







目录
前言:第一篇CSDN博客,还请各位大佬多多指教!!
一、认识Midjourney
Midjourney是由David Holz 2022年3月推出的一款AI制图工具。处于聊天软件discord中,主要功能涵盖图像生成、风格化、变体生成、图生图等,且提供高级工具精细控制生成过程。 使用上需创建账户、获邀请后通过Discord频道输入文字提示来操作。相比于SD(stable diffusion) MJ随机性更大,细节处理精度不够。
二、Midjourney算法原理
MJ基于深度学习中的生成对抗网络(GAN)和扩散模型等技术。
- 生成对抗网络(GAN):由生成器和判别器组成。生成器的任务是根据输入的随机噪声和文本描述等信息,生成尽可能逼真的图像;判别器则负责判断输入的图像是真实的还是由生成器生成的。在训练过程中,生成器和判别器相互博弈,不断优化自身的参数,以提高生成图像的质量和判别器的准确性,最终使生成器能够生成足以 “欺骗” 判别器的高质量图像。
- 扩散模型:扩散模型通过逐步向数据中添加噪声,然后学习如何去噪来生成新的数据。在图像生成中,它从一个完全随机的噪声图像开始,经过多个扩散步骤,逐渐调整图像的像素值,使其接近真实图像。每一步都根据当前的图像和一些条件信息(如文本提示)来预测下一步的图像,最终生成符合条件的高质量图像。
三、Midjourney基本操作指南
1、安装
- 运用魔法(Mj属国外模型)(MJ全部操作都应在魔法下)
- 下载discord 下载官网
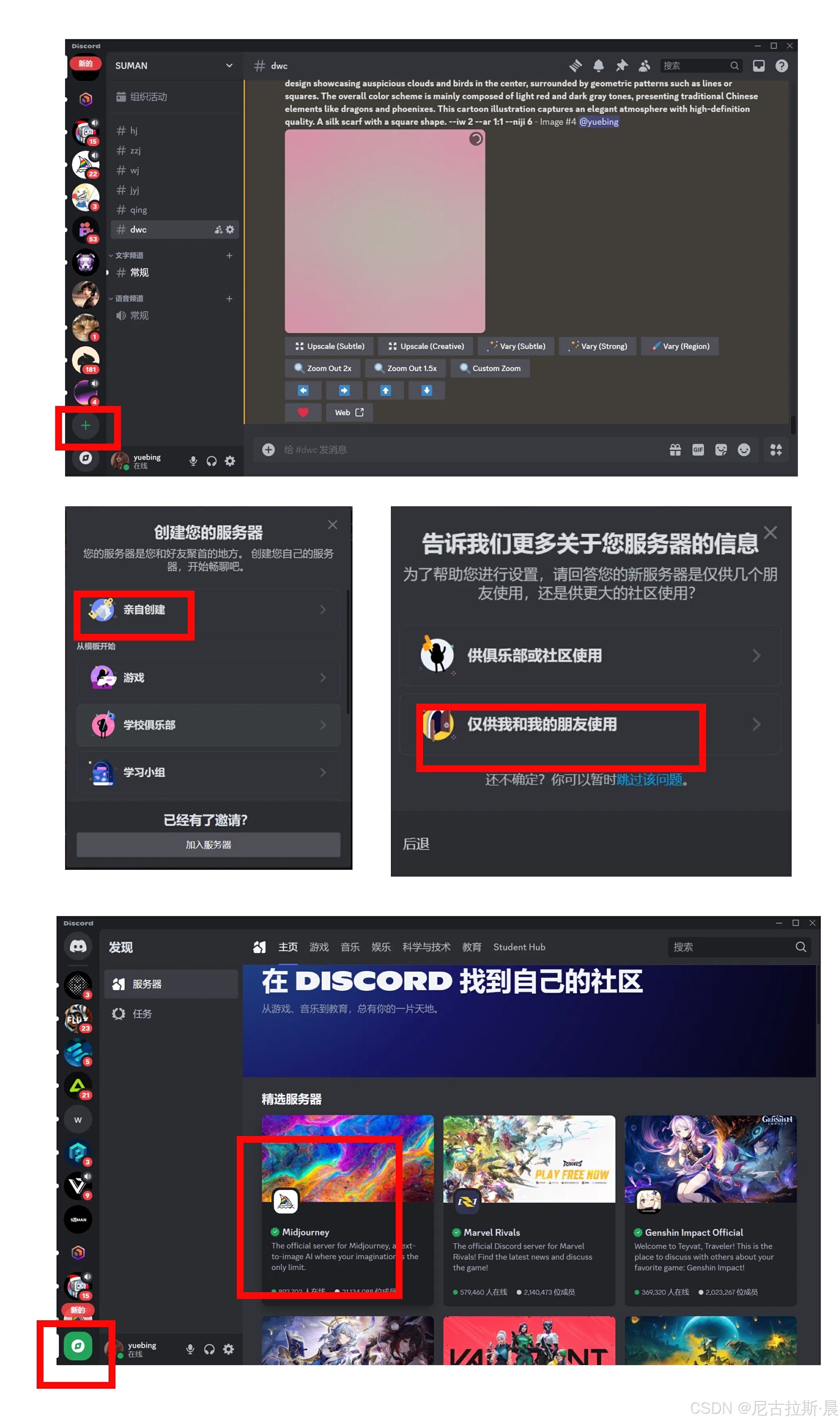
- 登录成功后建立服务器,点击左下角绿色的+号,点击亲自创建,点击仅供我和我的朋友使用,上传头像和名字,完成服务器建立。点击左下角小眼睛,去发现搜索MJ机器人,并将其添加到自己的服务器。
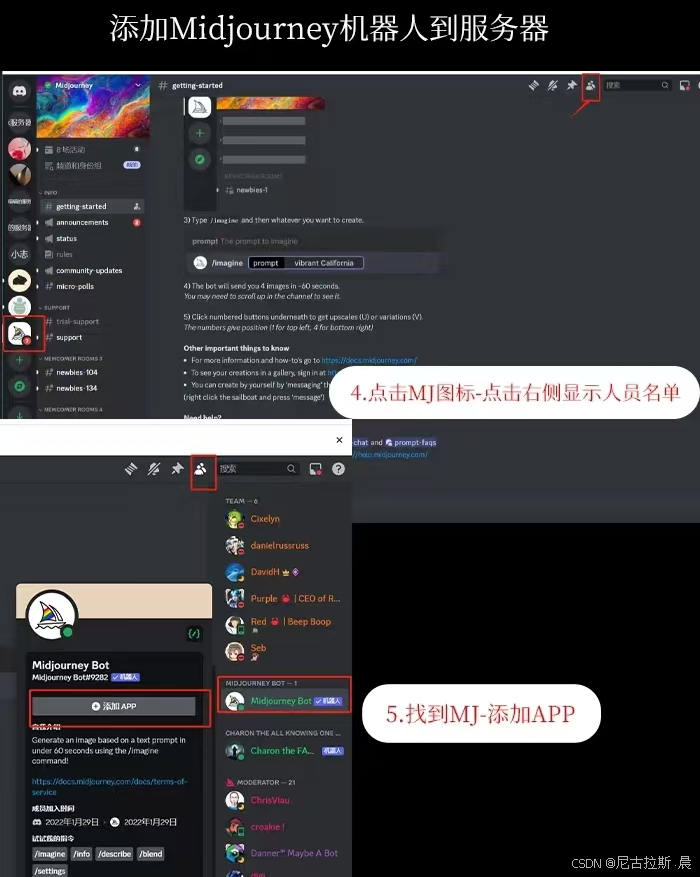
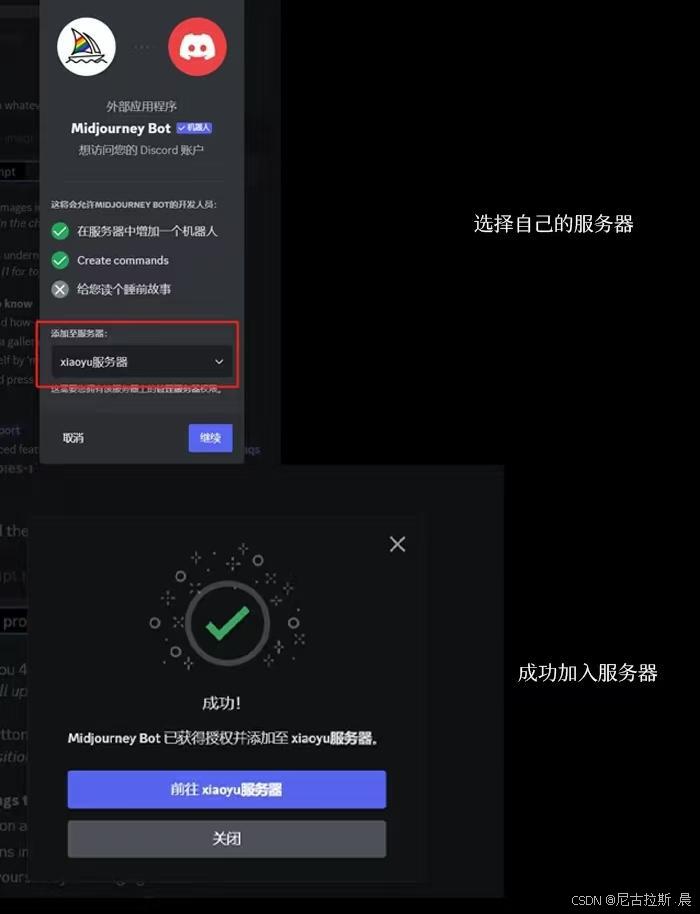
2、使用演示及基本分区讲解
- 使用演示
首先找到我们自己的服务器,在对话框中先输入“/”
就会弹出常用栏,白色帆船生成较为写实的作品,绿色帆船生成偏向于动漫风格的作品。(我们可以根据下图理解一下两种风格的差异)
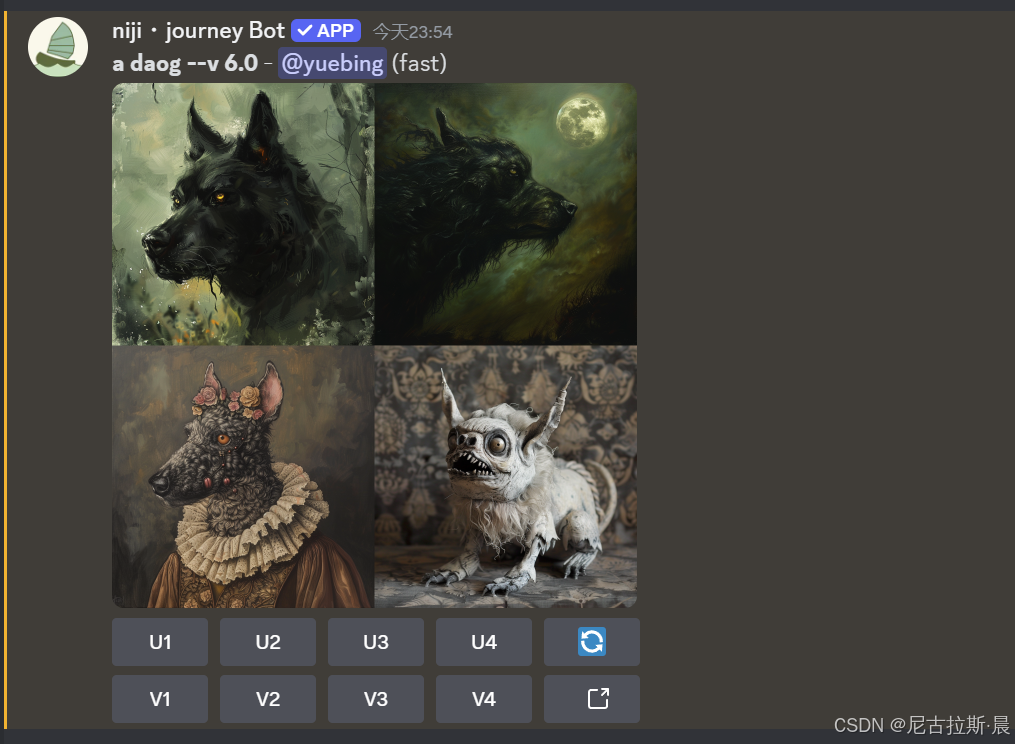
2.基本分区讲解
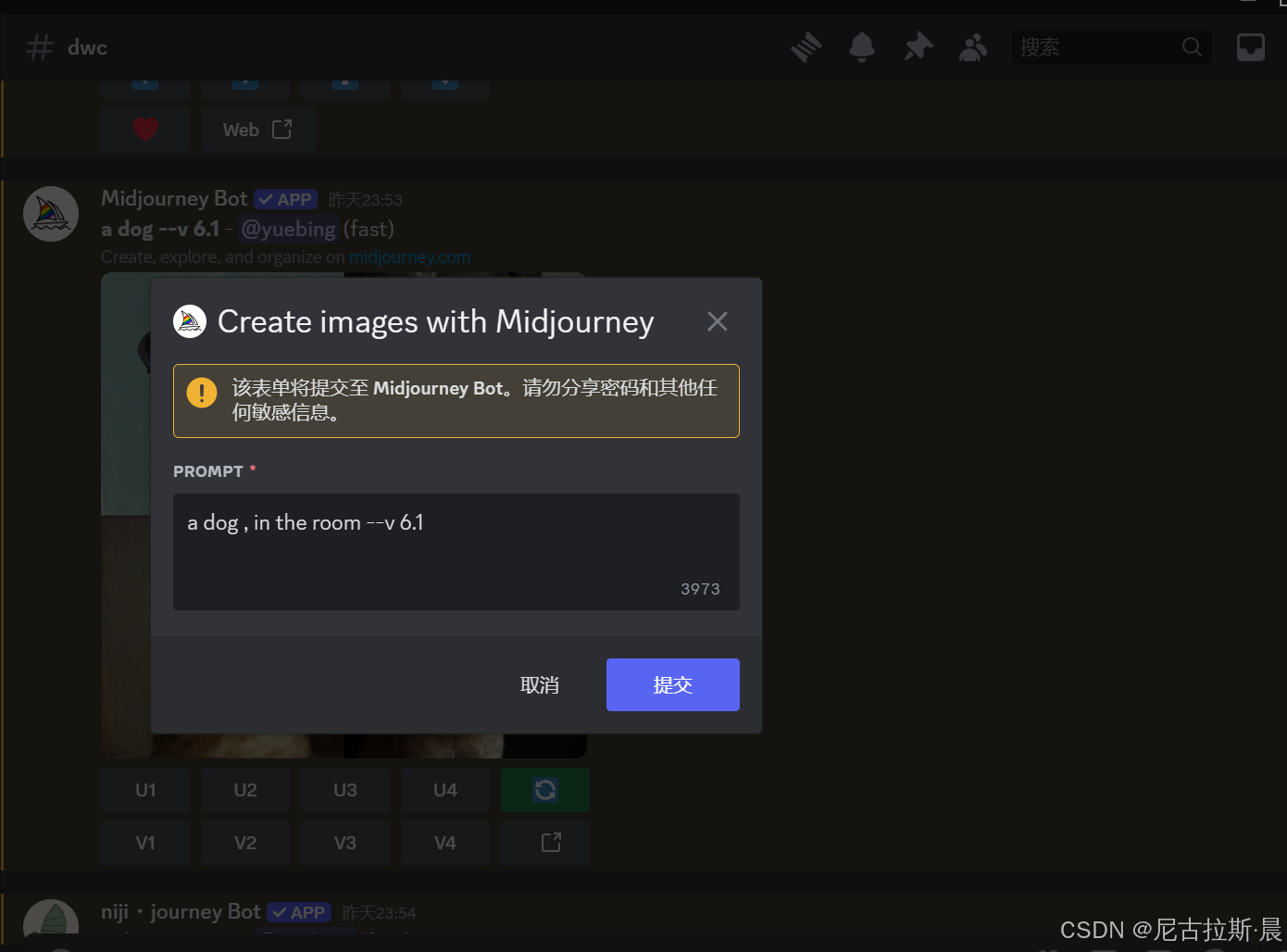
- 第一行最右边的图标代表:重绘,可以在新的界面对原来的提示词进行加工再次生成新的图像,如下图,我点击重绘标识,弹出黑框进行对原来的关键词进行修改加上“in the room”(所有输入都应在英文状态下,不然会报错)
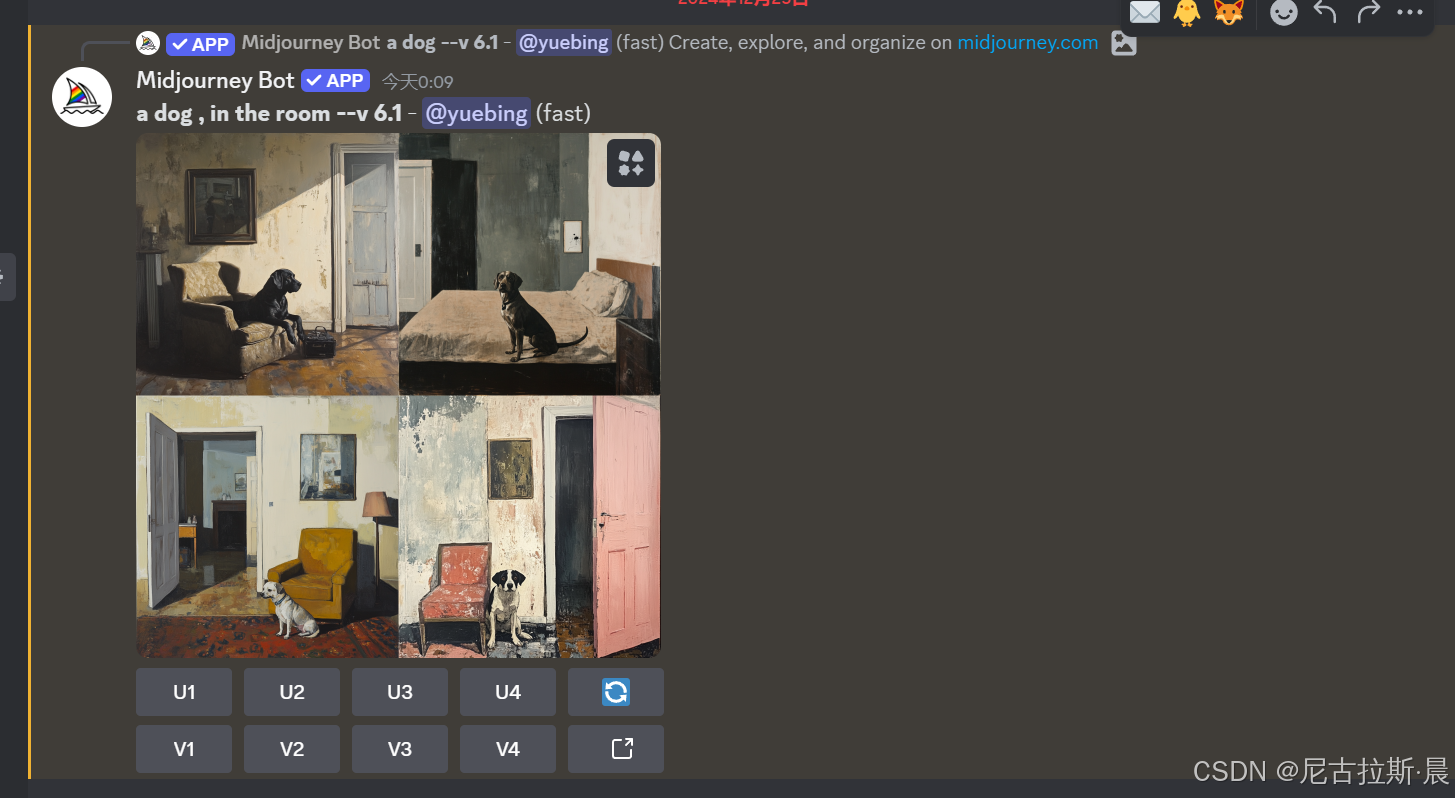
这时我们发现,我们用这个重绘图标进行重绘时,确实加入房子的元素,但是改变了小狗的人物一致性,如何在不改变小狗人物一致性的基础上加入,房间的元素呢?我们后续会详细讲解。
- U1 U2 U3 U4
我们一次操作可以生成四张图,如何查看单张图呢?如何单张图放大呢?这时我们需要用到第一行的按钮。
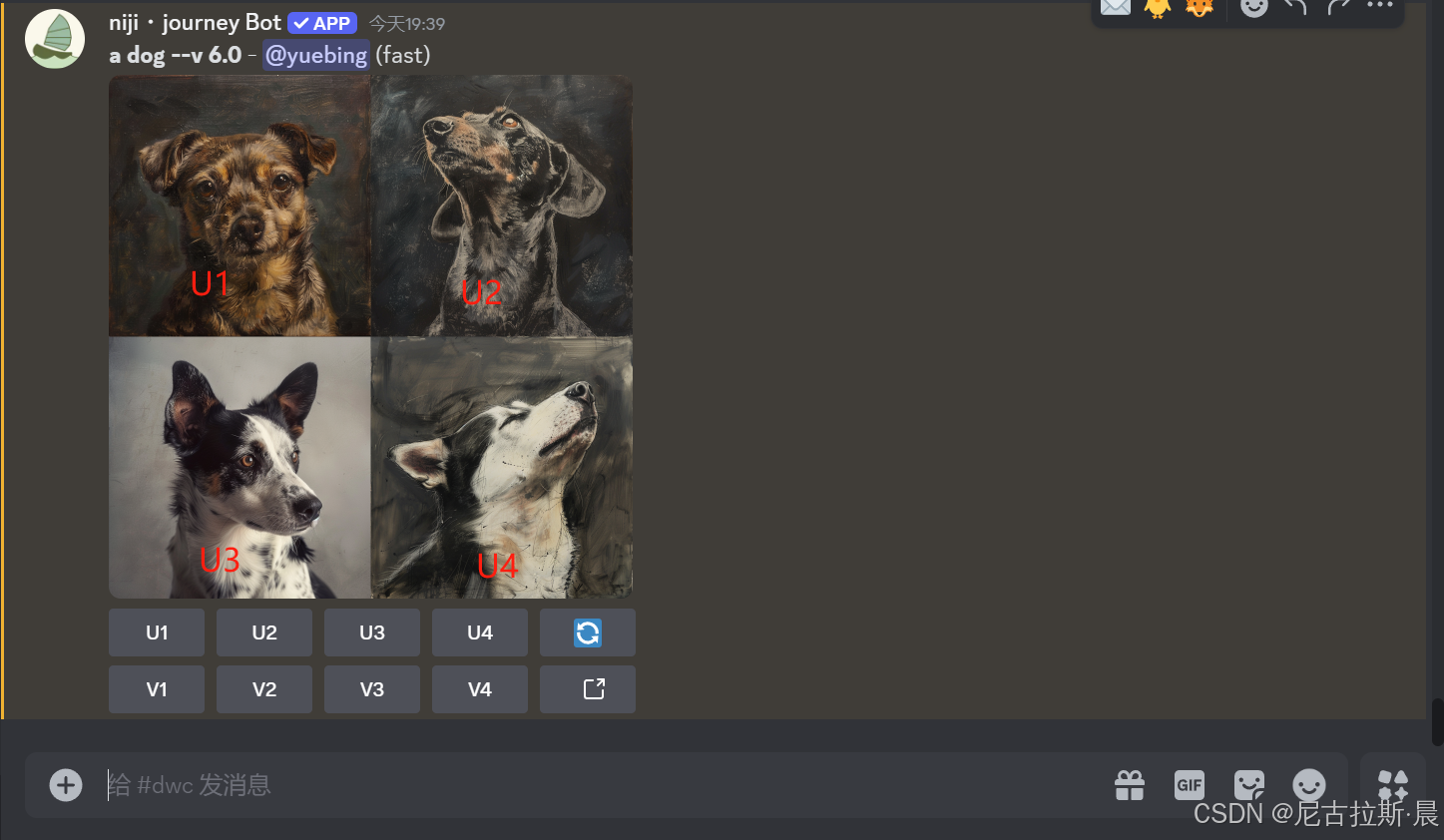
当我们要查看第一张图片,点击U1,则会出现以下界面。
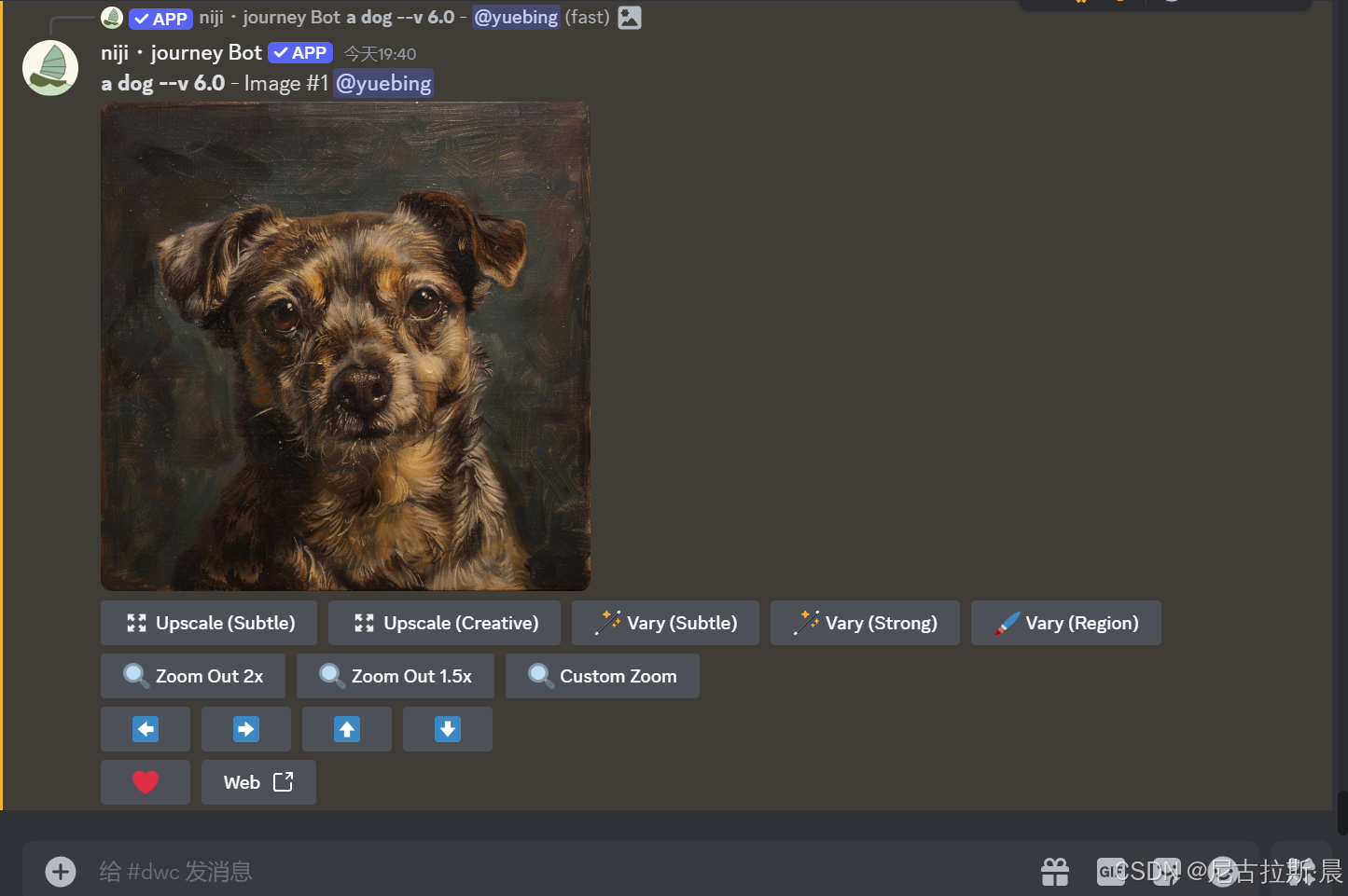
功能区解析:
Upscale(Subtle) 和 Upscale (Creative):1:1 放大
Subtle 细节变精细 & Creative 细节少量修改
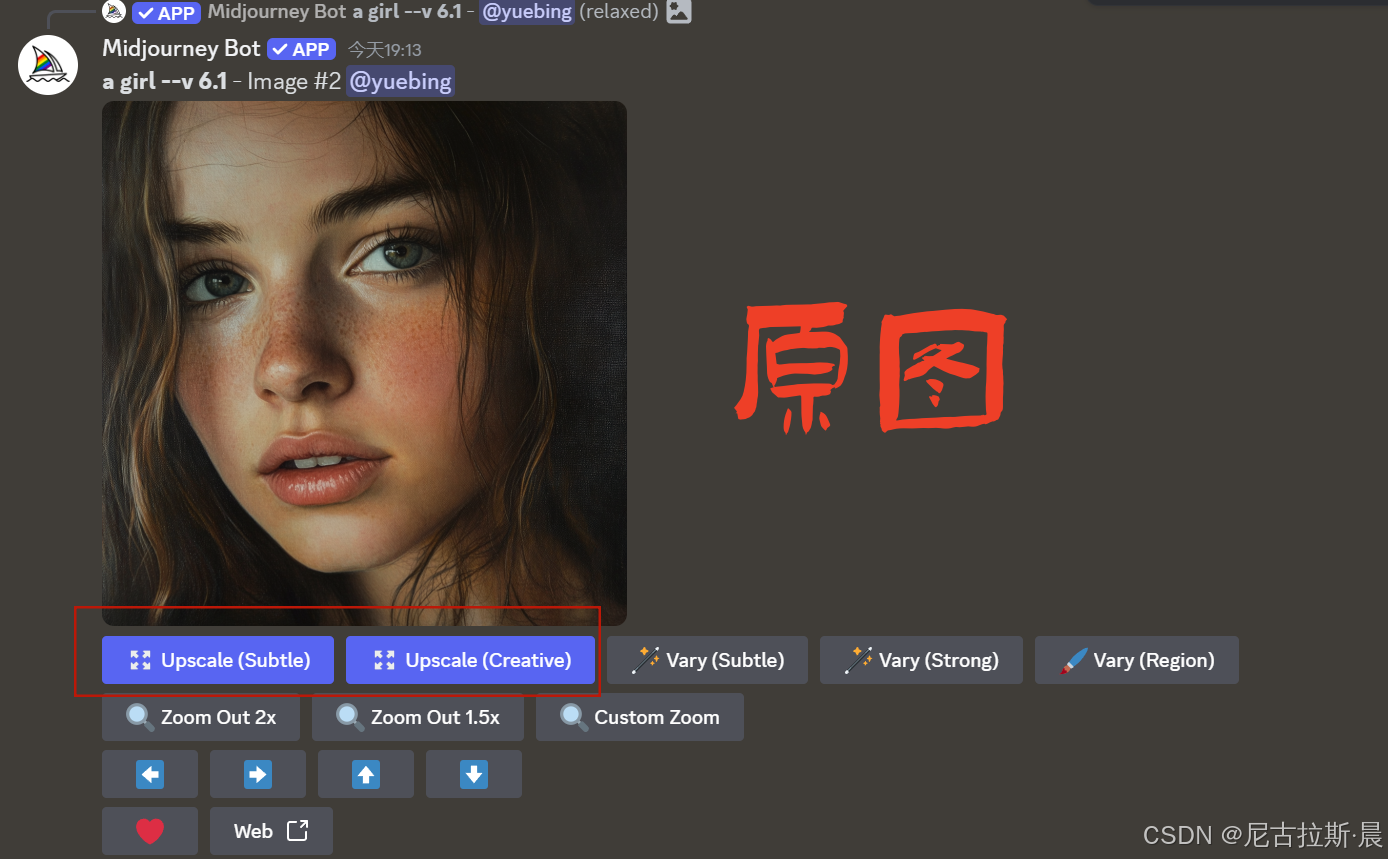
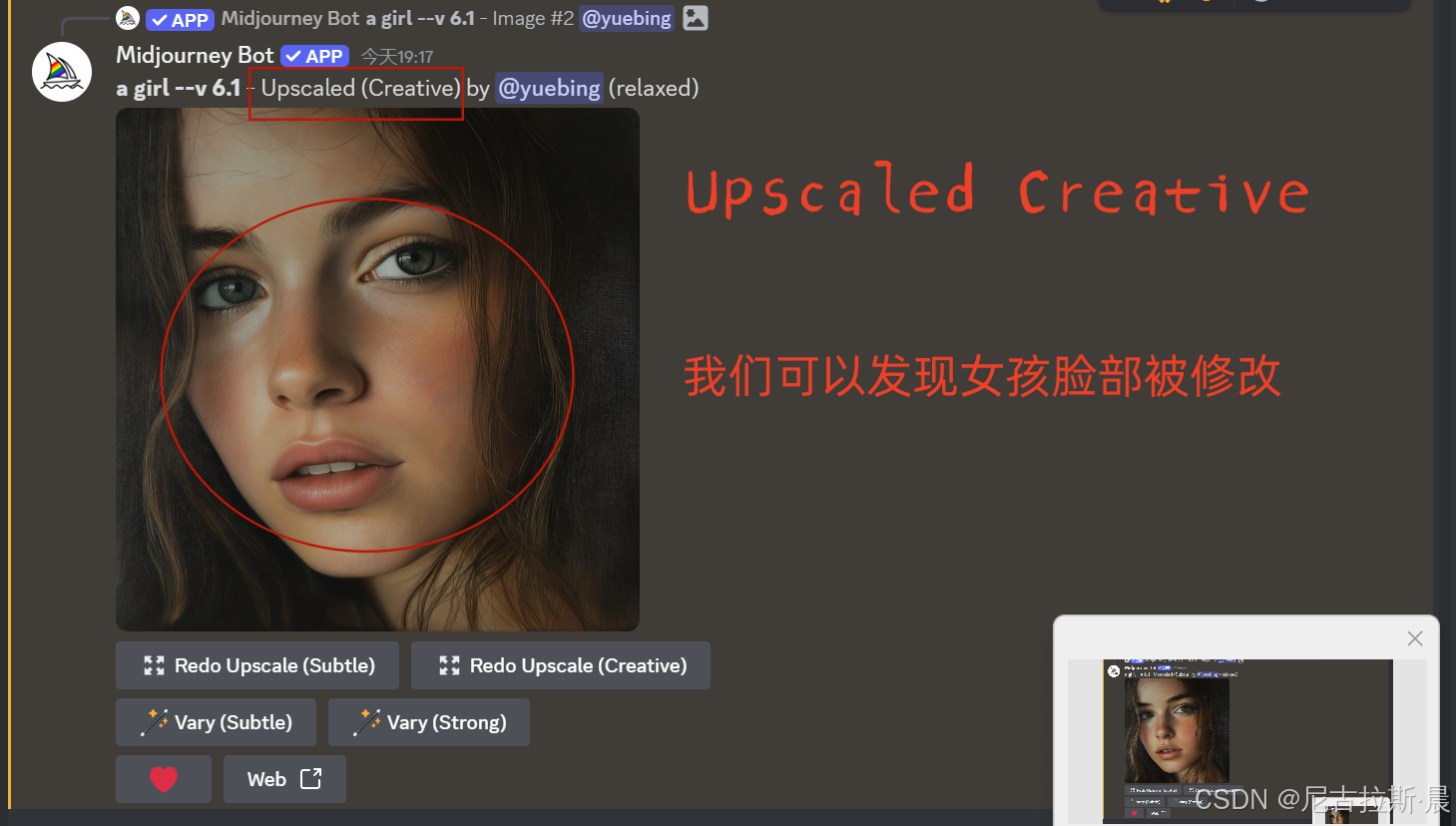
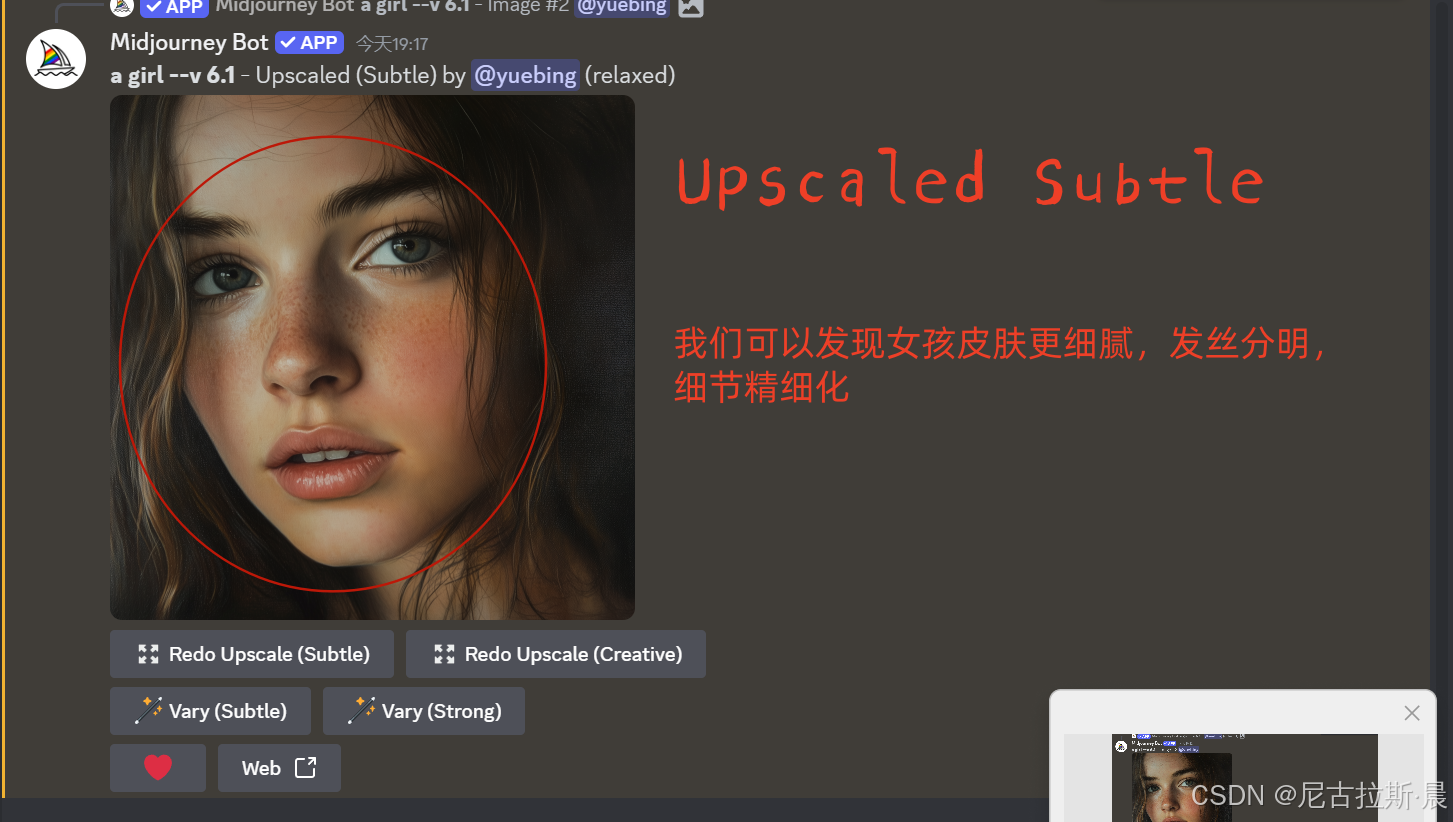
Vary(Subtle)和Vary(Creative): 图片变化,点击按钮,修改提示词,进行变化。
Subtle: 调整较为细微,如微调颜色、光影,或对图像细节进行优化,使图像更精致,整体风格和构图基本不变.
Creative:会较大幅度地改变图像元素、构图、颜色等,能为图像添加或移除元素,创造出与原图不同风格或效果的新图像.
效果图如下:
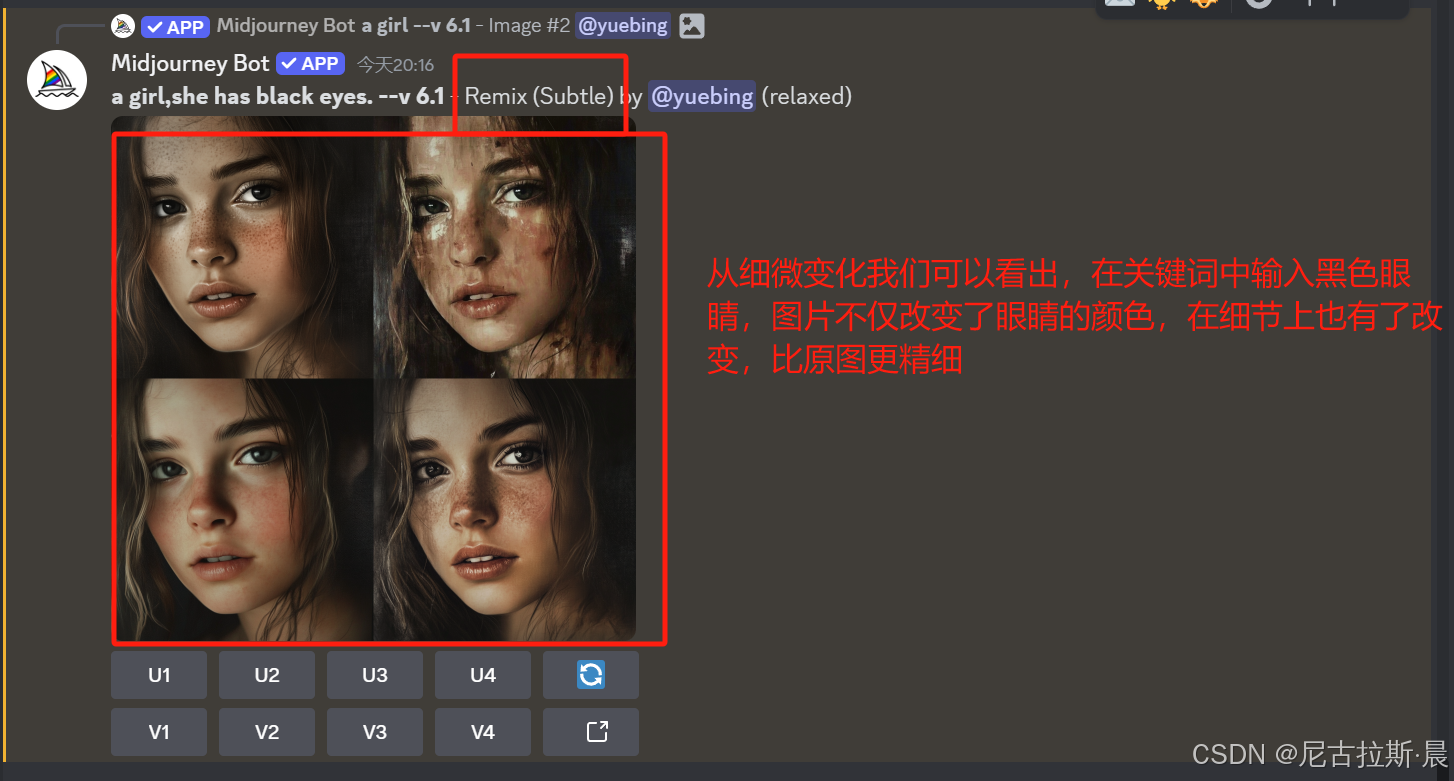
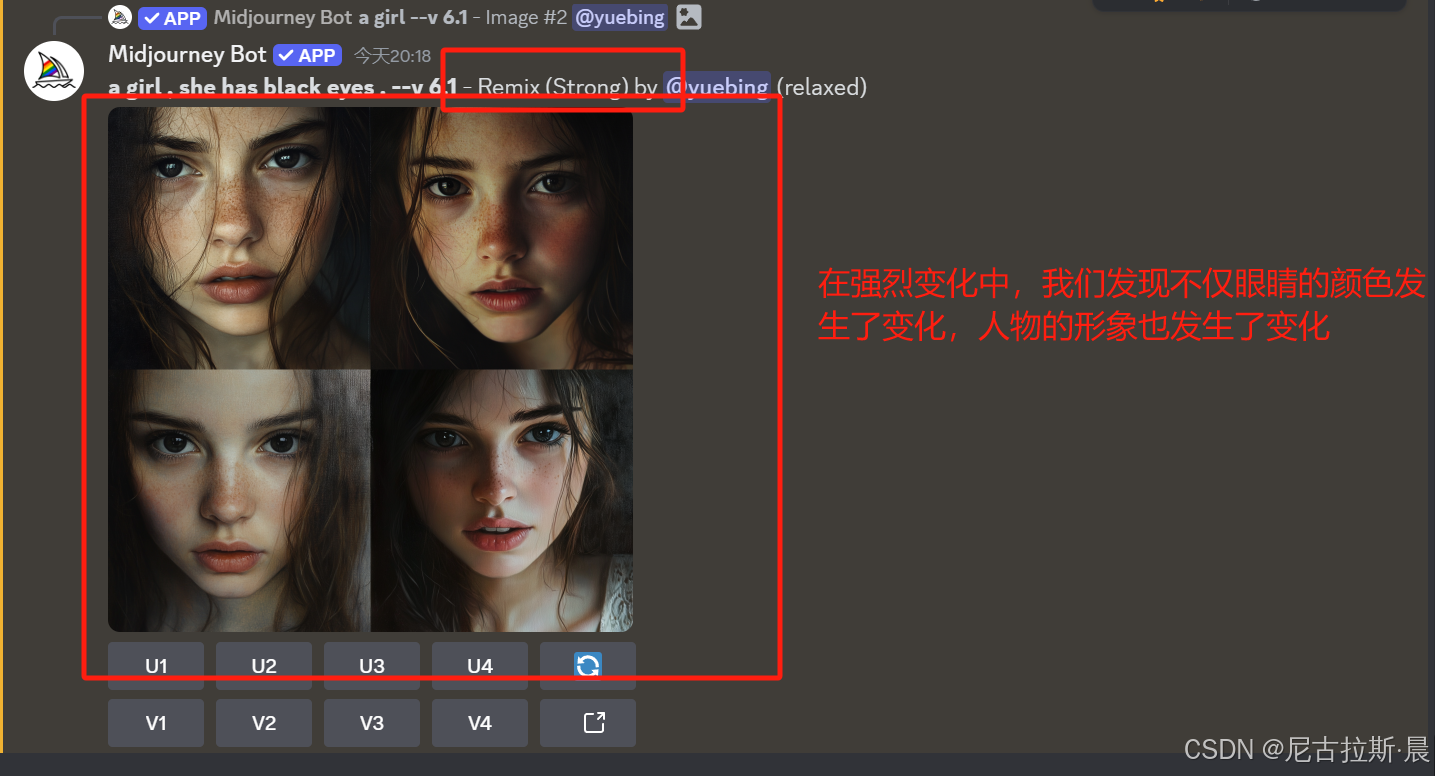
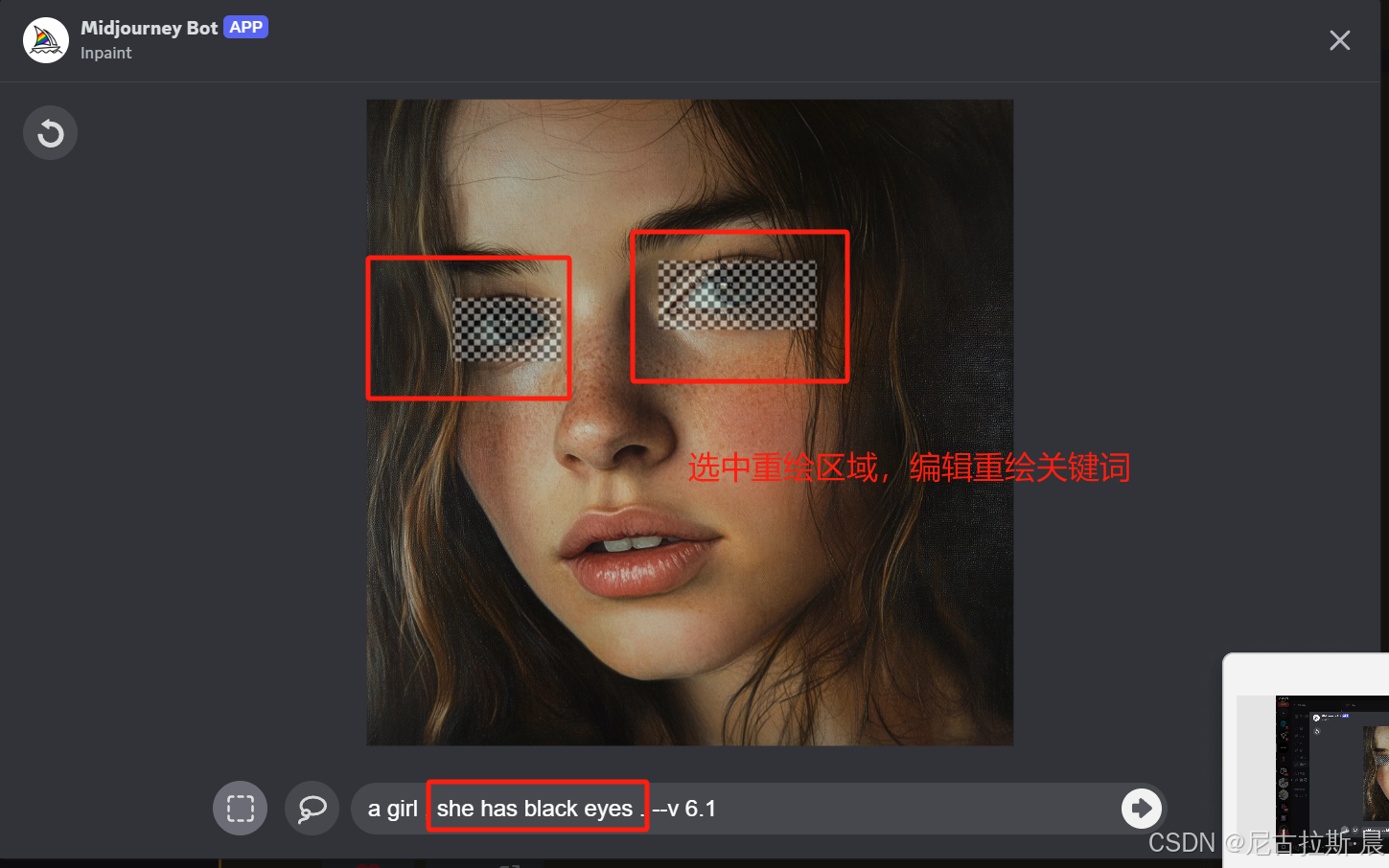
Vary (region):局部重绘,选中需要修改的位置,改变关键词,从而在不改变其他部分的前提下对所选中区域局部重绘。
效果图如下:
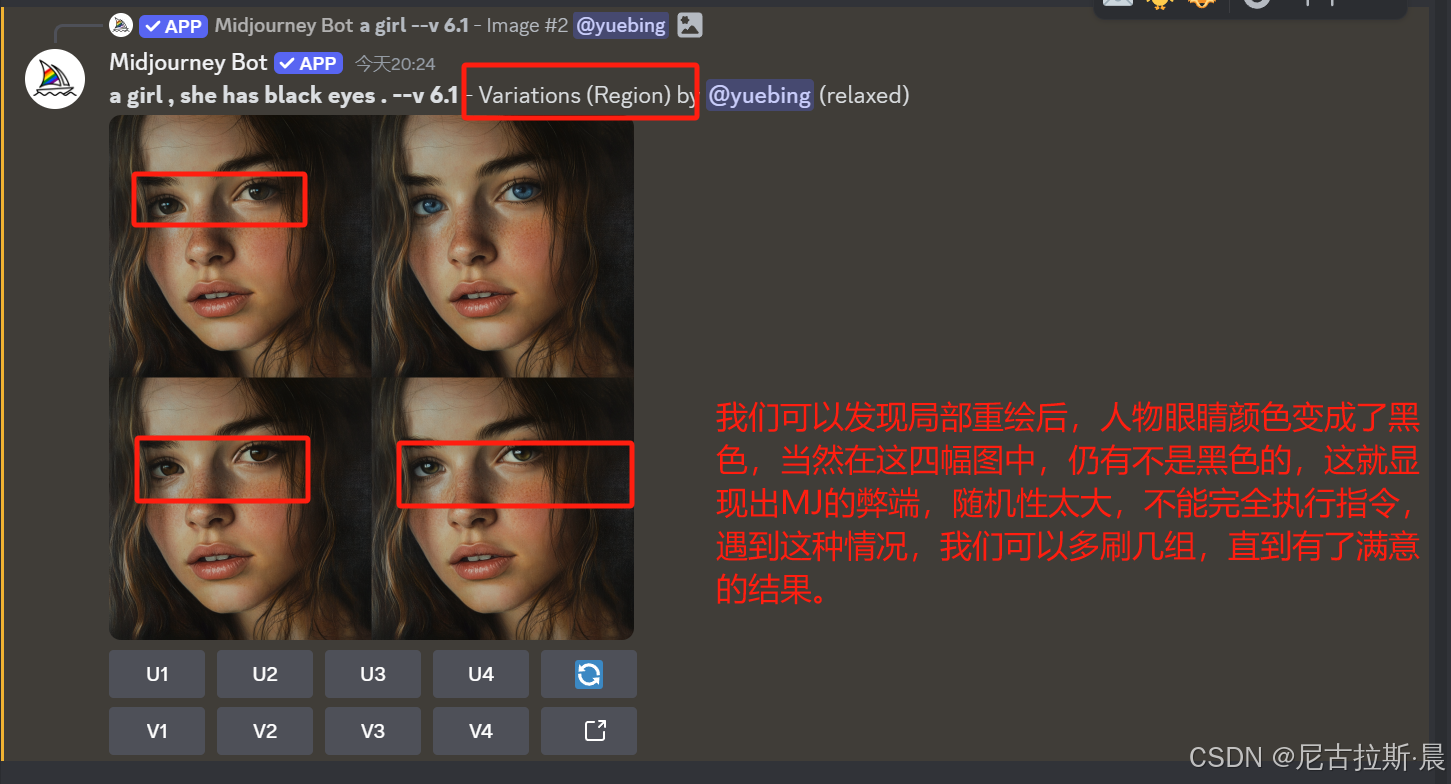
辨析:Vary(Subtle)&Vary(Creative)和Vary (region)的不同
作用范围
- Vary Subtle和Vary Creative:是对整个图像进行变化,在原图基础上生成一张新图,不过变化程度不同,Vary Subtle变化微弱,Vary Creative变化强烈.
- Vary Region:针对图像的特定区域进行修改,仅重绘选定区域,其余部分保持不变,能实现局部的精细调整.
变化程度
- Vary Subtle:调整较为细微,如微调颜色、光影,或对图像细节进行优化,使图像更精致,整体风格和构图基本不变.
- Vary Creative:会较大幅度地改变图像元素、构图、颜色等,能为图像添加或移除元素,创造出与原图不同风格或效果的新图像.
- Vary Region:变化程度取决于输入的修改指令和选定区域大小,可从细微调整到较大改变,如将人物手中物品替换是小变化,改变人物姿态表情等则是较大变化.
适用场景
- Vary Subtle:适用于对原图像整体满意,只需小幅度优化细节,或希望在保持原有风格基础上增强细腻感的情况.
- Vary Creative:适用于希望对原图像进行大幅度修改或重新构思,探索不同创作方向,以获得全新视觉效果的情况.
- Vary Region:适用于对图像整体满意但局部需修改,如人物服装、配饰、背景元素等,可在不影响其他部分的前提下进行局部创意调整.
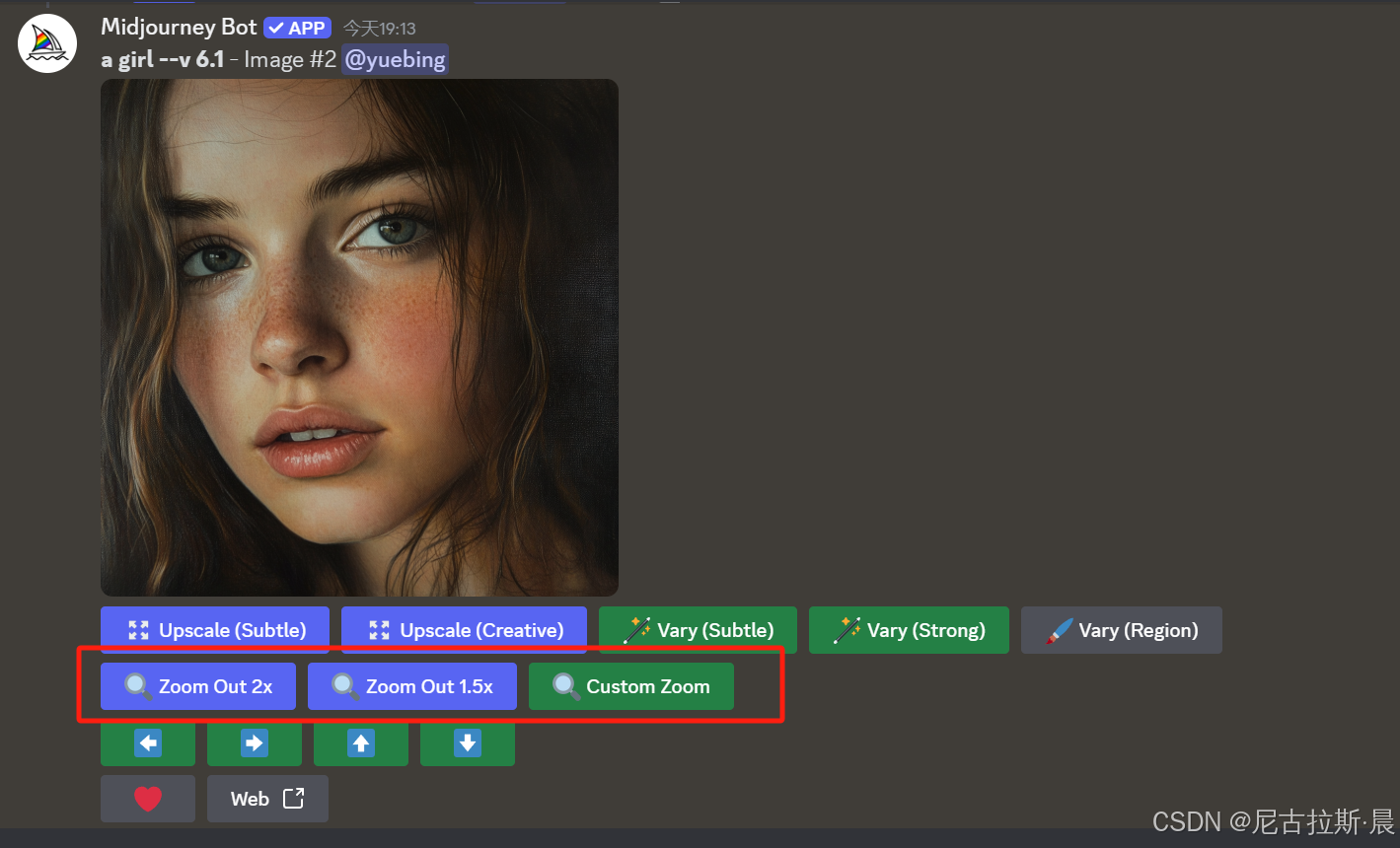
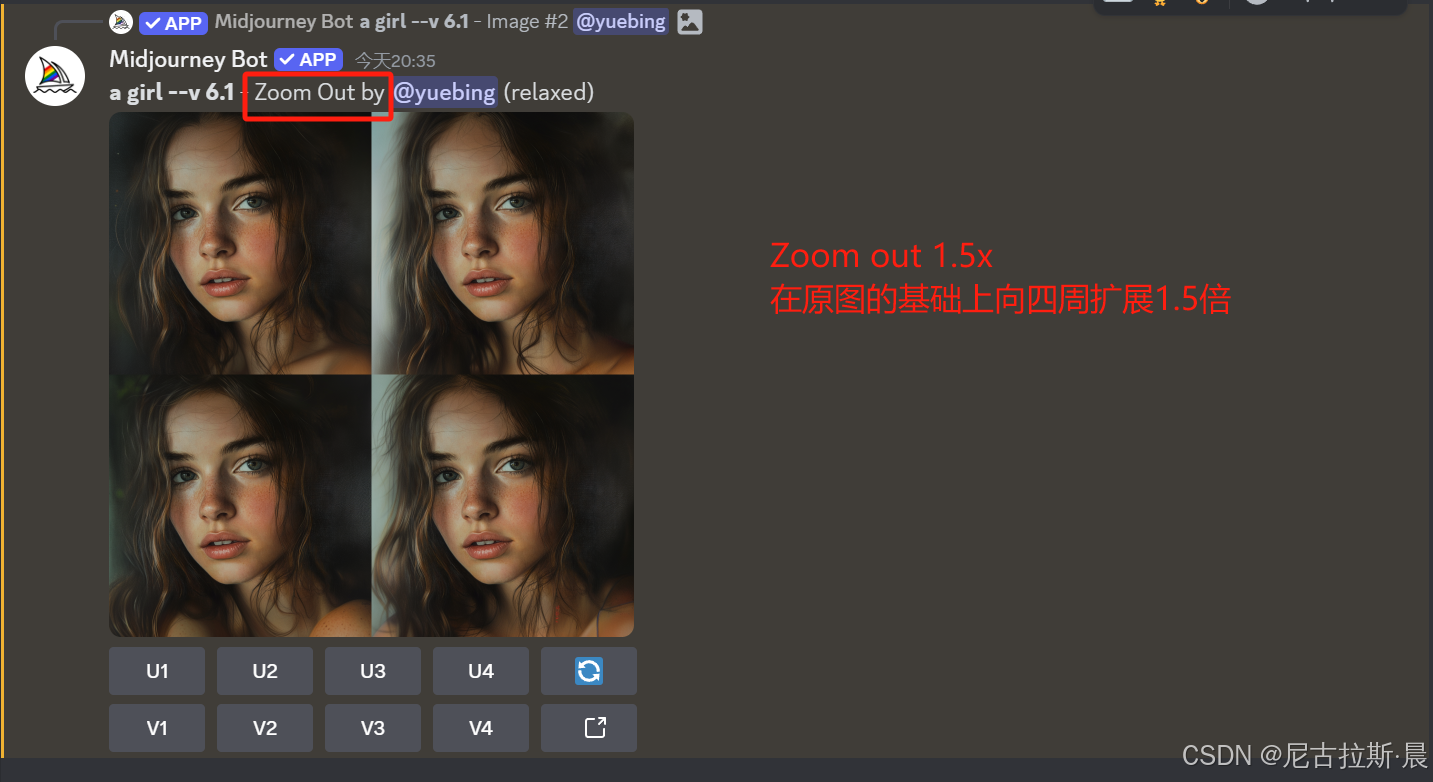
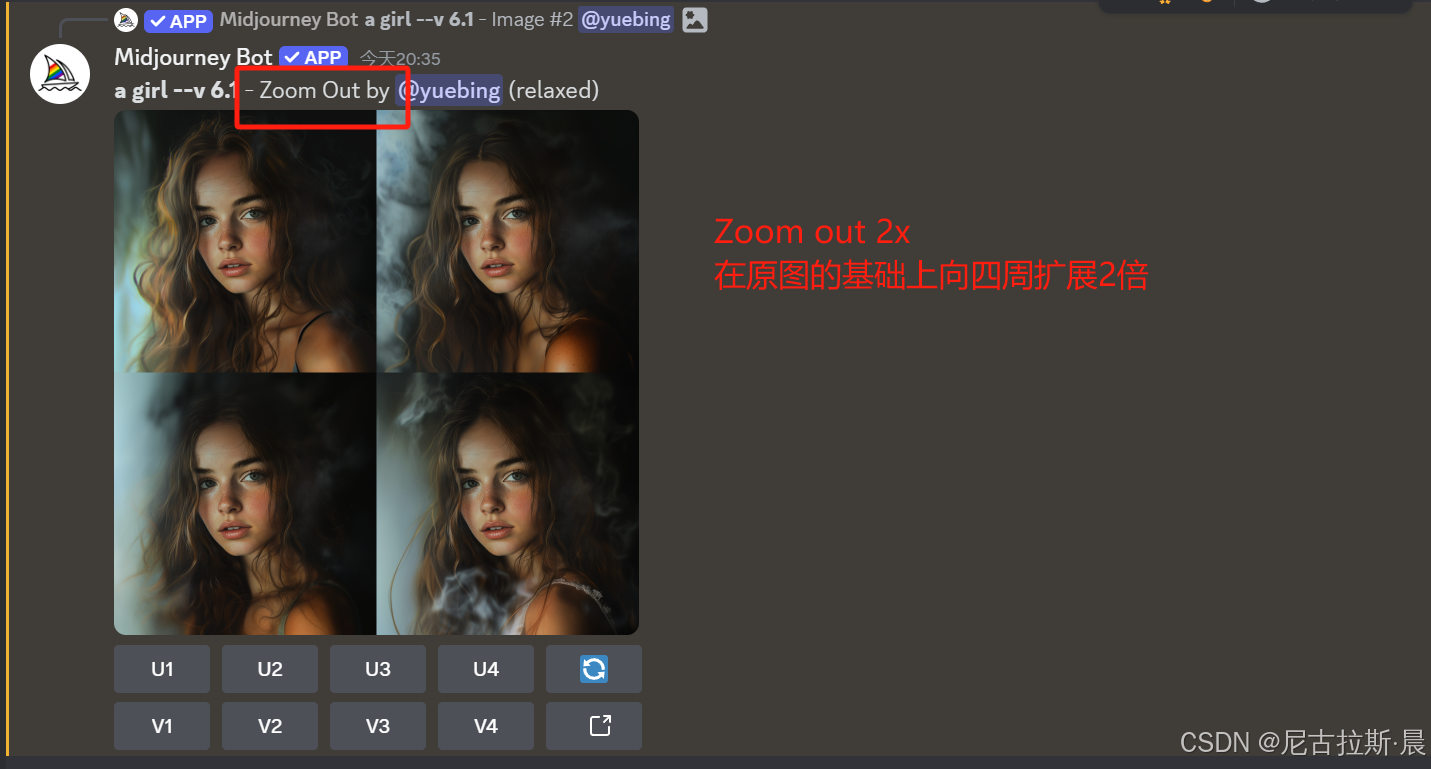
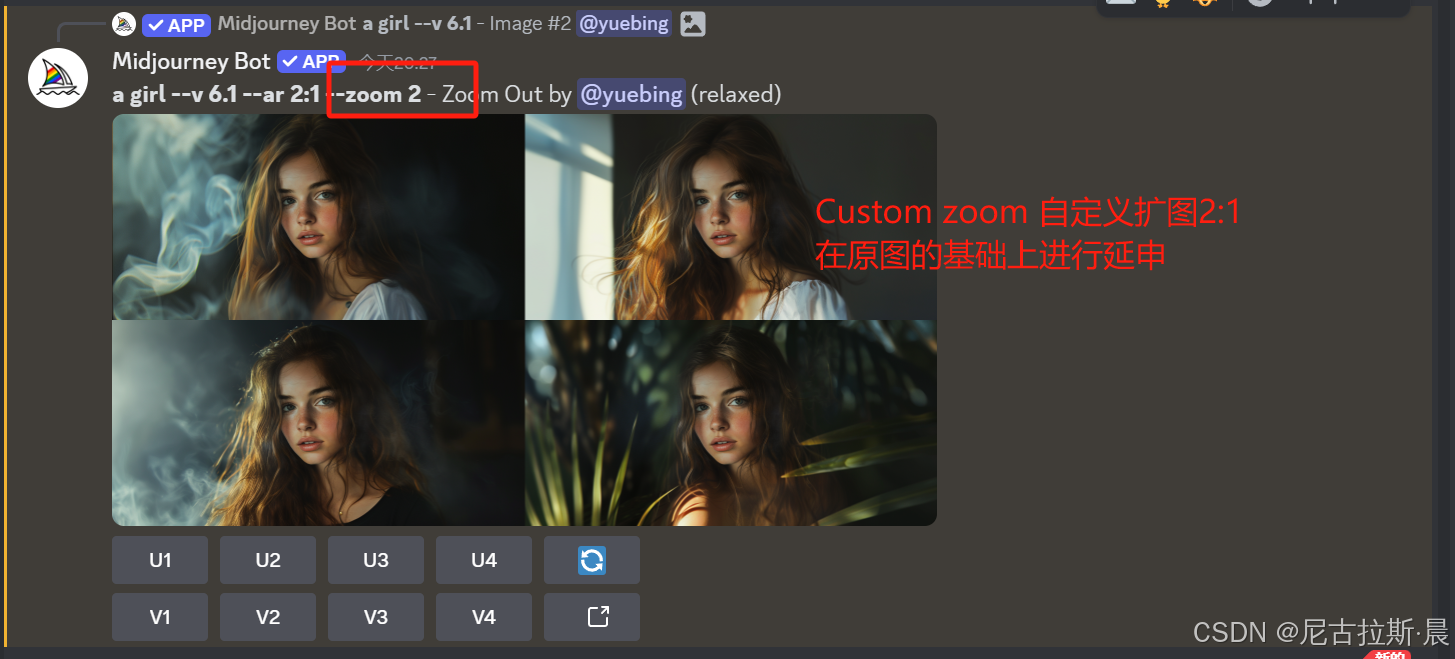
扩图:Zoom out 1.5x、2.0x 与 Custom zoom
Zoom out 1.5x、2.0x :固定倍数扩图,不改变原图
Custom zoom:自定义扩图,通过改变关键词--ar后的图片比例,修改扩图倍数
箭头延展画布:选定画布延展方向,添加关键词,丰富画布内容,对原主体形象不改变。
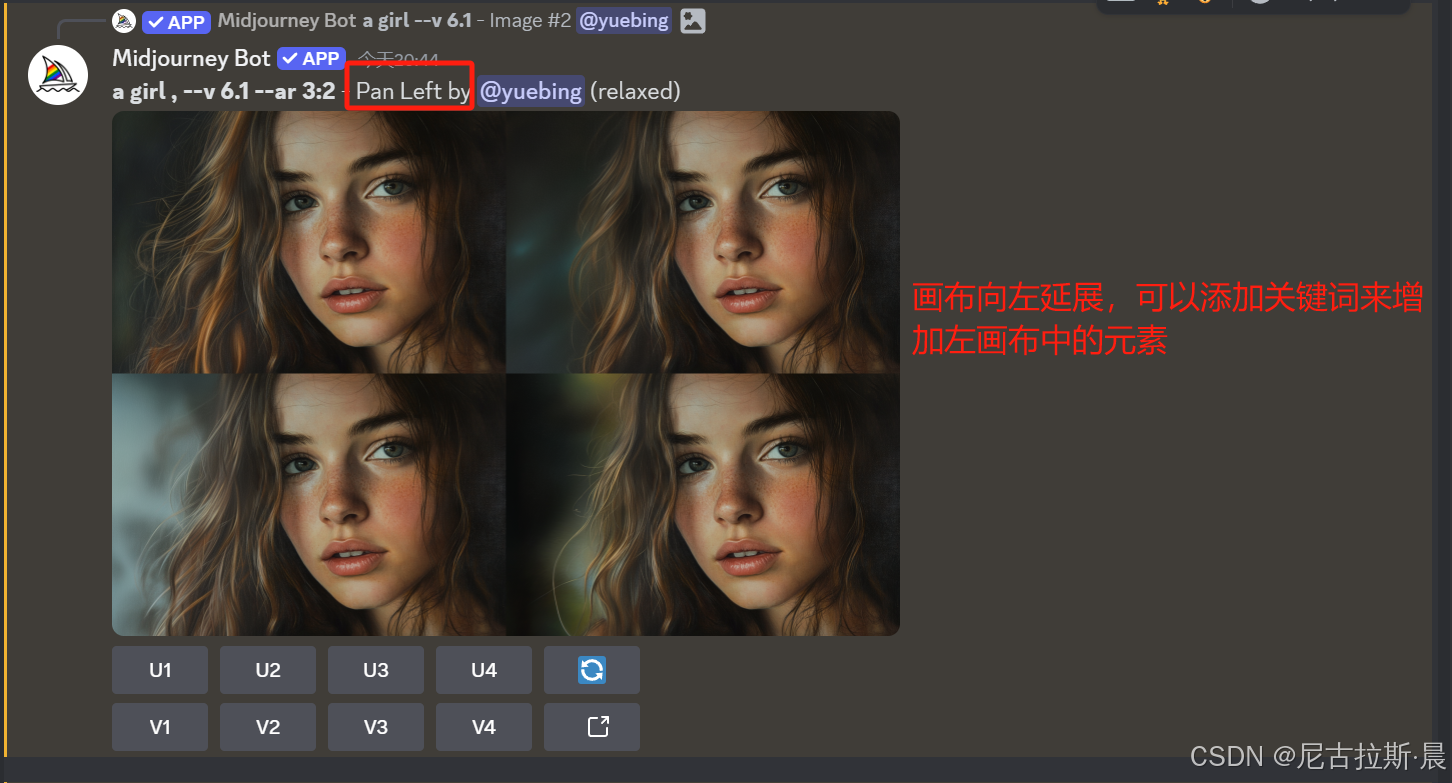
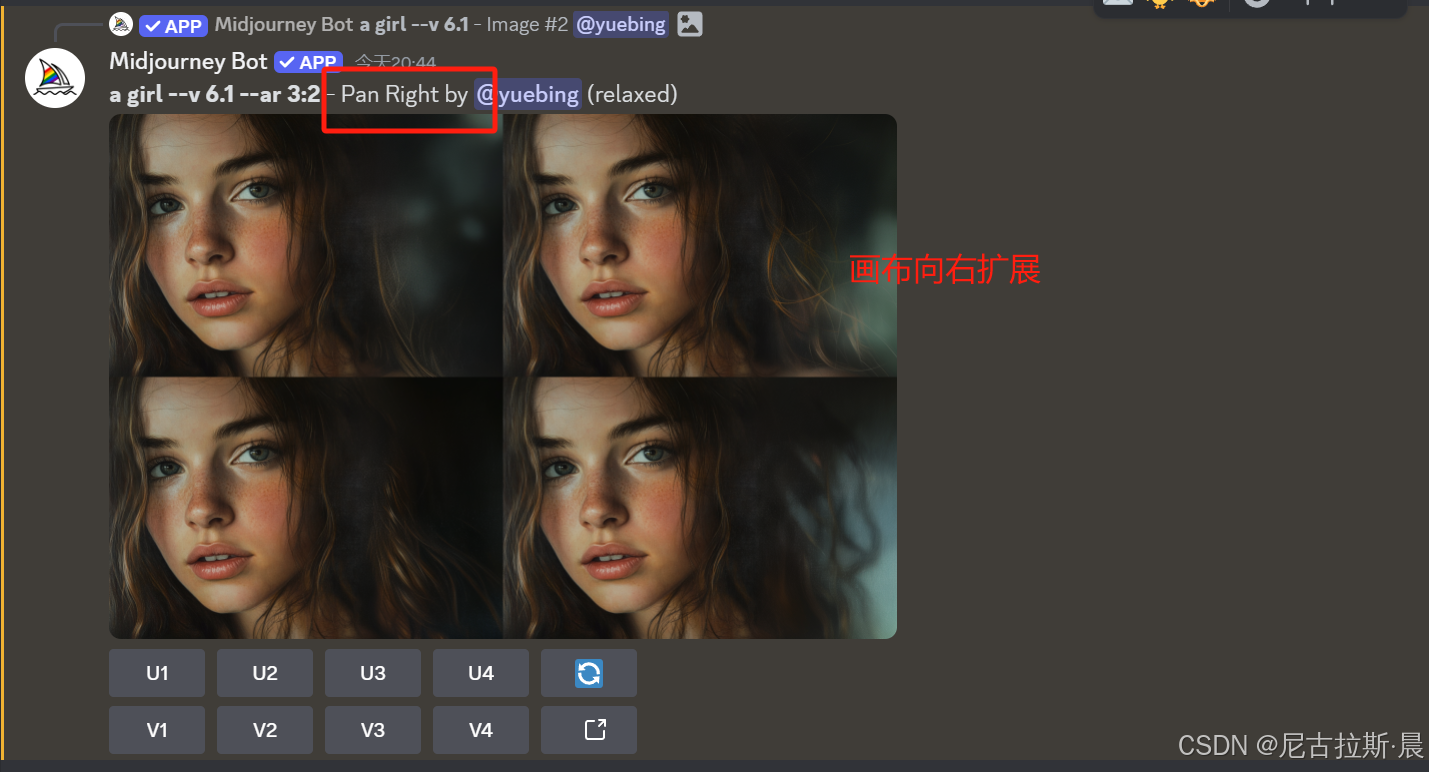
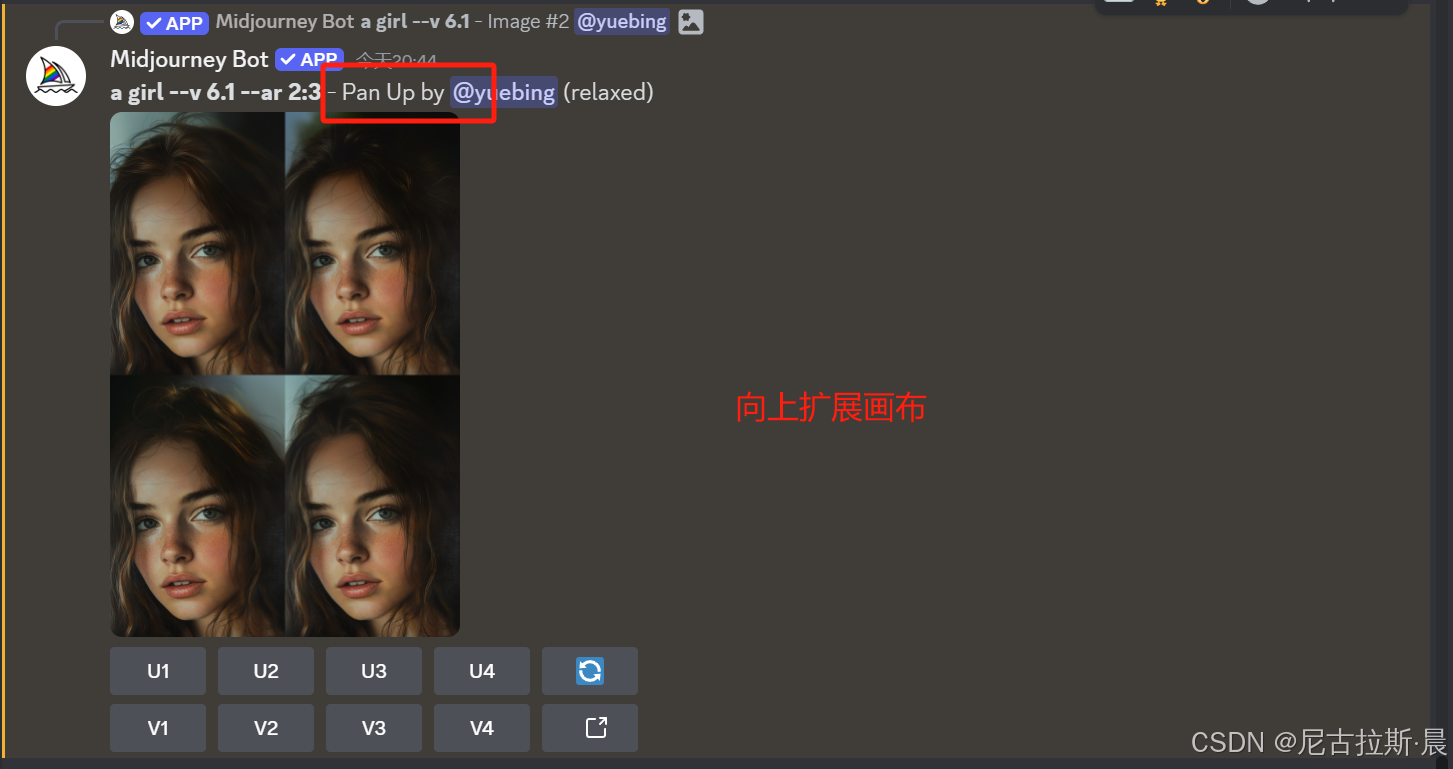
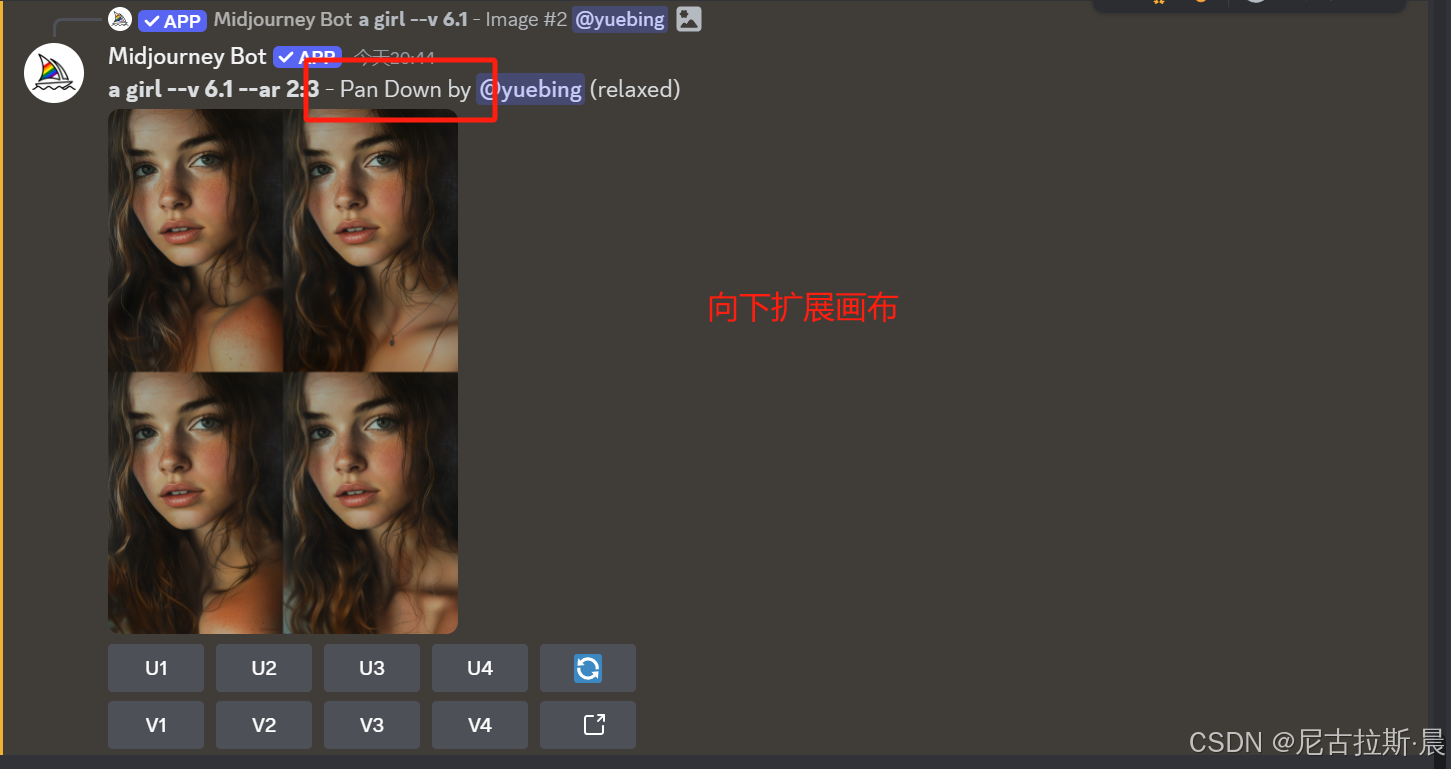
辨析Zoom Out扩图和箭头扩图的不同:
扩展方向
- Zoom Out:是对图像的整体边界进行向外扩展,可同时向图像的四周填充细节,使画面内容更丰富,展现更广阔场景.
- 箭头扩图:只能沿上、下、左、右四个特定方向对图像进行扩展,每次扩展区域的大小是原图大小的1/3,以原图为中心点往箭头所指方向延伸.
扩展比例
- Zoom Out:提供了1.5倍、2倍以及1.0到2.0之间的自定义缩放选择,用户能更灵活地控制图像的扩展程度.
- 箭头扩图:无法直接控制每次扩展的具体比例,扩展的距离相对固定,为原图大小的1/3,但可通过多次点击箭头来持续扩展.
适用场景
- Zoom Out:适合用于需要对图像整体进行放大以展现更多细节或扩展场景的情况,如将一幅风景图扩展成更广阔的画面,或把人物半身像扩成全身像等,常用于生成壁纸等需要更大尺寸图像的创作.
- 箭头扩图:更适用于需要在某个特定方向上延伸图像内容的情况,比如想查看图像中某个元素在该方向上的延续场景,或是构建具有方向性的连续画面等.
对原图像的依赖程度
- Zoom Out:主要依据原图像的内容和风格,按照一定的算法填充扩展区域的细节,使新生成的部分与原图像在风格和细节上保持较好的连贯性和一致性.
- 箭头扩图:同样依赖原图像,但由于是单方向扩展,若在扩展方向上原图像的内容信息较少,可能需要更明确具体的Prompt来指导新增区域的内容生成,以避免出现画面不协调或内容不连贯的情况.
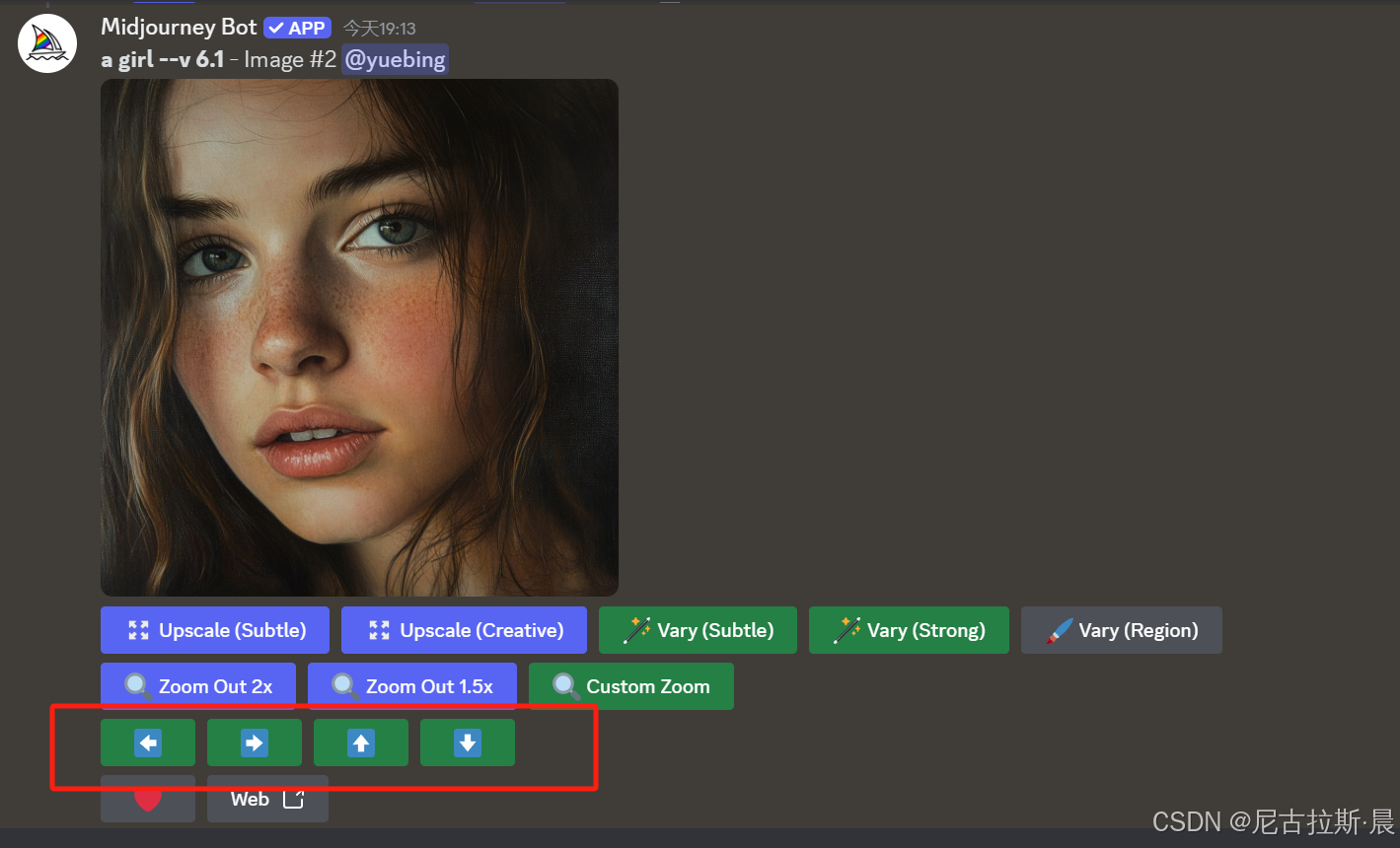
- V1 V2 V3 V4 : 生成图片变体
点击V1、V2、V3、V4按钮,会分别以对应的图片为基础,重新生成一组四张与之相似但又有细节变化的新图片,帮助用户对不满意的图片进行微调、优化和二次创作,以获得更符合需求的图像.
效果图如下:
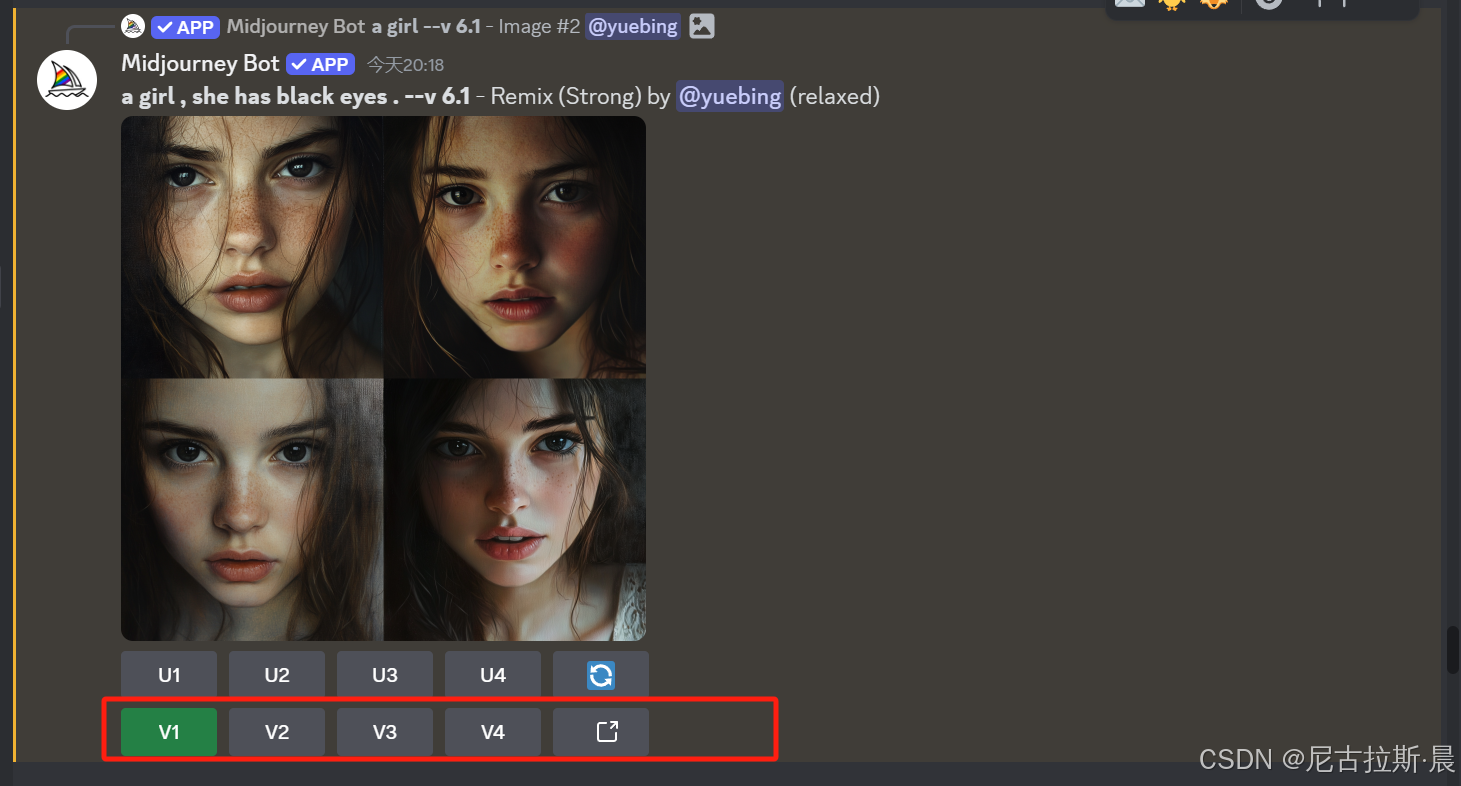
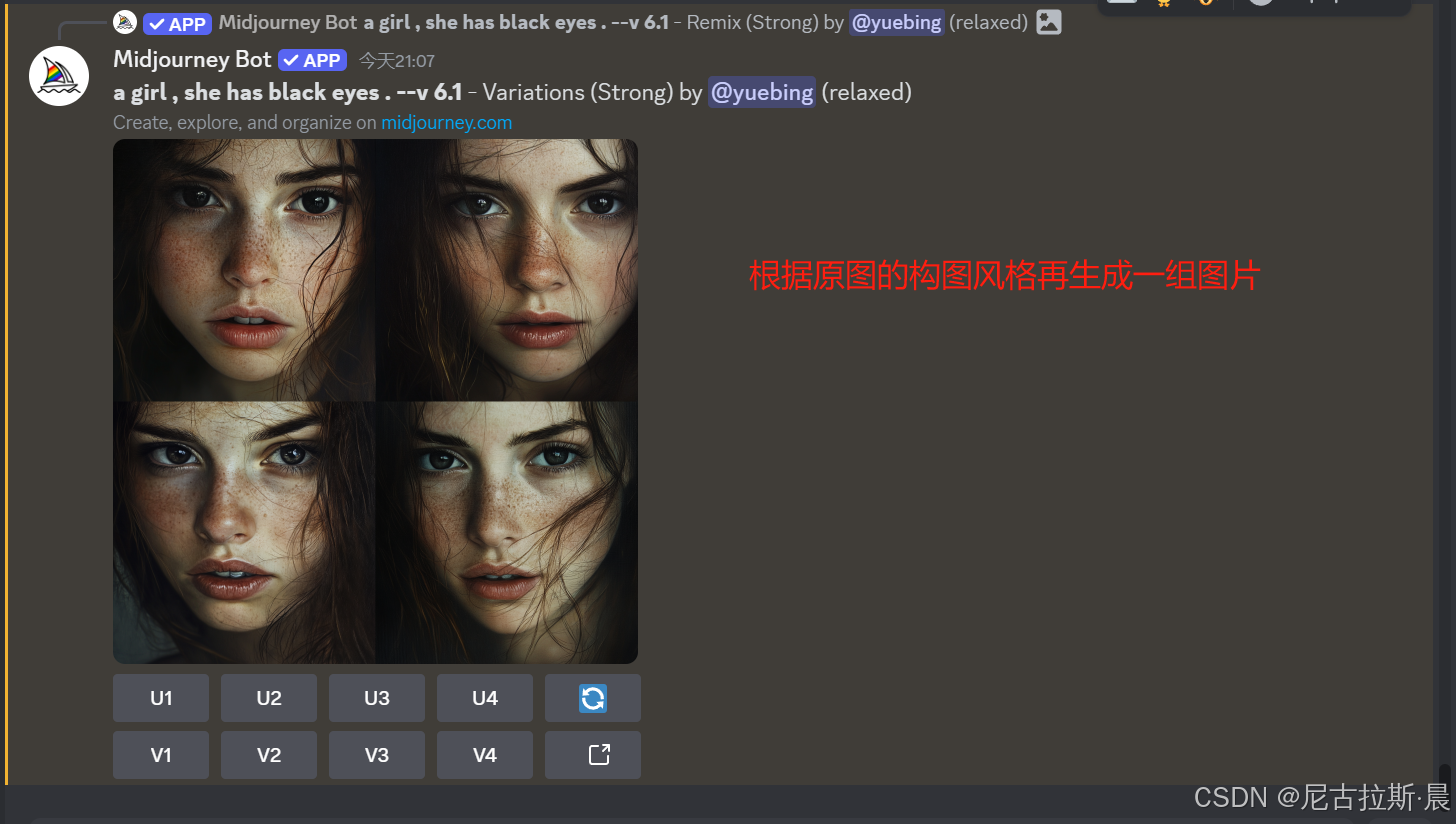
3、命令解析
使用MJ时,我们首先要进入自己的服务器。输入命令时要先输入“/”,任何命令一定要在英文状态下!
/settings 设置:输入“/settings”后,点击回车则会出现以下界面:
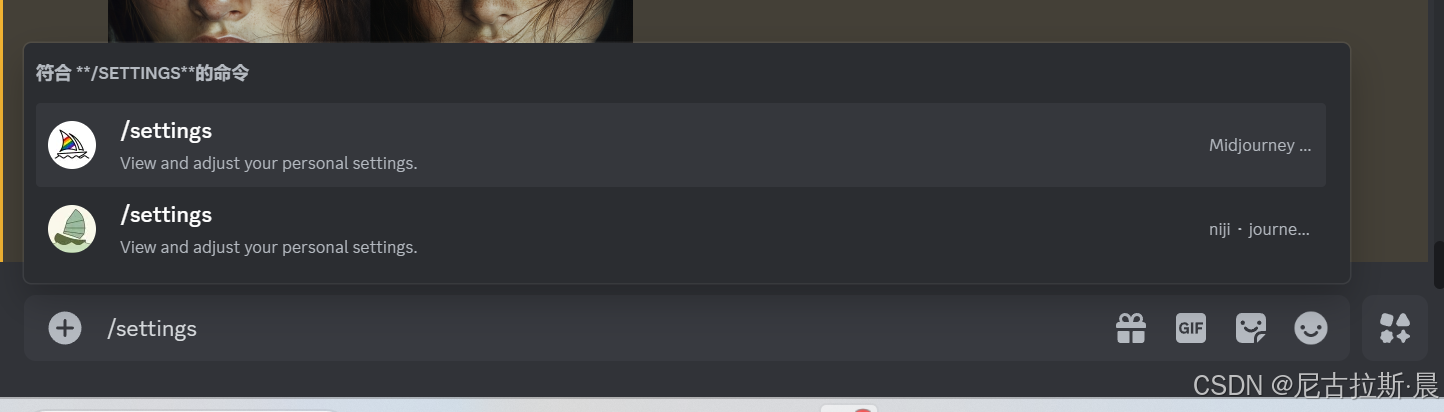
选择你要查看的大模型。
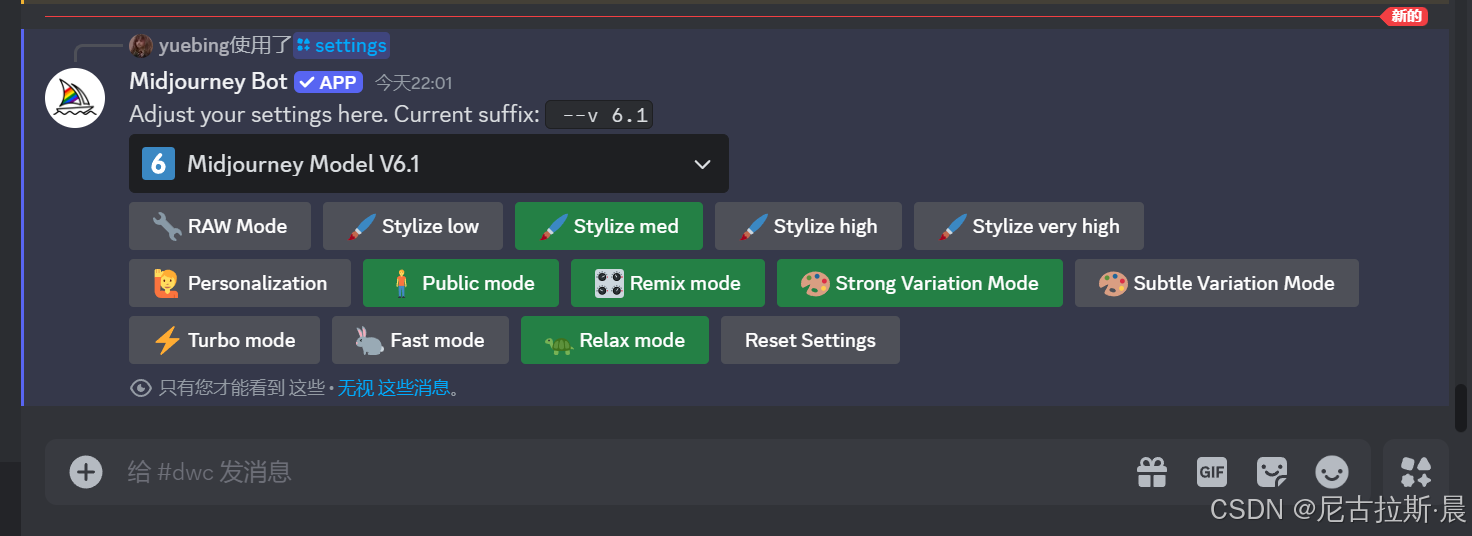
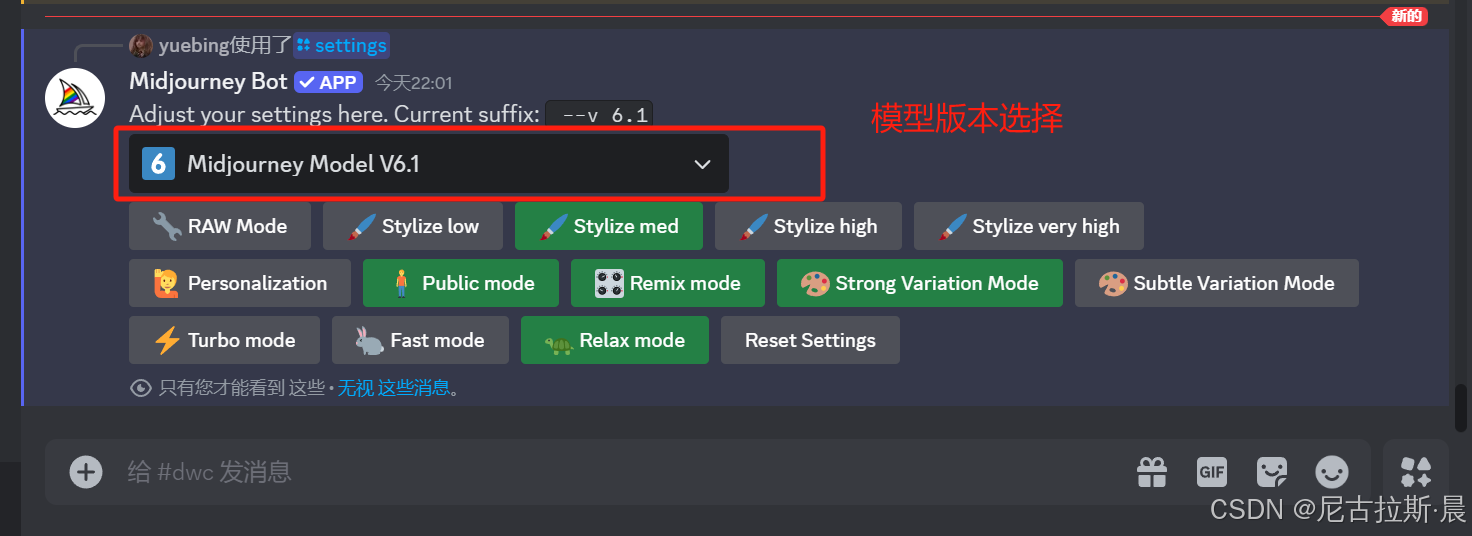
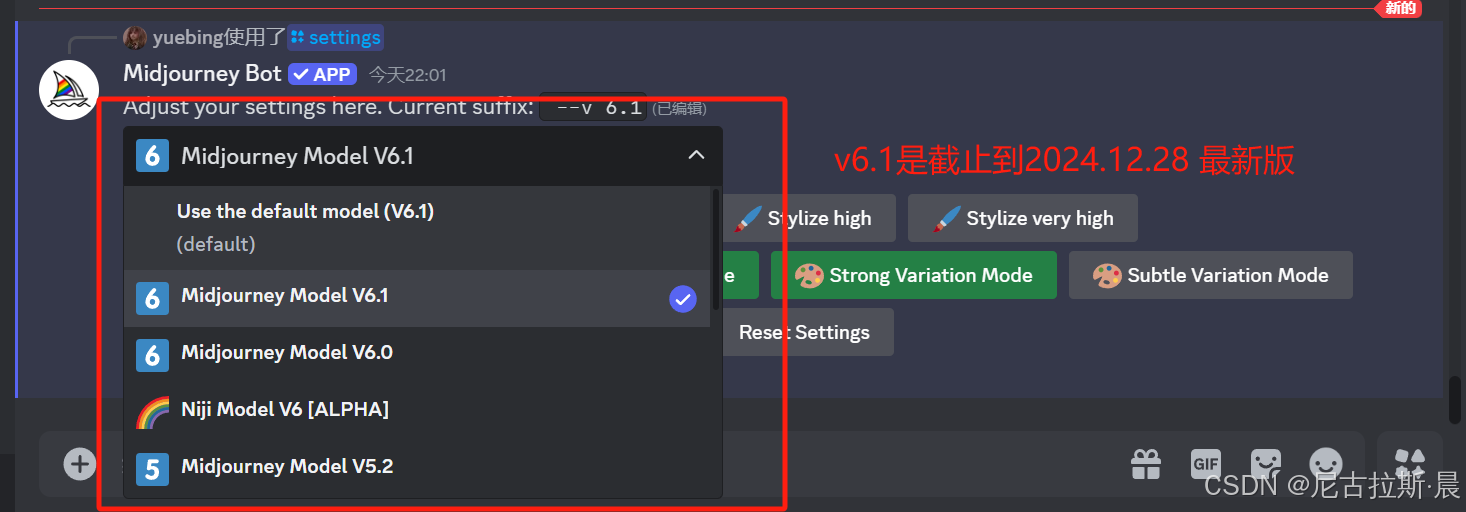
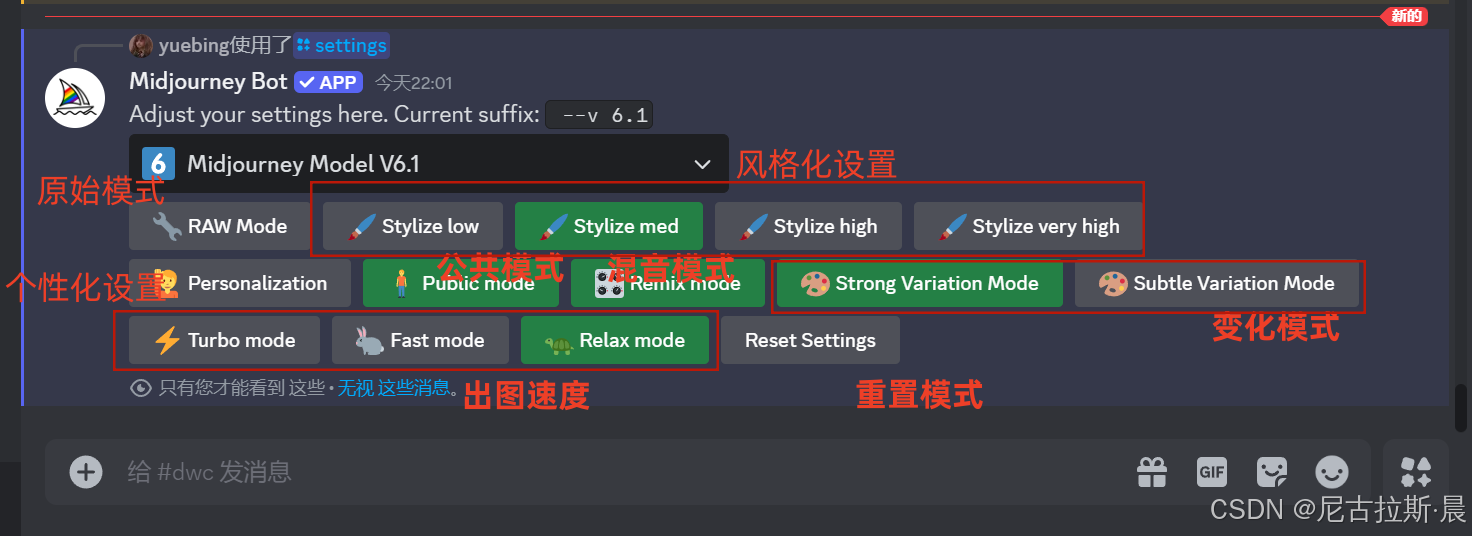
原始模式:raw mode
-与其他具有较高风格化设置的模式相比,raw mode生成的图像不会过度修饰或添加额外的艺术化处理,更注重呈现提示词所表达的真实场景、物体或概念.
- 临时启用可在输入提示词后添加“--style raw”参数;若想永久启用,则需进入设置界面,点击raw mode按钮来激活.
-生成的图像具有高度真实感和自然度,类似真实拍摄或写实绘画的效果时,raw mode是较好的选择,如生成自然风景、人物肖像等主题的图像.
风格化设置:Stylize low/med/high/very high
- stylize low:生成的图像与提示词关联性强,较为贴近原始描述,但艺术性相对较弱,如--s 50.
- stylize med:默认设置,能在遵循提示词的基础上提供适当的图像变化和艺术感,如--s 100.
- stylize high:图像变化较大,艺术性增强,与提示词的关联性有所降低,如--s 250.
- stylize very high:图像变化非常大,更具艺术性和创意性,但可能与提示词的联系不紧密,如--s 750.
个性化图像:Personalization
生成一定数量的图片后,Midjourney会记录用户喜欢的图像类型,并在后续生成时参考这些喜好.
公共模式与隐身模式:Public mode
- 公共模式:默认开启,用户生成的图片会出现在“MJ画廊”中,其他用户可见.
- 隐身模式:专业版或企业版会员用户可关闭公共模式切换至此,开启后生成的图片不会出现在公共画廊中.
混音模式:Remix mode
对生成的图片进行微调时,会弹出“修改提示词“的窗口,可通过修改提示词来控制图片的效果,达到改变图片设置、光线、主体进化或实现复杂构图等目的.
变化模式:Strong Variation / Subtle Variation Mode
- Strong Variation Mode:生成的4张图片差异性大,能为用户提供更多不同风格和细节的图像选择.
- Subtle Variation Mode:生成的4张图片差异性小,更适合在已有喜欢的图像基础上进行微调或获取相似但略有不同的变体.
出图速度:mode
- Turbo mode:涡轮模式,出图速度是放松模式的4倍,一般专业会员才能使用.
- Fast mode:快速模式,出图速度是放松模式的2倍,基础会员可以使用,但有时间限制.
- Relax mode:放松模式,可以无限出图,但所需时间较长.
重置设置:reset settings
可将所有修改后的设置恢复成默认设置,即使用最新模型(v6)和中等风格化设置,而公共/隐身模式、混音、变化和生成速度等偏好不受影响.
/imagine 创作:通过输入关键词,创作图像
输入“/” 选择风格机器人模型,prompt后加关键词
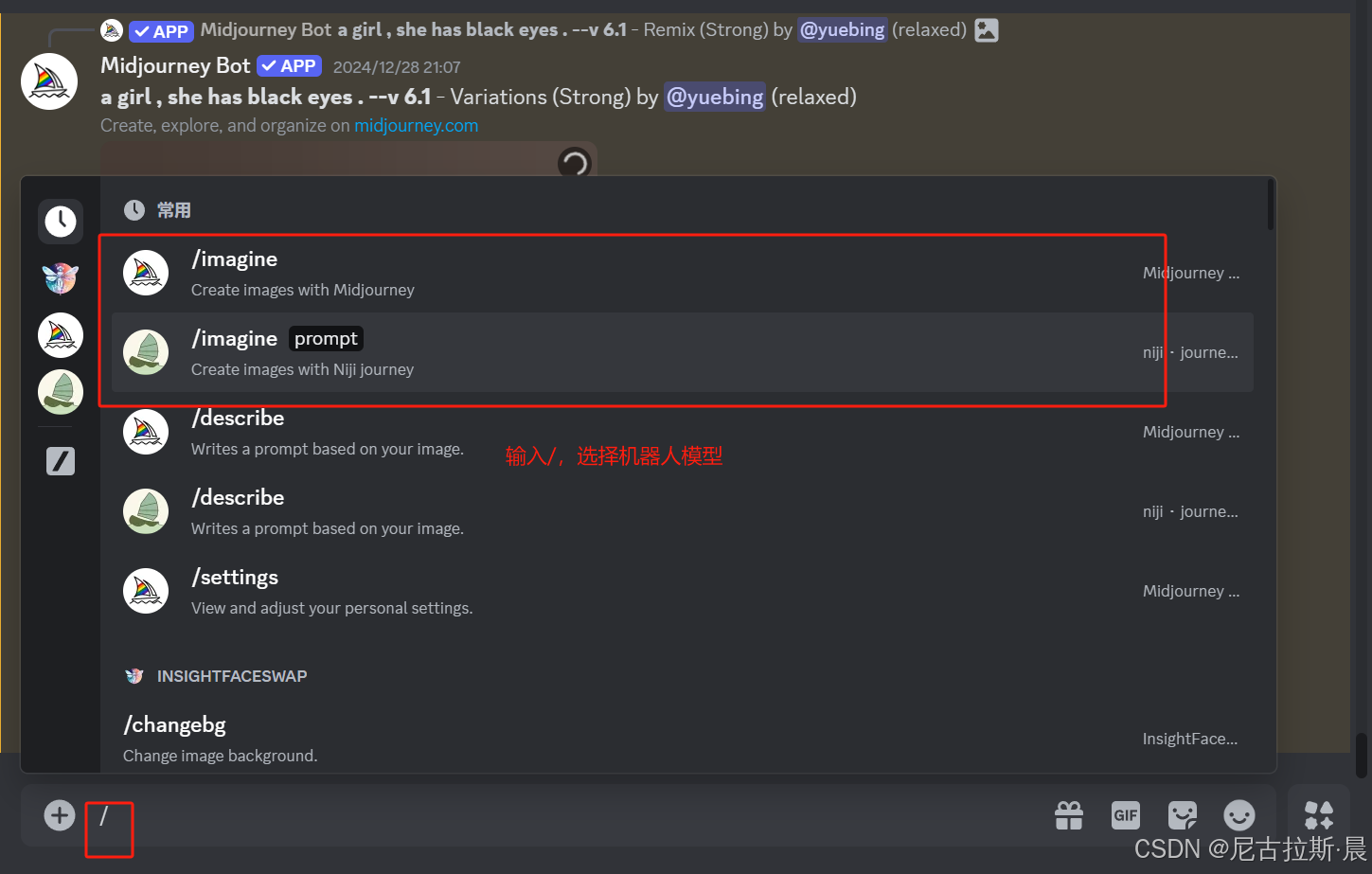

关键词写法:主题+场景+风格+画质+设置

/info 查询:可查询账号基本信息
输入/info,选择模型,即可查看基本信息


/help 帮助手册:查看使用教程
输入/help,选择机器人,即可查看用户手册,了解使用指南。

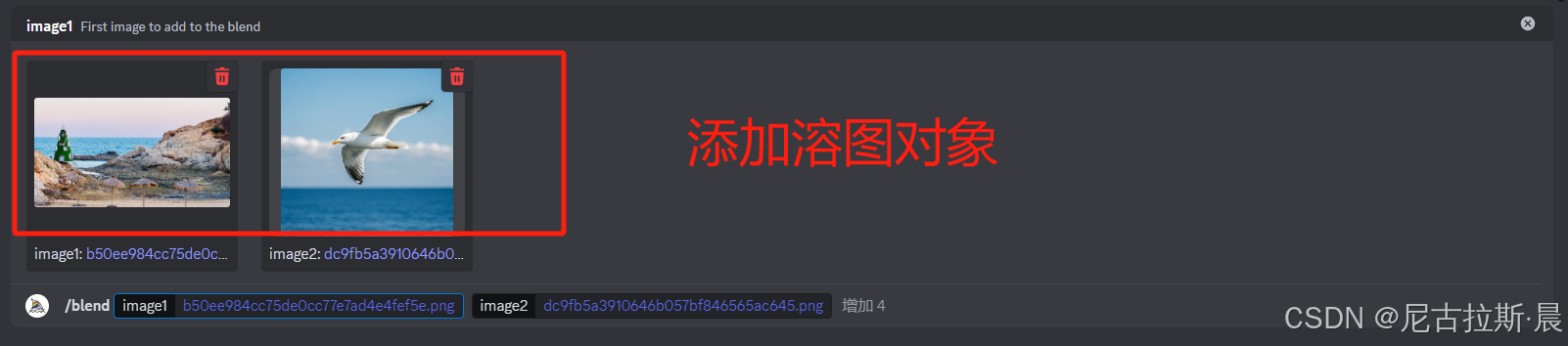
/blend 溶图: 融合多张图片风格和元素,生成一组新图
输入/blend指令,选择机器人模型,添加溶图图片

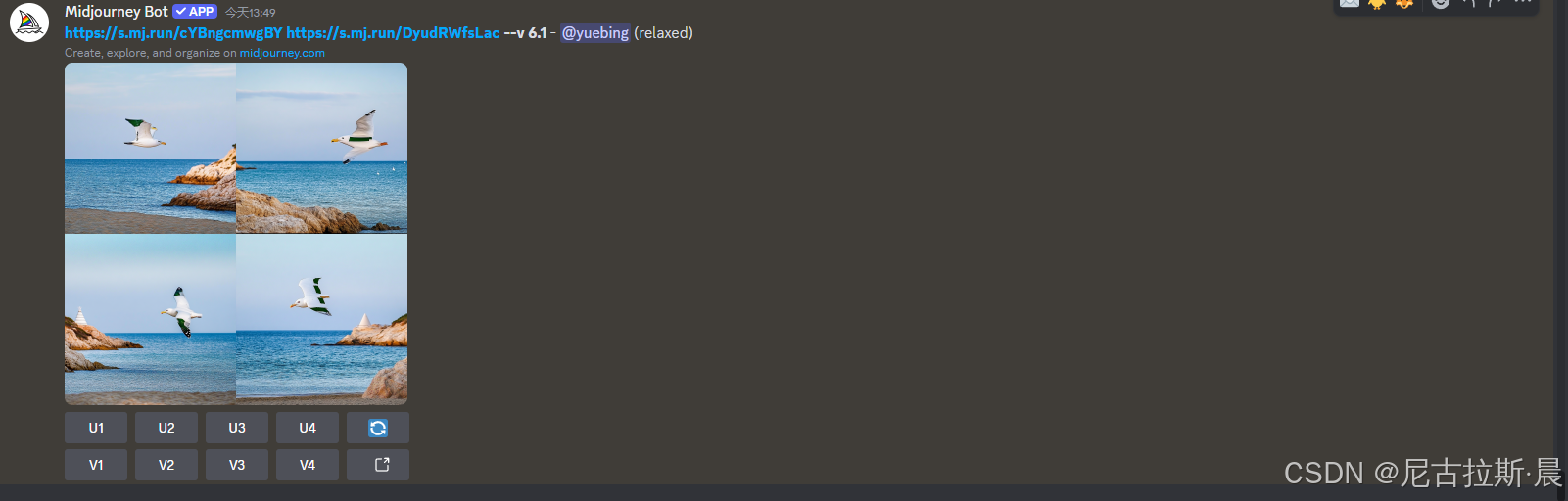
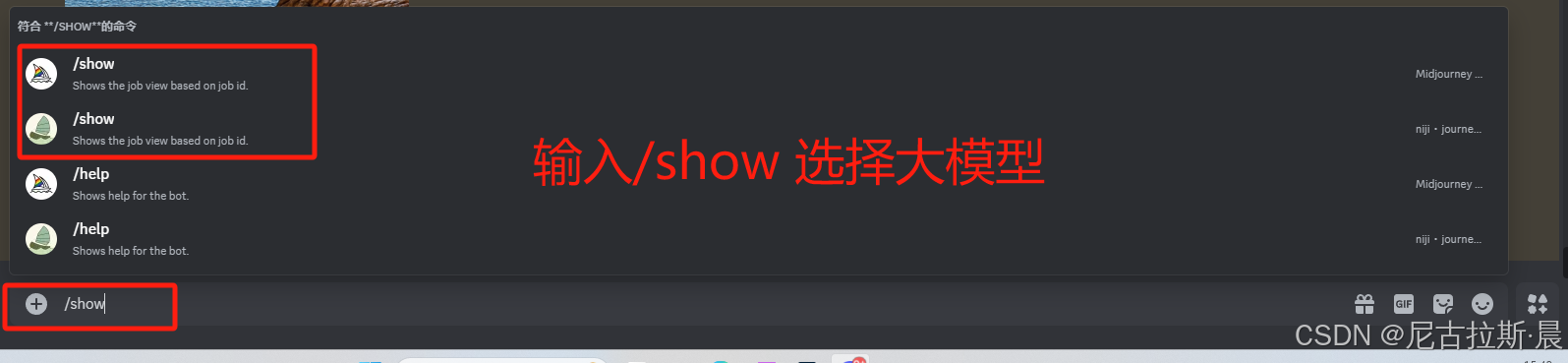
/show 查看曾经图片
输入/show +job id 即可查看原来图片

job id 获取方式:
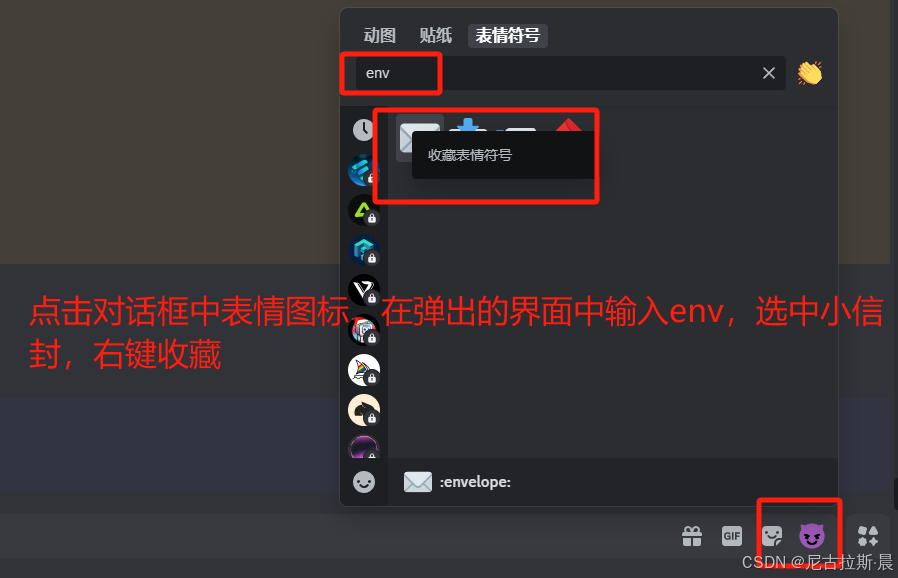
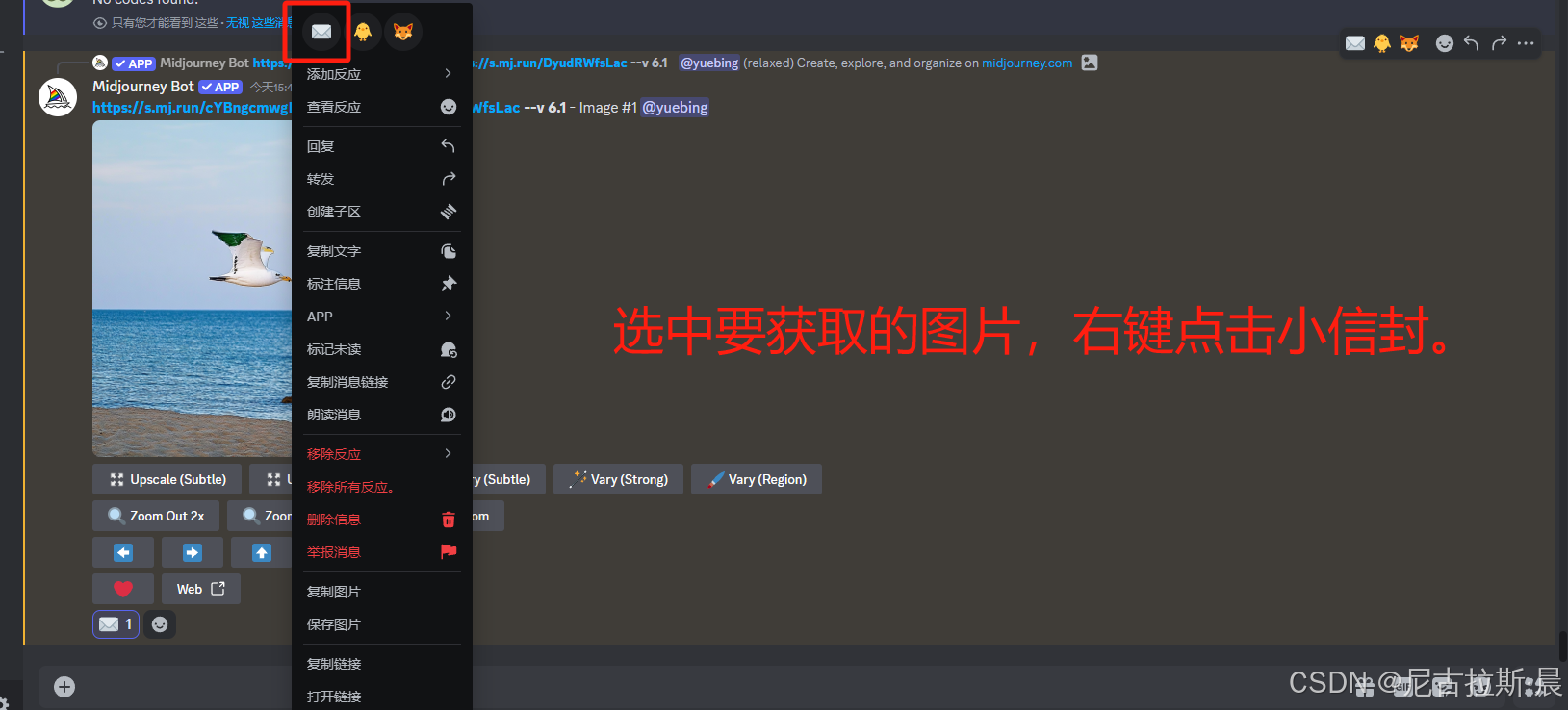
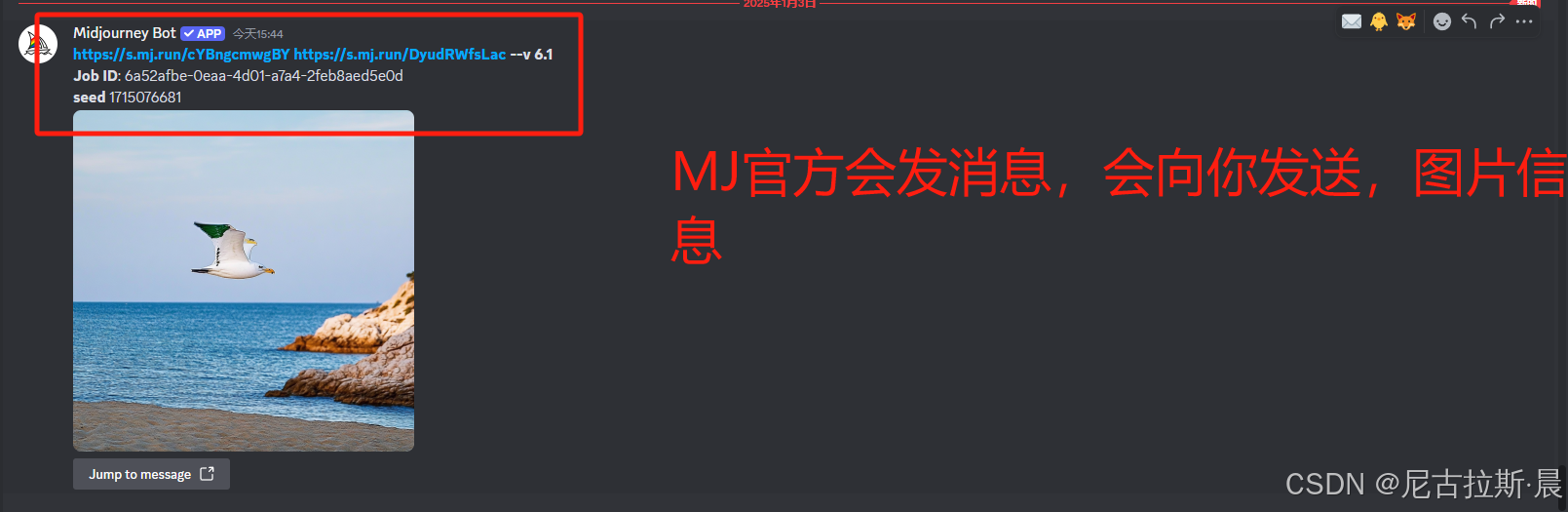
/prefer auto_dm: 开始自动发送保存job id



这一功能可以帮我们随时找到自己的作品,方便修改,相当于一个源文件。
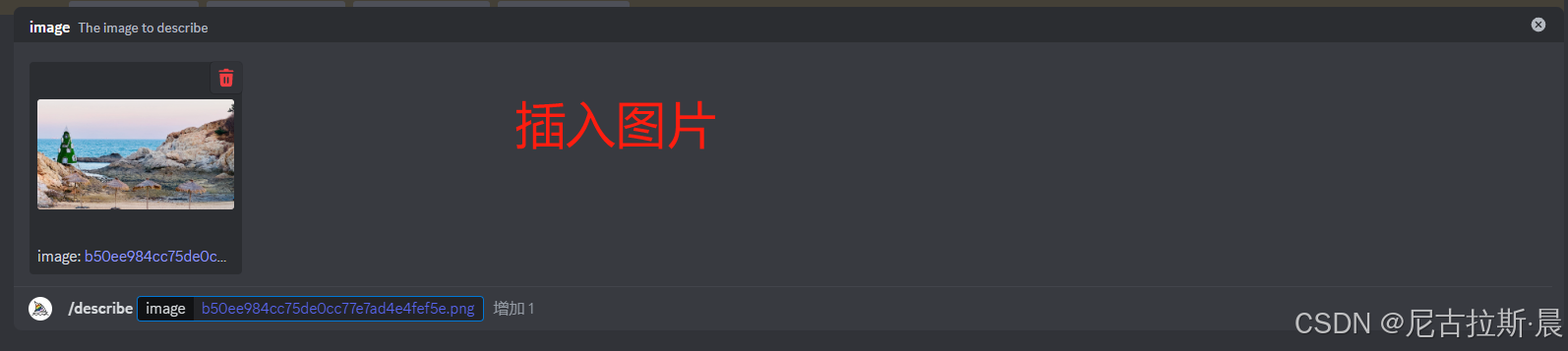
/describe 描述:通过图片描绘关键词
输入/describe 选择大模型,选择插入图片的方式,插入图片,回车即可查看模型写的四组关键词。

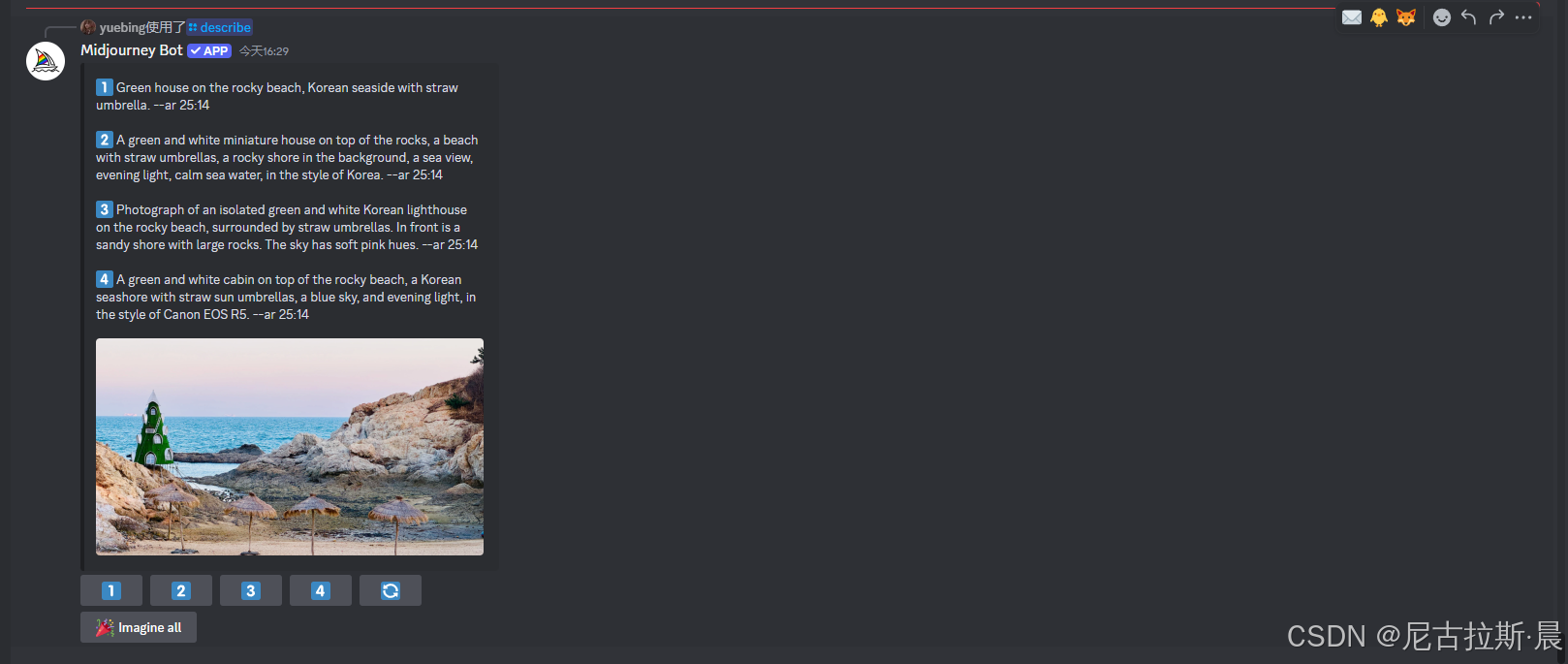
这个功能可以通过图片,反向推断关键词。从而可以自主创作出自己喜欢的图片。
/shorten 精简关键词:使关键词更精简,更有效


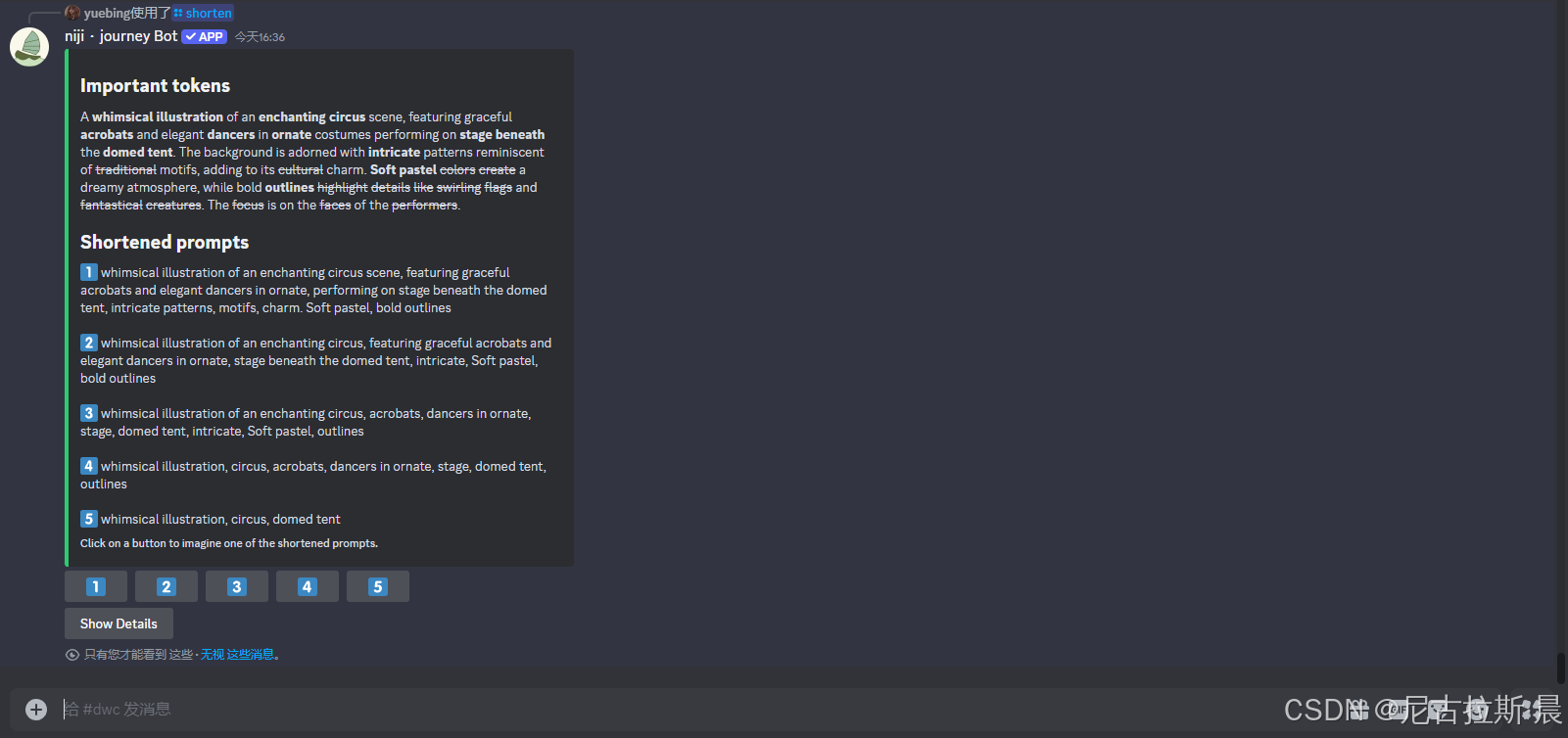
/prefer suffix 提示词预设
输入指令,点击new_value +预设提示词+imagine生成图片, 再次输入指令 回车 则关闭这一功能。




4、后缀解析
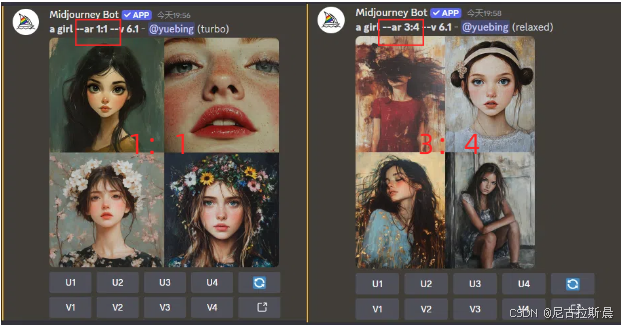
- --ar:用于调整生成图像的宽高比,格式为 --ar 宽:高,取值可为任意整数比,默认值是 1:1。
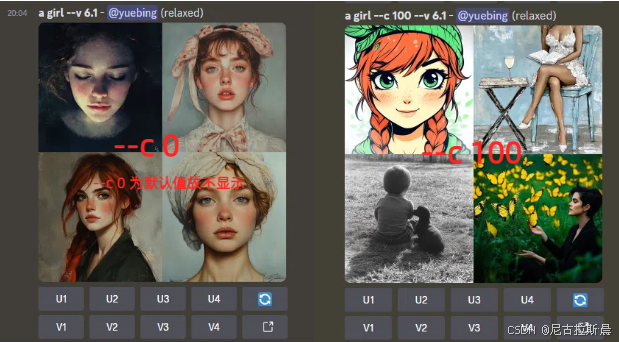
- --c:控制一次生成的 4 张图片的区别程度,即混沌值。取值范围是 0-100,默认值是 0。值越大,4 张图片的风格和构图差异越大。
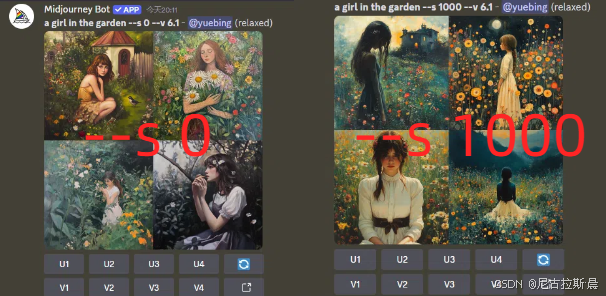
- --s:控制图片的风格化程度。取值范围一般认为是 0-1000,默认值是 100。数值越高,Midjourney 的默认美学风格越强,与 prompt 描述的联系可能越低。
- --q:控制图片质量。取值范围一般为 0.25、0.5、1、2,默认值是 1。数值越大,图片质量越高,细节越丰富,生成速度越慢。

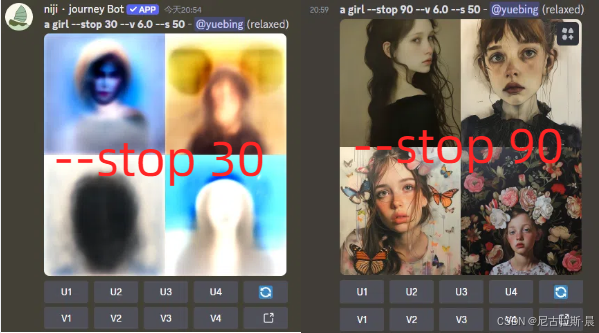
- --stop:用于提前停止图像生成任务。取值范围是 10-100,默认值为 100。若设置为较低的值,如 --stop 30,可提前停止生成,获得较模糊、细节较少的图像。
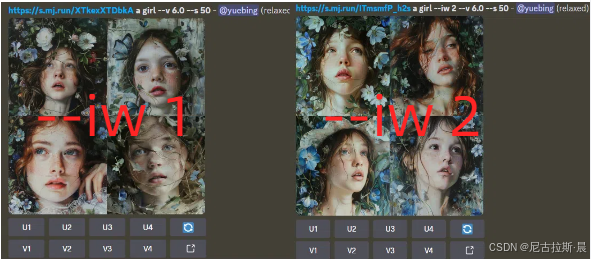
- --iw:调整垫图对生成图片的影响程度,只用在图生图。取值范围是 0-2,默认值是 1。值越大,参考图对生成图片的影响越大。垫图步骤:复制图片链接,/imagine +链接+空格+提示词+空格+--iw

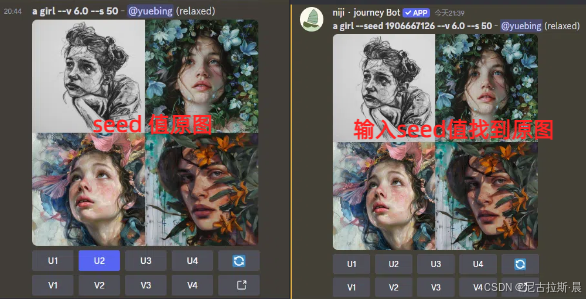
- --seed:设置随机数种子。取值范围理论上是 0-4294967295,使用相同的 seed 值和完全一样的提示词,将产生相似的初始四宫格图像。若不设置该参数,系统会默认下发一个随机数值.
- --no:去除画面中的某些元素,后面可跟多个英文单词,词与词之间用逗号隔开,没有严格的取值范围限制。如 --no flower,dog 可让生成的图像中不出现 “花” 和 “狗”。

- --tile:创建无缝平铺的图案或纹理,可用于生成壁纸、包装纸等。无严格取值范围限制,在 Midjourney 的 5、5.1、5.2 和 6 等版本上可用。

- --r:用于重复任务。取值为正整数,默认是 1。在 --fast 和 --turbo 模式下使用,设置 --r 值后,会按同一套参数运行 r 次,每次生成 4 张图片。
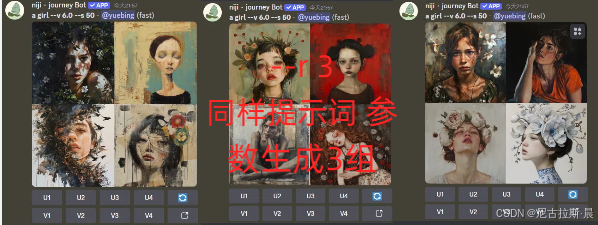
- --niji:指定使用 Niji 模型,用于生成动漫风格等特定类型的图像,无严格取值范围,有 niji4、niji5、niji6 等版本。
- --video:用于生成与初始图像网格生成过程相关的短视频,无严格取值范围。在图片生成结束后,点击小信封,Midjourney 机器人会将视频通过私信发送给用户,只对四张图拼起来的网格图片有效。
- --sref:样式参考指令,需在后面加上图片的链接,让生成的图像参考指定图片的风格,无严格取值范围。
- --sw:风格强度参数,需配合 --sref 使用。取值范围是 0-1000,默认值是 100。数值越高,生成图像的风格越接近参考图像。--sref空格+链接+空格--sw数值

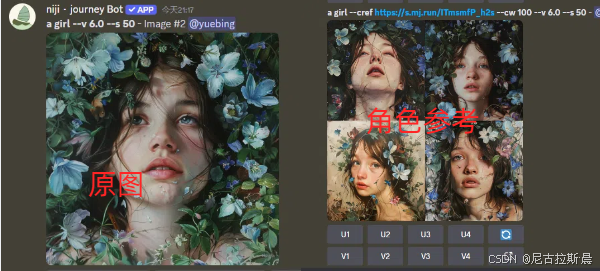
- --cref:角色参考指令,用于保持角色在不同图像中的一致性,后面需加图片链接,只用于 v6 和 niji6 版本,无严格取值范围。
- --cw:内容权重参数,需配合 --cref 使用。取值范围是 0-100,默认值是 100。值越高,生成图像越注重参考图中角色的整体特征。--cref空格+链接+空格--cw数值
注意:使用后缀时格式应为:提示词+空格+--后缀+空格+数值
总结:
MJ作为目前顶尖图像生成模型,在图像创作上有很大优势。但Midjourney 也有不足。面对超精细机械结构等复杂场景,算法易丢细节;小众艺术风格模仿,精准度欠佳,难完美复刻;中文语义理解存漏洞,易引发结果偏差。但总体瑕不掩瑜,为创作者带来诸多可能。


















 599
599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









