







源码版本: redis-4.0.1
源码位置:
一、跳跃表简介
跳跃表(SkipList),其实也是解决查找问题的一种数据结构,但是它既不属于平衡树结构,也不属于Hash结构,它的特点是元素是有序的。有关于跳跃表的更多解释,大家可以参考 张铁蕾老师 - Redis内部数据结构详解(6)——skiplist 中有关跳跃表的描述部分,我接下来主要分析有关于Redis跳跃表本身的代码部分,Redis作者antirez提到Redis中的实现的跳跃表与一般跳跃表相比具有以下三个特点:
a) this implementation allows for repeated scores. // 允许分值重复
b) the comparison is not just by key (our ‘score’) but by satellite data. //对比的时候不仅比较分值还比较对象的值
c) there is a back pointer, so it’s a doubly linked list with the back pointers being only at “level 1”. //有一个后退指针,即在第一层实现了一个双向链表,允许后退遍历
接下来我们去看下SkipList的数据结构定义。
二、数据结构定义
有许多数据结构的定义其实是按照(结点+组织方式)来的,结点就是一个数据点,组织方式就是把结点组织起来形成数据结构,比如 双端链表 (ListNode+list)、字典(dictEntry+dictht+dict)等,今天所说的SkipList其实也一样,我们首先看下它的结点定义:
typedef struct zskiplistNode {
sds ele; //数据域
double score; //分值
struct zskiplistNode *backward; //后向指针,使得跳表第一层组织为双向链表
struct zskiplistLevel { //每一个结点的层级
struct zskiplistNode *forward; //某一层的前向结点
unsigned int span; //某一层距离下一个结点的跨度
} level[]; //level本身是一个柔性数组,最大值为32,由 ZSKIPLIST_MAXLEVEL 定义
} zskiplistNode;
接下来是组织方式,即使用上面的zskiplistNode组织起一个SkipList:
typedef struct zskiplist {
struct zskiplistNode *header; //头部
struct zskiplistNode *tail; //尾部
unsigned long length; //长度,即一共有多少个元素
int level; //最大层级,即跳表目前的最大层级
} zskiplist;核心的数据结构就是上面两个。
三、创建、插入、查找、删除、释放
我们以下面这个例子来跟踪SkipList的代码,其中会涉及到的操作有创建、插入、查找、删除、释放等。(ps:将Redis中main函数的代码替换成下面的代码就可以测试)
// 需要声明下 zslGetElementByRank() 函数,main函数中使用
zkiplistNode* zslGetElementByRank(zskiplist *zsl, unsigned long rank);
int main(int argc, char **argv) {
unsigned long ret;
zskiplistNode *node;
zskiplist *zsl = zslCreate();
zslInsert(zsl, 65.5, sdsnew("tom")); //level = 1
zslInsert(zsl, 87.5, sdsnew("jack")); //level = 4
zslInsert(zsl, 70.0, sdsnew("alice")); //level = 3
zslInsert(zsl, 95.0, sdsnew("tony")); //level = 2
zrangespec spec = { //定义一个区间, 70.0 <= x <= 90.0
.min = 70.0,
.max = 90.0,
.minex = 0,
.maxex = 0};
printf("zslFirstInRange 70.0 <= x <= 90.0, x is:"); // 找到符合区间的最小值
node = zslFirstInRange(zsl, &spec);
printf("%s->%f\n", node->ele, node->score);
printf("zslLastInRange 70.0 <= x <= 90.0, x is:"); // 找到符合区间的最大值
node = zslLastInRange(zsl, &spec);
printf("%s->%f\n", node->ele, node->score);
printf("tony's Ranking is :"); // 根据分数获取排名
ret = zslGetRank(zsl, 95.0, sdsnew("tony"));
printf("%lu\n", ret);
printf("The Rank equal 4 is :"); // 根据排名获取分数
node = zslGetElementByRank(zsl, 4);
printf("%s->%f\n", node->ele, node->score);
ret = zslDelete(zsl, 70.0, sdsnew("alice"), &node); // 删除元素
if (ret == 1) {
printf("Delete node:%s->%f success!\n", node->ele, node->score);
}
zslFree(zsl); // 释放zsl
return 0;
}
Out >
zslFirstInRange 70.0 <= x <= 90.0, x is:alice->70.000000
zslLastInRange 70.0 <= x <= 90.0, x is:jack->87.500000
tony's Ranking is :4
The Rank equal 4 is :tony->95.000000
Delete node:alice->70.000000 success!- 接下来我们逐行分析代码,首先
zskiplist *zsl = zslCreate();创建了一个SkipList,需要关注的重点是会初始化zsl->header为最大层级32,因为 ZSKIPLIST_MAXLEVEL 定义为32,这个原因与SkipList中获取Level的随机函数有关,具体参考文章开头给的博客链接。我们看下zslCreate的代码:
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl)); // 申请空间
zsl->level = 1; // 初始层级定义为1
zsl->length = 0;
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL); // 初始化header为32层
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL; // tail目前为NULL
return zsl;
}
// zslCreateNode根据传入的level和score以及ele创建一个level层的zskiplistNode
zskiplistNode *zslCreateNode(int level, double score, sds ele) {
zskiplistNode *zn =
zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
}目前我们的zsl如下图所示:

- 接下来我们开始向zsl中插入数据,
zslInsert(zsl, 65.5, sdsnew("tom"));zslInsert的代码如下所示:
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
/* 虽然整个代码较长,但是从整体逻辑上可以分为三部分:
* 1:根据目前传入的score找到插入位置x,这个过程会保存各层x的前一个位置节点
* 就像我们对有序单链表插入节点的时候先要找到比目前数字小的节点保存下来。
* 2:根据随机函数获取level,生成新的节点
* 3:修改各个指针的指向,将创建的新节点插入。
*/
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
/* 第一步: 根据目前传入的score找到插入位置x,并且将各层的前置节点保存至rank[]中 */
serverAssert(!isnan(score));
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
/* 第二步:获取level,生成新的节点 */
level = zslRandomLevel();
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele);
/* 第三步:修改各个指针的指向,将创建的新节点插入 */
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
/* 更新backword的指向 */
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}需要注意的是span的含义,它表示当前节点距离下一个节点的跨度,之所以可以根据rank排名获取元素,就是根据span确定的。update[i]保存的就是第 i 层应该插入节点的前一个节点,在第三步更新指针的时候使用。插入了一个元素的zsl如下图所示(level=1):
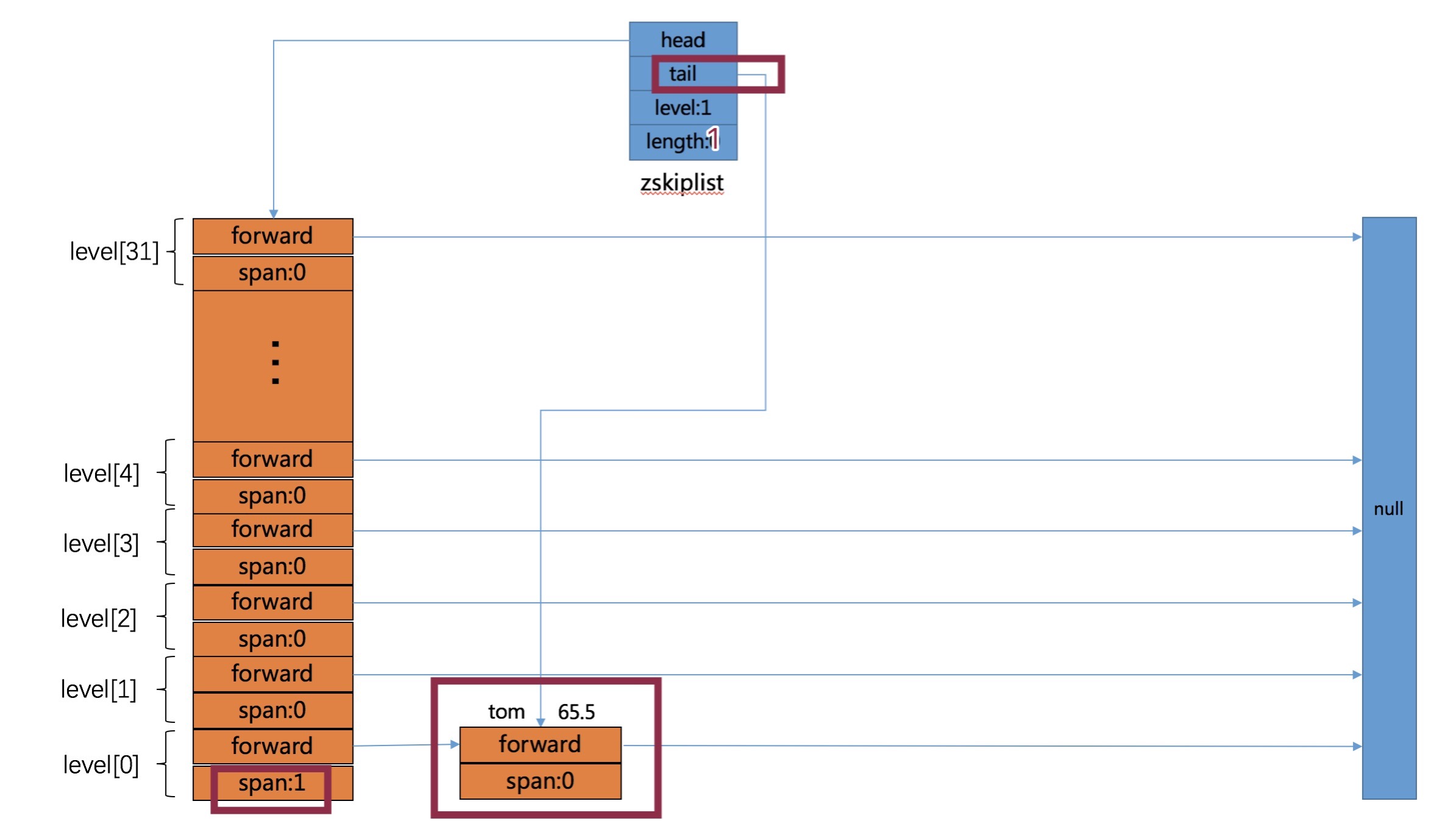
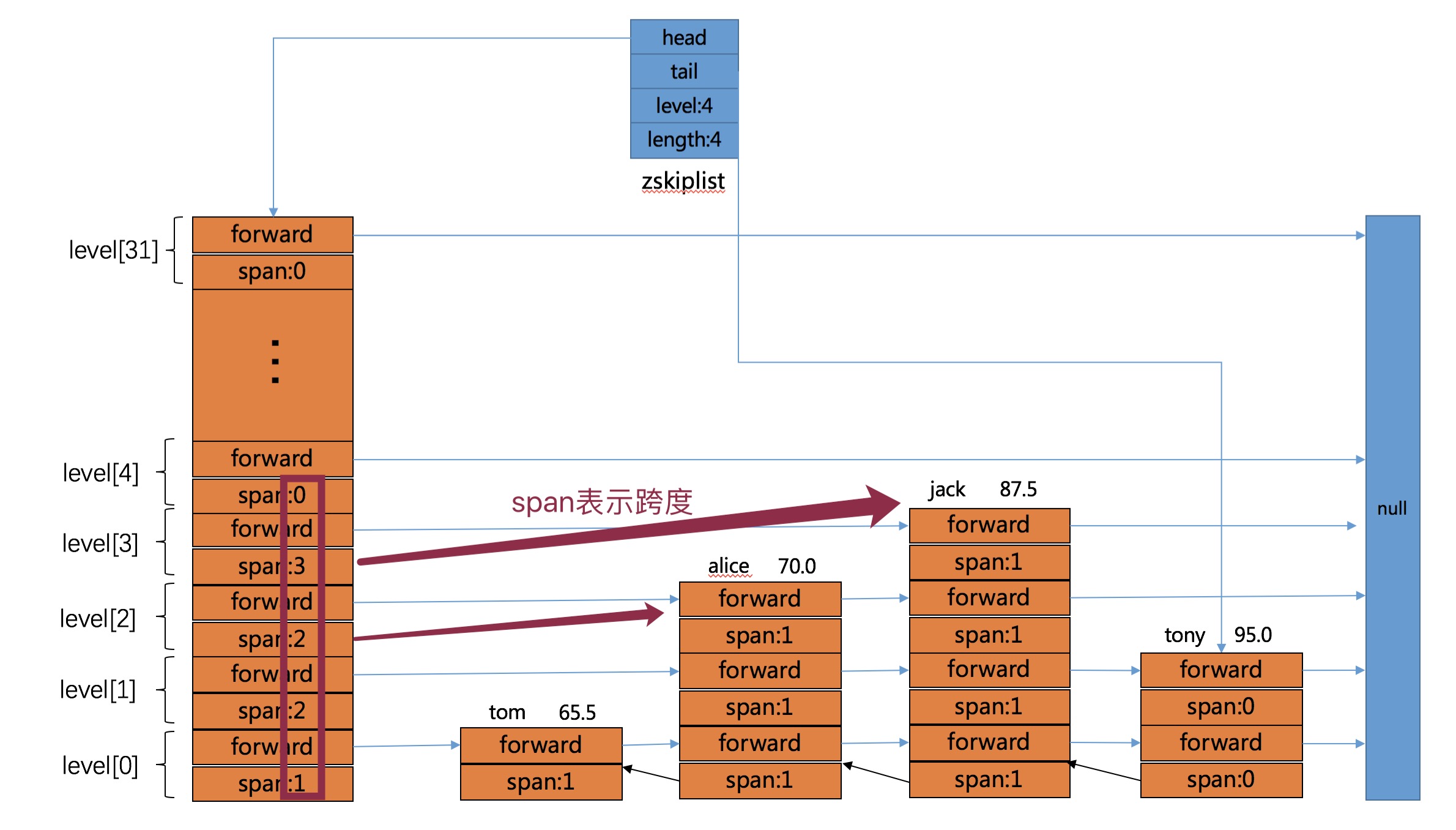
- 接着我们继续插入后面的三条数据,他们的level分别为
jack->4、alice->3、tony->2,此时的zsl如下图所示,注意span的更新:
- 好了,插入终于结束啦!接下来我们看下查找的相关操作,上面的代码中有关查找举了4个例子,分别是:
1)查找指定范围内最小的元素
2)查找指定范围内最大的元素
3)根据名称获取排名
4)根据排名获取名称
我们分析下(1)和(4),(2)、(3)同理。首先来看(1),用zrangespec结构体定义了一个范围为70.0 <= x <= 90.0,有关zrangespec结构体如下所示:
typedef struct {
double min, max; // 定义最小范围和最大范围
int minex, maxex; // 是否包含最小和最大本身,为 0 表示包含,1 表示不包含
} zrangespec;
/* 定义范围的代码如下所示 */
zrangespec spec = { //定义spec, 70.0 <= x <= 90.0
.min = 70.0,
.max = 90.0,
.minex = 0,
.maxex = 0}; //为结构体元素赋值下面调用zslFirstInRange()函数遍历得到了满足70.0 <= x <= 90.0的最小节点,代码如下:
/* Find the first node that is contained in the specified range.
* Returns NULL when no element is contained in the range. */
zskiplistNode *zslFirstInRange(zskiplist *zsl, zrangespec *range) {
zskiplistNode *x;
int i;
/* If everything is out of range, return early. */
if (!zslIsInRange(zsl,range)) return NULL; // 判断给定的范围是否合法
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) { // 从最高的Level开始
/* Go forward while *OUT* of range. */
while (x->level[i].forward && //只要没结束 && 目前结点的score小于目标score
!zslValueGteMin(x->level[i].forward->score,range))
// 将结点走到当前的节点
x = x->level[i].forward;
}
/* This is an inner range, so the next node cannot be NULL. */
x = x->level[0].forward; // 找到了符合的点
serverAssert(x != NULL);
/* Check if score <= max. */
if (!zslValueLteMax(x->score,range)) return NULL; // 判断返回的值是否小于max值
return x;
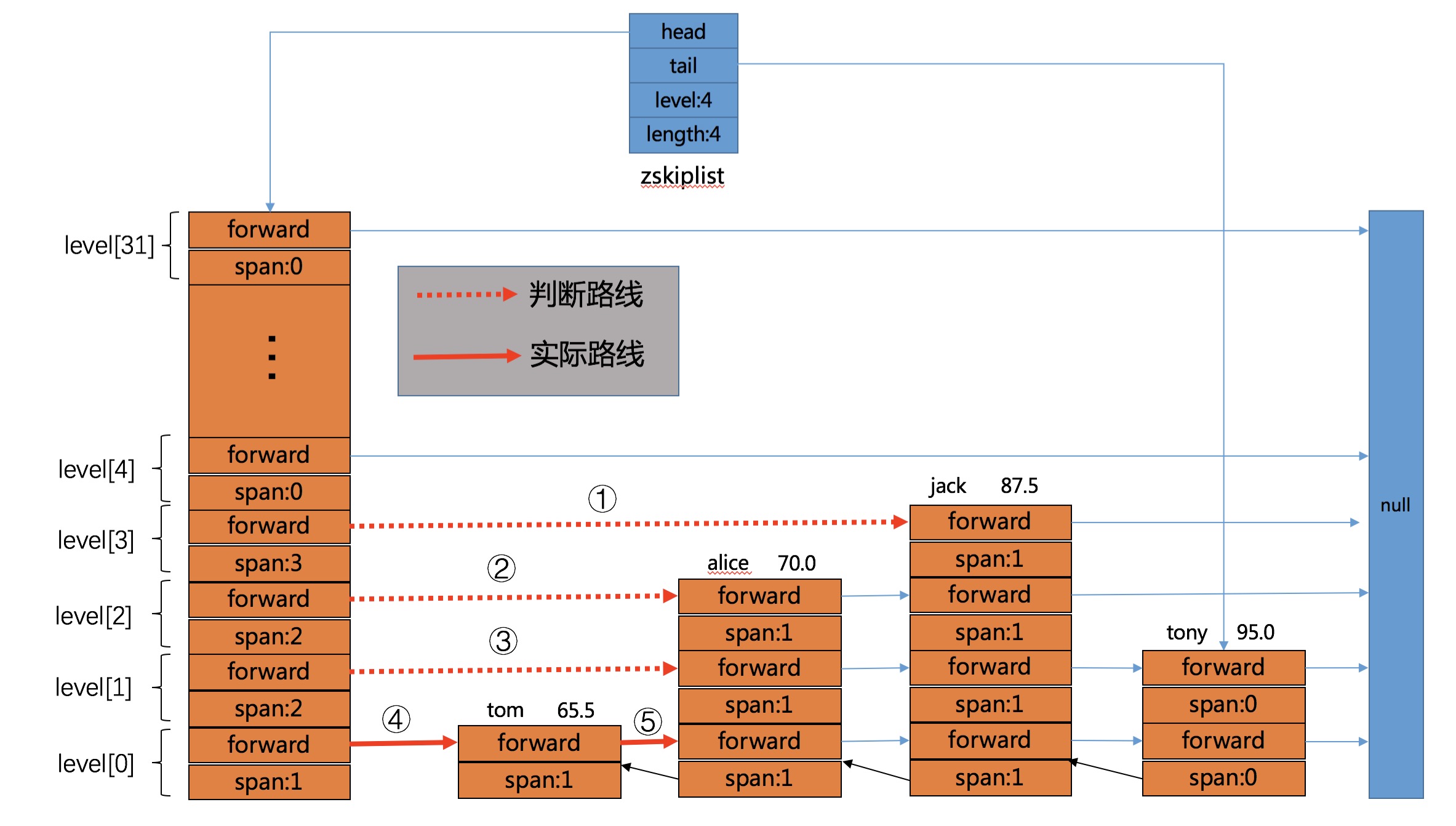
}可以看到,遍历的核心思想是:
(1) 高Level -> 低Level
(2) 小score -> 大score
即在从高Level遍历比较过程中,如果此时的score小于了某个高level的值,就在这个节点前一个节点降低一层Level继续往前遍历,我们找70.0的路线如下图所示(图中红线):
- 继续看下根据排名获取元素的函数
zslGetElementByRank(),主要是根据span域来完成,代码如下所示:
zskiplistNode* zslGetElementByRank(zskiplist *zsl, unsigned long rank) {
zskiplistNode *x;
unsigned long traversed = 0;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward && (traversed + x->level[i].span) <= rank)
{
traversed += x->level[i].span;
x = x->level[i].forward;
}
if (traversed == rank) {
return x;
}
}
return NULL;
}遍历的思想和之前没有什么差别,本次遍历路线如下图所示:
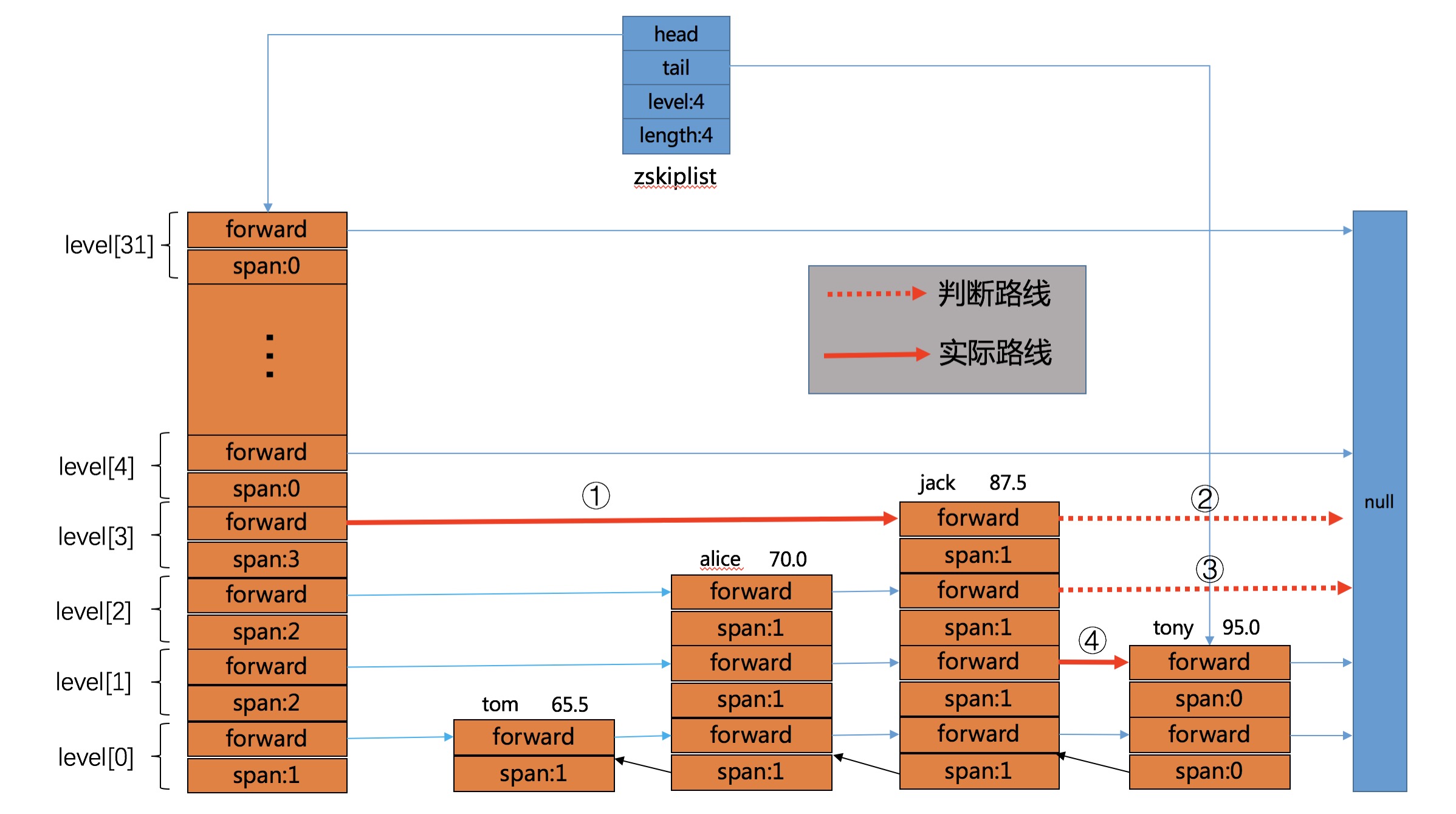
- 接着我们看下
Delete()函数,ret = zslDelete(zsl, 70.0, sdsnew("alice"), &node);表示删除zsl中score为70.0,数据为alice的元素,这也是Redis SkipList的第二个特征,比较一个元素不仅比较score,而且比较数据,下面看下zslDelete的代码:
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x;
}
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
zslDeleteNode(zsl, x, update);
if (!node)
zslFreeNode(x);
else
*node = x;
return 1;
}
return 0; /* not found */
}- 需要注意的是
zslDelete()第四个参数,是一个zskipListNode **类型,它如果不为NULL,那么代码在遍历找到node之后不会将其直接释放,而是将地址交给它,后续这块空间的释放就必须由我们手动处理。 - 遍历比较的思想和之前还是一样, 在update[]中记录下各层删除节点之前的节点。
- while循环比较条件,
sdscmp(x->level[i].forward->ele,ele) < 0是因为插入函数zslInsert()也是按照这个逻辑插入的。 - 最后需要再次比较
if (x && score == x->score && sdscmp(x->ele,ele) == 0)是因为Redis SkipList允许相同score的元素存在。
最后看看释放函数zslFree(zsl),思想很简单,因为level[0]一定是连续的(并且是一个双向链表),所以从level[0]依次遍历释放就行了。
/* Free a whole skiplist. */
void zslFree(zskiplist *zsl) {
zskiplistNode *node = zsl->header->level[0].forward, *next;
zfree(zsl->header);
while(node) {
next = node->level[0].forward;
zslFreeNode(node);
node = next;
}
zfree(zsl);
}通过上面的例子,我们分析了zskiplist的创建、插入、查找、删除、释放等操作,结合数据结构的定义,基本上分析清楚了zskiplist。其实zskiplist在Redis中的主要用处是和dict一起实现Sorted Set,这个我们后续看Sorted Set的时候再分析。
四、性能分析
| 操作 | 一般性能 | 最坏性能 |
|---|---|---|
| 插入 | O(log n) | O(n) |
| 删除 | O(log n) | O(n) |
| 搜索 | O(log n) | O(n) |
如果想了解更多关于跳表本身,比如RandomLevel()的随机性等,一定不要错过 维基百科 上的内容。
[完]
















 325
325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











