






参考文章
图解比较详细:
图解redis跳跃表
源码的复制(注释详细):
Redis源码分析(skiplist)
图文详述:
浅析SkipList跳跃表原理及代码实现
简介
跳跃表是Redis zset的底层实现之一,zset在member较多时会采用跳跃表作为底层实现,它在添加、删除、查找节点上都拥有与红黑树相当的性能,它其实说白了就是一种特殊的链表,链表的每个节点存了不同的“层”信息,用这种分层存节点的方式在查找节点时能跳过些节点,从而使添加、删除、查找操作都拥有了O(logn)的平均时间复杂度。
和链表、字典等数据结构被广泛地应用在Redis内部不同,Redis只在两个地方用到了跳跃表,一个是实现有序集合键,另一个是在集群结点中用作内部数据结构。除此之外,跳跃表在Redis里面没有其他用途。
下面简单介绍一下跳跃表
跳跃表最低层(第一层)是一个拥有跳跃表所有节点的普通链表,每次在往跳跃表插入链表节点时一定会插入到这个最低层,至于是否插入到上层 就由抛硬币决定(这么说不是很准确,redis里这个概率是1/4而非1/2,为了表述方便先这么说),什么意思呢?
假设已经有一个跳跃表,其高度只有一层:

往表中插入节点“7”时,假设插入7时抛硬币的结果是正,则在第二层中插入“7”节点,继续抛一次看看还能不能上到第三层,为反则停止插入,上层不再插入“7”节点了:


同理插入“4”节点假设连续抛两次都抛了正面,第三次抛了反面,则“4”节点会插入到2、3层:

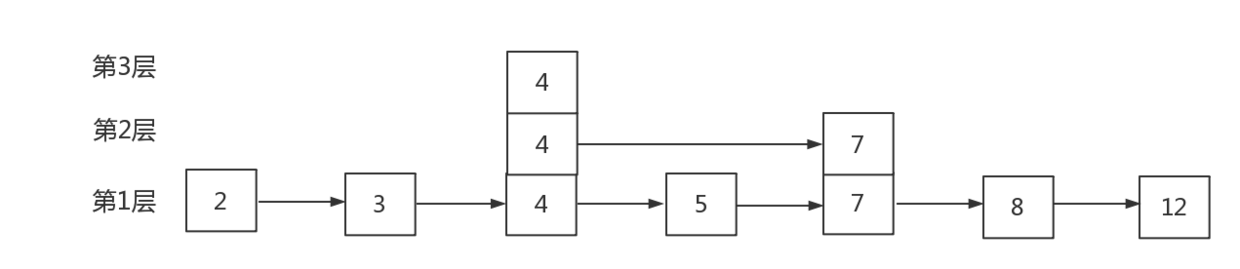
查找一个节点时,我们只需从高层到低层,一个个链表查找,每次找到该层链表中小于等于目标节点的最大节点,直到找到为止。由于高层的链表迭代时会“跳过”低层的部分节点,所以跳跃表会比正常的链表查找少查部分节点,这也是skiplist名字的由来。
假如我们需要查找节点“5”:
先遍历最高层,发现第三层头结点的下一个节点是“4”,4<5,所以游标定位到“4”节点,但是“4”节点的下一个节点是空,得继续往低层走;第二层也从“4”节点开始,“4”节点在第二层的下一个节点是“7”,7>5,公交车做过头了,回来依旧定位在“4”节点;继续往低层走,第一层“4”节点的下一个节点是“5”,这就找到了。
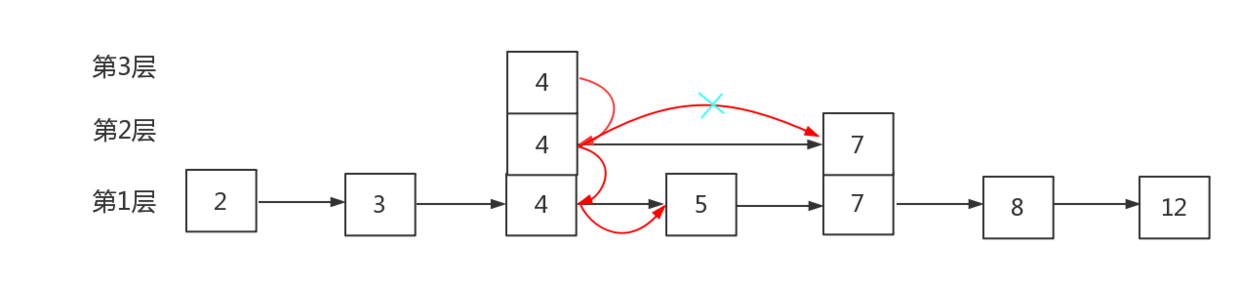
以上其实就是整个跳跃表在查找和插入时大致的流程,接下来我们详细的看一下redis中的zskiplist
结构定义和详细介绍
源码:server.h zskiplistNode和zskiplist的数据结构定义
t_zset.c 以zsl开头的函数是SkipList相关的操作函数
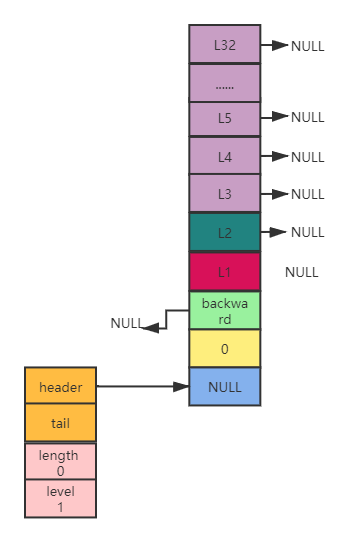
zskiplist 结构
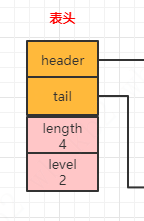
typedef struct zskiplist {
// 表头的头指针header和尾指针tail
struct zskiplistNode \*header, \*tail;
// 节点的数量
unsigned long length;
// 所有节点的最大层数
int level;
} zskiplist;
header和tail指针分别指向跳跃表的表头节点和表尾节点,通过这两个指针,定位表头节点和表尾节点的复杂度为O(1)。表尾结点是表中最后一个节点,而表头节点实际上是一个伪节点,该节点的成员对象为NULL ,分值为0,它的固定层数为32(现为64 层的最大值)
length属性记录节点的数值,程序可以在O(1)的时间复杂度返回跳跃表的长度
level属性记录跳跃表的层数,也就是表中层高最大的那个节点的层数,注意:表头节点的层高不计算在内
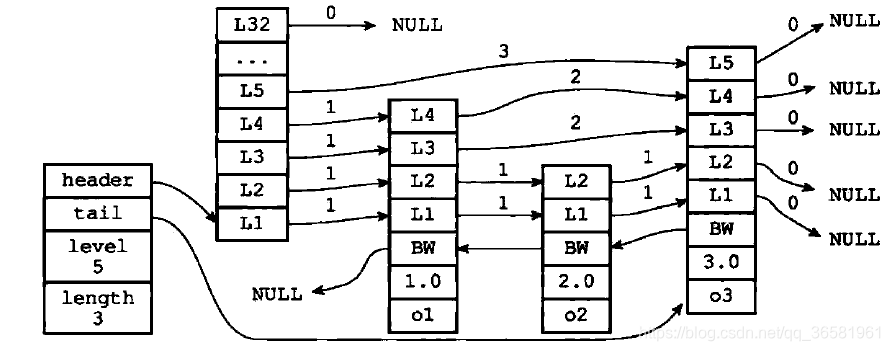
完整的跳跃表结构
zskiplistnode结构
/\* ZSETs use a specialized version of Skiplists \*/
typedef struct zskiplistNode {
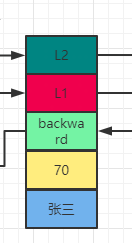
// 数据域 具体数据,对应的张三
sds ele;
// 分数
double score;
// 后退指针
struct zskiplistNode \*backward;
// 层级数组
struct zskiplistLevel {
// 前进指针
struct zskiplistNode \*forward;
// 跨度
unsigned long span;
} level[];//level本身是一个弹性数组,最大值为32,由 ZSKIPLIST\_MAXLEVEL 定义
} zskiplistNode;
sds ele具体的数据 在之前的版本中 robj *obj 标识节点的成员对象的指针
score 对象的分数 是一个浮点数 跳跃表中所有的节点 都是根据score从小到大来排序的 同一个跳跃表中,各个结点保存的成员对象必须是唯一的,但是多个结点保存的分值却可以是相同的:分值相同的结点将按照成员对象的字典顺序从小到大进行排序。
*backward 节点的后退指针 用于从表尾向表头方向访问节点:跟可以一次跳过多个节点的前进指针不同,因为每个节点只有一个后退指针,所以每次只能后退至前一个节点
level 跳跃表节点的数组可以包含多个元素,每个元素都包含一个指向其他节点的指针,程序可以通过这些层来加快访问其他节点的速度,一般来说,层的数量越多,访问其他节点的速度就越快。
每次创建一个新跳跃表节点的时候,程序根据幂次定律 ( power law,越大的数出现的概率越小)随机生成一个介于 1 和 32 之间的值作为 level 数组的大小,这个大小就是层的“高度”。
*forward 每个层都有一个指向表尾方向的前进指针(level[i].forward属性),用于从表头向表尾方向访问节点
层的跨度(level[i].span 属性)用于记录两个节点之间的距离:
两个节点之间的跨度越大, 它们相距得就越远。
指向 NULL 的所有前进指针的跨度都为 0 , 因为它们没有连向任何节点。
操作API
创建
创建空的跳跃表,其实就是创建表头和管理所有的节点的level数组。首先,定义一些变量,尝试分配内存空间。其次是初始化表头的level和length,分别赋值1和0。接着创建管理所有节点的Level的数组,是调用zslCreateNode函数,输入参数为数组大小宏常量ZSKIPLIST_MAXLEVEL(64),分数为0,对象值为NULL。(此为跳跃表得以实现重点)。再接着就是为此数组每个元素的前指针forword和跨度span初始化。最后初始化尾指针并返回值。
/\* Create a skiplist node with the specified number of levels.
\* The SDS string 'ele' is referenced by the node after the call. \*/
zskiplistNode \*zslCreateNode(int level, double score, sds ele) {
zskiplistNode \*zn =
zmalloc(sizeof(\*zn)+level\*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
}
/\* Create a new skiplist. \*/
zskiplist \*zslCreate(void) {
int j;
zskiplist \*zsl;
// 尝试分配内存空间
zsl = zmalloc(sizeof(\*zsl));
// 初始化level和length
zsl->level = 1;
zsl->length = 0;
/\*
调用下面的方法zslCreateNode
参数
数组长度ZSKIPLIST\_MAXLEVEL 64
score 分数为0
具体的元素
这一步就是创建管理所有节点的数组
并且设置表头的头指针为该数组对象的地址
\*/
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
// 为这个64位的数组赋值前进指针forword和跨度span
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
// 设置尾指针
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
随机算法
一个具有k个后继指针的结点称为k层结点。假设k层结点的数量是k+1层结点的P倍,那么其实这个跳跃表可以看成是一棵平衡的P叉树。跳跃表结点的层数,采用随机化算法得到,实现如下
/\* Returns a random level for the new skiplist node we are going to create.
\* The return value of this function is between 1 and ZSKIPLIST\_MAXLEVEL
\* (both inclusive), with a powerlaw-alike distribution where higher
\* levels are less likely to be returned. \*/
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P \* 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
ZSKIPLIST_P为0.25 level 初始化1 然后,如果持续满足条件:(random()&0xFFFF)< (ZSKIPLIST_P * 0xFFFF)的话,则level+=1。最终调整level的值,使其小于ZSKIPLIST_MAXLEVEL。
理解该算法的核心,就是要理解满足条件:**(random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF)**的概率是多少?
random()&0xFFFF形成的数,均匀分布在区间[0,0xFFFF]上,那么这个数小于(ZSKIPLIST_P * 0xFFFF)的概率是多少呢?自然就是ZSKIPLIST_P,也就是0.25了。
因此,最终返回level为1的概率是1-0.25=0.75,返回level为2的概率为0.250.75,返回level为3的概率为0.250.250.75…因此,如果返回level为k的概率为x,则返回level为k+1的概率为0.25x,换句话说,如果k层的结点数是x,那么k+1层就是0.25*x了。这就是所谓的幂次定律(powerlaw),越大的数出现的概率越小。
0xFFFF int(65535)
插入
虽然整个代码较长,但是从整体逻辑上可以分为三部分:
* 1:根据目前传入的score找到插入位置x,这个过程会保存各层x的前一个位置节点
* 就像我们对有序单链表插入节点的时候先要找到比目前数字小的节点保存下来。
* 2:根据随机函数获取level,生成新的节点
* 3:修改各个指针的指向,将创建的新节点插入。
/\* Insert a new node in the skiplist. Assumes the element does not already
\* exist (up to the caller to enforce that). The skiplist takes ownership
\* of the passed SDS string 'ele'. \*/
/\*
插入节点
参数:
zsl 表头
score 插入元素的分数
ele 插入元素的具体数据
\*/
zskiplistNode \*zslInsert(zskiplist \*zsl, double score, sds ele) {
// 使用update数组记录每层待插入元素的前一个元素
zskiplistNode \*update[ZSKIPLIST_MAXLEVEL], \*x;
// 记录前置节点与第一个节点之间的跨度 即元素在列表中的排名-1
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
// 从最大的level开始遍历 从顶到底 找到每一层待插入的位置
for (i = zsl->level-1; i >= 0; i--) {
/\* store rank that is crossed to reach the insert position \*/
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
// 直接找到第一个分数比该元素大的位置
// 或者分数与该以元素相同但是对象的ASSIC码比该元素大的位置
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
//将已走过元素的跨越元素进行计数,得到元素在列表中排名,或者是已搜寻的路径长度
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
// 记录待插入位置
update[i] = x;
}
/\* we assume the element is not already inside, since we allow duplicated
\* scores, reinserting the same element should never happen since the
\* caller of zslInsert() should test in the hash table if the element is
\* already inside or not. \*/
// 随机产生一个层数,在1到32之间,层数越高,生成的概率越低
level = zslRandomLevel();
// 如果产生的层数大于现有的最高层数 则超出层数需要初始化
if (level > zsl->level) {
// 循环遍历
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
//该元素作为这些层的第一个节点,前节点就是header
update[i] = zsl->header;
//初始化后这些层每层有两个元素,走一步就是跨越所有元素
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
//创建节点
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
//将新节点插入到各层链表中
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
// rank[0]是第0层的前置节点P1(也就是底层插入节点前面那个节点)与第一个节点的跨度
// rank[i]是第i层的前置节点P2(这一层里在插入节点前面那个节点)与第一个节点的跨度
// 插入节点X与后置节点Y的跨度f(X,Y)可由以下公式计算
// 关键在于f(P1,0)-f(P2,0)+1等于新节点与P2的跨度,这是因为跨度呈扇形形向下延伸到最底层
// 记录节点各层跨越元素情况span, 由层与层之间的跨越元素总和rank相减而得
/\* update span covered by update[i] as x is inserted here \*/
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
// 插入位置前一个节点的span在原基础上加1即可(新节点在rank[0]的后一个位置)
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/\* increment span for untouched levels \*/
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
// 第0层是双向链表, 便于redis常支持逆序类查找
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
插入的代码比较长我们分段进行分析解读
第一部分:寻找插入结点在每层上的前驱结点的代码
x = zsl->header;
// 从最大的level开始遍历 从顶到底 找到每一层待插入的位置
for (i = zsl->level-1; i >= 0; i--) {
/\* store rank that is crossed to reach the insert position \*/
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
// 直接找到第一个分数比该元素大的位置
// 或者分数与该以元素相同但是对象的ASSIC码比该元素大的位置
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
//将已走过元素的跨越元素进行计数,得到元素在列表中排名,或者是已搜寻的路径长度
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
// 记录待插入位置
update[i] = x;
}
从表头结点的最高层开始查找,首先在该层中寻找插入结点的前驱结点。只要插入结点比当前结点x在该层的后继结点x->level[i].forward要大,则首先记录x后继结点的排名:rank[i] += x->level[i].span; 接着开始比较x的后继结点:x =x->level[i].forward。
注意,因为Redis中的跳跃表中,允许分数重复而不允许成员对象重复。所以,这里的判断条件中,一旦分数相同,则要比较成员对象的字典顺序。
一旦当前结点x的后继结点为空,或者后继结点比插入结点要大,说明找到了插入结点在该层的前驱结点,记录到update数组中:update[i] = x,此时,rank[i]就是结点x的排名。
然后,开始遍历下一层,从x结点开始比较。
第二部分:将节点插入到跳跃表中
//创建节点
// 随机产生一个层数,在1到32之间,层数越高,生成的概率越低
level = zslRandomLevel();
// 如果产生的层数大于现有的最高层数 则超出层数需要初始化
if (level > zsl->level) {
// 循环遍历
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
//该元素作为这些层的第一个节点,前节点就是header
update[i] = zsl->header;
//初始化后这些层每层有两个元素,走一步就是跨越所有元素
update[i]->level[i].span = zsl->length;


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
加入社区》https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0
{
rank[i] = 0;
//该元素作为这些层的第一个节点,前节点就是header
update[i] = zsl->header;
//初始化后这些层每层有两个元素,走一步就是跨越所有元素
update[i]->level[i].span = zsl->length;
[外链图片转存中...(img-KCqp3e8R-1725711662559)]
[外链图片转存中...(img-gNrUvbcv-1725711662560)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
加入社区》https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0















 427
427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









