






python情感分析识别 基于Python的情感分析识别系统,用于网络舆情分析 积极消极文本分析
积极消极文本分析 网络舆情分析系统
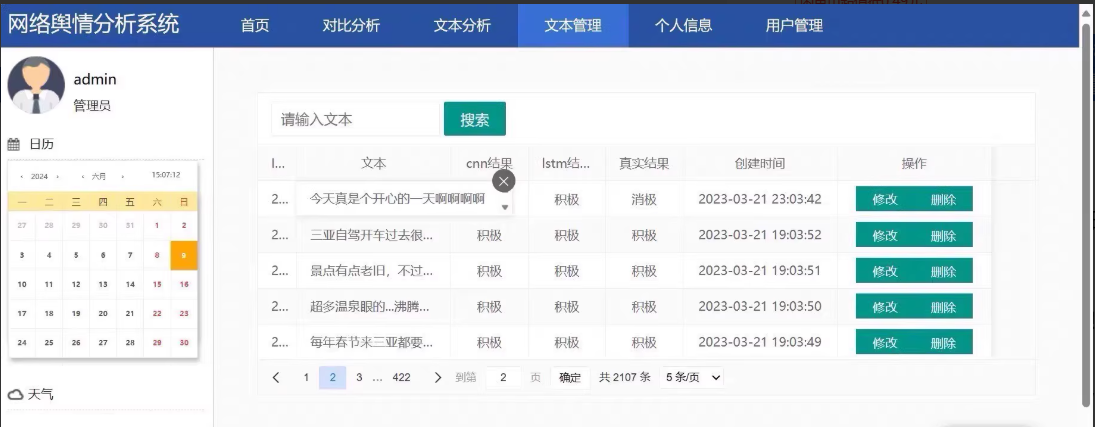
python情感分析识别 附数据量
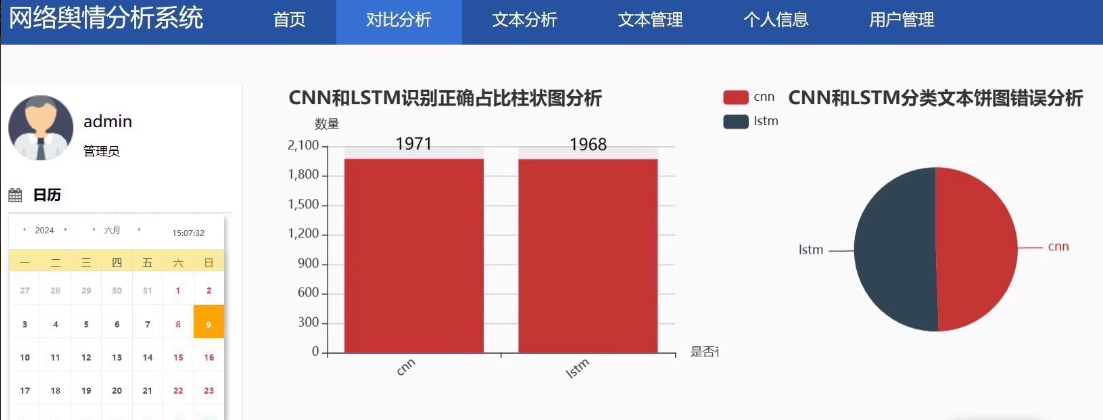
构建一个基于Python的情感分析识别系统,用于网络舆情分析,涉及文本预处理、模型训练和预测等多个步骤。以下是相关代码示例。
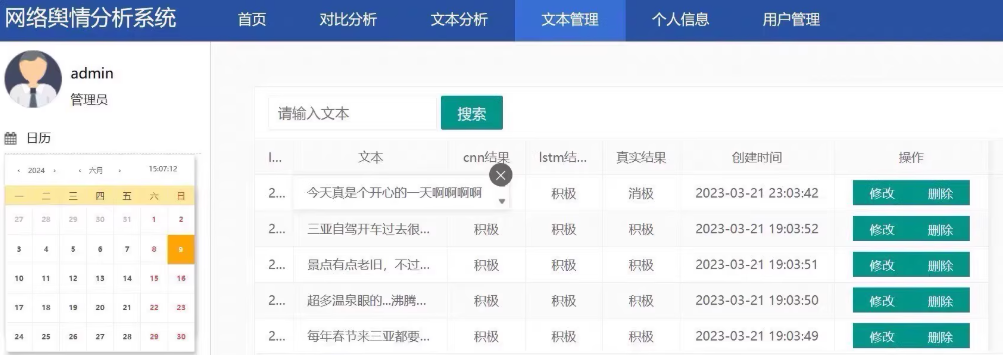
1. 环境配置
确保安装了必要的库:
pip install numpy pandas scikit-learn tensorflow keras nltk
2. 数据准备
假设你已经有了一个包含文本和标签的数据集,例如CSV文件sentiment_data.csv,其中包含两列:text和label(0表示消极,1表示积极)。
import pandas as pd
# 加载数据
data = pd.read_csv('sentiment_data.csv')
# 查看数据前几行
print(data.head())
3. 文本预处理
使用NLTK进行文本清洗和分词。
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
nltk.download('stopwords')
nltk.download('wordnet')
def preprocess_text(text):
# 转换为小写
text = text.lower()
# 移除标点符号和数字
text = re.sub(r'\W', ' ', text)
text = re.sub(r'\d', ' ', text)
# 分词
words = text.split()
# 去除停用词
stop_words = set(stopwords.words('english'))
words = [word for word in words if word not in stop_words]
# 词形还原
lemmatizer = WordNetLemmatizer()
words = [lemmatizer.lemmatize(word) for word in words]
return ' '.join(words)
data['cleaned_text'] = data['text'].apply(preprocess_text)
4. 特征提取
使用TF-IDF向量化文本。
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(max_features=5000)
X = vectorizer.fit_transform(data['cleaned_text']).toarray()
y = data['label']
5. 模型训练
使用Keras构建一个简单的CNN模型进行情感分析。
from keras.models import Sequential
from keras.layers import Dense, Embedding, Conv1D, GlobalMaxPooling1D
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
max_features = 5000
max_len = 500
X_train = pad_sequences(X, maxlen=max_len)
y_train = to_categorical(y, num_classes=2)
model = Sequential()
model.add(Embedding(max_features, 128, input_length=max_len))
model.add(Conv1D(128, 5, activation='relu'))
model.add(GlobalMaxPooling1D())
model.add(Dense(128, activation='relu'))
model.add(Dense(2, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=32, epochs=10, validation_split=0.2)
6. 预测与评估
对新文本进行情感分析预测。
def predict_sentiment(text):
cleaned_text = preprocess_text(text)
X_test = vectorizer.transform([cleaned_text]).toarray()
X_test = pad_sequences(X_test, maxlen=max_len)
prediction = model.predict(X_test)
sentiment = 'Positive' if np.argmax(prediction) == 1 else 'Negative'
return sentiment
new_text = "今天真是个开心的一天啊啊啊啊"
print(predict_sentiment(new_text))
7. 用户界面设计
使用Flask构建一个简单的Web界面。
from flask import Flask, request, render_template
app = Flask(__name__)
@app.route('/')
def home():
return render_template('index.html')
@app.route('/predict', methods=['POST'])
def predict():
text = request.form['text']
sentiment = predict_sentiment(text)
return render_template('result.html', text=text, sentiment=sentiment)
if __name__ == '__main__':
app.run(debug=True)
创建HTML模板templates/index.html和templates/result.html来展示输入表单和预测结果。
以上就是构建一个基于Python的情感分析识别系统的详细步骤和代码示例。你可以根据实际需求调整模型结构、优化超参数或改进用户界面,以进一步提升系统的性能和用户体验。
仅供参考。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









