







写在前面
本系列文章是我的学习笔记,涵盖了入门的基础知识与模型以及对应的上机实验,截图截取自老师的课程ppt。
- 概论
- 词汇分析
- 句法分析
- 语篇分析
- 语义分析
- 语义计算
- 语言模型
- 文本摘要--自动摘要生成
- 情感分析
- 部分对应上机实验
目录
概述
文本摘要的定义:从单/多文档中提取重要信息,生成简洁的摘要(长度通常小于原文一半)。
四个核心概念:
- Extraction:直接抽取原文关键句(如
TextRank)。 - Abstraction:抽象化,生成新句子(如
Seq2Seq)。 - Fusion:多文档信息融合,把抽取的东西联合在一起。
- Compression:删除冗余内容。
分类
源数据类型
- 单文档摘要
- 多文档摘要
文档长度
- 长文本摘要
- 短文本摘要
生成方式
- Extractive抽取式的,从原文中找到一些关键的句子,组合成一篇摘要;
from gensim.summarization import summarize text = "《肖申克的救赎》讲述了一位银行家被冤入狱...(长文本)" summary = summarize(text, ratio=0.2) # 按文本比例压缩 print(summary)from sklearn.feature_extraction.text import TfidfVectorizer doc = "自然语言处理是人工智能的重要分支。文本摘要是其应用之一。摘要技术分为抽取式和生成式。" sentences = doc.split("。")[:-1] # 分句 # TF-IDF加权抽取关键句 vectorizer = TfidfVectorizer() X = vectorizer.fit_transform(sentences) keywords = vectorizer.get_feature_names_out() print("关键词:", keywords) # 输出: ['摘要', '分支', '处理', ...] - Abstractive摘要式(生成式)的,通过建立抽象的语意表示,使用自然语言生成技术,形成摘要。需要复杂的自然语言理解和生成技术支持。
from transformers import pipeline summarizer = pipeline("summarization", model="facebook/bart-large-cnn") text = "自然语言处理是人工智能的重要分支..." # 长文本 summary = summarizer(text, max_length=50) print(summary[0]['summary_text'])
生成技术
- 基于篇章技术的摘要生成
- 基于统计方法的摘要生成
- 基于深度学习的摘要生成
- 其他相关技术
基于篇章技术的摘要生成
篇章的分段:利用词的内在联系来把带有注释的文本按照子标题分成多段。
- 指代问题:用词语标注法代替句法分析解决代词指代问题
- 描述对象的终止与否的判定:如何确定连接描述词与其前述词的关系
- 基于会话分析的摘要生成:把连贯和衔接用于建立一种基于分类的模型从而生成文摘
- 言语行为:承诺行为、表达行为、断言行为、指示行为、宣布行为
- 会谈的对话性质确定了几乎所有的话语都可以归结为五种言语行为之一
- 识别言语行为的类型为我们理解会谈者的立场、观点和主张提供了一条很重要的线索
- 每一以言行事行为都必定对应不同的语言表层现象, 如动词“呼吁” 、“希望” 、“愿”对应指示行为; “对……表示(感谢、赞赏、遗憾… …)”结构对应于表达行为;“说” 、“认为” 、“相信”等引导断言行为
- 主题的确定:根据文本及篇章结构的不同从语料中学习句子出现的位置规律进而确定题目
模型示例:
(SpeechAct (role 洛佩斯) (actType 承诺) on (event 坚持一个中国的政策) (eventType 一个中国问题)基于统计方法的摘要生成
- 词加权:利用对所有句中的词加权建立一个矩阵方法从而生成摘要
- 段落抽取:利用一个基础语料及共同出现的高频率的词在各段落中出现的相似度从而确定出重要的段落形成摘要
- 句子抽取:利用各种加权特征对句子进行打分,选出最具有代表意义句子作为文摘句
- 基于模板填充的信息抽取:利用背景知识建立时事新闻模式对多篇报道进行比较分析形成摘要
- ① 为文摘预定义好框架结构;
② 从原文中检索出文摘框架所要求的内容,填充到文摘框架中;
③ 制定文摘模板;
④ 利用文摘模板,将文摘框架中的内容转换为文摘输出。
- ① 为文摘预定义好框架结构;
- 文本分类:通过语料学习建立一组具有相关语义词典作为以后判断所读文本类别的依据
TextRank
TextRank 算法是一种用于文本的基于图的排序算法。其基本思想来源于谷歌的 PageRank算法, 通过把文本分割成若干组成单元(单词、句子)并建立图模型, 利用投票机制对文本中的重要成分进行排序, 仅利用单篇文档本身的信息即可实现关键词提取、文摘。
- 和 LDA、HMM 等模型不同, TextRank不需要事先对多篇文档进行学习训练, 因其简洁有效而得到广泛应用。

主要步骤:


无监督TextRank算法优势:
- TextRank不依赖于文本单元的局部上下文,而是考虑全局信息,从全文中不断迭代采样的文本信息进行文本单元重要性学习;
- TextRank识别文本中各种实体间的连接关系,利用了推荐的思想。文本单元会推荐与之相关的其他文本单元,推荐的强度是基于文本单元的重要性不断迭代计算得到。被其他句子高分推荐的句子往往在文本中更富含信息量,因此得分也高;
- TextRank实现了“文本冲浪”的思路,意思与文本凝聚力类似。对于文本中的某一概念c,我们往往更倾向于接下来看与概念c相关的其他概念;
- 通过迭代机制,TextRank能够基于连接的文本单元的重要性来计算文本单元得分。
TextRank算法存在的问题:
- 摘要句子重复: 去除相似句子
- 摘要开头句子不适合作为句子;
- 部分摘要句子太长:限定摘要句子长度
摘要生成评价方法
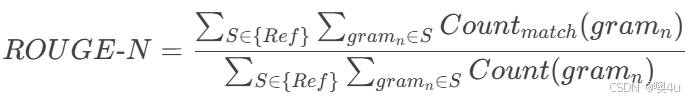
- 系统摘要:
the cat was found under the bed - 参考摘要:
the cat was under the bed - ROUGE-1 = 1.0,ROUGE-2 = 0.8。
- Edmundson:句子重合率 = 匹配句子数 / 参考摘要句子数 × 100%。
from rouge_score import rouge_scorer
scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2'])
scores = scorer.score(
"猫在床上被发现", # 系统摘要
"猫在床下" # 参考摘要
)
print(scores['rouge1'].fmeasure) # 输出: 0.67总结
文本摘要技术是自然语言处理的重要应用领域,主要分为抽取式和生成式两大方向。抽取式方法如TextRank通过统计和图表算法直接从原文提取关键信息,生成式方法则利用深度学习模型重新组织语言生成摘要。
从技术发展来看,传统方法如基于篇章结构的分析和统计模型(TF-IDF、TextRank)奠定了摘要生成的基础,而现代深度学习方法(Seq2Seq、Transformer)则大幅提升了摘要的流畅性和语义理解能力。评价体系方面,ROUGE和Edmundson等指标为不同方法提供了量化比较标准。
实际应用中,选择摘要方法需要考虑多个维度:对于准确性要求高且允许直接引用的场景,抽取式方法更为适合;需要生成通顺自然语言时,生成式方法表现更佳。同时,无监督方法在小数据场景下优势明显,而有监督方法在大数据环境下能取得更好效果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









