






一、数据集
此数据集来自厦门二手房房源_厦门二手房出售|买卖|交易信息(厦门链家),爬取的厦门二手房数据,数据下载链接为百度网盘 请输入提取码,提取码为liuj。
二、数据预处理
根据之前的数据集来看,我们需要对数据进行预处理,包括去除‘['’与 ‘']’,去除unit_price的 ‘元\平’ ,follower 的 ‘人关注’,building_area的 ‘平米’,build_year的 ‘年建’,替换修建时间未知值为空值,删除空值。
u = 0
def data_predict(filepath):
#读取数据集
import pandas as pd
global u
df = pd.read_csv(filepath,encoding='gbk')
# #查看文件前数据
# print(df.head())
#
# #查看数据集的简单描述
# print(df.info())
#
# #查看数据集的简单描述
# print(df.describe())
#改动title、total_price、unit_price、louceng、chaoxiang、zhuangxiu、building_area、build_year、community_name、location_info、location_info_seclisting_day、last_trade
#去除‘['’与 ‘']’
df.iloc[:,1] = df.iloc[:,1].str[2:-2]
for i in range(3,5):
df.iloc[:,i] = df.iloc[:,i].str[2:-2]
for j in range(7,15):
df.iloc[:,j] = df.iloc[:,j].str[2:-2]
for k in range(17, 19):
df.iloc[:,k] = df.iloc[:,k].str[2:-2]
#去除unit_price的 ‘元\平’ ,follower 的 ‘人关注’,building_area的 ‘平米’,build_year的 ‘年建’
df.iloc[:,4] = df.iloc[:,4].str[:-3]
df.iloc[:,5] = df.iloc[:,5].str[:-4]
df.iloc[:,10] = df.iloc[:,10].str[:-2]
df.iloc[:,11] = df.iloc[:,11].str[:-2]
#替换修建时间未知值为空值
mask = df.iloc[:,11].str.startswith("未")
df.iloc[mask,11] = ''
# colunmn_title = df['title']
# df['title'] = colunmn_title.str[2:-2]
# print(df)
#将df存入csv文件中
df.to_csv('data/xmhouse_data_clean.csv',index=False,encoding='gbk')
### 删除空值
df_02 = pd.read_csv('data/xmhouse_data_clean.csv',encoding='gbk')
print(df_02.info())
# print(df_02['last_trade'])
# print(df_02.info())
df_02 = df_02.dropna(axis=0)
print(df_02.info())
##更兴第一列索引
df_02.iloc[:,0] = range(0,len(df_02))
##保存csv文件
df_02.to_csv('data/xmhouse_data_clean_{}.csv'.format(u),index=False,encoding='gbk')
u = u + 1
return 'data/xmhouse_data_clean_{}.csv'.format(u-1)
三、建立模型
本次实验采用的是随机森林对数据进行训练(训练集占比为80%,测试集占比为20%)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
from data_predict import *
def model(failpath_1,failpath_2):
# df = pd.read_csv('data/xmhouse_data_clean.csv',encoding='gbk')
# print(df.describe())
#
# df.hist(bins=20,figsize=(20,15))
# plt.show()
data_csv = pd.read_csv(failpath_1,encoding='gbk')
data_csv_2 = pd.read_csv(failpath_2,encoding='gbk')
# 对分类变量进行编码
label_encoders = {}
for column in ['huxing', 'title','louceng','building_area','last_trade','listing_day','elevator','elevator_house','location_info_sec','zhuangxiu','location_info','build_year', 'chaoxiang', 'community_name']:
le = LabelEncoder()
data_csv[column] = le.fit_transform(data_csv[column])
data_csv_2[column] = le.fit_transform(data_csv[column])
label_encoders[column] = le
# print(data_csv[column].unique())
# print(le.classes_)
# 划分特征和目标变量
X = data_csv[
['huxing', 'louceng','title','zhuangxiu','last_trade','listing_day','location_info_sec','elevator_house',
'elevator','build_year','location_info','building_area', 'chaoxiang', 'community_name']]
y = data_csv['total_price']
X2 = data_csv_2[
['huxing', 'louceng', 'title', 'zhuangxiu', 'last_trade', 'listing_day', 'location_info_sec', 'elevator_house',
'elevator', 'build_year', 'location_info', 'building_area', 'chaoxiang', 'community_name']]
y2 = data_csv_2['total_price']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train_2, X_test_2, y_train_2, y_test_2 = train_test_split(X2, y2, test_size=0.999, random_state=42,shuffle=False)
# 特征缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
X_test_scaled_2 = scaler.transform(X_test_2)
# 创建随机森林回归模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
# 在训练集上训练模型
rf_model.fit(X_train_scaled, y_train)
# 在测试集上进行预测
y_pred = rf_model.predict(X_test_scaled)
y_pred_2 = rf_model.predict(X_test_scaled_2)
# 评估模型性能
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
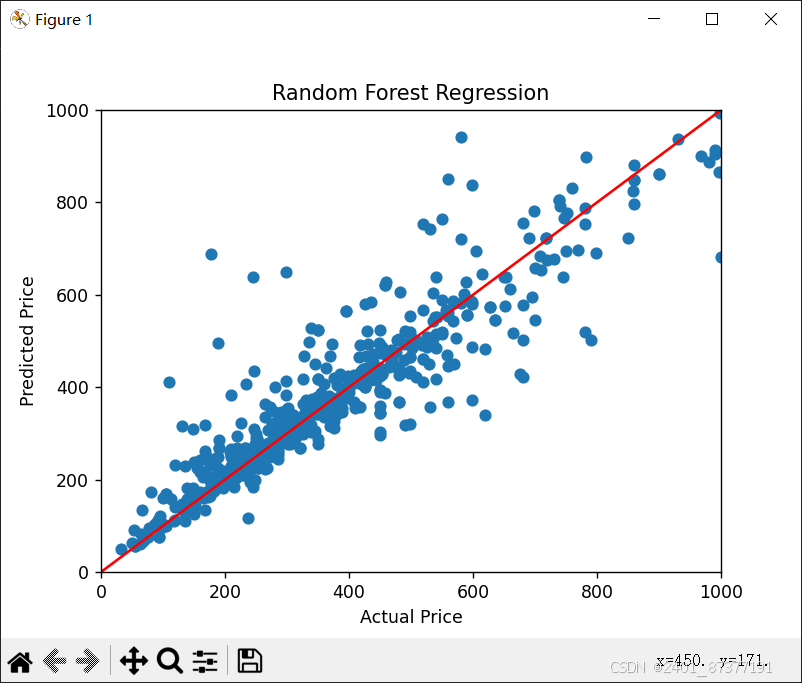
plt.scatter(y_test, y_pred)
plt.xlabel('Actual Price')
plt.ylabel('Predicted Price')
plt.xlim(0, 1000)
plt.ylim(0, 1000)
plt.title('Random Forest Regression')
x_line = np.linspace(0, 4400, 4400)
y_line = x_line
# 绘制 y=x 线
plt.plot(x_line, y_line, 'r')
plt.show()
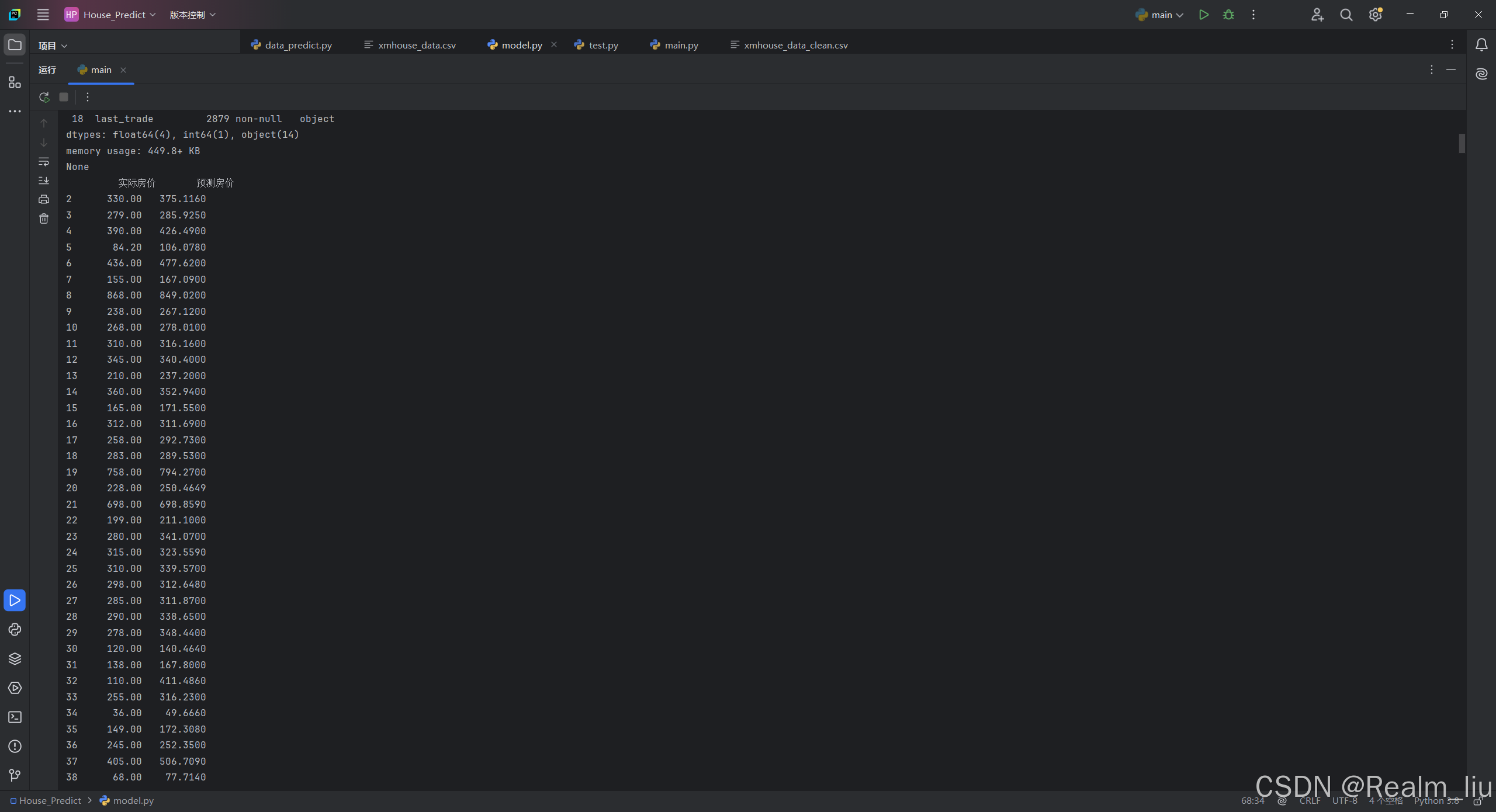
pd.set_option('display.max_rows', None)
# print(pd.DataFrame({'实际房价': y_test, '预测房价': y_pred}))
print(pd.DataFrame({'实际房价': y_test_2, '预测房价': y_pred_2}))
四、主函数main()
from data_predict import data_predict as D1
from model import model as D2
if __name__ == '__main__':
failpath_1 = D1('data/xmhouse_data.csv')
#路径二是对你爬取后来的数据进行预测,本实验并未爬取其他的数据,故使用本身的数据进行测试
failpath_2 = D1('data/xmhouse_data.csv')
D2(failpath_1,failpath_2)五、预测结果
1.预测结果图如下所示,x轴代表真实价值,y轴代表预测价值。
2. 房价预测文字展示如下图所示

















 8507
8507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









