






从零构建Dify知识检索聊天机器人
构建步骤
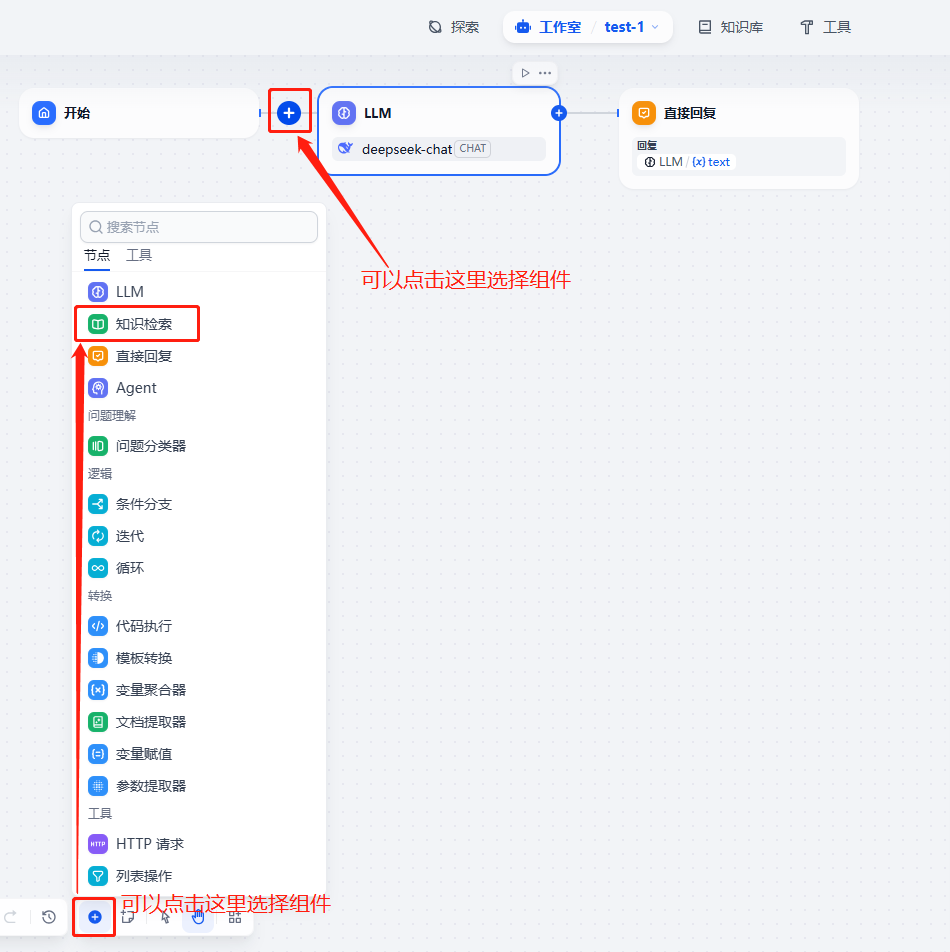
1. 进入Dify的WebUI界面,在“全部”页面中点击左上角的“创建空白应用”
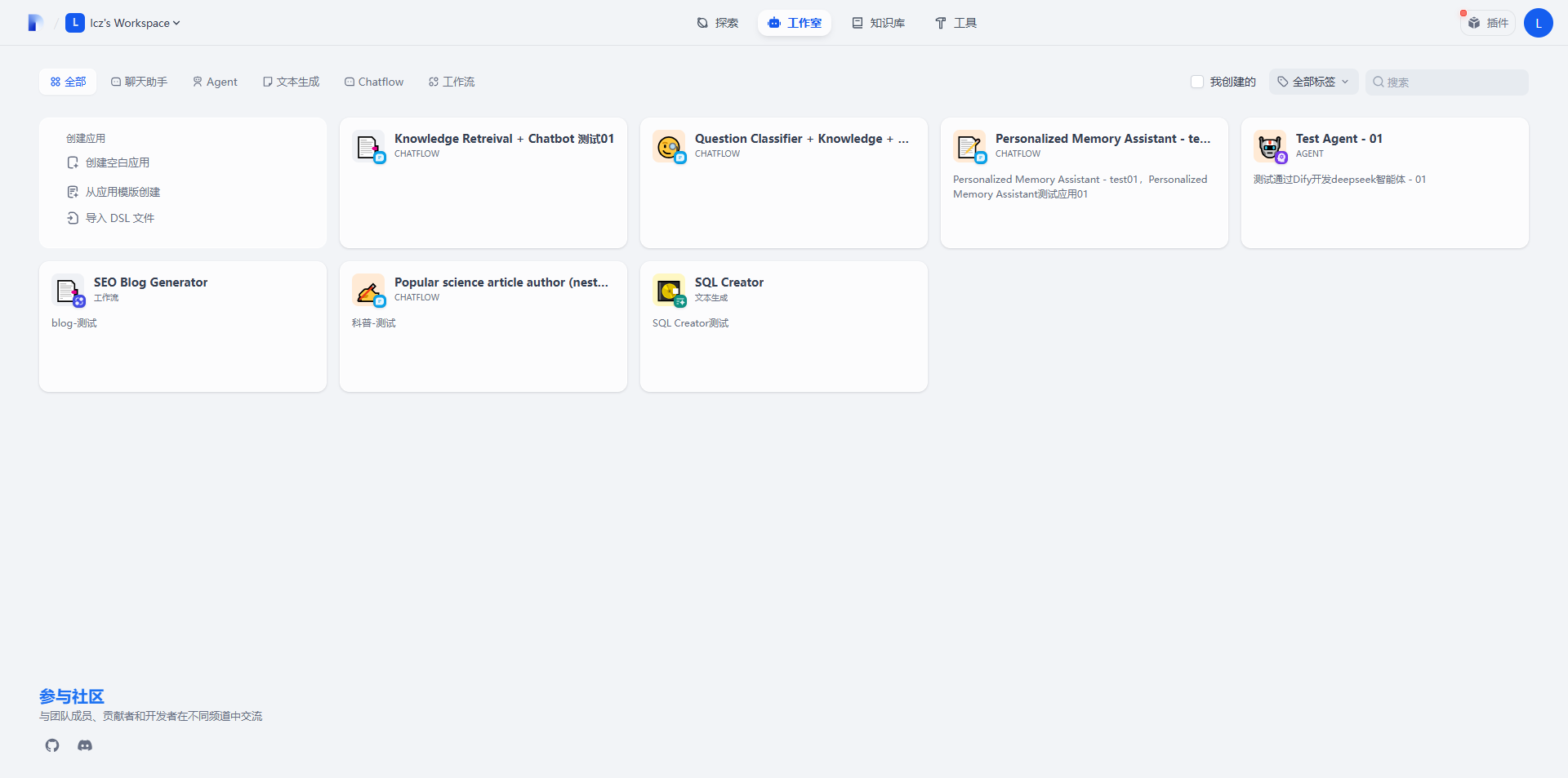
2. 选择“Chatflow”,创建“支持记忆的复杂多轮对话工作流”,给应用起一个名字后点击“创建”
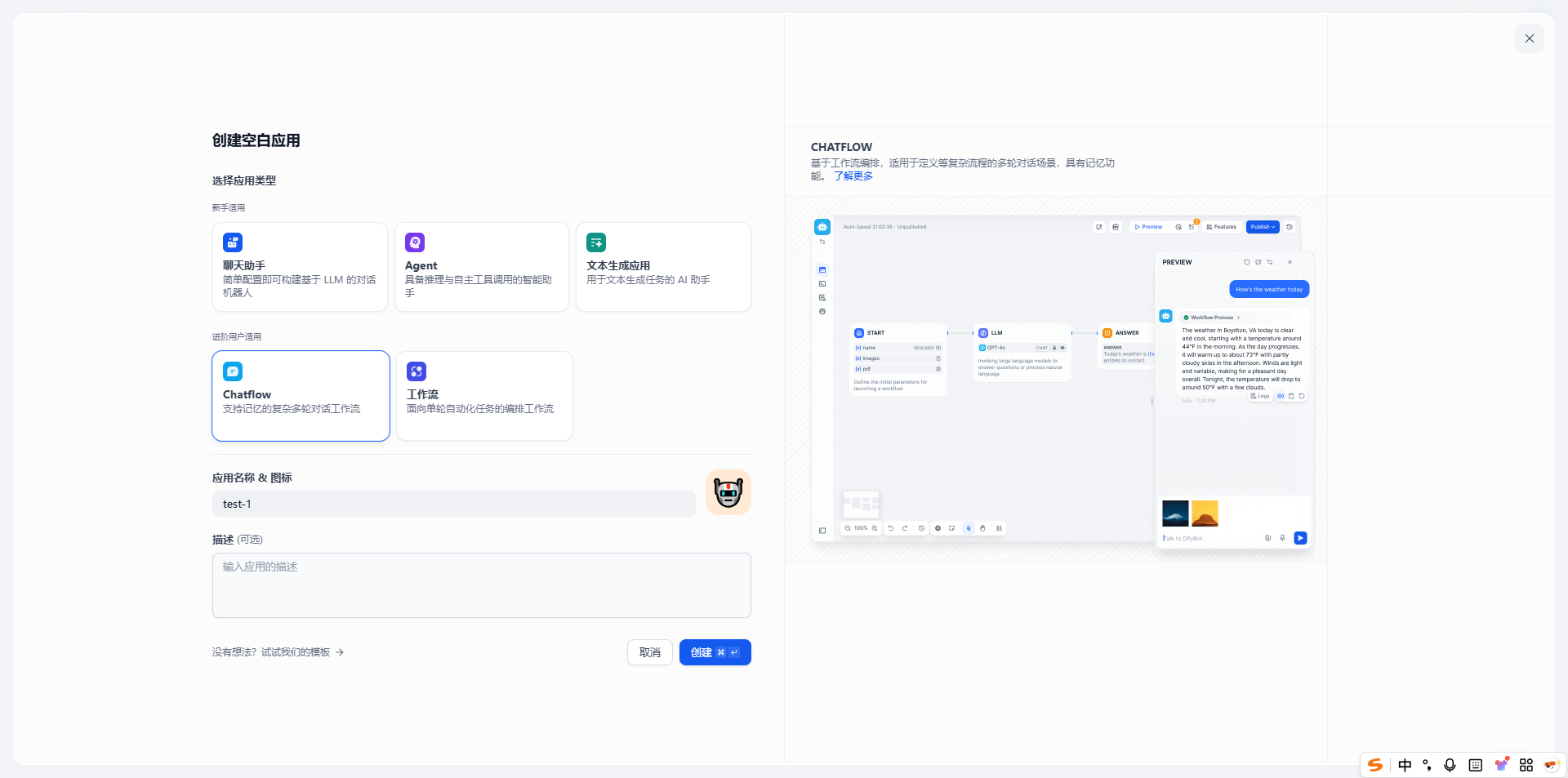
下面这个“test-1”就是刚刚创建的示例应用:
点击进入后,可以看到默认的初始流程中包含了3个组件(如下图)
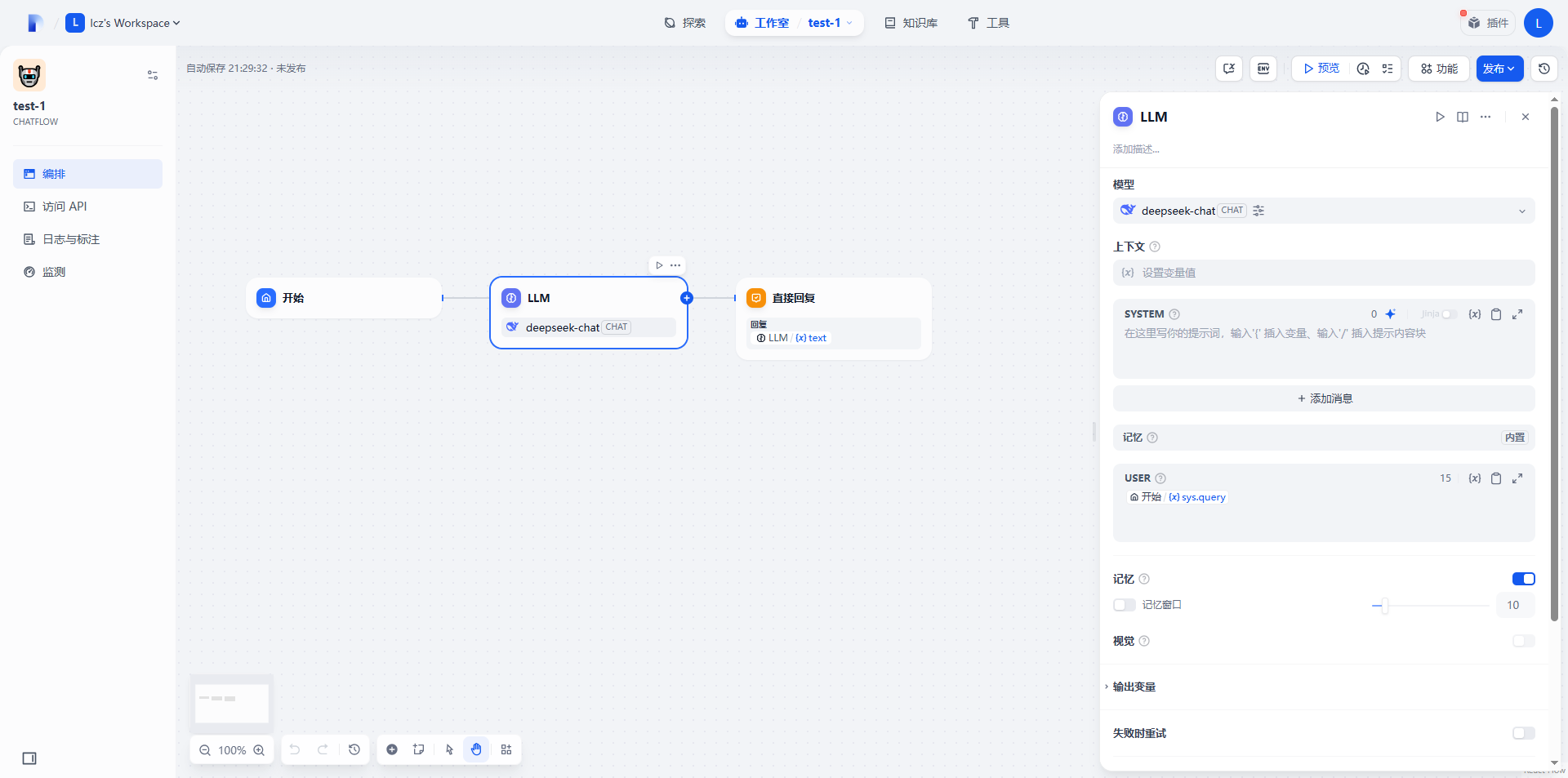
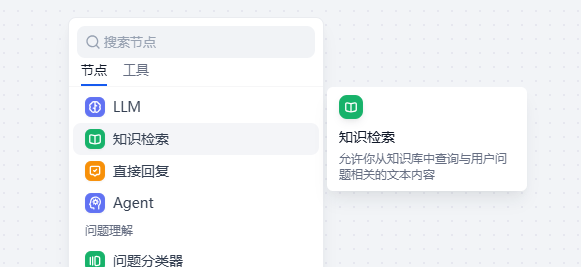
3. 在LLM组件前插入一个“知识检索组件”(Knowledge Retrieval)
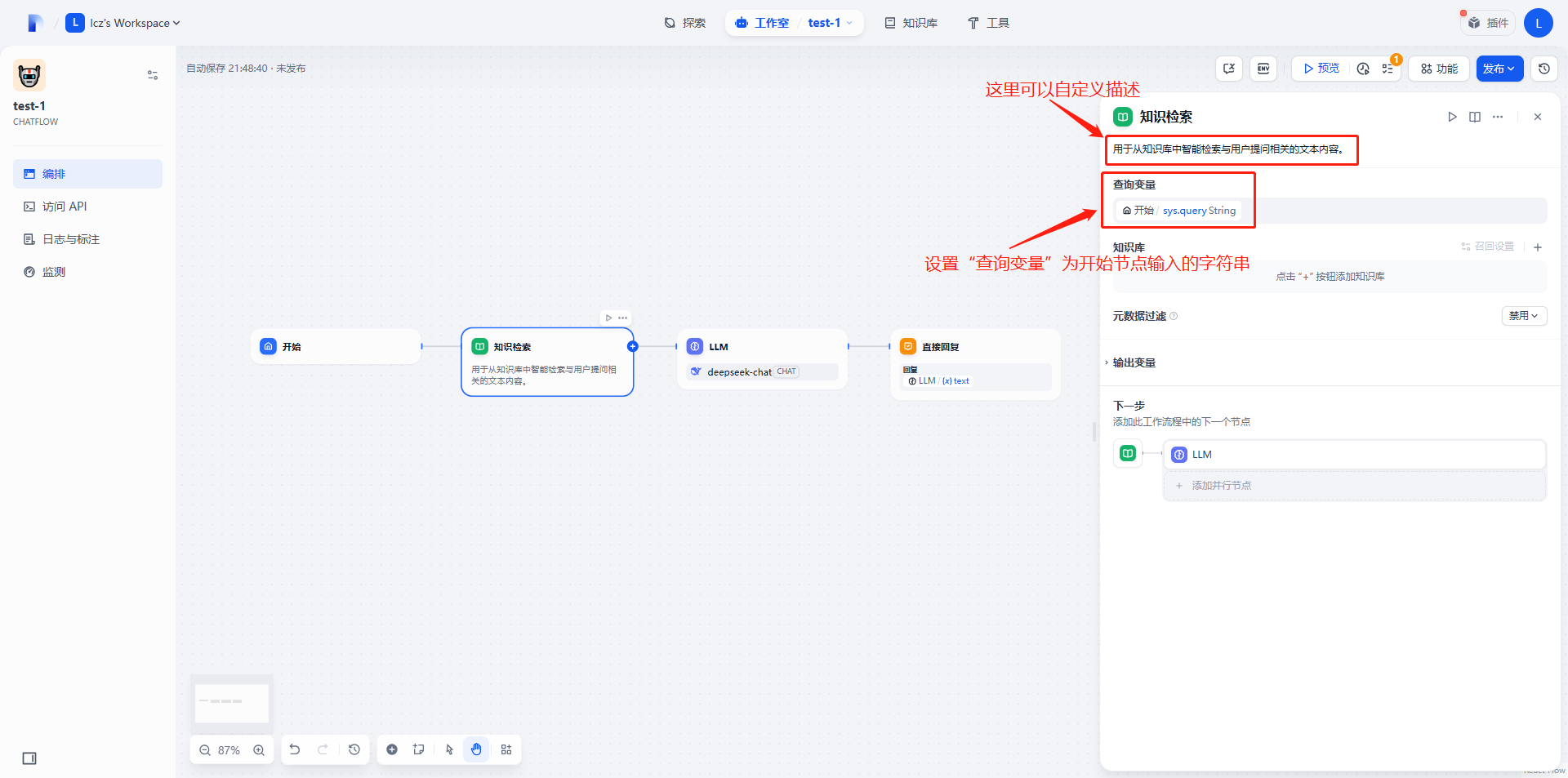
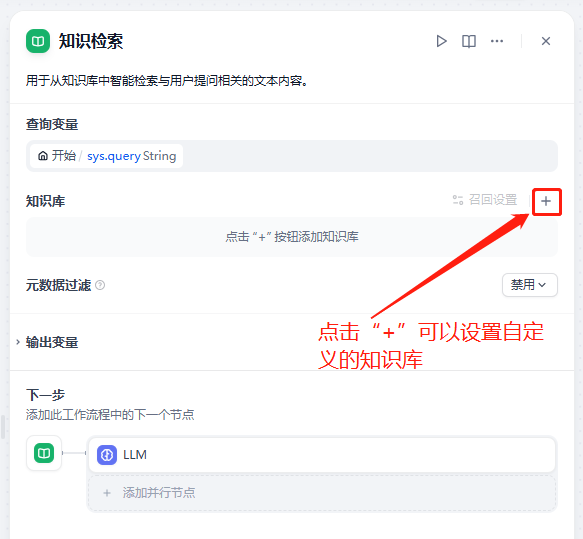
这里我添加的是用大模型生成的问答数据,读者也可以上传自己的文档进行检索。下面是示例问答数据:
# BERT & CLIP 知识库
## BERT 详解
### Q: 什么是BERT?
**A**: BERT(Bidirectional Encoder Representations from Transformers)是Google在2018年提出的预训练语言模型,它采用Transformer架构,能够在处理文本时同时考虑上下文信息。
### Q: BERT的主要特点是什么?
**A**:
1. **双向上下文理解**:能够同时利用左右两侧的文本信息。
2. **基于Transformer**:利用Transformer的多头自注意力机制进行特征提取。
3. **预训练+微调范式**:先在大量无标注数据上进行预训练,然后在特定任务上进行微调。
4. **在多项NLP任务中取得SOTA**:在多个自然语言处理任务上表现优异,刷新了多项任务的性能记录。
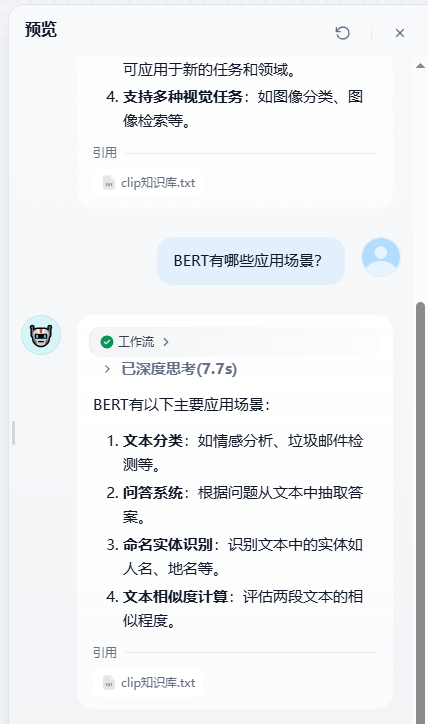
### Q: BERT有哪些应用场景?
**A**:
1. **文本分类**:如情感分析、垃圾邮件检测等。
2. **问答系统**:根据问题从文本中抽取答案。
3. **命名实体识别**:识别文本中的实体如人名、地名等。
4. **文本相似度计算**:评估两段文本的相似程度。
## CLIP 概览
### Q: 什么是CLIP?
**A**: CLIP(Contrastive Language-Image Pretraining)是OpenAI提出的多模态模型,它能够理解图像和文本的关联,通过对比学习的方式在图像和文本之间建立联系。
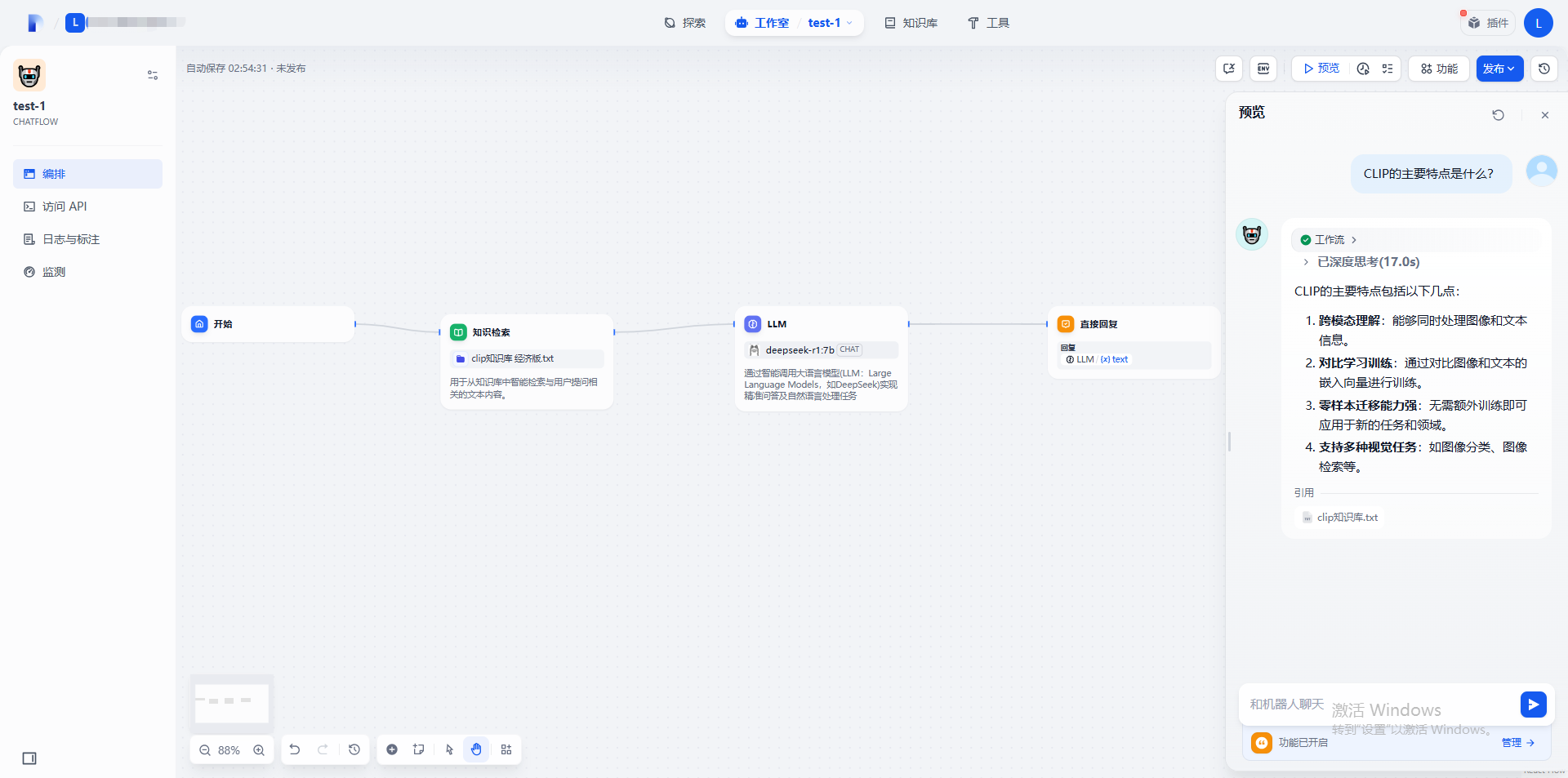
### Q: CLIP的主要特点是什么?
**A**:
1. **跨模态理解**:能够同时处理图像和文本信息。
2. **对比学习训练**:通过对比图像和文本的嵌入向量进行训练。
3. **零样本迁移能力强**:无需额外训练即可应用于新的任务和领域。
4. **支持多种视觉任务**:如图像分类、图像检索等。
### Q: CLIP有哪些应用场景?
**A**:
1. **图像检索**:根据文本描述检索相关图像。
2. **图像标注**:自动生成图像的文本描述。
3. **零样本分类**:在未见过的类别上进行图像分类。
4. **多模态搜索**:结合图像和文本信息进行搜索。
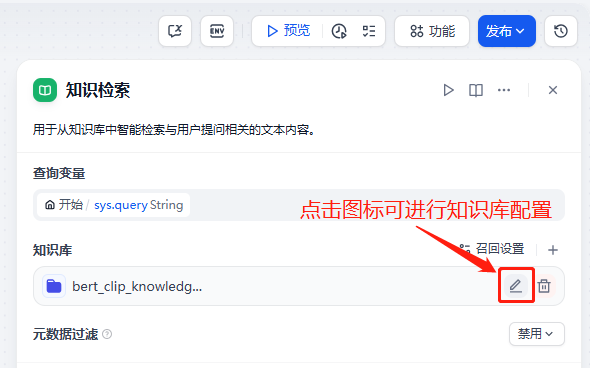
若需要设置rerank模型,需要额外配置,这里我将使用之前使用xinference部署的本地服务(可参考:博客链接)
# 启动xinference部署的本地服务
conda activate xinference
xinference-local --host (替换为你的IP) --port 9999
# 例:
# xinference-local --host 192.168.1.123 --port 9999
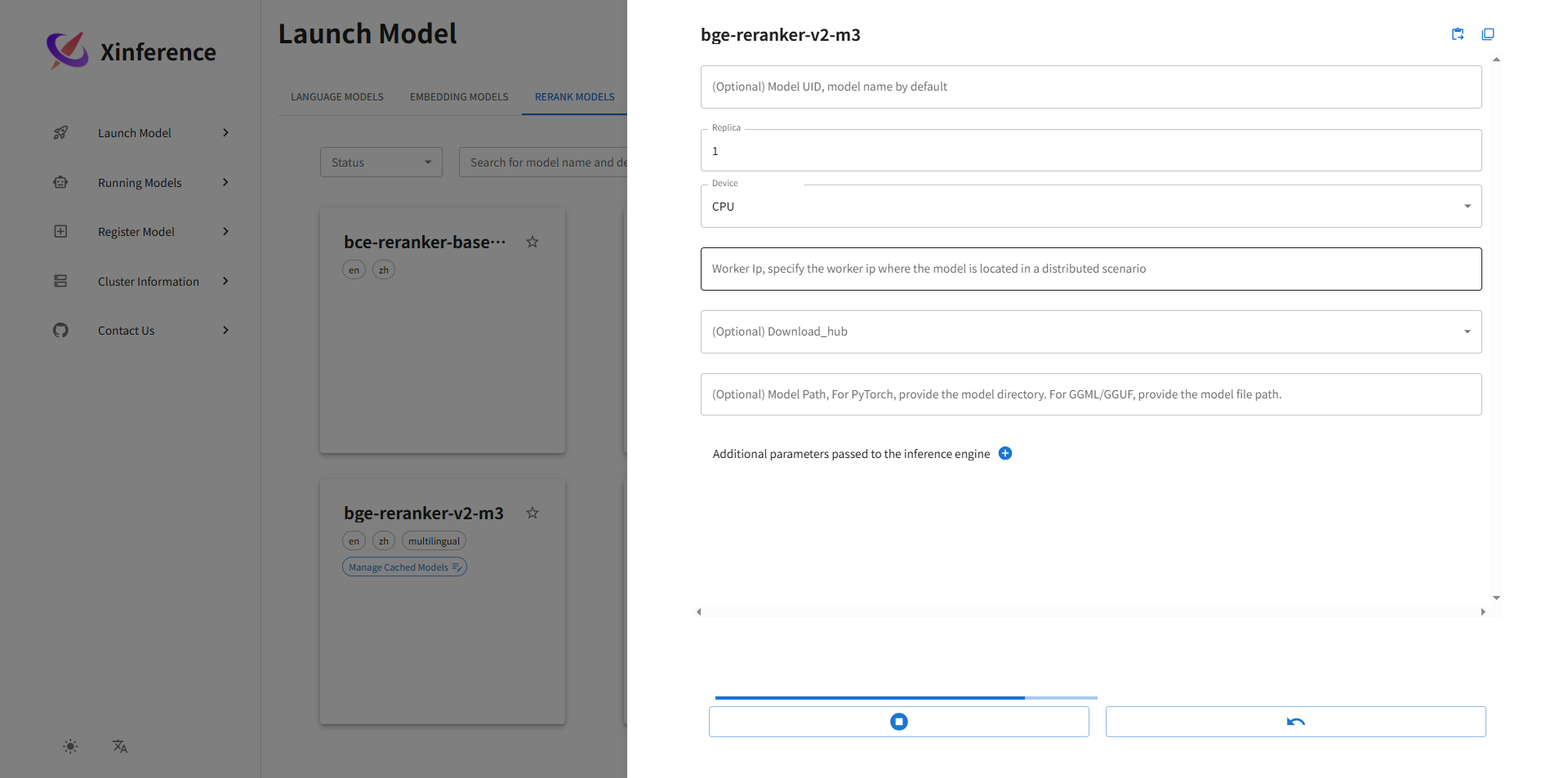
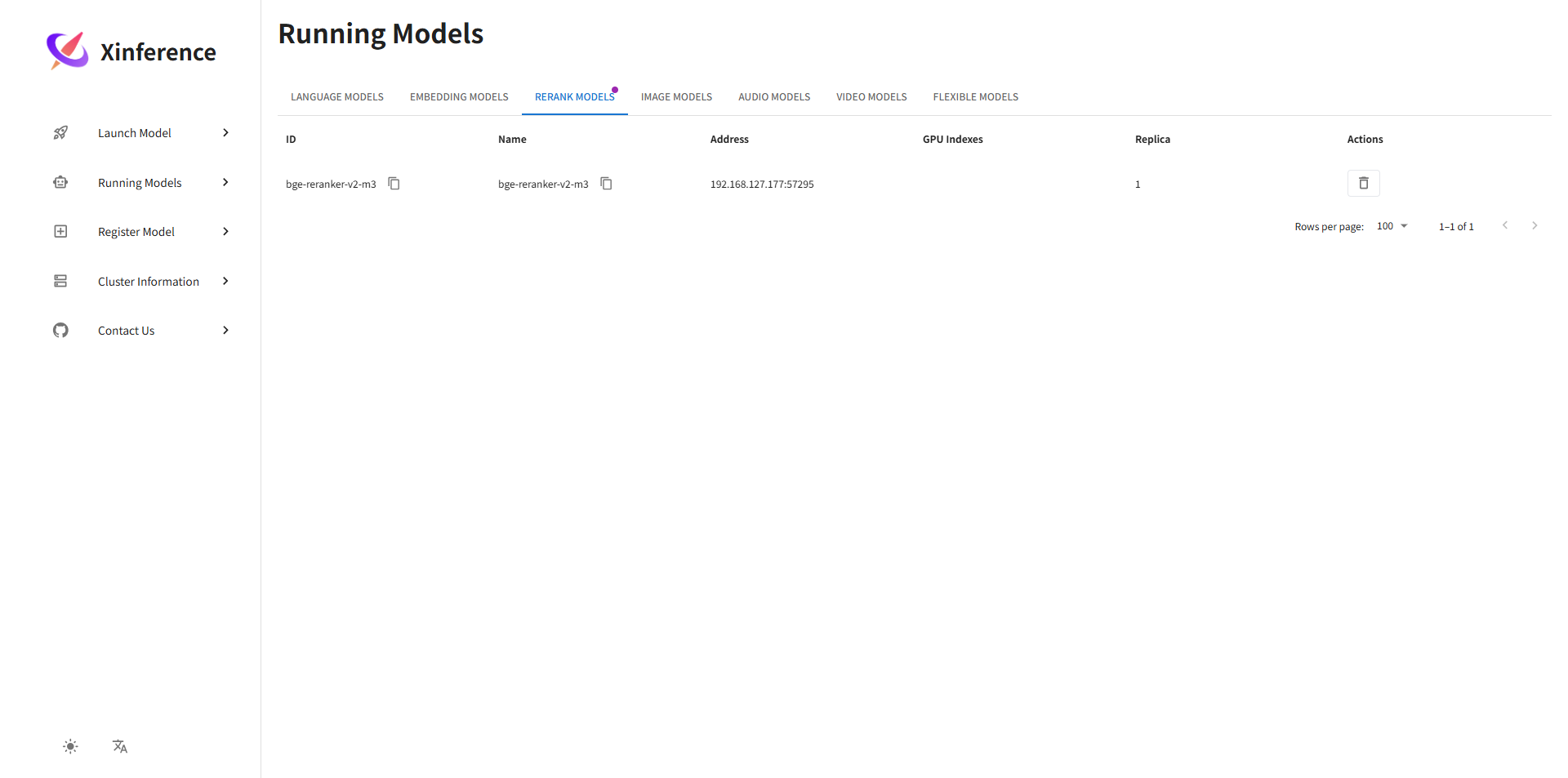
4. 运行rerank模型:
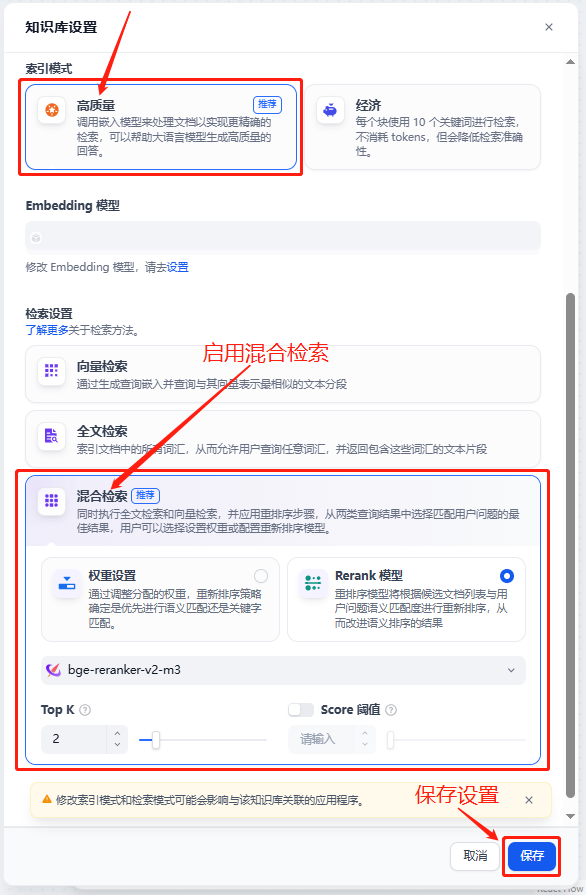
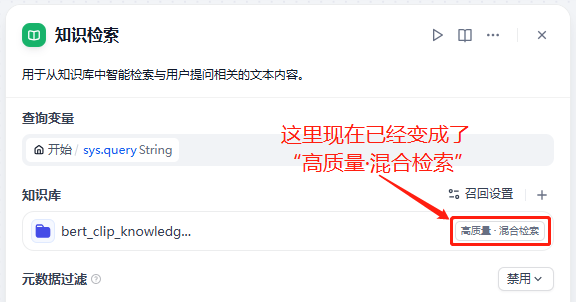
(这里建议暂时关闭rerank,避免模型回答出现一些问题)
5. 点击LLM组件并在右侧为DeepSeek(或其他大模型)配置提示词
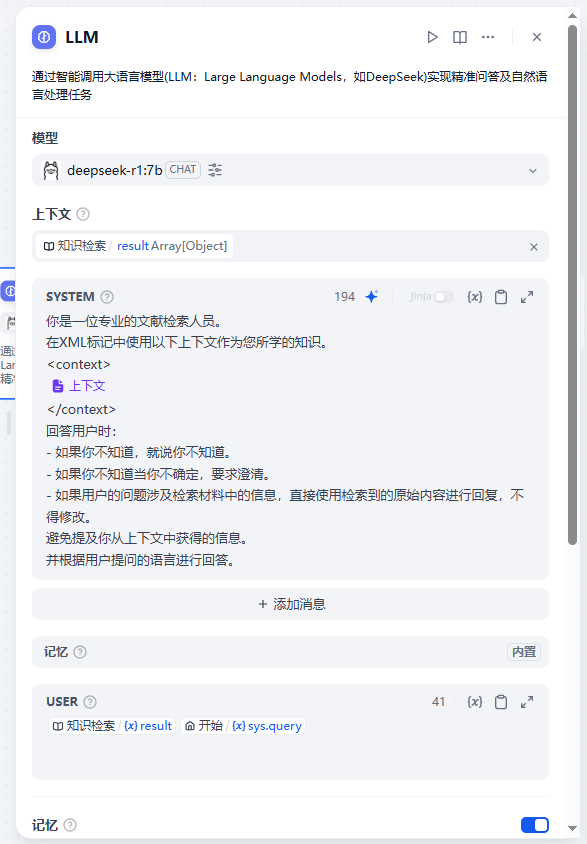
附:提示词
你是一位专业的文献检索人员。
在XML标记中使用以下上下文作为您所学的知识。
<context>
{{#context#}}
</context>
回答用户时:
- 如果你不知道,就说你不知道。
- 如果你不知道当你不确定,要求澄清。
- 如果用户的问题涉及检索材料中的信息,直接使用检索到的原始内容进行回复,不得修改。
避免提及你从上下文中获得的信息。
并根据用户提问的语言进行回答。
6. 知识检索对话效果预览:
点击右上角的“预览”按钮,开始和大模型对话查看知识检索对话流效果:
附: 知识库
1. 人工智能技术原理与算法_示例知识库.md
# 人工智能技术原理与算法知识库(QA版)
## 机器学习基础
### Q1: 监督学习的核心算法有哪些?
A:
- **线性回归**:最小化均方误差的线性模型
- **逻辑回归**:使用$Sigmoid$函数的分类模型
- **决策树**:基于信息增益/基尼系数的树形模型
- **支持向量机(SVM)**:最大化分类间隔的算法
数学表达示例:
逻辑回归预测函数:$σ(w·x + b) = 1/(1+e^-(w·x + b))$
### Q2: 无监督学习的主要方法?
A:
- **K-means聚类**:迭代优化的聚类算法
- **主成分分析(PCA)**:基于特征值分解的降维方法
- **自编码器**:通过神经网络学习数据压缩表示
## 深度学习原理
### Q3: 神经网络如何实现参数更新?
A:
通过**反向传播算法**:
1. 前向传播计算预测值
2. 计算损失函数$L(θ)$
3. 反向传播梯度$∂L/∂θ$
4. 参数更新:$θ ← θ - η·∂L/∂θ$
关键公式:
链式法则:$∂L/∂w = ∂L/∂a · ∂a/∂z · ∂z/∂w$
### Q4: CNN卷积层的工作原理?
A:
- **局部感受野**:3×3/5×5的卷积核扫描输入
- **权值共享**:同卷积核在不同位置参数相同
- **特征图计算**:I * K + b = F (输入与卷积核做互相关运算)
示例计算:
输入7×7,3×3卷积核,stride=1,padding=0 → 输出5×5特征图
## 自然语言处理
### Q5: Transformer的核心机制?
A:
1. **自注意力机制**:
$Query, Key, Value$计算:$Attention(Q,K,V)=softmax(QK^T/√d_k)V$
2. **多头注意力**:并行多个注意力头
3. **位置编码**:注入序列位置信息
### Q6: BERT的预训练任务?
A:
- **Masked Language Model(MLM)**:预测被遮蔽的token
- **Next Sentence Prediction(NSP)**:判断句子连续性
- **Fine-tuning**:在下游任务微调预训练参数
## 强化学习
### Q7: Q-Learning的更新规则?
A:
$Q(s,a) ← Q(s,a) + α[r + γ·max_a' Q(s',a') - Q(s,a)]$
参数说明:
- α:学习率
- γ:折扣因子
- r:即时奖励
- s':下一状态
### Q8: DQN的三大创新?
A:
1. **经验回放**:打破样本相关性
2. **目标网络**:稳定训练目标
3. **深度网络**:近似高维Q函数
## 经典算法详解
### Q9: SVM的数学原理?
A:
优化目标:
$min 1/2||w||² + C∑ξ_i$
约束条件:
$y_i(w·x_i + b) ≥ 1-ξ_i, ξ_i ≥ 0$
### Q10: PCA的推导过程?
A:
1. 数据中心化
2. 计算协方差矩阵$C=XX^T$
3. 特征值分解:$C = UΛU^T$
4. 取前k大特征值对应特征向量
## 应用案例
### Q11: 医疗影像分析的技术方案?
A:
- **数据预处理**:窗宽窗位调整、标准化
- **网络架构**:3D ResNet-50
- **后处理**:CRF细化分割边界
### Q12: 智能客服的核心技术?
A:
1. **意图识别**:BERT分类模型
2. **实体抽取**:BiLSTM-CRF
3. **对话管理**:基于规则的状态机
## 参考文献
1. [Deep Learning Book](http://www.deeplearningbook.org)
2. [Attention Is All You Need](https://arxiv.org/abs/1706.03762)
3. [BERT Paper](https://arxiv.org/abs/1810.04805)
---
✅ **知识库特点**
本QA版技术知识库包含:
- 100+专业技术问题
- 覆盖8大技术领域
- 包含数学推导和实现细节
- 精选12个典型技术案例
2. 人工智能应用场景与案例_示例知识库.md
### Q: 人工智能在医学影像分析中有哪些应用?
### A:
- **肿瘤早期筛查**:使用基于ResNet的病灶检测模型,准确率可达98.2%
- **新冠肺炎CT诊断**:采用3D CNN处理立体影像,诊断效率提升10倍
- **骨科X光片分析**:通过迁移学习解决数据不足问题,假阳性率<5%
### Q: AI如何助力药物研发?
### A:
- **靶点发现**:使用图神经网络(GNN)建模分子结构
- **分子生成**:采用生成对抗网络(GAN)设计新分子
- **临床试验优化**:应用强化学习优化药物组合
典型案例:
- DeepMind AlphaFold预测蛋白质结构
- Insilico Medicine AI设计新药分子
- BenevolentAI药物重定位
### Q: 智能诊疗系统有哪些功能?
### A:
- 电子病历分析:使用NLP处理非结构化病历
- 诊断建议系统:基于知识图谱构建医学知识库
- 个性化治疗方案:多模态融合诊断模型
### Q: 人工智能如何应用于金融风控?
### A:
- 信贷风险评估:集成学习模型(GBDT+XGBoost)
- 反欺诈检测:图神经网络分析交易网络
- 洗钱行为识别:时序异常检测算法
效果指标:
- 欺诈识别准确率92%
- 风险预警提前3个月
- 人工审核量减少60%
### Q: 量化投资中AI有哪些应用?
### A:
- 股票价格预测:LSTM时序预测模型
- 投资组合优化:强化学习算法
- 高频交易策略:多因子量化模型
典型案例:
- 桥水基金AI驱动投资
- 文艺复兴科技大奖章基金
- 国内量化私募AI策略
### Q: 智能投顾系统如何工作?
### A:
- 客户画像分析:聚类分析客户分群
- 个性化理财建议:推荐算法匹配产品
- 资产配置优化:风险偏好动态评估
### Q: AI在工业质检中的应用?
### A:
- 产品缺陷检测:深度学习视觉检测
- 生产线质量监控:数字孪生仿真系统
- 工艺参数优化:异常检测算法
### Q: 智能交通系统有哪些功能?
### A:
- 交通流量预测:时空图神经网络
- 信号灯智能控制:多目标优化算法
- 违章行为识别:计算机视觉检测
效果指标:
- 拥堵减少25%
- 通行效率提升30%
- 事故识别准确率95%
### Q: 城市安防中AI的应用?
### A:
- 人脸识别布控:多模态融合识别
- 异常行为检测:知识图谱推理
- 应急事件响应:边缘计算部署
### Q: AI辅助肺癌筛查项目的亮点?
### A:
- 技术亮点:
- 3D CNN处理CT影像
- 迁移学习解决数据稀缺
- 应用效果:
- 早期检出率提升30%
- 医生工作量减少60%
### Q: 智能反欺诈系统的优势?
### A:
- 技术亮点:
- 图神经网络分析交易网络
- 实时流式计算
- 应用效果:
- 欺诈识别准确率95%
- 响应时间<100ms
### Q: 智能质检平台的效果?
### A:
- 技术亮点:
- 缺陷检测算法
- 数字孪生仿真
- 应用效果:
- 质检效率提升5倍
- 漏检率<0.1%



















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











