






使用深度学习模型YOLOv8训练使用水面垃圾数据集 模型对水面及漂浮物垃圾进行检测 识别水面漂浮物13种垃圾
水面垃圾数据集

格式:yolo数据集格式 voc格式
类别:can bad fruit bottle glass bottle plastic box plastic bag milk box
leaf branch paper ball grass garbage
标注:labelimg
总共有3000+张标记图像,主要应用背景:水面垃圾检测
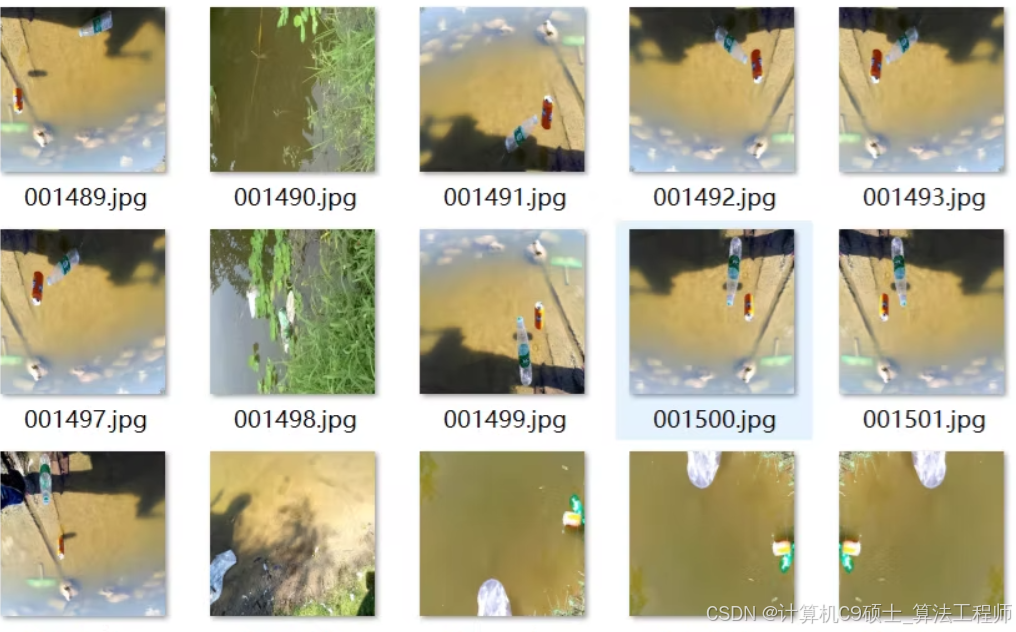
使用深度学习模型对水面垃圾进行检测,采用YOLOv8作为目标检测框架。由于你提到数据集已经提供了YOLO和VOC两种格式的标注文件,基于YOLO格式进行训练。以下是详细的步骤、关键文件及代码示例来指导你完成从准备数据集到训练模型的整个流程。
1. 数据集准备
假设你的数据集结构如下:
water_trash_detection/
├── images/
│ ├── train/
│ │ ├── img1.jpg
│ │ └── ...
│ ├── val/
│ │ ├── img1.jpg
│ │ └── ...
│ └── test/
│ ├── img1.jpg
│ └── ...
└── labels/
├── train/
│ ├── img1.txt
│ └── ...
├── val/
│ ├── img1.txt
│ └── ...
└── test/
├── img1.txt
└── ...
data_water_trash.yaml
data_water_trash.yaml 文件内容示例:
train: ./water_trash_detection/images/train/
val: ./water_trash_detection/images/val/
nc: 12 # 类别数量:can, bad fruit, bottle, glass bottle, plastic box, plastic bag, milk box, leaf, branch, paper, ball, grass, garbage
names: ['can', 'bad fruit', 'bottle', 'glass bottle', 'plastic box', 'plastic bag', 'milk box', 'leaf', 'branch', 'paper', 'ball', 'grass', 'garbage']
确保每个标签文件的内容符合YOLO格式,即每行包含一个对象的类别ID、中心点x, y坐标(归一化到0-1),宽度和高度(同样归一化)。
2. 安装依赖库
确保安装了必要的库:
pip install ultralytics opencv-python-headless tensorboard
3. 模型训练
创建一个Python脚本来开始训练过程。这里我们以YOLOv8为例说明如何训练模型。
训练脚本
from ultralytics import YOLO
def main_train():
# 加载预训练的YOLOv8n模型或从头开始定义模型
model = YOLO('yolov8n.yaml') # 或者直接加载预训练权重,如 'yolov8n.pt'
results = model.train(
data='./data_water_trash.yaml',
epochs=100, # 根据需要调整
imgsz=640,
batch=16,
project='./runs/detect',
name='water_trash_detection',
optimizer='SGD',
device='0', # 使用GPU编号
save=True,
cache=True,
verbose=True,
)
if __name__ == '__main__':
main_train()
4. 推理与结果可视化
训练完成后,我们可以利用训练好的模型对新图片进行预测,并将结果可视化。

推理脚本
import cv2
from PIL import Image
from ultralytics import YOLO
model = YOLO('./runs/detect/water_trash_detection/weights/best.pt')
def detect_objects(image_path):
results = model.predict(source=image_path)
img = cv2.imread(image_path)
for result in results:
boxes = result.boxes.numpy()
for box in boxes:
r = box.xyxy
x1, y1, x2, y2 = int(r[0]), int(r[1]), int(r[2]), int(r[3])
label_id = int(box.cls)
label = result.names[label_id]
confidence = box.conf
if confidence > 0.5: # 设置置信度阈值
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2) # 绘制矩形框
cv2.putText(img, f'{label} {confidence:.2f}', (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
return img
# 示例调用
result_image = detect_objects('your_test_image.jpg') # 确保测试图像路径正确
Image.fromarray(cv2.cvtColor(result_image, cv2.COLOR_BGR2RGB)).show() # 使用PIL显示图像
5. 可视化界面
为了监控训练过程,可以使用TensorBoard。在训练脚本中添加 tensorboard=True 参数,然后运行以下命令启动TensorBoard:
tensorboard --logdir runs/
然后在浏览器中访问 http://localhost:6006 查看训练进度和结果。
6. 运行步骤总结
- 数据集准备:确认数据集已按要求组织好,并创建
data_water_trash.yaml。 - 安装依赖:通过提供的命令安装所需的Python库。
- 训练模型:运行训练脚本开始训练过程。
- 推理与可视化:使用训练好的模型进行推理,并可视化结果。
- 监控训练:使用TensorBoard监控训练过程。
使用YOLOv8对水面垃圾检测数据集进行目标检测任务。请根据实际需求调整相关参数和代码。如果有任何问题或需要进一步的帮助,请随时提问!
此外,希望将其转换为YOLO格式,可以编写一个简单的脚本来实现这种转换。例如:
import xml.etree.ElementTree as ET
import os
def convert_voc_to_yolo(xml_file, classes):
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
yolo_lines = []
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
yolo_lines.append(f"{cls_id} {' '.join(map(str, bb))}")
txt_file = xml_file.replace('.xml', '.txt')
with open(txt_file, 'w') as f:
f.write('\n'.join(yolo_lines))
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
# 使用方法
classes = ['can', 'bad fruit', 'bottle', 'glass bottle', 'plastic box', 'plastic bag', 'milk box', 'leaf', 'branch', 'paper', 'ball', 'grass', 'garbage']
for xml_file in os.listdir('path/to/voc/annotations'):
if xml_file.endswith('.xml'):
convert_voc_to_yolo(os.path.join('path/to/voc/annotations', xml_file), classes)
这个脚本可以帮助你快速地将VOC格式的标注文件转换为YOLO格式,以


















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









