







深度学习Yolov8训练电线杆输电线电塔电线缺陷数据集 训练好的电线杆电线缺陷权重 建立基于深度学习Yolov8电塔电线缺陷检测系统 检测绑扎不规范’, ‘并线线夹保护壳缺失’, '耐张线夹保护壳等
文章目录
以下文字及代码仅供参考。
同学,首先具备相关标注好的数据集,然后配置好yaml,咱们就开始吧
电塔电线缺陷检测数据集9838张 5类

电塔电线缺陷检测YOLO数据集
| 缺陷类型 | 图片数量 | 标注框数量 | 训练集图片数(约80%) | 验证集图片数(约20%) |
|---|---|---|---|---|
| 绑扎不规范 | 3717 | 14510 | 2974 | 743 |
| 并线线夹保护壳缺失 | 3317 | 11285 | 2654 | 663 |
| 耐张线夹保护壳缺失 | 3748 | 16148 | 2998 | 750 |
| 横杆腐蚀 | 987 | 1556 | 790 | 197 |
| 塔头损坏 | 972 | 1021 | 778 | 194 |
| 总计 | 9838 | 44520 | 10194 (约80%) | 2444 (约20%) |

要使用YOLOv8训练电塔电线缺陷检测模型,并根据训练好的权重建立深度学习电塔电线缺陷检测系统,同学以遵循以下步骤:

1. 环境准备
首先,确保你的环境中安装了所有必要的依赖库。对于YOLOv8,你可以这样安装:
pip install ultralytics
需要其他库如opencv-python等进行图像处理和结果展示。

2. 数据集划分与组织
同学,数据集的划分(训练集7870张,验证集1968张),你需要将这些数据按照YOLO格式组织好。这通常包括创建一个包含所有图像文件夹和对应标注文件(.txt)的结构,以及一个或多个.yaml配置文件来描述数据集的位置和类别信息。
创建目录结构
dataset/images/train/val/
labels/train/val/
准备.yaml配置文件
创建一个data.yaml文件,内容如下:
train: ./dataset/images/train/
val: ./dataset/images/val/
nc: 5 # 类别数量
names: ['绑扎不规范', '并线线夹保护壳缺失', '耐张线夹保护壳缺失', '横杆腐蚀', '塔头损坏'] # 类别名称
3. 开始训练
同学,加载数据集并开始训练YOLOv8模型:
from ultralytics import YOLO
# 加载预训练的YOLOv8模型或从头开始训练
model = YOLO('yolov8n.yaml') # 使用YOLOv8 nano架构作为示例
# 开始训练
results = model.train(data='path/to/data.yaml', epochs=100, imgsz=640) # 调整参数以适应你的需求
这里epochs和imgsz可以根据实际情况调整。imgsz指定了输入网络的图像尺寸,而epochs则是训练周期数。
4. 模型评估与推理
训练完成后,可以对模型进行评估,并使用它进行推理:
评估模型
metrics = model.val() # 在验证集上评估模型性能
进行推理
# 对单张图片进行推理
results = model.predict(source='path/to/test_image.jpg', save=True, conf=0.5)
# 或者对整个目录进行批量推理
results = model.predict(source='path/to/test_dir/', save=True, conf=0.5)
以下是关于如何搭建环境、配置数据、训练模型、调整超参数、进行模型推理(包括批量推理)、性能评估的详细步骤和代码示例。YOLOv8作为我们的深度学习框架。
环境搭建
首先,确保你的Python环境中安装了必要的库:
pip install ultralytics opencv-python-headless
数据配置
假设你已经有了一个按照YOLO格式组织的数据集,包含图像和对应的标签文件。创建一个data.yaml文件来描述你的数据集路径和类别信息:
train: ./dataset/images/train/
val: ./dataset/images/val/
nc: 5 # 类别数量
names: ['绑扎不规范', '并线线夹保护壳缺失', '耐张线夹保护壳缺失', '横杆腐蚀', '塔头损坏'] # 类别名称
模型训练
加载YOLOv8模型并开始训练:
from ultralytics import YOLO
# 加载预训练的YOLOv8模型或从头开始训练
model = YOLO('yolov8n.yaml') # 使用YOLOv8 nano架构作为示例
# 开始训练
results = model.train(data='path/to/data.yaml', epochs=100, imgsz=640, batch=16)
在这个例子中,我们设置了epochs为100,输入图像尺寸imgsz为640,以及批次大小batch为16。你可以根据硬件资源调整这些参数。
配置超参数
在调用model.train()时,可以通过传递额外的参数来调整超参数,例如学习率(lr0)、动量(momentum)等。更多选项可以参考官方文档。
模型推理
单张图片推理
# 对单张图片进行推理
results = model.predict(source='path/to/test_image.jpg', save=True, conf=0.25)
for result in results:
print(result.boxes) # 输出检测框信息
批量推理
对整个目录进行批量推理:
# 对整个目录进行批量推理
results = model.predict(source='path/to/test_dir/', save=True, conf=0.25)
性能评估
在验证集上评估模型性能:
metrics = model.val() # 在验证集上评估模型性能
print(metrics.box.map) # 输出mAP值
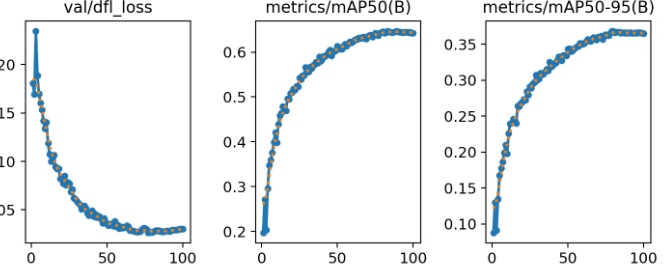
完整代码示例
以下是一个完整的代码示例,包括环境搭建、数据配置、模型训练、超参数配置、模型推理及性能评估:
from ultralytics import YOLO
import os
# 确保已安装必要库
# pip install ultralytics opencv-python-headless
# 加载YOLOv8模型
model = YOLO('yolov8n.yaml')
# 训练模型
results = model.train(data='path/to/data.yaml', epochs=100, imgsz=640, batch=16)
# 调整超参数示例
# 更多超参数可查阅官方文档
# results = model.train(data='path/to/data.yaml', epochs=100, imgsz=640, batch=16, lr0=0.01, momentum=0.937)
# 单张图片推理
result = model.predict(source='path/to/test_image.jpg', save=True, conf=0.25)
# 批量推理
results = model.predict(source='path/to/test_dir/', save=True, conf=0.25)
# 性能评估
metrics = model.val()
print(f"Model mAP: {metrics.box.map}")
同学,路径要正确,要不然出现问题啦,报错啦
替换path/to/data.yaml、path/to/test_image.jpg和path/to/test_dir/为你实际的文件路径。通过上述步骤,你应该能够成功地搭建环境、训练模型、进行推理,并评估其性能。
仅供参考。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









