






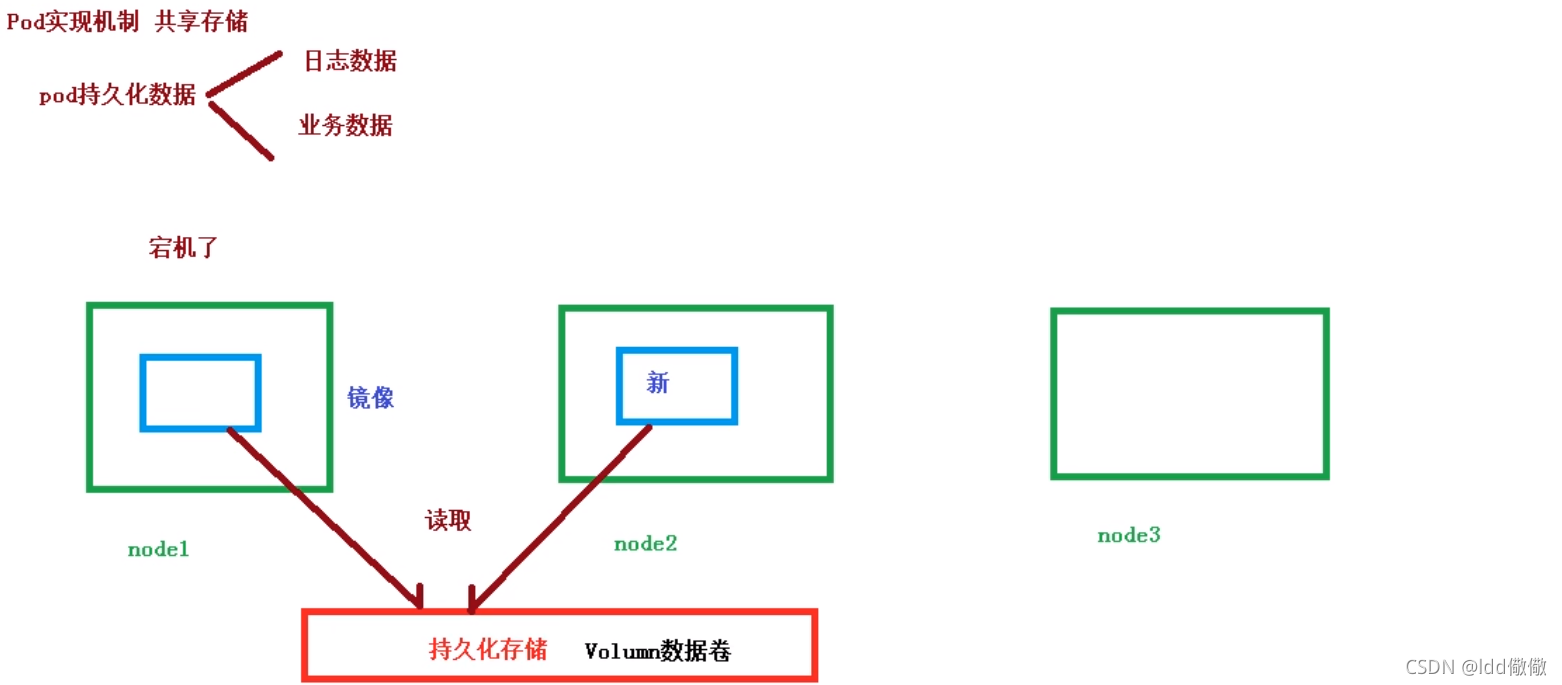
我们之前了解到,K8S有自我修复能力,意思是如果node挂掉了,那么该节点的Pod会转移到其他node中,如node2
可是如果pod在node2节点运行,node2是不是又要重新拉去镜像,那么之前数据不就没了?
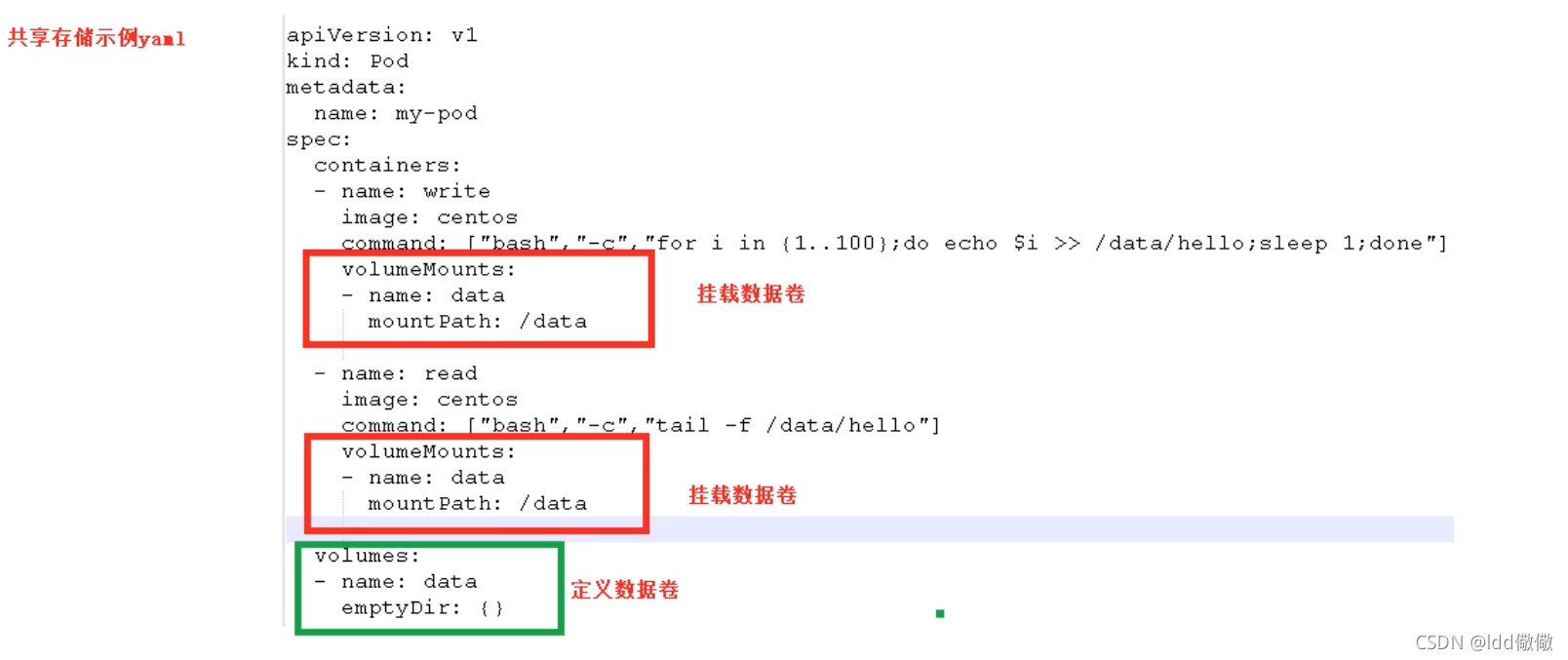
K8S做了一个持久化存储,也叫数据卷;通过持久化存储,当node1挂掉之后,n该节点的Pod会持久化存储,之后node2会从中读取数据
5.镜像拉取策略
主要有三种策略:
- IfNotPresent:默认值,镜像在宿主机上不存在才拉取
- Always:每次创建Pod都会重新拉取一次镜像
- Never:Pod永远不会主动拉取这个镜像

6.Pod资源限制
也就是我们Pod在进行调度的时候,可以对调度的资源进行限制,例如我们限制 Pod调度是使用的资源是 2C4G,那么在调度对应的node节点时,只会占用对应的资源,对于不满足资源的节点,将不会进行调度


- request:表示调度所需的资源
- limits:表示最大所占用的资源
7.Pod重启策略

重启策略主要分为以下三种
- Always:当容器终止退出后,总是重启容器,默认策略 【nginx等,需要不断提供服务】
- OnFailure:当容器异常退出(退出状态码非0)时,才重启容器。
- Never:当容器终止退出,从不重启容器 【批量任务】
8.Pod健康检查

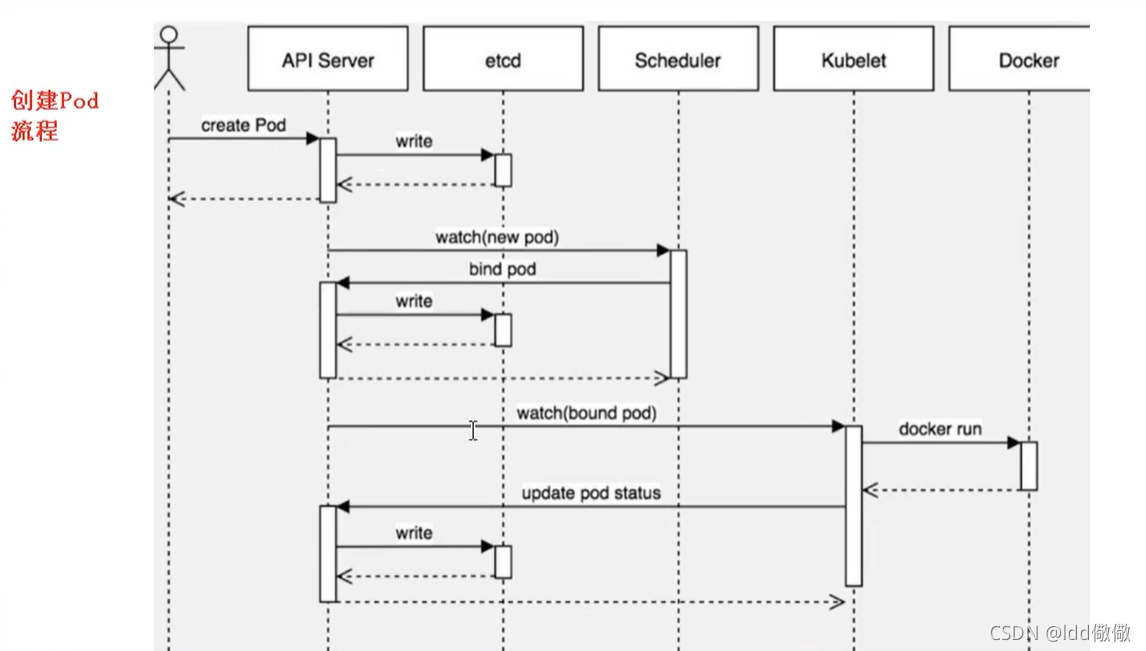
9.创建Pod流程
master节点
- 首先创建一个pod,会进入到API Server 进行创建,之后通过API Server 将pod信息存储在 Etcd中
- 在Etcd存储完成后,Etcd将存储结果返回给API Server,告诉它,我已经存储成功
- 然后是Scheduler,监控API Server是否有新的Pod,如果有的话,先是通过API server读取存储在Etcd的pod信息,之后会通过调度算法,把pod调度某个node上
node节点
- 在node节点,会通过 kubelet – apiserver 读取etcd 拿到分配在当前node节点上的pod,然后通过docker创建容器
- 创建成功后 ,会将创建结果返回给Kubectl ,通过Kubectl 更新API Server的Pod状态,之后通过API Server更新etc存储状态
- 更新后,Etcd返回给API Server,之后通过API Server 返回给Kubectl
10.影响Pod调度的属性
10.1.Pod资源限制对Pod的调度会有影响,这个之前已经提到,不再赘述
10.2.节点选择器标签影响Pod调度

关于节点选择器,其实就是有两个环境,然后环境之间所用的资源配置不同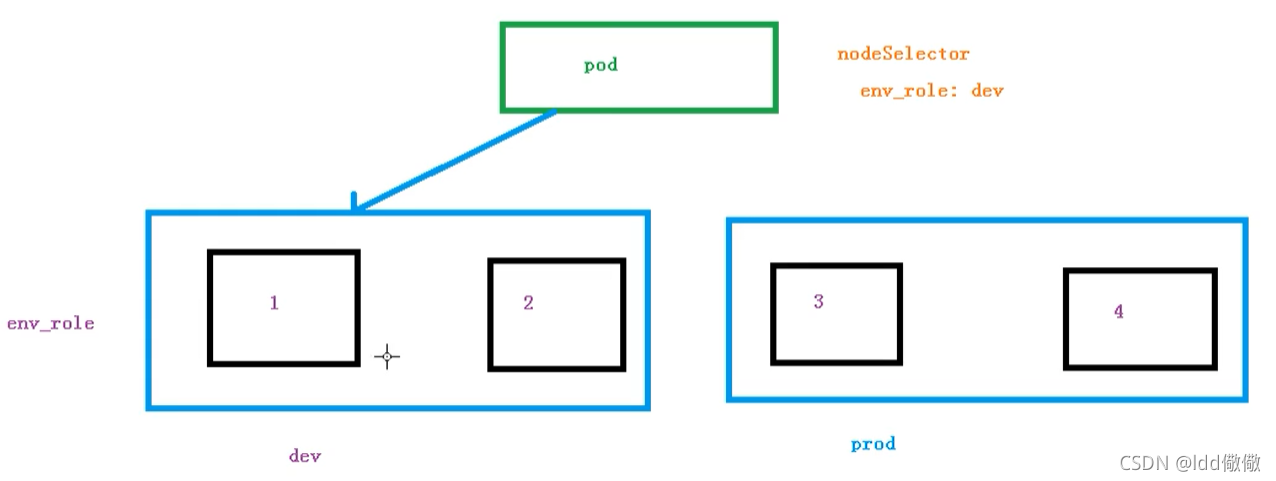
以通过以下命令,给我们的节点新增标签,然后节点选择器就会进行调度了
[root@localhost manifests]# kubectl get nodes k8s-node1 --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-node1 Ready <none> 6h6m v1.22.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node1,kubernetes.io/os=linux
[root@localhost manifests]# kubectl label node k8s-node1 env_role=dev
node/k8s-node1 labeled
[root@localhost manifests]# kubectl get nodes k8s-node1 --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-node1 Ready <none> 6h8m v1.22.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,env_role=dev,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node1,kubernetes.io/os=linux
10.3.节点亲和性
节点亲和性 nodeAffinity 和 之前nodeSelector 基本一样的,根据节点上标签约束来决定Pod调度到哪些节点上
- 硬亲和性:约束条件必须满足
- 软亲和性:尝试满足,不保证
支持常用操作符:in、NotIn、Exists、Gt、Lt、DoesNotExists
反亲和性:就是和亲和性刚刚相反,如 NotIn、DoesNotExists等

10.4. 污点和污点容忍
- nodeSelector 和 NodeAffinity,都是Prod调度到某些节点上,属于Pod的属性,是在调度的时候实现的。
- Taint 污点:节点不做普通分配调度,是节点属性
场景
- 专用节点【限制ip】
- 配置特定硬件的节点【固态硬盘】
- 基于Taint驱逐【在node1不放,在node2放】
污点相关命令
查看污点情况
kubectl describe node k8smaster | grep Taint
删除污点
kubectl taint node k8snode1 env_role:NoSchedule-
未节点添加污点
kubectl taint node [node] key=value:污点的三个值
kubectl taint node k8snode1 env\_role=yes:NoSchedule
污点值类型
- NoSchedule:一定不被调度
- PreferNoSchedule:尽量不被调度【也有被调度的几率】
- NoExecute:不会调度,并且还会驱逐Node已有Pod
污点容忍
就是某个节点可能被调度,也可能不被调度

演示例子
正常情况下,node1,node2是都有的
[root@localhost ~]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 6h3m
[root@localhost ~]# kubectl scale deployment nginx --replicas=5
deployment.apps/nginx scaled
[root@localhost ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-6799fc88d8-9gdz2 1/1 Running 0 14s 10.244.1.4 k8s-node1 <none> <none>
nginx-6799fc88d8-ct4v9 1/1 Running 0 14s 10.244.2.4 k8s-node2 <none> <none>
nginx-6799fc88d8-dfcrn 1/1 Running 0 14s 10.244.2.3 k8s-node2 <none> <none>
nginx-6799fc88d8-n692z 1/1 Running 0 6h6m 10.244.1.3 k8s-node1 <none> <none>
nginx-6799fc88d8-r6dp6 1/1 Running 0 14s 10.244.1.5 k8s-node1 <none> <none>
[root@localhost ~]#
[root@localhost ~]# kubectl delete deployment nginx
deployment.apps "nginx" deleted
[root@localhost ~]# kubectl get deployment
No resources found in default namespace.
对node1添加污点,类型为一定不会调度NoSchedule,发现创建pod后,pod运行节点只有node2
[root@localhost ~]# kubectl taint node k8s-node1 env_role=yes:NoSchedule
node/k8s-node1 tainted
[root@localhost ~]# kubectl create deployment web --image=nginx
deployment.apps/web created
[root@localhost ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-96d5df5c8-276vj 1/1 Running 0 8s 10.244.2.5 k8s-node2 <none> <none>
[root@localhost ~]# kubectl scale deployment nginx --replicas=5
Error from server (NotFound): deployments.apps "nginx" not found
[root@localhost ~]# kubectl scale deployment web --replicas=5
deployment.apps/web scaled
[root@localhost ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-96d5df5c8-276vj 1/1 Running 0 30s 10.244.2.5 k8s-node2 <none> <none>
web-96d5df5c8-8b4gz 0/1 ContainerCreating 0 3s <none> k8s-node2 <none> <none>
web-96d5df5c8-n5cg2 1/1 Running 0 3s 10.244.2.7 k8s-node2 <none> <none>
web-96d5df5c8-qpb2q 1/1 Running 0 3s 10.244.2.6 k8s-node2 <none> <none>
web-96d5df5c8-xdvkt 0/1 ContainerCreating 0 3s <none> k8s-node2 <none> <none>
查看污点是否添加
[root@localhost ~]# kubectl describe node k8s-node1 | grep Taint
Taints: env_role=yes:NoSchedule
删除污点,之后扩容发现可以调度到节点node1了
[root@localhost ~]# kubectl taint node k8s-node1 env_role:NoSchedule-
node/k8s-node1 untainted
[root@localhost ~]# kubectl describe node k8s-node1 | grep Taint
Taints: <none>
[root@localhost ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-96d5df5c8-276vj 1/1 Running 0 9m13s 10.244.2.5 k8s-node2 <none> <none>
web-96d5df5c8-8b4gz 1/1 Running 0 8m46s 10.244.2.8 k8s-node2 <none> <none>
web-96d5df5c8-n5cg2 1/1 Running 0 8m46s 10.244.2.7 k8s-node2 <none> <none>
web-96d5df5c8-qpb2q 1/1 Running 0 8m46s 10.244.2.6 k8s-node2 <none> <none>
web-96d5df5c8-xdvkt 1/1 Running 0 8m46s 10.244.2.9 k8s-node2 <none> <none>
[root@localhost ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-96d5df5c8-276vj 1/1 Running 0 9m17s 10.244.2.5 k8s-node2 <none> <none>
web-96d5df5c8-8b4gz 1/1 Running 0 8m50s 10.244.2.8 k8s-node2 <none> <none>
web-96d5df5c8-n5cg2 1/1 Running 0 8m50s 10.244.2.7 k8s-node2 <none> <none>
web-96d5df5c8-qpb2q 1/1 Running 0 8m50s 10.244.2.6 k8s-node2 <none> <none>















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









