







使用深度学习模型采用YOLOv8作为目标检测框架训练卫星图像火点、烟雾检测数据集 对卫星图像中的火点和烟雾进行检测
 卫星图像火点、烟雾检测数据集30480张,yolo和voc两种标注2类,标注数量:Smoke: 1311Wildfire: 22138image num: 30480
卫星图像火点、烟雾检测数据集30480张,yolo和voc两种标注2类,标注数量:Smoke: 1311Wildfire: 22138image num: 30480

使用深度学习模型对卫星图像中的火点和烟雾进行检测,采用YOLOv8作为目标检测框架。YOLO格式和VOC格式的标注文件,我们将直接使用YOLO格式进行训练。
以下是详细的步骤、关键文件及代码示例来指导你完成从准备数据集到训练模型的整个流程。
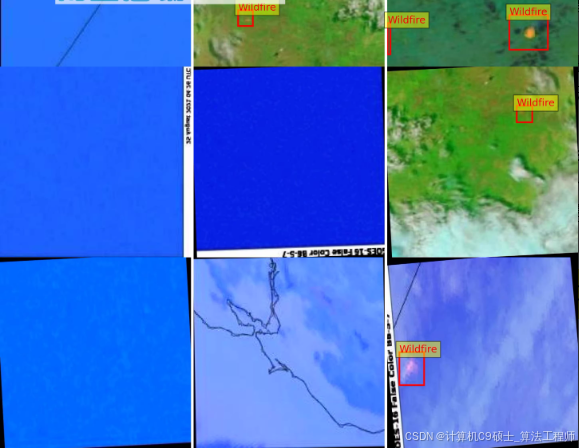
1. 数据集准备
假设你的数据集结构如下:

satellite_fire_smoke/
├── images/
│ ├── train/
│ │ ├── img1.jpg
│ │ └── ...
│ ├── val/
│ │ ├── img1.jpg
│ │ └── ...
│ └── test/
│ ├── img1.jpg
│ └── ...
└── labels/
├── train/
│ ├── img1.txt
│ └── ...
├── val/
│ ├── img1.txt
│ └── ...
└── test/
├── img1.txt
└── ...
data_fire_smoke.yaml
data_fire_smoke.yaml 文件内容示例:
train: ./satellite_fire_smoke/images/train/
val: ./satellite_fire_smoke/images/val/
nc: 2 # 类别数量:Smoke 和 Wildfire
names: ['Smoke', 'Wildfire']
确保每个标签文件的内容符合YOLO格式,即每行包含一个对象的类别ID、中心点x, y坐标(归一化到0-1),宽度和高度(同样归一化)。
2. 安装依赖库
确保安装了必要的库:
pip install ultralytics opencv-python-headless tensorboard
3. 模型训练
创建一个Python脚本来开始训练过程。这里我们以YOLOv8为例说明如何训练模型。
训练脚本
from ultralytics import YOLO
def main_train():
# 加载预训练的YOLOv8n模型或从头开始定义模型
model = YOLO('yolov8n.yaml') # 或者直接加载预训练权重,如 'yolov8n.pt'
results = model.train(
data='./data_fire_smoke.yaml',
epochs=100, # 根据需要调整
imgsz=640,
batch=16,
project='./runs/detect',
name='fire_smoke_detection',
optimizer='SGD',
device='0', # 使用GPU编号
save=True,
cache=True,
verbose=True,
)
if __name__ == '__main__':
main_train()
4. 推理与结果可视化
训练完成后,我们可以利用训练好的模型对新图片进行预测,并将结果可视化。
推理脚本
import cv2
from PIL import Image
from ultralytics import YOLO
model = YOLO('./runs/detect/fire_smoke_detection/weights/best.pt')
def detect_objects(image_path):
results = model.predict(source=image_path)
img = cv2.imread(image_path)
for result in results:
boxes = result.boxes.numpy()
for box in boxes:
r = box.xyxy
x1, y1, x2, y2 = int(r[0]), int(r[1]), int(r[2]), int(r[3])
label_id = int(box.cls)
label = result.names[label_id]
confidence = box.conf
if confidence > 0.5: # 设置置信度阈值
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2) # 绘制矩形框
cv2.putText(img, f'{label} {confidence:.2f}', (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
return img
# 示例调用
result_image = detect_objects('your_test_image.jpg') # 确保测试图像路径正确
Image.fromarray(cv2.cvtColor(result_image, cv2.COLOR_BGR2RGB)).show() # 使用PIL显示图像
5. 可视化界面
为了监控训练过程,可以使用TensorBoard。在训练脚本中添加 tensorboard=True 参数,然后运行以下命令启动TensorBoard:
tensorboard --logdir runs/
然后在浏览器中访问 http://localhost:6006 查看训练进度和结果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









