







根据二叉树创建字符串

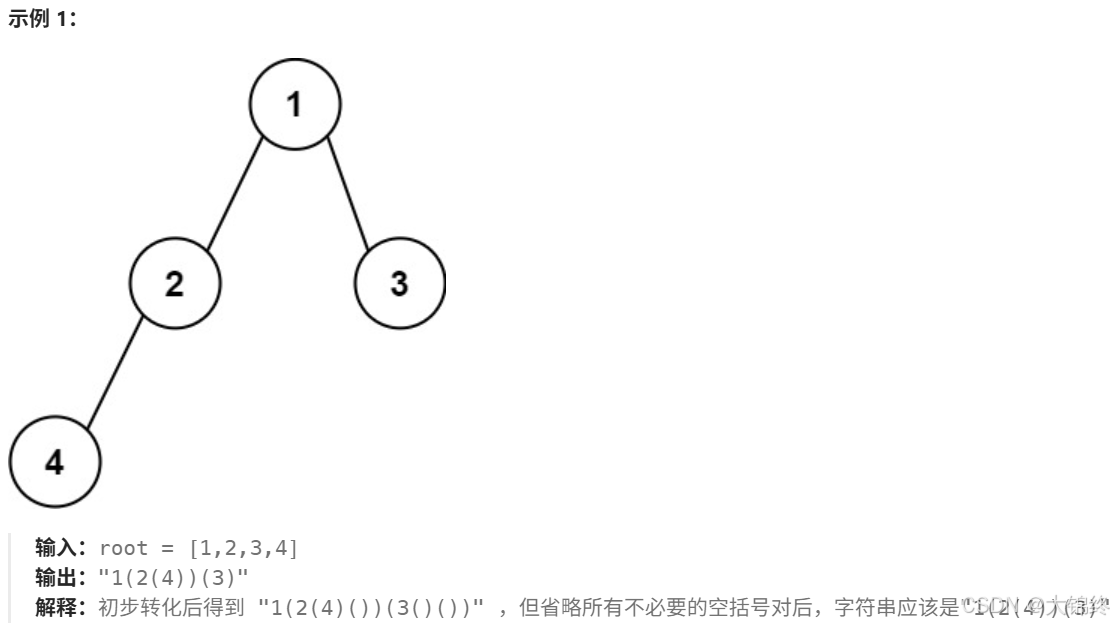
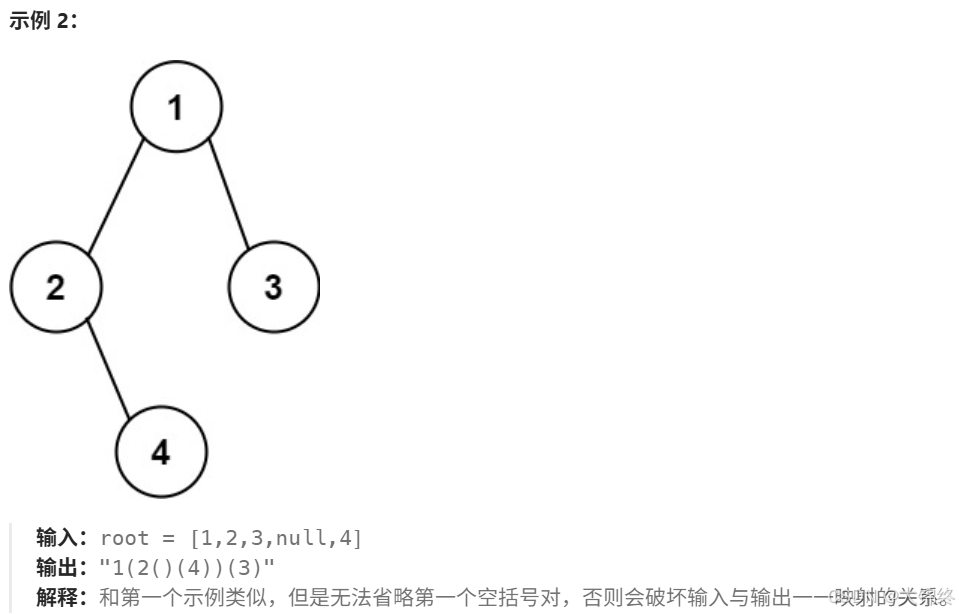
重点是要注意括号省略问题,分为以下情况:
1.左字树为空,右子树不为空,左边括号保留
2.左右子树都为空,括号都不保留
3。左子树不为空,右子树为空,右边括号不保留
如果根节点为空,返回空字符串。创建一个字符串将根节点的值转换为字符串并存储在 str 中,将整数值转化为字符串目的可以直接进行追加操作。
代码逻辑:
1.本质上是一个前序遍历,在遍历前加‘(‘遍历后加’)’
2.左子树加括号的条件用if(root->left||root->right)就完美描述,左子树为空判断第二个条件,右子树也不为空就+(),若第一条件左子树不为空直接成立也+()。调用左子树递归来追加key值到字符串中
2.只要右子树不为空就加(),调用右子树递归来追加key值到字符串中
二叉树的最近公共祖先

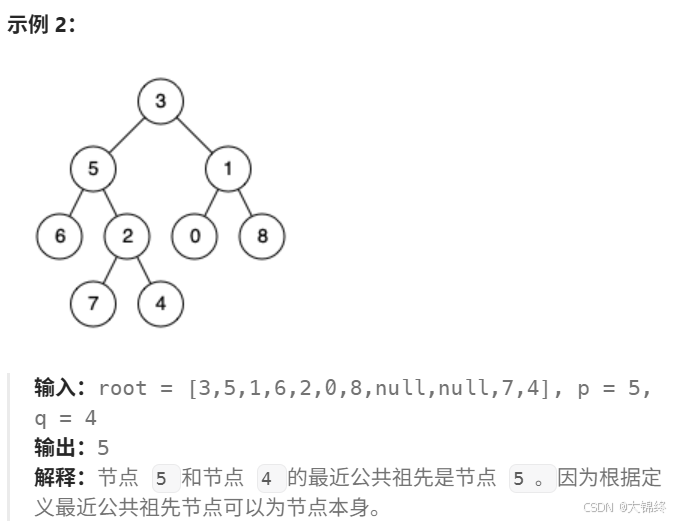
若直接是一棵搜索二叉树,能确定pq大小,在左子树还是右子树。
一般情况下普通树情况居多,思路:
1.一个在左边,一个在右边,当前根就是公共祖先
2.p或q就是根,另外一个在其子树中,当前根就是公共祖先
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
bool find(TreeNode* root,TreeNode* x)
{
if(root==nullptr)
{
return false;
}
return root==x||
find(root->left,x)||
find(root->right,x);
}
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(root==nullptr)
return nullptr;
//处理根节点就是pq情况
if(root==p||root==q)
{
return root;
}
bool pinleft,pinright,qinleft,qinright;
pinleft=find(root->left,p);
pinright=!pinleft;
qinleft=find(root->left,q);
qinright=!qinleft;
//处理pq都在左边情况
if(pinleft&&qinleft)
{
return lowestCommonAncestor(root->left, p, q);
}
//处理都在右边情况
else if(pinright&&qinright)
{
return lowestCommonAncestor(root->right, p, q);
}
//处理一左一右情况
else
{
return root;
}
}
};
代码逻辑:
1.创建一个find函数去查找pq值所在节点,当前根不是就按前序递归查找
2.创建pinleft等状态值,通过调用find函数来确定pq的存在情况
3.处理pq都在左子树和右子树情况,分别调用递归,成功返回root节点
4.最后pq一左一右情况直接返回根节点
精髓在于,通过递归从整个二叉树逐步缩小树的范围,pq最终会呈现出一左一右的情况。时间复杂度分析:
find 函数最坏情况下,可能需要访问子树中的所有节点,需要遍历 O(n) 个节点。lowestCommonAncestor 函数 最坏情况下,如树是完全不平衡的(退化为链式结构),此时递归调用的次数为 O(n),所以总的时间复杂度为 O(n²)。
倒着走,转化为链表相交类似问题
bool FindPath(TreeNode* root, TreeNode* x, stack<TreeNode*>&path)
{
if(root==nullptr)
return false;
//先入栈再去判断
path.push(root);
if(root==x)
return true;
//左右递归分别寻找
if(FindPath(root->left,x,path))
return true;
if(FindPath(root->right,x,path))
return true;
//找不到pop掉该路节点,换路寻找
path.pop();
return false;
}
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
stack<TreeNode*>ppath,qpath;
FindPath(root,p,ppath);
FindPath(root,q,qpath);
//长的先走差距步,两种情况
while(ppath.size()>qpath.size())
{
ppath.pop();
}
while(qpath.size()>ppath.size())
{
qpath.pop();
}
//一起走,寻找相交节点
while(ppath.top()!=qpath.top())
{
ppath.pop();
qpath.pop();
}
return ppath.top();
}
};
FindPath查找路径函数,利用栈后进先出的特性来实现。
1.空节点返回失败,不为空先入栈,在判断是否为目标值
2.当前节点为目标值返回成功,否则通过if条件套用去递归按照前序遍历寻找
3.若没找到,要pop节点,告诉父节点该方向没有,换一个方向
lowestCommonAncestor 函数
1.pq分别创建一个栈,通过路径查找函数招到各自路径
2.相交链表处理思路,长的先走差距步,再一起走,第一次相遇点即为相交点。
3.长的先走,只要长度长于短的通过循环pop掉,最后一起走只要不相等就pop掉,最后随便返回一个栈顶元素,有可能为空。
二叉树搜索树转换成排序双向链表
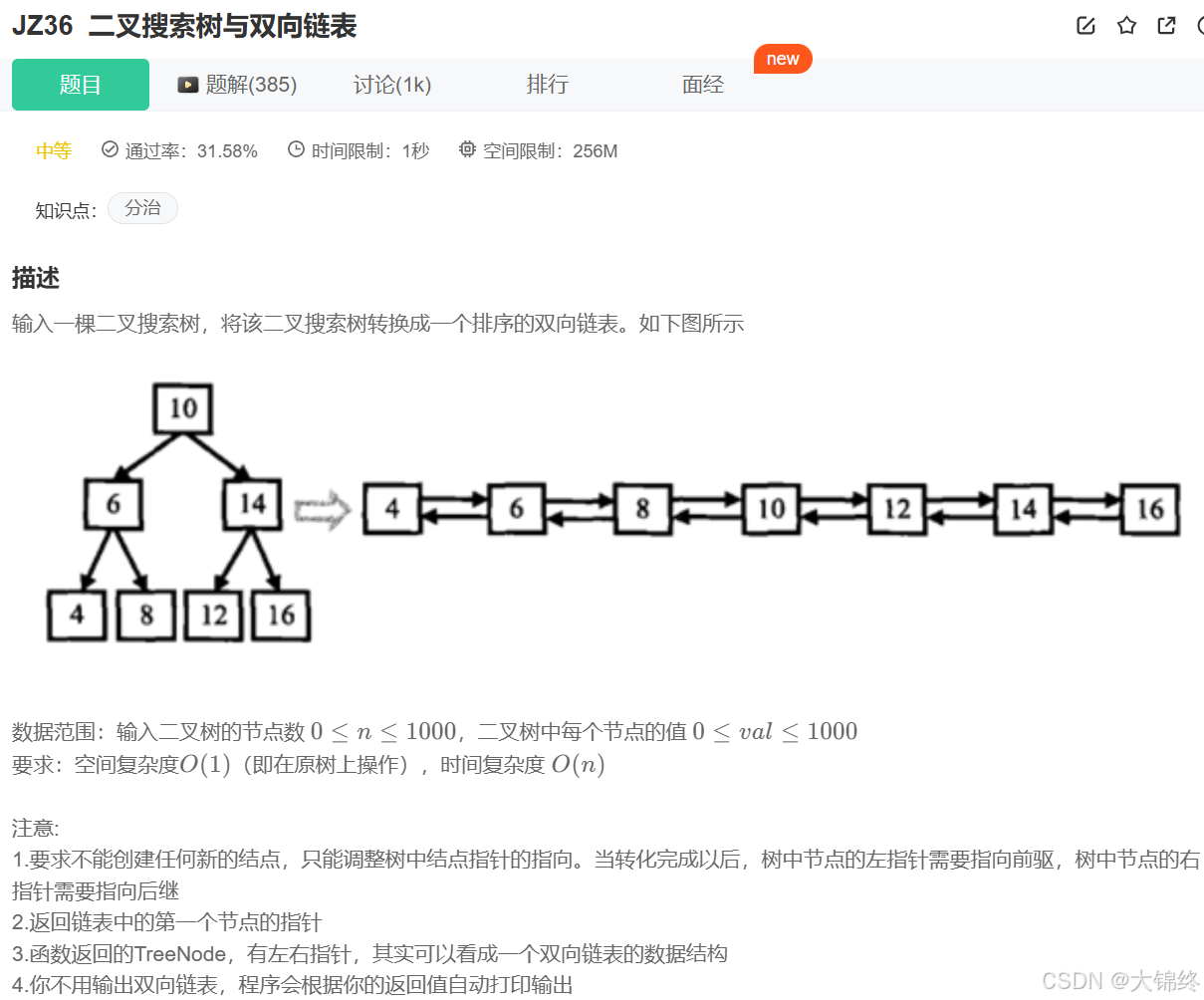
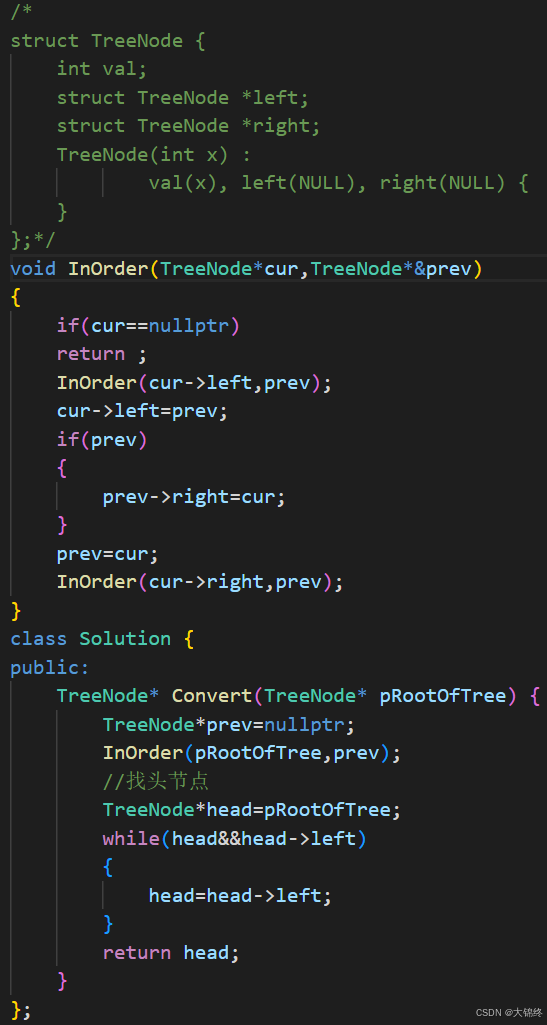
思路:
因要转化成一个排序的双向链表,所以要用到中序遍历,至于如何转化成双向链表,需将中序遍历部分添加前后指针
1.前指针开始置空,链接完后更新为当前节点,当前节点往下递归,再链接,如此下去直到结束
2.后指针如何链接?我们无法预知未来,若是穿越者就可,所以当遍历到下一个节点时,将上一个节点(需判断不为空时)的后指针指向当前节点,就完成了后指针链接的难题,中序遍历最后节点的后指针一定为空。
注意:
InOrder函数传参时prev要传指针的引用,因为再递归过程中会不断开辟新的栈帧,不传引用没办法控制每个栈帧中prev相同,链接就会出问题
根据一棵树的前序遍历与中序遍历构造二叉树
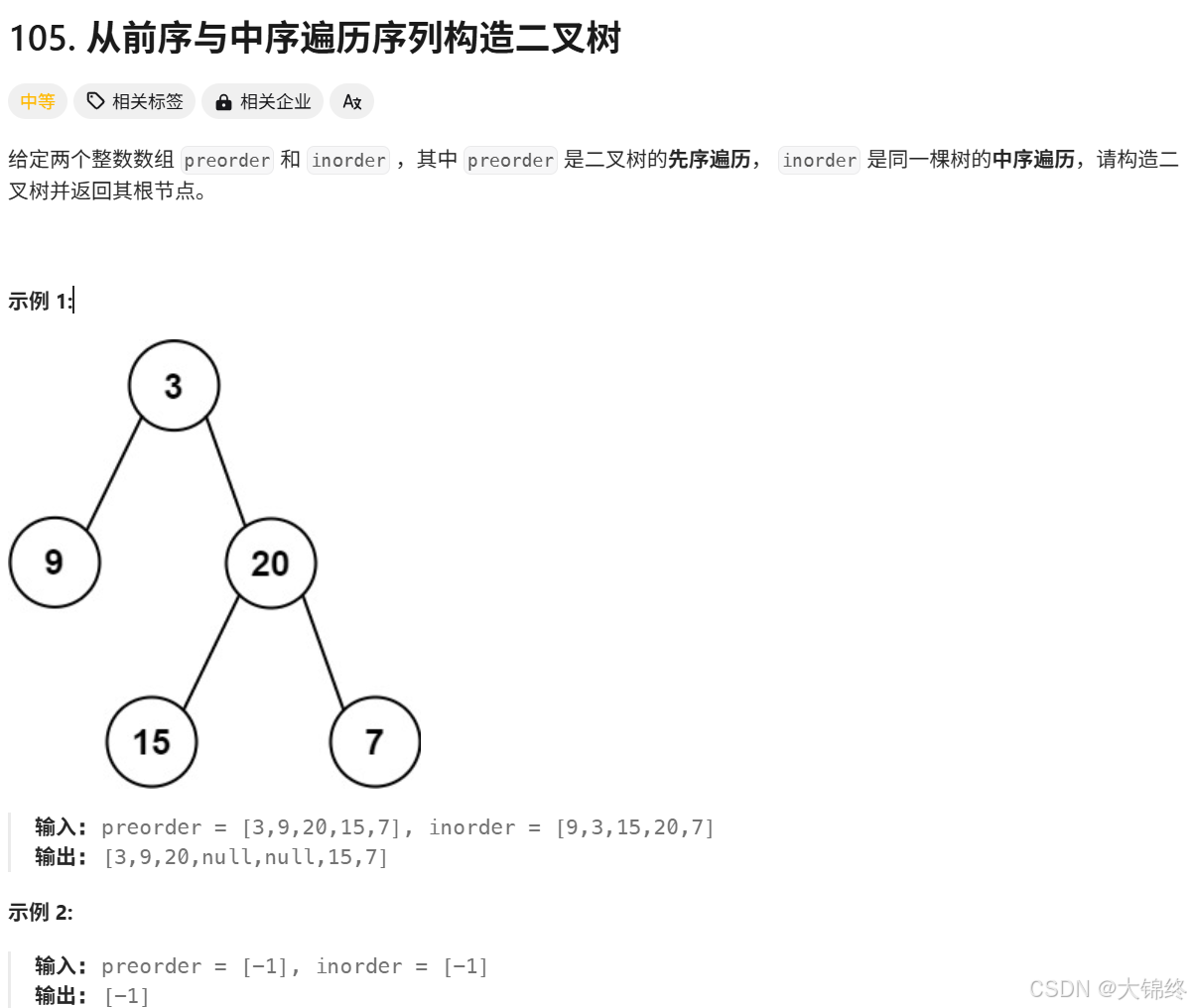
思路:
前序确定根节点位置,中序用来划分区间
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
TreeNode* build(vector<int>& preorder, vector<int>& inorder,int& prei,
int inbegin,int inend)
{
if(inbegin>inend)
return nullptr;
//创建节点
TreeNode*root=new TreeNode(preorder[prei]);
//在中序容器中找到根节点来划分区间
//int rooti=prei;prei每次递归都会增加,所以在递归过程中可能让rooti错失根节点
//位置,导致划分区间出现问题,会导致数组越界问题
int rooti=inbegin;
while(rooti<inend)
{
if(preorder[prei]==inorder[rooti])
break;
rooti++;
}
//划分好区间[inbegin,rooti-1]rooti[rooti+1,inend]
//按前序遍历依次递归,链接节点
prei++;
root->left=build(preorder,inorder,prei,inbegin,rooti-1);
root->right=build(preorder,inorder,prei,rooti+1,inend);
return root;
}
class Solution {
public:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
int i=0;
TreeNode*root=build(preorder,inorder,i,0,inorder.size()-1);
return root;
}
};
1.结束条件:创建节点函数中当初下标大于尾下标时无法构建出区间,返回空节点
2.用前序vector和其下标prei来创建节点,第一次为根节点,后面prei不断更新依次创建出前序遍历中每个节点
3.通过循环比较来找出中序vector中根节点位置,从而划分区间
4.通过递归调用按照前序遍历依次链接每个节点,返回根节点。每进行一次递归,prei都要++,直到遍历完前序vector,为确保每次递归新创建的栈帧中prei相同,参数要传引用。
二叉树的前序遍历,非递归迭代实现
思路:
前序遍历,最先访问到的节点是左路节点,再访问左路节点的右子树。我们可以利用栈后进先出的特性来实现
1.创建一个vector来实现最终输出,一个stack来实现遍历操作,一个cur代替根节点进行遍历
2.循环条件,当前节点cur和栈其中一个不为空。cur是访问一棵树的开始,先访问左路节点,依次如栈,节点值也依次如vector
3.依次访问左路节点的右子树,创建top取栈顶元素,再pop掉,因为已经访问过了,栈中剩余元素是未访问的。利用子问题的方式访问右子树,将cur更新为右子树,进行循环遍历。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int> v;
stack<TreeNode*>st;
TreeNode*cur=root;
while(cur||!st.empty())
{
//访问的开始,先访问左子树
while(cur)
{
v.push_back(cur->val);
st.push(cur);
cur=cur->left;
}
//访问左子树的右子树
TreeNode*top=st.top();
st.pop();
//访问右子树转化为子问题
cur=top->right;
}
return v;
}
};
总结:
通过栈后进先出特性能确保从下往上依次访问左子树的右树,满足前序性质。本质还是递归的思想,不过用循环来实现。依次访问左节点的右子树,还是会将其转化为先访问左子树,再访问左子树的右子树的子问题
二叉树中序遍历,非递归迭代实现
与前序遍历的非递归思路相同,只是左路节点的访问时机不同
思路:
1.左路节点入栈 2.访问左路节点及左路节点右子树
本质:在遍历左节点过程中先不入vector,从栈中取到一个节点,意味着这个节点的左子树已经访问完了,再把当前节点入vector因为先遍历左节点,最后肯定遇到空结束,代表最后节点左子树为空,已经访问完了,再取栈顶元素,然后pop掉,意味着当前节点的左子树已访问完,当前节点作为根节点入vector,再将当前节点更新为其右子树,满足了中序遍历性质。再取栈顶元素,旧栈顶元素(上一次pop掉的)作为当前栈顶元素的左子树已被访问过并且已经入vector,如此循环往复直到遍历完成。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> v;
stack<TreeNode*>st;
TreeNode*cur=root;
while(cur||!st.empty())
{
//访问的开始,先访问左子树
while(cur)
{
st.push(cur);
cur=cur->left;
}
//访问左子树的右子树
TreeNode*top=st.top();
st.pop();
v.push_back(top->val);
//访问右子树转化为子问题
cur=top->right;
}
return v;
}
};
可看出与前序遍历的非递归实现,仅仅是v.push_back(top->val);的执行顺序不同,中序遍历放在了取栈顶元素之后,而前序遍历放在了遍历左节点时直接访问
二叉树的后序遍历 ,非递归迭代实现
按照 左子树 右子树 根的顺序访问,如何在访问根节点前访问右子树呢?
采取比较的方式,容易理解和操作:
1.和中序遍历一样,先遍历左节点入栈,等取栈顶元素后再访问
2.如果当前节点的右子树没访问过,上一个访问的节点是左子树的根
3.如果当前节点的右子树已访问过,上一个访问的节点是右子树的根
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
vector<int> v;
stack<TreeNode*>st;
TreeNode*prev=nullptr;
TreeNode*cur=root;
while(cur||!st.empty())
{
//访问的开始,先遍历左子树
while(cur)
{
st.push(cur);
cur=cur->left;
}
TreeNode*top=st.top();
//如果右子树为或上一个访问的节点为右子树,代表
//右子树已访问完
if(top->right==nullptr||top->right==prev)
{
prev=top;
v.push_back(top->val);
st.pop();
}
else
{
cur=top->right;
}
}
return v;
}
};
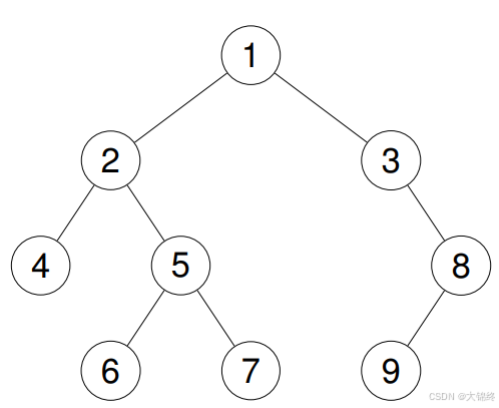
需要创建一个prev来保存上一个访问过的节点,通过一个图来分析感受一下
1.先遍历左节点,124依次入栈
2.取栈顶元素4,其左子树为空相当于访问过了,其右子树为空也相当于访问过了,直接将4入vector,将prev更新为当前top,然后pop
3.继续取栈顶元素2,其左子树4已访问过,其右树不为空,更新当前结点为其右树,返回循环,划分为子问题,56依次入栈,取栈顶元素6,其左子树和右子树为空相当于访问过,直接将6入vector,然后pop。继续取栈顶元素5,其左子树6已访问过,右子树不为空,更新当前节点为其右子树,如此循环。剩下部分分析省略,思路相同
4.按照如此方式就可以完成后序遍历

















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









