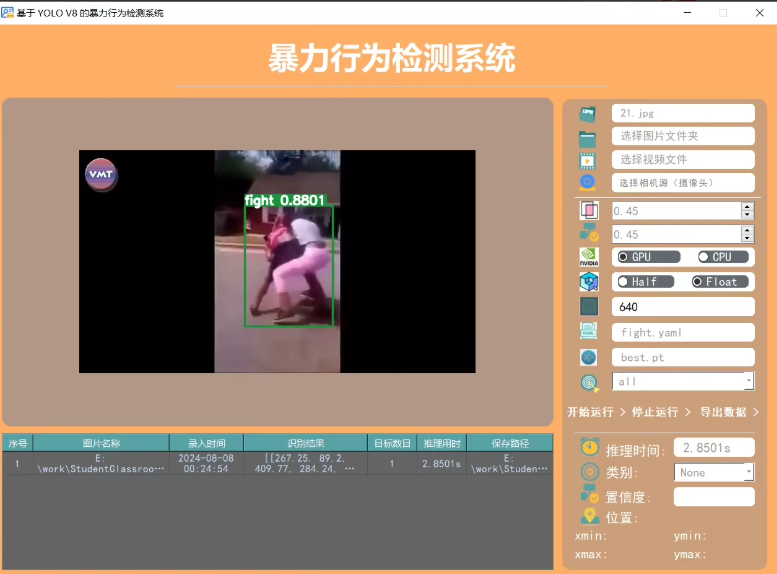
YOLOv8的暴力行为检测系统的界面,我们可以使用Python中的tkinter库来构建GUI(图形用户界面)。
代码示例,包括界面布局、功能按钮和推理逻辑。
1. 安装必要的库
确保你已经安装了tkinter和opencv-python:
pip install opencv-python
2. 界面代码
以下是完整的Python代码,用于创建如图所示的界面,并集成YOLOv8模型进行暴力行为检测:
import tkinter as tk
from tkinter import filedialog, messagebox
from PIL import Image, ImageTk
import cv2
import numpy as np
from ultralytics import YOLO
class ViolenceDetectionApp:
def __init__(self, root):
self.root = root
self.root.title("基于YOLO V8的暴力行为检测系统")
# 设置窗口大小和背景颜色
self.root.geometry("1024x768")
self.root.configure(bg="#FFA500")
# 创建标题标签
title_label = tk.Label(root, text="暴力行为检测系统", font=("Arial", 24, "bold"), bg="#FFA500")
title_label.pack(pady=20)
# 创建图像显示区域
self.image_frame = tk.Frame(root, bg="#D2B48C", width=600, height=400)
self.image_frame.pack(padx=20, pady=10)
self.image_label = tk.Label(self.image_frame, bg="#D2B48C")
self.image_label.pack()
# 创建右侧操作面板
self.control_panel = tk.Frame(root, bg="#FFA500")
self.control_panel.pack(side=tk.RIGHT, padx=20, pady=10)
# 文件选择按钮
self.create_button("选择图片文件夹", self.select_image_folder)
self.create_button("选择视频文件", self.select_video_file)
self.create_button("选择摄像头源(摄像头)", self.select_camera_source)
# 参数设置
self.threshold_var = tk.DoubleVar(value=0.45)
self.create_slider("置信度阈值", self.threshold_var, 0, 1, 0.01)
self.device_var = tk.StringVar(value="GPU")
self.create_radio_button("设备选择", ["GPU", "CPU"], self.device_var)
self.model_path_var = tk.StringVar(value="best.pt")
self.create_entry("模型路径", self.model_path_var)
# 开始运行按钮
self.run_button = tk.Button(self.control_panel, text="开始运行", command=self.start_detection)
self.run_button.pack(pady=5)
# 停止运行按钮
self.stop_button = tk.Button(self.control_panel, text="停止运行", command=self.stop_detection)
self.stop_button.pack(pady=5)
# 导出数据按钮
self.export_button = tk.Button(self.control_panel, text="导出数据", command=self.export_data)
self.export_button.pack(pady=5)
# 初始化YOLO模型
self.model = None
def create_button(self, text, command):
button = tk.Button(self.control_panel, text=text, command=command)
button.pack(pady=5)
def create_slider(self, label, var, min_val, max_val, step):
slider_frame = tk.Frame(self.control_panel, bg="#FFA500")
slider_frame.pack(pady=5)
tk.Label(slider_frame, text=label, bg="#FFA500").pack(side=tk.LEFT)
tk.Scale(slider_frame, variable=var, from_=min_val, to=max_val, resolution=step, orient=tk.HORIZONTAL).pack(side=tk.LEFT)
def create_radio_button(self, label, options, var):
radio_frame = tk.Frame(self.control_panel, bg="#FFA500")
radio_frame.pack(pady=5)
tk.Label(radio_frame, text=label, bg="#FFA500").pack(side=tk.LEFT)
for option in options:
tk.Radiobutton(radio_frame, text=option, variable=var, value=option, bg="#FFA500").pack(side=tk.LEFT)
def create_entry(self, label, var):
entry_frame = tk.Frame(self.control_panel, bg="#FFA500")
entry_frame.pack(pady=5)
tk.Label(entry_frame, text=label, bg="#FFA500").pack(side=tk.LEFT)
tk.Entry(entry_frame, textvariable=var).pack(side=tk.LEFT)
def select_image_folder(self):
folder_path = filedialog.askdirectory()
if folder_path:
print(f"Selected image folder: {folder_path}")
def select_video_file(self):
video_path = filedialog.askopenfilename(filetypes=[("Video files", "*.mp4 *.avi")])
if video_path:
print(f"Selected video file: {video_path}")
def select_camera_source(self):
camera_index = simpledialog.askinteger("Camera Source", "Enter camera index (0 for default):")
if camera_index is not None:
print(f"Selected camera source: {camera_index}")
def start_detection(self):
model_path = self.model_path_var.get()
device = self.device_var.get().lower()
threshold = self.threshold_var.get()
if not model_path:
messagebox.showerror("Error", "Please select a model path.")
return
try:
self.model = YOLO(model_path)
self.model.to(device)
# 示例:加载一张图片并进行检测
image_path = "path/to/your/image.jpg"
image = cv2.imread(image_path)
results = self.model.predict(image, conf=threshold)
for result in results:
boxes = result.boxes.xyxy.cpu().numpy()
scores = result.boxes.conf.cpu().numpy()
labels = result.boxes.cls.cpu().numpy()
for box, score, label in zip(boxes, scores, labels):
x1, y1, x2, y2 = map(int, box)
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(image, f"fight {score:.4f}", (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = Image.fromarray(image)
image = ImageTk.PhotoImage(image)
self.image_label.config(image=image)
self.image_label.image = image
except Exception as e:
messagebox.showerror("Error", str(e))
def stop_detection(self):
pass
def export_data(self):
pass
if __name__ == "__main__":
root = tk.Tk()
app = ViolenceDetectionApp(root)
root.mainloop()
3. 功能说明
- 文件选择按钮:允许用户选择图片文件夹、视频文件或摄像头源。
- 参数设置:包括置信度阈值滑块、设备选择单选按钮和模型路径输入框。
- 开始运行按钮:启动暴力行为检测。
- 停止运行按钮:停止当前检测任务。
- 导出数据按钮:导出检测结果数据。
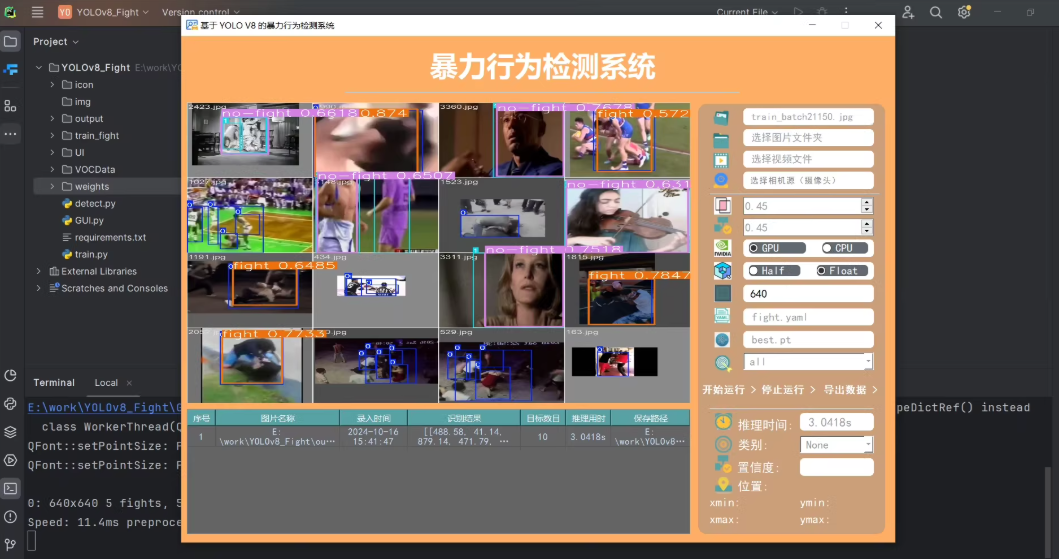
4. 注意事项
- 请根据实际情况调整文件路径和参数。
以上内容仅供参考。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









