







4月中下旬,无问芯穹Infini-AI大模型服务平台面向企业认证用户开放了LLaMA3试用申请。今天,无问芯穹宣布LLaMA3-8B中文增强模型——LLaMA3-8B-Infini-instruct,已可以登陆Infini-AI(https://www.infini-ai.com/),获取申请试用链接。
01
15T 超大数据集规模
中文数据不足5%
此前,DeepMind研究团队于《Training Compute-Optimal Large Language Models》等在先研究中,认为8B模型的最佳训练数据规模可能在0.2T(2千亿)Tokens左右。LLaMA3之前,业界实践的最高训练数据记录,则在3T(3万亿)Tokens左右。根据技术报告,本次Meta LLaMA3的训练在超两万张H100卡组成的计算集群上运行,并在8B模型上消耗了共计130万GPU小时数,数据集规模高达15T(15万亿)Tokens,是目前主流模型训练数据的5倍多。
但这15T 数据中,只有不超过5%的非英语数据。换言之,30多种非英语数据加起来不超过0.75T(7千5百亿)。可想而知,其中中文数据会更少。Meta在技术报告原文中也表示:“并不指望模型在非英语情景下的表现能达到英语水平。”
02
推理能力强大
少量数据即可快速实现中文增强
LLaMA3在各测试和任务中展现的高性能水平,已引起开源社区的极大关注,被广泛认定为开源大模型里程碑中的重要节点,将会在各种应用场景中发挥作用。对LLaMA3展开中文增强,是中文社区必不可少的工作。
无问芯穹算法团队发现,LLaMA3通过增加大量代码数据增强了模型推理能力。或许能借助LLaMA3强大的逻辑基础水平,仅通过增加少量的中文数据,即快速实现中文能力的增强。
方案选择
我们首先尝试了直接对Meta-Llama-3-8B-Instruct进行中文监督微调(SFT)的方案,但训练后发现中文模型表现与英文原始模型存在较大的差距。推测是由于LLaMA3的中文词表只有4k左右大小,许多中文词汇可能会退化为Unicode编码,仅靠SFT数据不足以激活小词表对中文的表达能力。因此选择了先基于Base模型进行继续预训练,再使用对话数据进行有监督微调的技术路线。
数据准备
使用了10B(1百亿)Tokens中文数据对LLaMA3-8B-Base模型展开了继续训练,不到12小时便完成了继续训练与微调。
数据组成
我们混合了高质量中文数据(百科、书籍等)、互联网通用语料、代码、数学、逻辑推理等多种数据,并在基座模型的继续训练中混入了大量对话及指令数据来激发模型的指令跟随能力。
监督微调
在10B Tokens的继续预训练完成后,使用了高质量对话数据进行SFT,最终获得完整的对话模型。
增强结果
通用领域增强效果
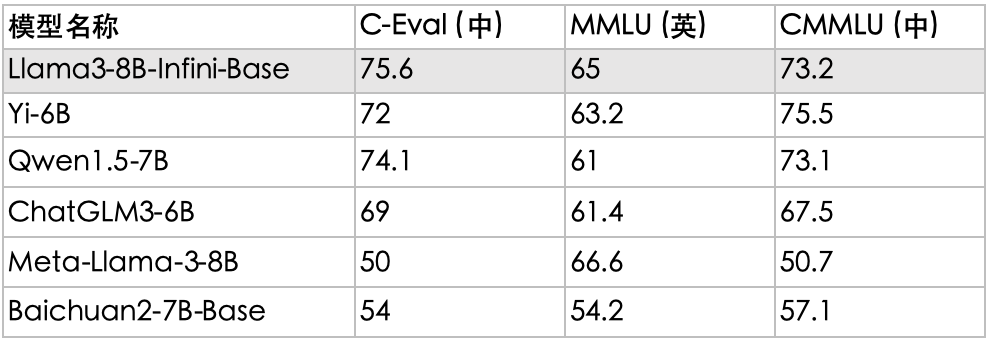
注:C-Eval/MMLU/CMMLU为5-shot点数,LLaMA3中文点数使用OpenCompass测试,表格排序依据为三个基准平均分。
对话能力增强效果
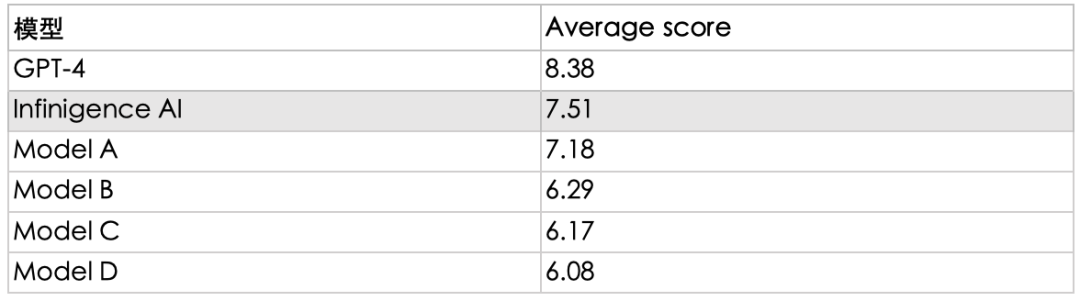
注:使用了MT-Bench来测试模型的对话能力,测试集内容由英翻中。模型A-D均采用匿名化处理,选取了目前市面头部模型品牌的同规模参数大模型,对话能力多维度测评结果见下方雷达图。

从结果看,经无问芯穹团队增强过后的LLaMA3 8B模型精度在同规模模型中位列第一梯队。同时我们也测量了直接SFT的性能(对话能力得分6.53),和先进行继续预训练的效果差距明显,印证了此前方案选择的正确性。
对话效果
我们在无问芯穹Infini-AI大模型服务平台上线了LLaMA3-8B-Infini-instruct,打开Infini-AI,可以申请在“M*N体验”模型中,通过简单对话体验LLaMA3 8B经无问芯穹中文增强前后的效果对比。
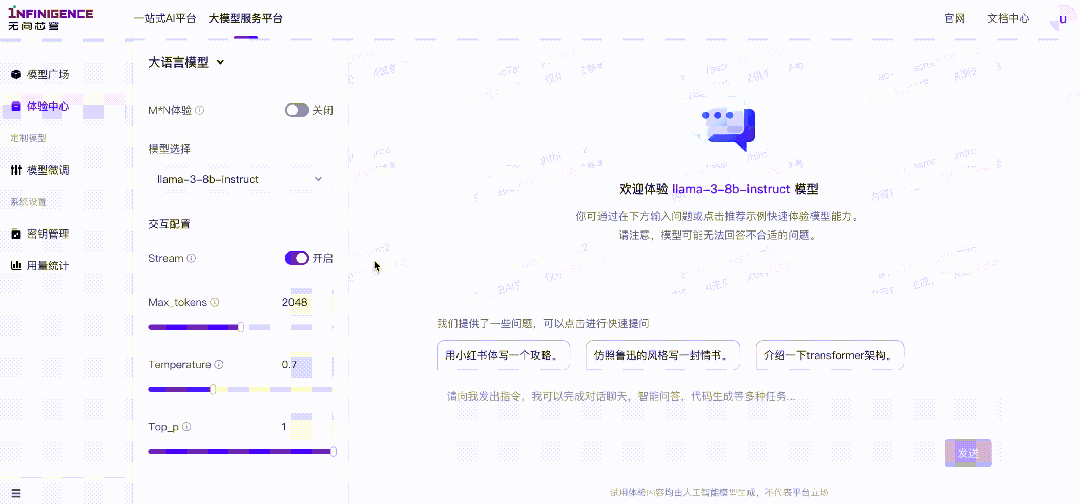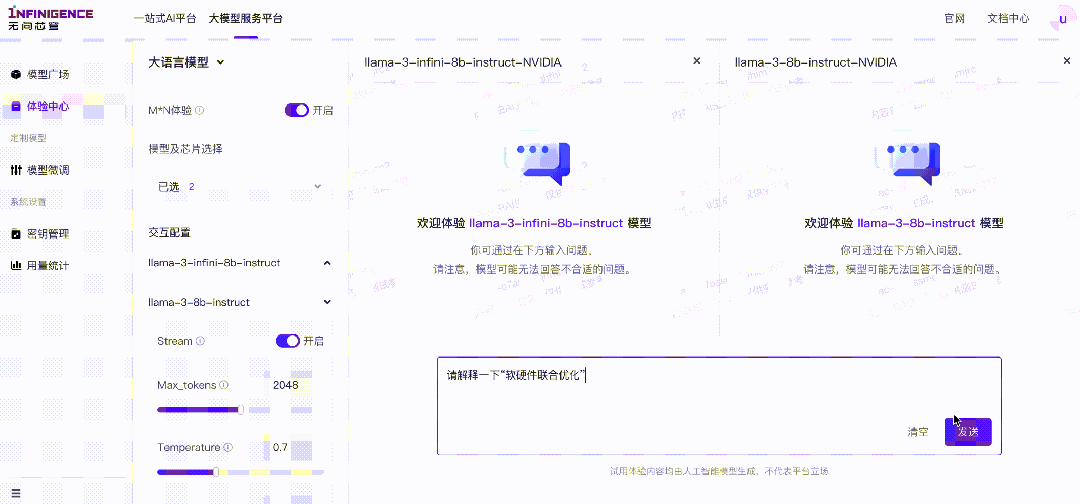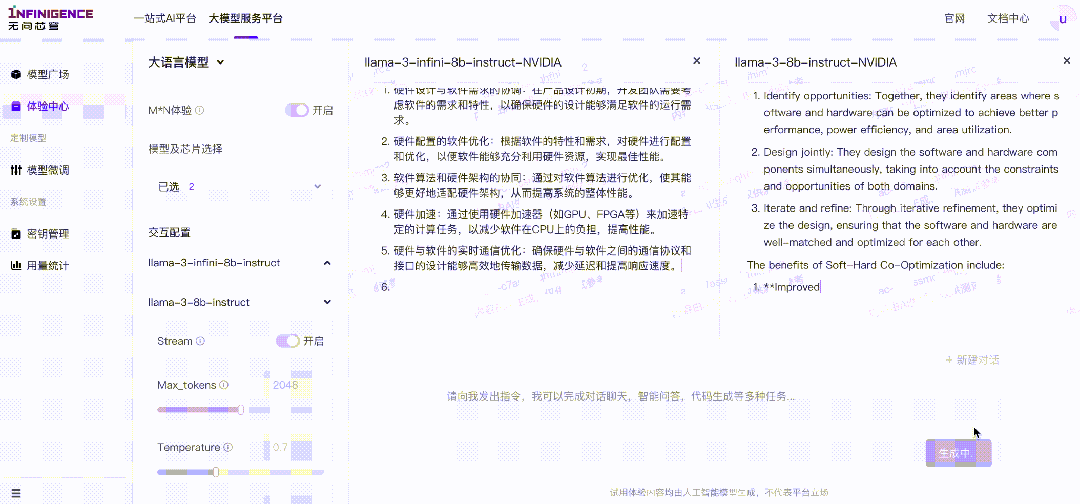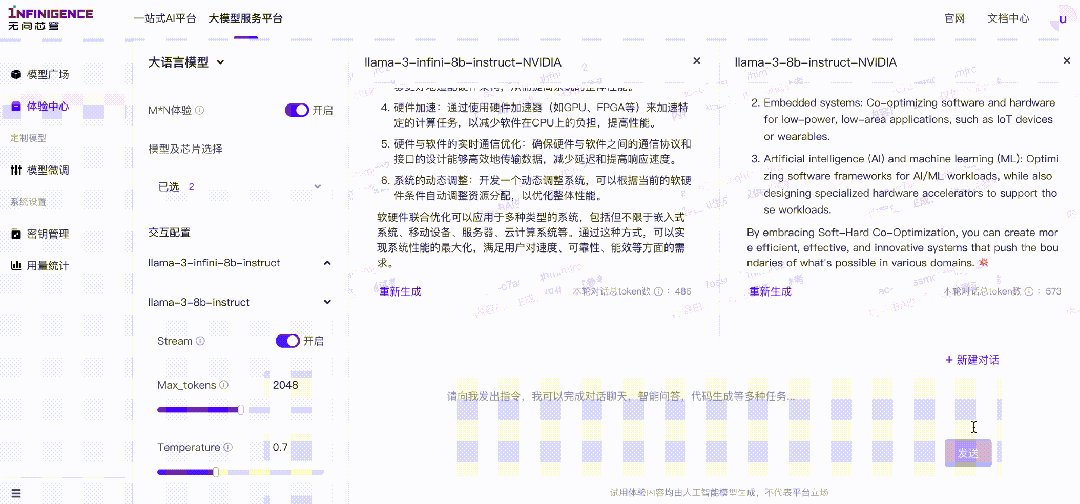
无问芯穹Infini-AI“M*N体验”
LLaMA3中文增强前后对比,试用未增强模型时,即便使用中文提问,模型仍会反馈英文回答
03
10B数据提升有限
仍有极大增强空间
本次工作虽然验证了LLaMA3抢眼的逻辑能力,但对于古典中文文本生成等任务,仍需依赖更多增强训练,如配合RAG等方法实现中文数据的进一步高效处理,可继续弥补LLaMA3 在中文知识储备方面的欠缺。
案例一:导盲犬禁止入内,是给盲人看的,还是给导盲犬看的?
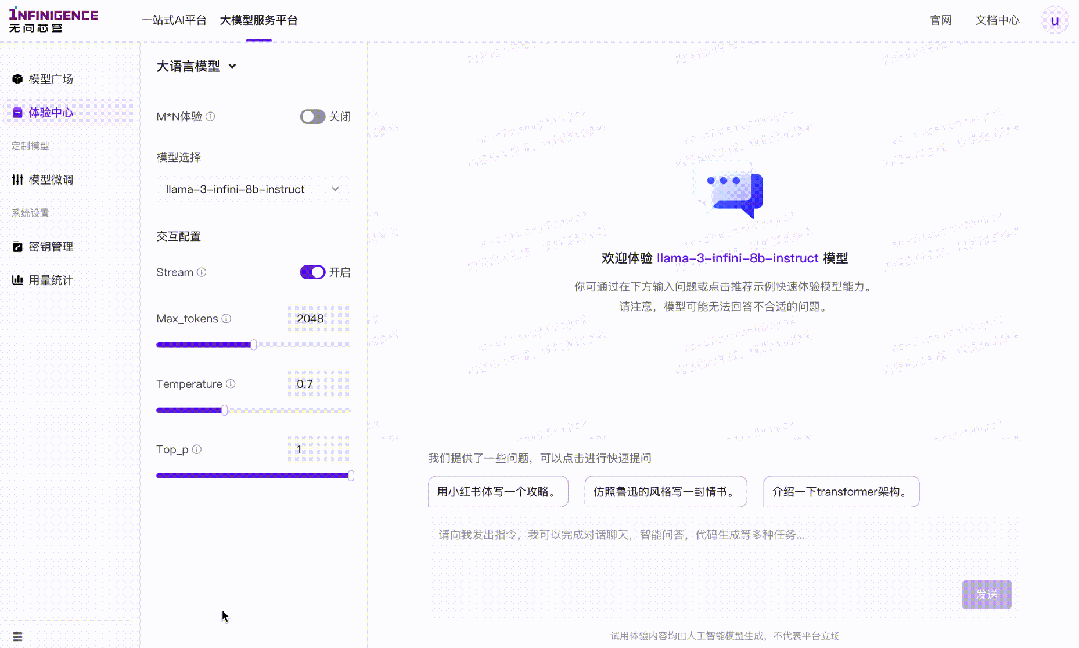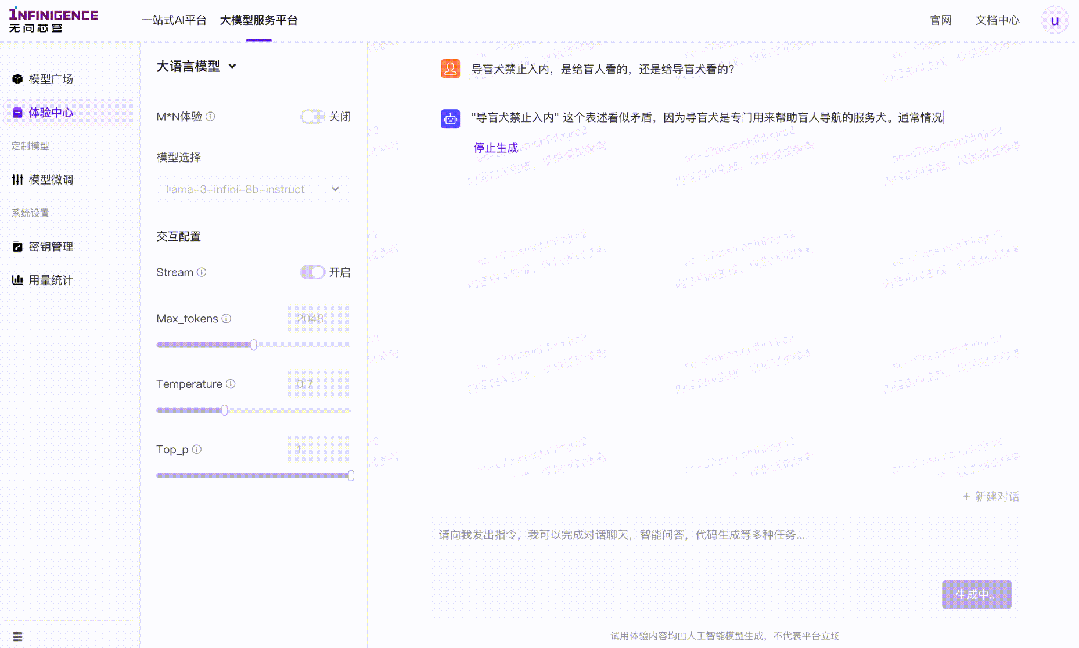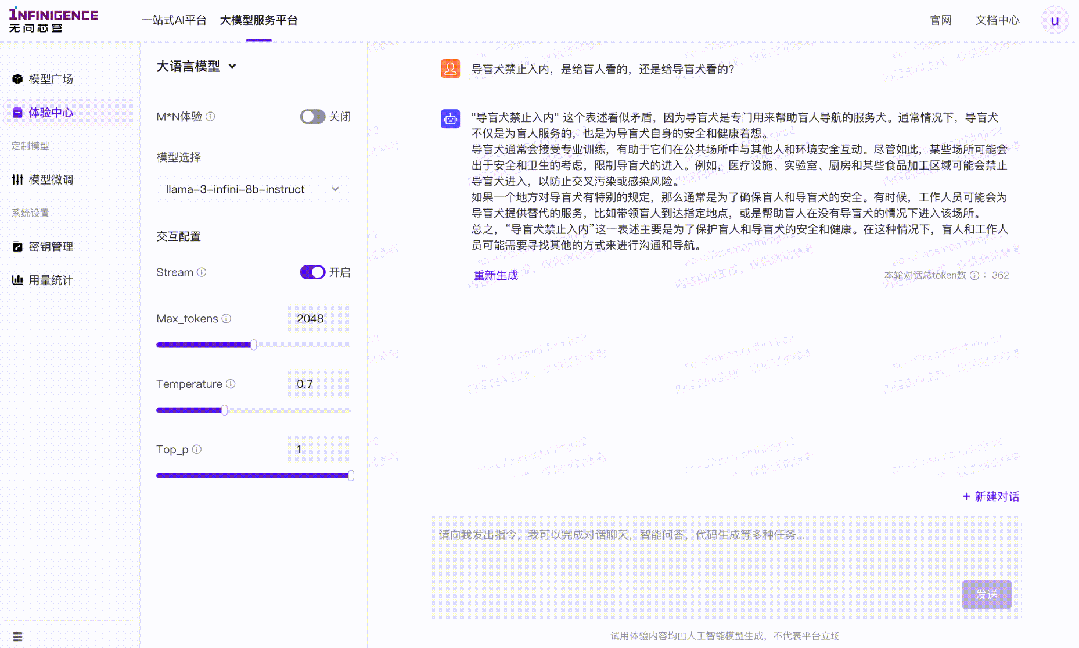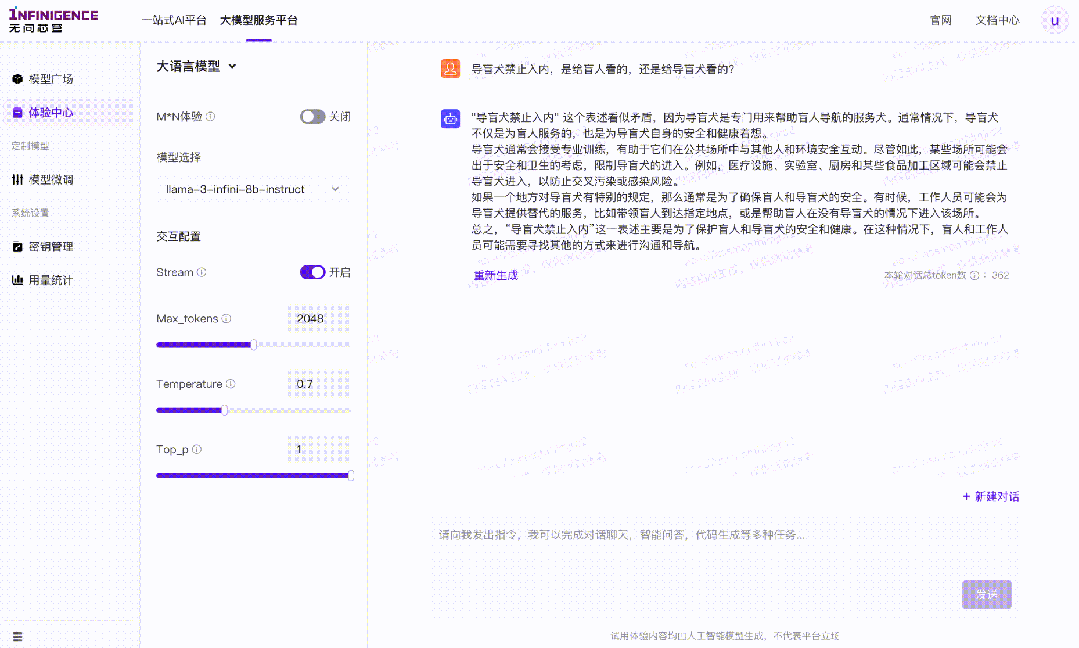
针对这一问题,模型给出的答案虽然做到了事实正确,但是并无法识别问题中的陷阱,对问题本身作出否定。比如本案例中,无法作出“既不是给盲人看,也不是给导盲犬看”的回答。
案例二:请解释“陟彼崔嵬,我马虺隤”。
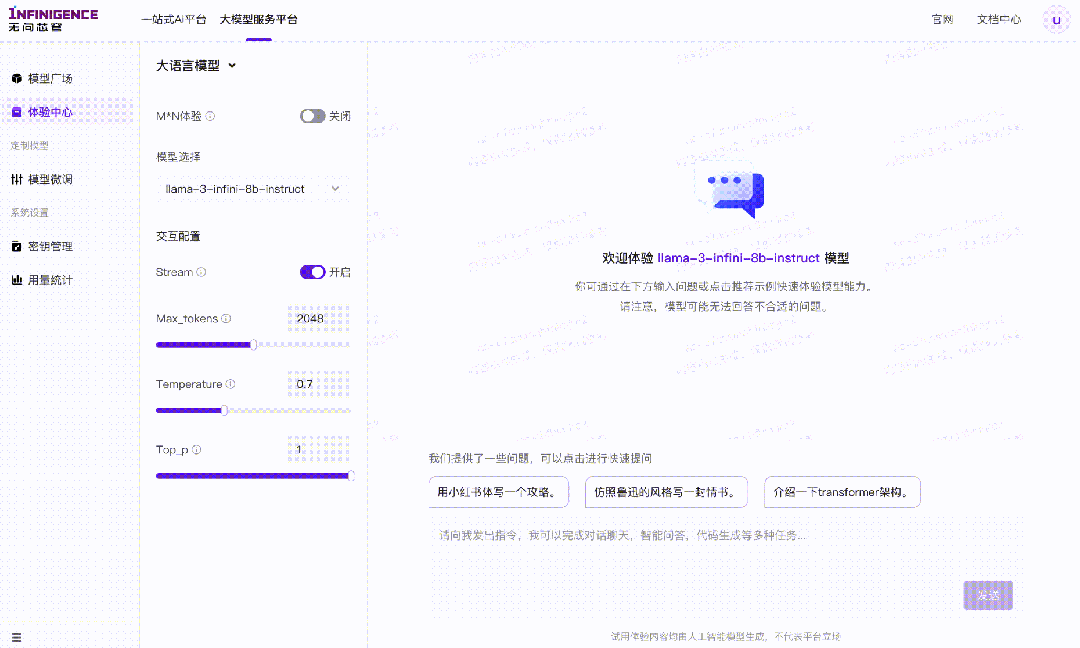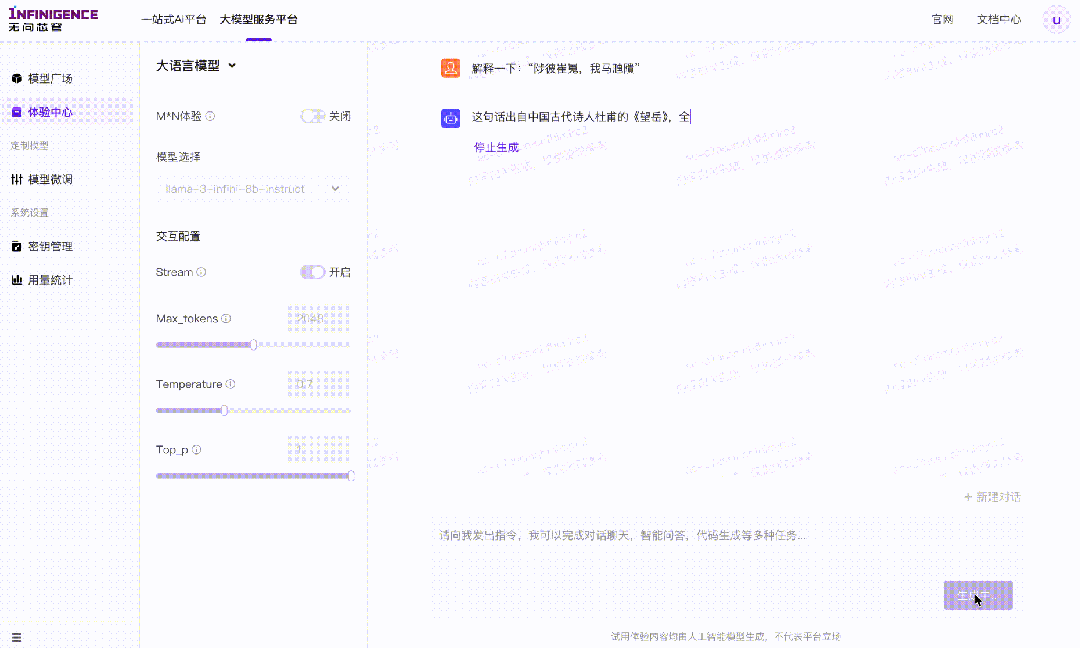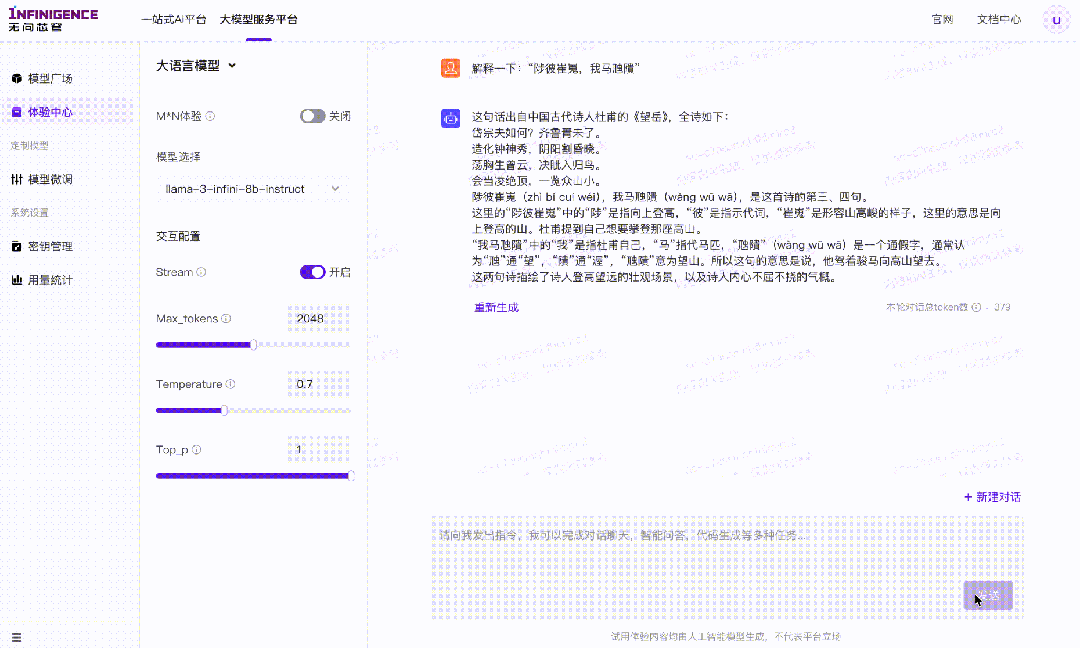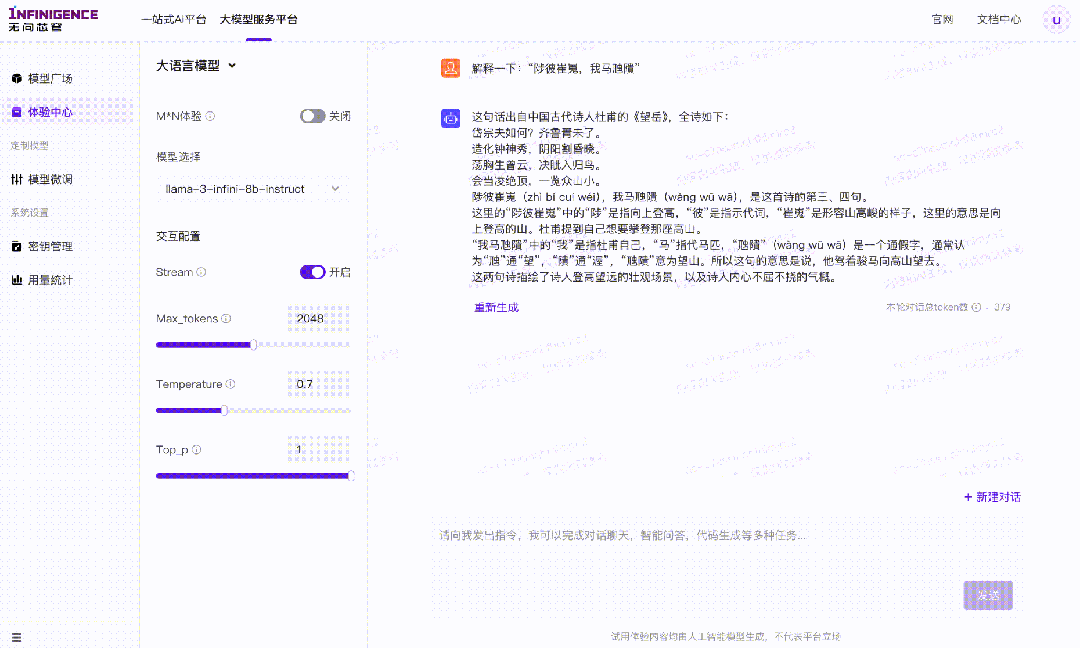
对于晦涩的古典诗词,虽然能够做到直译,逐字解读,将每个字的意思串联起来。但是对于每个字带有的情感色彩,乃至整个句子表达的情绪理解却仍然存在一定偏差。比如本案例中,未能解读出原诗句想要表达的“马儿爬山的疲惫感,以及作者对心上人的思念和离别的伤感之情”,这即是由于缺少足够多的专业中文语料导致的。
04
One more thing
仅仅10B tokens的增强训练便展现出LLaMA3-8B模型强大的中文处理能力,如果我们基于更大的70B模型、未来的405B模型,使用更多的中文数据去做增强训练,或将揭示LLaMA3更多潜力。
然而性能更好、规模更大的模型,其推理成本也会变得更加昂贵。无问芯穹的Infini-ACC大模型计算加速引擎正是为此而生。
挑选适合场景应用的特定模型,并通过软硬件协同优化方法,降低大模型在应用中的推理成本,已经成为AI能力落地千行百业的重要课题。目前,无问芯穹Infini-ACC大模型计算加速引擎已实现在主流GPU上的2-4倍推理提速,并针对大模型场景,在国内外十余种计算卡上实现最高推理加速比。
我们将持续关注LLaMA3在更多中文数据训练增强后的表现,展开相应计算加速研究,并将相关计算加速能力集成到Infini-ACC大模型计算加速引擎中。















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









