






- 有序表顺序搜索算法分析
如果数据项不在列表中,比对平均次数是n/2
如果数据项在列表中,要比对的次数,其情况就较为复杂
因为数据项在列表中各个位置出现的概率是相同的;所以平均状况下,比对的次数是n/2;
实际上,就算法复杂度而言,仍然是O(n)
只是在数据项不存在的时候,有序表的查找能节省一些比对次数,但并不改变其数量级
- 从列表中间开始比对
如果列表中间的项匹配搜索项,则搜索结束
如果不匹配,那么就有两种情况:
• 列表中间项比搜索项大,那么搜索项只可能出现在前半部分
• 列表中间项比搜索项小,那么搜索项只可能出现在后半部分
无论如何,我们都会将比对范围缩小到原来的一半: n/2
继续采用上面的方法搜索每次都会将比对范围缩小一半
这种搜索方式就是二分搜索
- 二分搜索:代码
def binarySearch(alist, item):
first = 0
last = len(alist)-1
found = False
while first<=last and not found:
midpoint = (first + last)//2
if alist[midpoint] == item: # 中间项比对
found = True
else:
if item < alist[midpoint]: # 缩小对比范围
last = midpoint-1
else:
first = midpoint+1
return found
testlist = [0, 1, 2, 8, 13, 17, 19, 32, 42,]
print (binarySearch(testlist, 3))
print ( binarySearch(testlist, 13))
结果
“”"
False
True
“”"
二分搜索算法实际上体现了解决问题的典型策略:分而治之
将问题分为若干更小规模的部分通过解决每一个小规模部分问题,并将结果汇总 得到原问题的解
显然,递归算法就是一种典型的分治策略算法,二分法也适合用递归算法来实现
def binarySearch(alist, item):
if len(alist) == 0:
return False
else:
midpoint = len(alist)//2
if alist [midpoint ]==item:
return True
else:
if item<alist [midpoint] :
return binarySearch( alist[ : midpoint], item)
else:
return binarySearch(alist [midpoint+1:], item)
testlist = [0, 1, 2, 8, 13, 17, 19, 32, 42,]
print (binarySearch(testlist, 3))
print ( binarySearch(testlist, 13))
结果
“”"
False
True
“”"
- 二分搜索算法分析
由于二分搜索,每次比对都将下一步的比对范围缩小一半
当比对次数足够多以后,比对范围内就会仅剩余1个数据项
无论这个数据项是否匹配搜索项,比对最终都会结束
n/2^i = 1
i = log2(n)
所以二分法搜索的算法复杂度是O(log n)
虽然我们根据比对的次数,得出二分搜索 的复杂度O(log n)
但本算法中除了比对,还有一个因素需要注意到 :
binarySearch(alist[:midpoint],item)
这个递归调用使用了列表切片,而切片操作的复杂度是 O(k),这样会使整个算法的时间复杂度稍有增加;
当然,我们采用切片是为了程序可读性更好,实际上也可以不切片,
而只是传入起始和结束的索引值即可,这样就不会有切片的时间开销了。
另外,虽然二分搜索在时间复杂度上优于顺序搜索
但也要考虑到对数据项进行排序的开销
如果一次排序后可以进行多次搜索,那么排序的开销就可以摊薄
但如果数据集经常变动,搜索次数相对较少,那么可能还是直接用 无序表加上顺序搜索来得经济
所以,在算法选择的问题上,光看时间复杂度的优劣是 不够的,还需要考虑到实际应用的情况
- 散列的一些基本概念
前面我们利用数据集中关于数据项之间排列关系的知识,来将搜索算法进行了提升
如果数据项之间是按照大小排好序的话,就可以利用二分搜索来降低算法复杂度。
现在我们进一步来构造一个新的数据结构,能使得搜索算法的复杂度降到O(1),
这 种概念称为“散列Hashing”
能够使得搜索的次数降低到常数级别,我们对数据项所处的位置就必须有更多的先 验知识。
如果我们事先能知道要找的数据项应该出现在数据集中的什么位置,就可以直接到 那个位置看看数据项是否存在即可
哈希算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一
且极其紧凑的数值表示形式。如果散列一段明文而且哪怕只更改该段落的一个字母,随后的哈希都将产生不同的值。要找到
散列为同一个值的两个不同的输入,在计算上是不可能的,所以数据的哈希值可以检验数据的完整性。一般用于快速查找和
加密算法
散列表(hash table,又称哈希表)是一种数据集,其中数据项的存储方式尤其有利于将来快速的搜索定位。
散列表中的每一个存储位置,称为槽(slot),可以用来保存数据项,每个槽有一个唯一的名称。
实现从数据项到存储槽名称的转换的,称为散列函数(hash function)
槽被数据项占据的比例称为散列表的“ 负载因子”
- 示例(对散列有更深入的了解)
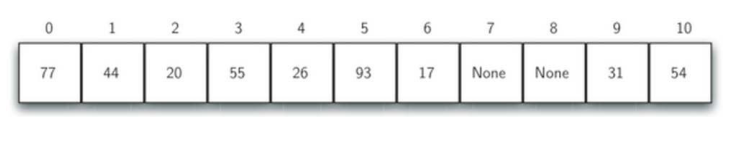
例如:一个包含11个槽的散列表,槽的名称分别为0~ 10
在插入数据项之前,每个槽的值都是None,表示空槽
实现从数据项到存储槽名称的转换的,称为散列函数(hash function)
下面示例中,散列函数接受数据项作为参数,返回整数值0~ 10,表示数据项存储的槽号(名称)
为了将数据项保存到散列表中,我们设计第一个散列函数
数据项: 54, 26, 93, 17, 77, 31
有一种常用的散列方法是“求余数” ,将数据项除以散列表的大小,得到的余数作为槽号。
实际上“ 求余数” 方法会以不同形式出现在所有散列函数里
因为散列函数返回的槽号必须在散列表大小范围之内,所以一般会对散列表大小求余
本例中我们的散列函数是最简单的求余:h(item)= item % 11
按照散列函数h(item),为每个数据项计算出存放的位置之后,就可以将数据项存入相应的槽中
Item HashValue
54 10
26 4
93 5
17 6
77 0
31 9
例子中的6个数据项插入后,占据了散列表11个槽中的6个
槽被数据项占据的比例称为散列表的“ 负载因子” ,这里负载因子为6/11
数据项都保存到散列表后,搜索就无比简单
要搜索某个数据项是否存在于表中,我们只需要使用同一个散列函数,对搜索项进行计算,测试下返回的槽号所对应的槽中
是否有数据项即可.实现了O(1)时间复杂度的搜索算法。
不过,你可能也看出这个方案的问题所在,这组数据相当凑巧,各自占据了不同槽
假如还要保存44,h(44)=0,它跟77被分配到同一个0#槽中,这种情况称为“冲
突collision” ,我们后面会讨论到这个问题的解决方案
- 完美散列函数
❖ 给定一组数据项,如果一个散列函数能把每个数据项映射到不同的槽中,那么这个散列函数就可以称为“完美散列函数”
❖ 对于固定的一组数据,总是能想办法设计出完美散列函数
❖ 但如果数据项经常性的变动,很难有一个系统性的方法来设计对应的完美散列函数
❖ 获得完美散列函数的一种方法是扩大散列表的容量,大到所有可能出现的数据项都能够占据不同的槽
❖ 但这种方法对于可能数据项范围过大的情况并不实用
(假如我们要保存手机号(11位数字),完美散列函数得要求散列表具有百亿个槽!会浪费太多存储空间)
❖ 退而求其次,好的散列函数需要具备特性冲突最少(近似完美)、计算难度低(额外开销小)、充分分散数据项(节约空间)
- 完美散列函数的更多用途
❖ 除了用于在散列表中安排数据项的存储位置,散列技术还用在信息处理的很多领域
❖ 由于完美散列函数能够对任何不同的数据生成不同的散列值,如果把散列值当作数据的“指纹” 或者“摘要” ,这种特性被广泛应用在数据的一致性校验上
由任意长度的数据生成长度固定的“指纹”,还要求具备唯一性,这在数学上是无法做到的,但设计巧妙的“ 准完美”
散列函数却能在实用范围内做到这一点
❖作为一致性校验的数据“指纹” 函数需要具备如下的特性
压缩性:任意长度的数据,得到的“ 指纹”长度是固定的;
易计算性:从原数据计算“指纹”很容易;(从指纹计算原数据是不可能的);
抗修改性:对原数据的微小变动,都会引起“ 指纹” 的大改变;
抗冲突性:已知原数据和“指纹”,要找到相同指纹的数据(伪造)是非常困难的
- Python的散列函数库hashlib
Python自带MD5和SHA系列的散列函数库: hashlib
包括了md5 / sha1 / sha224 / sha256 /sha384 / sha512等6种散列函数
import hashlib
print(hashlib.md5(“hello world!”.encode(“utf8”)).hexdigest())
print(hashlib.md5(“hello world”.encode(“utf8”)).hexdigest())
print(hashlib.sha1(“hello world!”.encode(“utf8”)).hexdigest())
m = hashlib.md5()
m.update(“hello world!”.encode(“utf8”))
print(m.hexdigest())
结果
“”"
fc3ff98e8c6a0d3087d515c0473f8677
5eb63bbbe01eeed093cb22bb8f5acdc3
430ce34d020724ed75a196dfc2ad67c77772d169
fc3ff98e8c6a0d3087d515c0473f8677
“”"
- 完美散列函数用于数据一致性校验
❖数据文件一致性判断
❖为每个文件计算其散列值,仅对比其散列值即可得知是否文件内容相同;
❖用于网络文件下载完整性校验;
❖用于文件分享系统:网盘中相同的文件(尤其是电影)可以无需存储多次
❖加密形式保存密码
❖仅保存密码的散列值,用户输入密码后,计算散列值并比对;
❖无需保存密码的明文即可判断用户是否输入了正确的密码。
(通过值计算散列值很简单,但反过来就不可以)
- 散列函数设计:折叠法
❖ 折叠法设计散列函数的基本步骤是
将数据项按照位数分为若干段,
再将几段数字相加,
最后对散列表大小求余,得到散列值
❖ 例如,对电话号码62767255
可以两位两位分为4段(62、 76、 72、 55)
相加(62+76+72+55=265)
散列表包括11个槽,那么就是265%11=1
所以h(62767255)=1
❖ 有时候折叠法还会包括一个隔数反转的步骤
比如(62、 76、 72、 55)隔数反转为(62、 67、 72、 55)
再累加(62+67+72+55=256)
对11求余(256%11=3),所以h’(62767255)=3
❖ 虽然隔数反转从理论上看来毫无必要,但这个步骤确实为折叠法得到散列函数提供了一种微调手段,以便更好符合散列特性
- 散列函数设计:平方取中法
❖ 平方取中法,首先将数据项做平方运算,然后取平方数的中间两位,再对散列表的大小求余
❖ 例如,对44进行散列
首先44*44=1936
然后取中间的93
对散列表大小11求余, 93%11=5
- 散列函数设计:非数项
“”"
❖ 我们也可以对非数字的数据项进行散列,把字符串中的每个字符看作ASCII码即可
如cat, ord(‘c’)==99, ord(‘a’)==96,ord(‘t’)==116
❖ 再将这些整数累加,对散列表大小求余
“”"
def hash(astring,tablesize):
sum = 0
for pos in range(len(astring)):
sum = sum + ord(astring[pos])
return sum%tablesize
ord函数可以将字符转化为你所需要的ASCII码
当然,这样的散列函数对所有的异序词都返回相同的散列值
为了防止这一点,可以将字符串所在的位置作为权重因子,乘以ord值
- 散列函数设计
❖ 我们还可以设计出更多的散列函数方法,但要坚持的一个基本出发点是,散列函数不能成为存储过程和搜索过程的计算负担
❖ 如果散列函数设计太过复杂,去花费大量的计算资源计算槽号,失去了散列本身的意义
可能还不如简单地进行顺序搜索或者二分搜索
- 冲突解决方案
❖ 如果两个数据项被散列映射到同一个槽,需要一个系统化的方法在散列表中保存第二个数据项,这个过程称为“解决冲突”
❖ 前面提到,如果说散列函数是完美的,那就不会有散列冲突,但完美散列函数常常是不现实的
❖ 解决散列冲突成为散列方法中很重要的一部分。
❖ 解决散列的一种方法就是为冲突的数据项再找一个开放的空槽来保存
最简单的就是从冲突的槽开始往后扫描,直到碰到一个空槽
如果到散列表尾部还未找到,则从首部接着扫描
❖ 这种寻找空槽的技术称为“ 开放定址open addressing”
❖向后逐个槽寻找的方法则是开放定址技术中的“线性探测linear probing”
- 冲突解决方案:线性探测Linear Probing

我们把44、 55、 20逐个插入到散列表中
h(44)=0,但发现0#槽已被77占据,向后找到第一个空槽1#,保存
h(55)=0,同样0#槽已经被占据,向后找到第一个空槽2#,保存
h(20)=9,发现9#槽已经被31占据了,向后,再从头开始找到3#槽保存
采用线性探测方法来解决散列冲突的话,则散列表的搜索也遵循同样的规则
如果在散列位置没有找到搜索项的话,就必须向后做顺序搜索
直到找到搜索项,或者碰到空槽(搜索失败)。
- 冲突解决方案:线性探测的改进
❖ 线性探测法的一个缺点是有聚集(clustering)的趋势
❖ 即如果同一个槽冲突的数据项较多的话,这些数据项就会在槽附近聚集起来
❖ 从而连锁式影响其它数据项的插入
❖ 避免聚集的一种方法就是将线性探测扩展,从逐个探测改为跳跃式探测
下图是“ +3” 探测插入44、 55、 20

- 冲突解决方案:再散列rehashing
❖ 重新寻找空槽的过程可以用一个更为通用的“再散列rehashing” 来概括
newhashvalue = rehash(oldhashvalue)
对于线性探测来说, rehash(pos)= (pos+ 1)%sizeoftable
“ +3” 的跳跃式探测则是: rehash(pos)=(pos+ 3)% sizeoftable
跳跃式探测的再散列通式是: rehash(pos)=(pos+skip)% sizeoftable
❖ 跳跃式探测中,需要注意的是skip的取值,不能被散列表大小整除,否则会产生周期,造成很多空槽永远无法探测到
一个技巧是,把散列表的大小设为素数,如例子的11
❖ 还可以将线性探测变为“ 二次探测 quadratic probing”
❖ 不再固定skip的值,而是逐步增加skip值,如1、 3、 5、 7、 9
❖ 这样槽号就会是原散列值以平方数增加:h, h+1, h+4, h+9, h+16…
- 冲突解决方案:数据项链Chaining
❖除了寻找空槽的开放定址技术之外,另一种解决散列冲突的方案是将容纳单个数据项的槽扩展为容纳数据项集合(或者对数据项链表的引用)
❖这样,散列表中的每个槽就可以容纳多个数据项,如果有散列冲突发生,只需要简单地将数据项添加到数据项集合中。
❖搜索数据项时则需要搜索同一个槽中的整个集合,当然,随着散列冲突的增加,对数据项的搜索时间也会相应增加。

===============================================================================
- 抽象数据类型“映射”:ADT Map
❖ Python最有用的数据类型之一“字典”
❖ 字典是一种可以保存key-data键值对的数据类型
其中关键码key可用于查询关联的数据值data
❖ 这种键值关联的方法称为“映射Map”
❖ ADT Map的结构是键-值关联的无序集合
关键码具有唯一性
通过关键码可以唯一确定一个数据值
实现ADT Map
❖ 使用字典的优势在于,给定关键码key,能够很快得到关联的数据值data
❖ 为了达到快速搜索的目标,需要一个支持高效搜索的ADT实现
可以采用列表数据结构加顺序搜索或者二分搜索当然,更为合适的是使用前述的散列表来实现,这样搜索可以达到最快O(1)的性能
- ADT Map定义的操作
Map():创建一个空映射,返回空映射对象;
put(key, val):将key‐val关联对加入映射中,如果key已存在,将val替换旧关联值;
get(key):给定key,返回关联的数据值,如不存在,则返回None;
del:通过del map[key]的语句形式删除key‐val关联;
len():返回映射中key‐val关联的数目;
in:通过key in map的语句形式,返回key是否存在于关联中,布尔值
- ADT Map 的实现实例
#我们用一个HashTable类来实现ADT Map,该类包含了两个列表作为成员
其中一个slot列表用于保存key
另一个平行的data列表用于保存数据项
在slot列表搜索到一个key的位置以后,在data列表对应相同位置的数据项即为关联数据
class HashTable:
def init (self):
self.size = 11
self.slots = [None]*self.size
self.data = [None]*self.size
def hashfunction(self, key):
return key% self.size
def rehash( self, oldhash):
return (oldhash+ 1)% self.size
def put(self,key,data):
hashvalue = self.hashfunction(key)
if self.slots [hashvalue] == None:
self.slots[hashvalue] = key
self.data [hashvalue] = data
else:
if self.slots [hashvalue] == key:
self.data[hashvalue] = data #replace
else:
nextslot = self.rehash(hashvalue)
while self.slots[nextslot] != None and self.slots [nextslot] != key:
nextslot = self.rehash(nextslot)
if self.slots [nextslot] == None:
self . slots[nextslot]=key
self . data [nextslot]=data
else:
self.data[nextslot] = data #replace
def get(self,key):
startslot = self.hashfunction(key) # 标记散列值为搜索起点
data = None
stop = False
found = False
position = startslot
while self.slots[position] != None and not found and not stop:
找key,直到空槽或回到起点
if self.slots[position] == key:
found = True
data = self . data[position]
else:
position=self.rehash( position) # 未找到key,再散列继续找
if position == startslot: # 回到起点 , 停
stop = True
return data
通过特殊方法实现[]访问
def getitem(self, key):
return self.get(key)
def setitem(self, key, data):
self.put(key, data)
H=HashTable()
H[54]=“cat”
H[26]= “dog”
H[93]=“lion”
H[17]=“tiger”
H[77]=“bird”
H[31]=“cow”
H[44]=“goat”
H[55]=“pig”
H[ 20]= “chicken”
print(H.slots)
print(H.data)
print(H[20])
print(H[17])
H[20]= ‘duck’
print(H[20])
print(H[99])
结果
“”"
[77, 44, 55, 20, 26, 93, 17, None, None, 31, 54]
[‘bird’, ‘goat’, ‘pig’, ‘chicken’, ‘dog’, ‘lion’, ‘tiger’, None, None, ‘cow’, ‘cat’]
chicken
tiger
duck
None
“”"
- 散列算法分析
❖ 散列在最好的情况下,可以提供O(1)常数级时间复杂度的搜索性能
由于散列冲突的存在,搜索比较次数就没有这么简单
❖ 评估散列冲突的最重要信息就是负载因子λ,
一般来说:
如果λ较小,散列冲突的几率就小,数据项通常会保存在其所属的散列槽中
如果λ较大,意味着散列表填充较满,冲突会越来越多,冲突解决也越复杂,也就需要更多的比较来找到空槽;如果采用数据链的话,意味着每条链上的数据项增多
❖ 如果采用线性探测的开放定址法来解决冲突(λ在0~1之间)
成功的搜索,平均需要比对次数为:0.5*(1 + 1/(1-λ)) 不成功的搜索,平均比对次数为: 0.5*(1 + 1/(1-λ)^2)
❖ 如果采用数据链来解决冲突(λ可大于1)
成功的搜索,平均需要比对次数为: 1 + λ/2
不成功的搜索,平均比对次数为: λ
================================================================
代码
def bubbleSort(alist):
for passnum in range(len(alist)-1,0,-1):
for i in range(passnum):
if alist[i]>alist[i+1]:
temp = alist[i]
alist[i] = alist[i+1]
alist[i+1] = temp
alist = [54,26,93,17,77,31,44,55,20]
bubbleSort(alist)
print(alist)
结果
[17, 20, 26, 31, 44, 54, 55, 77, 93]
冒泡排序:算法分析
比对次数是1~ n-1的累加:1/2 * n * (n-1)
比对的时间复杂度是O(n^2)
“”"
❖ 关于交换次数,时间复杂度也是O(n^2),通常每次交换包括3次赋值
❖ 最好的情况是列表在排序前已经有序,交换次数为0
❖ 最差的情况是每次比对都要进行交换,交换次数等于比对次数
❖ 平均情况则是最差情况的一半
❖ 冒泡排序通常作为时间效率较差的排序算法,来作为其它算法的对比基准。
❖ 其效率主要差在每个数据项在找到其最终位置之前,必须要经过多次比对和交换,其中大部分的操作是无效的。
❖ 但有一点优势,就是无需任何额外的存储空间开销。
“”"
性能改进
“”"
❖ 另外,通过监测每趟比对是否发生过交换,可以提前确定排序是否完成
❖ 这也是其它多数排序算法无法做到的
❖ 如果某趟比对没有发生任何交换,说明列表已经排好序,可以提前结束算法"
“”"
def shortBubbleSort(alist):
exchanges = True
passnum = len(alist)-1
while passnum > 0 and exchanges:
exchanges = False
for i in range(passnum):
if alist[i]>alist[i+1]:
exchanges = True
temp = alist[i]
alist[i] = alist[i+1]
alist[i+1] = temp
passnum = passnum - 1
alist=[20,30,40,90,50, 60,70, 80, 100,110]
shortBubbleSort(alist)
print(alist)
结果
[20, 30, 40, 50, 60, 70, 80, 90, 100, 110]
“”"
❖ 选择排序对冒泡排序进行了改进,保留了其基本的多趟比对思路,每趟都使当前最大项就位。
❖ 但选择排序对交换进行了削减,相比起冒泡排序进行多次交换,每趟仅进行1次交换,记录最大项的所在位置,最后再跟本趟最后一项交换
❖ 选择排序的时间复杂度比冒泡排序稍优
比对次数不变,还是O(n2)
交换次数则减少为O(n)
“”"
def selectionSort(alist):
for fillslot in range(len(alist)-1,0,-1):
positionOfMax=0
for location in range(1, fillslot+1):
if alist[location]>alist[positionOfMax]:
positionOfMax = location
temp = alist[fillslot]
alist[fillslot] = alist[positionOfMax]
alist[positionOfMax] = temp
alist = [54,26,93,17,77,31,44,55,20]
selectionSort(alist)
print(alist)
结果
[17, 20, 26, 31, 44, 54, 55, 77, 93]
“”"
❖ 第1趟,子列表仅包含第1个数据项,将第2个数据项作为“新项” 插入到子列表的合适位置中,这样已排序的子列表就包含了2个数据项
❖ 第2趟,再继续将第3个数据项跟前2个数据项比对,并移动比自身大的数据项,空出位置来,以便加入到子列表中
❖ 经过n-1趟比对和插入,子列表扩展到全表,排序完成
❖ 插入排序的比对主要用来寻找“新项” 的插入位置
❖ 最差情况是每趟都与子列表中所有项进行比对,总比对次数与冒泡排序相同,数量级仍是O(n2)
❖ 最好情况,列表已经排好序的时候,每趟仅需1次比对,总次数是O(n)
“”"
def insertionSort(alist):
for index in range(1,len(alist)):
currentvalue = alist[index] #新项/插入项
position = index
while position>0 and alist[position-1]>currentvalue:
alist[position]=alist[position-1]
position = position-1 # 比对、移动
alist[position]=currentvalue # 插入新项
alist = [54,26,93,17,77,31,44,55,20]
insertionSort(alist)
print(alist)
结果
[17, 20, 26, 31, 44, 54, 55, 77, 93]
-
我们注意到插入排序的比对次数,在最好的情况下是O(n),这种情况发生在列表已是有序的情况下,实际上, 列表越接近有序,插入排序的比对次数就越少
-
从这个情况入手,谢尔排序以插入排序作为基础,对无序表进行“间隔” 划分子列表,每个子列表都执行插入排序
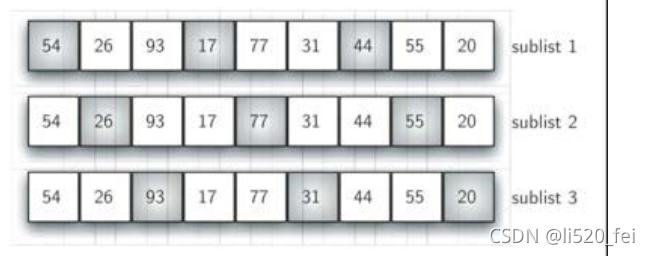
-
随着子列表的数量越来越少,无序表的整体越来越接近有序,从而减少整体排序的比对次数
-
间隔为3的子列表,子列表分别插入排序后的整体状况更接近有序
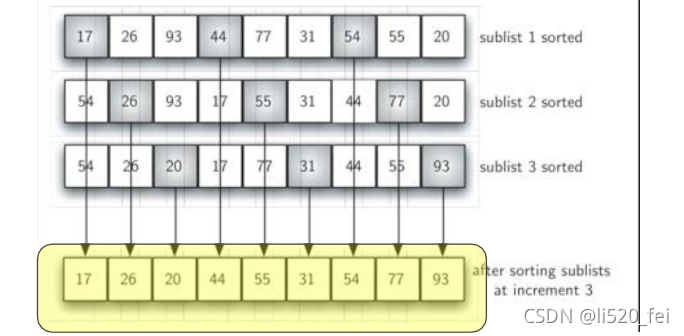
-
最后一趟是标准的插入排序,但由于前面几趟已经将列表处理到接近有序,这一趟仅需少数几次移动即可完成
-
子列表的间隔一般从n/2开始,每趟倍增: n/4, n/8…… 直到1
def shellSort(alist):
sublistcount = len(alist)//2 # 间隔设定
while sublistcount > 0:
for startposition in range(sublistcount): # 子列表排序
gapInsertionSort(alist , startposition, sublistcount)
print(“After increments of size” , sublistcount ,“The list is”,alist)
sublistcount = sublistcount // 2 # 间隔缩小
def gapInsertionSort (alist,start,gap):
for i in range(start+gap,len(alist),gap):
currentvalue = alist[i]
position = i
while position>=gap and alist [position-gap]>currentvalue:
alist[position]=alist [position-gap]
position = position-gap
alist[position]=currentvalue
alist = [54,26,93,17,77,31,44,55,20]
shellSort(alist)
结果
“”"
After increments of size 4 The list is [20, 26, 44, 17, 54, 31, 93, 55, 77]
After increments of size 2 The list is [20, 17, 44, 26, 54, 31, 77, 55, 93]
After increments of size 1 The list is [17, 20, 26, 31, 44, 54, 55, 77, 93]
“”"
-
粗看上去,谢尔排序以插入排序为基础,可能并不会比插入排序好
-
但由于每趟都使得列表更加接近有序,这过程会减少很多原先需要的“无效” 比对
对谢尔排序的详尽分析比较复杂,大致说是介于O(n)和O(n2)之间
- 如果将间隔保持在2k-1(1、 3、 5、 7、 15、 31等等),谢尔排序的时间复杂度约为O(n3/2)
-
分治策略在排序中的应用
-
归并排序是递归算法,思路是将数据表持续分裂为两半,对两半分别进行归并排序
递归的基本结束条件是:数据表仅有1个数据项,自然是排好序的;
缩小规模:将数据表分裂为相等的两半,规模减为原来的二分之一;
调用自身:将两半分别调用自身排序,然后将分别排好序的两半进行
def mergeSort(alist):
if len(alist)>1:# 基本结束条件
mid = len(alist)//2
lefthalf = alist[ :mid]
righthalf = alist[mid:]
mergeSort(lefthalf) # 递归调用
mergeSort(righthalf)
i=j=k=0
while i<len(lefthalf) and j<len(righthalf):#拉链式交错把左右半部从小到大归并到结果列表中
if lefthalf[i]<righthalf[j]:
alist[k]=lefthalf[i]
i=i+1
else:
alist[k]=righthalf[j]
j=j+1
k=k+1
while i<len(lefthalf):#归并左半部剩余项
alist[k]=lefthalf[i]
i=i+1
k=k+1
while j<len(righthalf):#归并右半部剩余项
alist[k]=righthalf[j]
j=j+1
k=k+1
alist = [54,26,93,17,77,31,44,55,20]
mergeSort(alist)
print(alist)
结果
[17, 20, 26, 31, 44, 54, 55, 77, 93]
另一个归并排序代码
def merge_sort(lst):
#递归结束条件
if len(lst) <= 1:
return lst
#分解问题,并递归调用
middle = len(lst) // 2
left = merge_sort(lst[:middle]) #左半部排好序
right = merge_sort(lst[middle:]) # 右半部排好序
#合并左右半部,完成排序
merged = []
while left and right :
if left[0] <= right[0]:
merged. append(left.pop(0))
else:
merged. append(right . pop(0))
merged.extend(right if right else left)
return merged
alist = [54,26,93,17,77,31,44,55,20]
print(merge_sort(alist))
结果
[17, 20, 26, 31, 44, 54, 55, 77, 93]
- 归并排序:算法分析
❖ 将归并排序分为两个过程来分析: 分裂和归并
❖ 分裂的过程,借鉴二分搜索中的分析结果,是对数复杂度,时间复杂度为O(log n)
❖ 归并的过程,相对于分裂的每个部分,其所有数据项都会被比较和放置一次,所以是线性复杂度,其时间复杂度是O(n)
综合考虑,每次分裂的部分都进行一次O(n)的数据项归并,总的时间复杂度是O(nlog n)
❖ 最后,我们还是注意到两个切片操作为了时间复杂度分析精确起见,可以通过取消切片操作,
改为传递两个分裂部分的起始点和终止点,也是没问题的,只是算法可读性稍微牺牲一点点。
❖ 我们注意到归并排序算法使用了额外1倍的存储空间用于归并 ,这个特性在对特大数据集进行排序的时候要考虑进去















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









