







基于YOLOv8的人体姿势关键点检测系统,并使用PyQt6编写GUI界面支持图片、视频和摄像头实时检测
文章目录
以下文字及代码仅供参考。
MPII人体姿势关键点检测数据集的yolo格式。16个关键点。可以直接进行yolo系列模型训练。其中,训练集,10306张,验证集4420张。
1
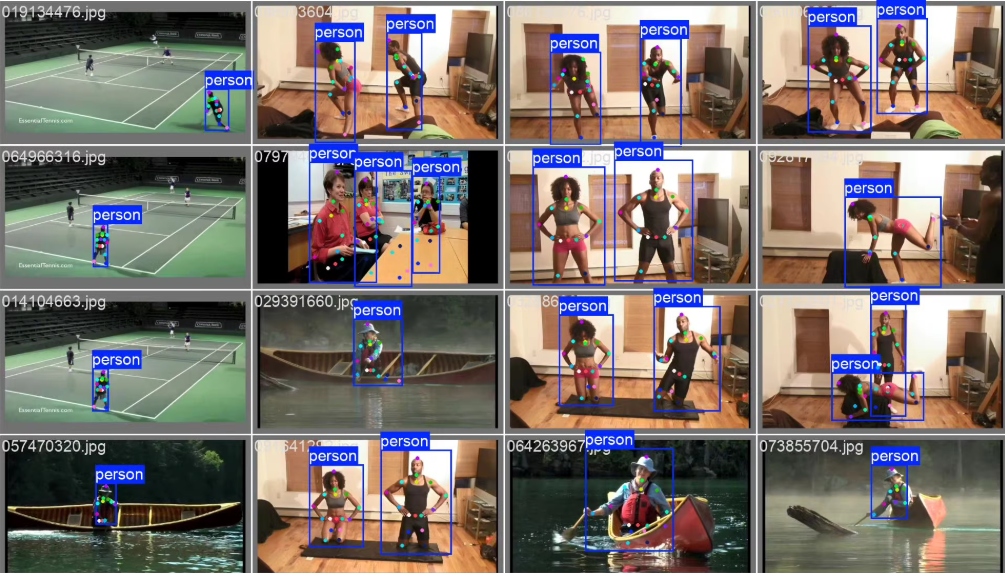
1

1

要利用MPII人体姿势关键点检测数据集构建基于YOLOv8的检测系统,使用PyQt6编写GUI界面,需完成以下步骤:
1. 数据准备和格式转换
1.1 将MPII数据集转换为YOLO格式
MPII数据集包含人体关键点信息,但YOLO模型主要用于目标检测。为了将关键点检测任务转化为目标检测任务,将每个关键点视为一个小的目标框。
假设我们只关注人体检测(即person类别),并且需要在检测到的人体上绘制关键点。
# utils.py
import json
import os
from PIL import Image
def mpii_to_yolo(mpii_json, output_dir):
with open(mpii_json) as f:
data = json.load(f)
for img_info in data['images']:
img_id = img_info['id']
img_width = img_info['width']
img_height = img_info['height']
img_filename = img_info['file_name']
yolo_labels = []
for ann in data['annotations']:
if ann['image_id'] == img_id and ann['category_id'] == 1: # category_id=1 表示 person
bbox_2d = ann['bbox']
keypoints = ann['keypoints']
x_center = (bbox_2d[0] + bbox_2d[2] / 2) / img_width
y_center = (bbox_2d[1] + bbox_2d[3] / 2) / img_height
width = bbox_2d[2] / img_width
height = bbox_2d[3] / img_height
yolo_labels.append(f"0 {x_center} {y_center} {width} {height}")
# 添加关键点坐标
for i in range(0, len(keypoints), 3):
x = keypoints[i] / img_width
y = keypoints[i + 1] / img_height
visible = keypoints[i + 2]
if visible > 0:
yolo_labels.append(f"{i // 3 + 1} {x} {y} 0 0")
label_file = os.path.join(output_dir, img_filename.replace('.jpg', '.txt'))
with open(label_file, 'w') as f:
f.write('\n'.join(yolo_labels))
# 调用函数进行转换
mpii_train_json = 'path/to/mpii/annotations/person_keypoints_train.json'
output_train_dir = 'path/to/output/train/labels'
os.makedirs(output_train_dir, exist_ok=True)
mpii_to_yolo(mpii_train_json, output_train_dir)
mpii_val_json = 'path/to/mpii/annotations/person_keypoints_val.json'
output_val_dir = 'path/to/output/val/labels'
os.makedirs(output_val_dir, exist_ok=True)
mpii_to_yolo(mpii_val_json, output_val_dir)
2. 训练YOLO模型
2.1 创建数据配置文件 data.yaml
train: path/to/output/train/images
val: path/to/output/val/images
nc: 17 # 1个person类别 + 16个关键点类别
names: ['person', 'keypoint1', 'keypoint2', ..., 'keypoint16']
2.2 训练脚本 train.py
# train.py
from ultralytics import YOLO
model = YOLO("yolov8n-pose.pt")
results = model.train(
data="data.yaml",
epochs=50,
imgsz=640,
batch=16,
name="pose_detector"
)
3. 检测与推理
3.1 修改 detect.py 支持关键点绘制
# detect.py
from ultralytics import YOLO
import cv2
import numpy as np
def draw_keypoints(image, results):
for result in results:
boxes = result.boxes.xyxy.cpu().numpy()
keypoints = result.keypoints.data.cpu().numpy()
for box, kps in zip(boxes, keypoints):
x1, y1, x2, y2 = map(int, box)
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
for kp in kps:
if not np.isnan(kp).any():
x, y = map(int, kp[:2])
cv2.circle(image, (x, y), 5, (0, 0, 255), -1)
return image
def process_video(video_path, model):
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
results = model(frame)
annotated_frame = draw_keypoints(frame.copy(), results)
cv2.imshow("Video Detection", annotated_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
video_path = "path/to/video.mp4"
model = YOLO("runs/detect/pose_detector/weights/best.pt")
process_video(video_path, model)
4. PyQt6 GUI界面
4.1 界面布局和功能实现
# gui.py
import sys
from PyQt6.QtWidgets import QApplication, QMainWindow, QPushButton, QVBoxLayout, QWidget, QLabel, QFileDialog, QSlider, QHBoxLayout, QComboBox
from PyQt6.QtGui import QImage, QPixmap
from PyQt6.QtCore import Qt, QTimer
import cv2
from detect import model, draw_keypoints
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("YOLOv8 Pose Detection")
self.setGeometry(100, 100, 1280, 720)
self.central_widget = QWidget()
self.setCentralWidget(self.central_widget)
self.layout = QVBoxLayout()
self.central_widget.setLayout(self.layout)
self.image_label = QLabel(self)
self.layout.addWidget(self.image_label)
self.control_layout = QHBoxLayout()
self.layout.addLayout(self.control_layout)
self.open_image_button = QPushButton("Open Image", self)
self.open_image_button.clicked.connect(self.open_image)
self.control_layout.addWidget(self.open_image_button)
self.open_video_button = QPushButton("Open Video", self)
self.open_video_button.clicked.connect(self.open_video)
self.control_layout.addWidget(self.open_video_button)
self.open_camera_button = QPushButton("Open Camera", self)
self.open_camera_button.clicked.connect(self.open_camera)
self.control_layout.addWidget(self.open_camera_button)
self.model_combo = QComboBox(self)
self.model_combo.addItem("yolov8-baseline.pt")
self.control_layout.addWidget(self.model_combo)
self.iou_slider = QSlider(Qt.Orientation.Horizontal, self)
self.iou_slider.setMinimum(1)
self.iou_slider.setMaximum(100)
self.iou_slider.setValue(45)
self.control_layout.addWidget(self.iou_slider)
self.conf_slider = QSlider(Qt.Orientation.Horizontal, self)
self.conf_slider.setMinimum(1)
self.conf_slider.setMaximum(100)
self.conf_slider.setValue(25)
self.control_layout.addWidget(self.conf_slider)
self.timer = QTimer(self)
self.timer.timeout.connect(self.update_frame)
self.cap = None
def open_image(self):
file_dialog = QFileDialog()
file_path, _ = file_dialog.getOpenFileName(self, "Open Image", "", "Images (*.png *.xpm *.jpg *.bmp *.gif)")
if file_path:
img = cv2.imread(file_path)
results = model(img)
annotated_img = draw_keypoints(img.copy(), results)
self.display_image(annotated_img)
def open_video(self):
file_dialog = QFileDialog()
file_path, _ = file_dialog.getOpenFileName(self, "Open Video", "", "Videos (*.mp4 *.avi)")
if file_path:
self.cap = cv2.VideoCapture(file_path)
self.timer.start(30)
def open_camera(self):
self.cap = cv2.VideoCapture(0)
self.timer.start(30)
def update_frame(self):
ret, frame = self.cap.read()
if ret:
results = model(frame)
annotated_frame = draw_keypoints(frame.copy(), results)
self.display_image(annotated_frame)
else:
self.timer.stop()
self.cap.release()
def display_image(self, img):
qimg = QImage(img.data, img.shape[1], img.shape[0], QImage.Format.Format_BGR888)
pixmap = QPixmap.fromImage(qimg)
self.image_label.setPixmap(pixmap)
if __name__ == "__main__":
app = QApplication(sys.argv)
window = MainWindow()
window.show()
sys.exit(app.exec())
同学,构建一个完整的基于YOLOv8的人体姿势关键点检测系统,并使用PyQt6编写GUI界面支持图片、视频和摄像头实时检测。
以上文字及代码仅供参考。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









