






2025深度学习发论文&模型涨点之—— 遥感+多模态
遥感+多模态是当前遥感技术与人工智能交叉领域的重要研究方向之一,主要通过融合多种模态的数据(如光学、雷达、文本、音频等)来提升遥感信息的提取和理解能力。
随着遥感数据量和种类的爆炸式增长,传统的分析方法已难以满足精细地物感知的需求。多模态遥感大模型通过融合不同模态的数据,能够更全面地挖掘遥感大数据中的信息。例如,中国科学院空天信息创新研究院提出了多模态AI大模型对地观测的新范式,研发了高精度、全链路的多模态遥感大数据智能解译系统。
我整理了一些 遥感+多模态【论文+代码】合集,需要的同学公人人人号【AI创新工场】自取。
论文精选
论文1:
RS-GPT4V: A Unified Multimodal Instruction-Following Dataset for Remote Sensing Image Understanding
RS-GPT4V:用于遥感图像理解的统一多模态指令跟随数据集
方法
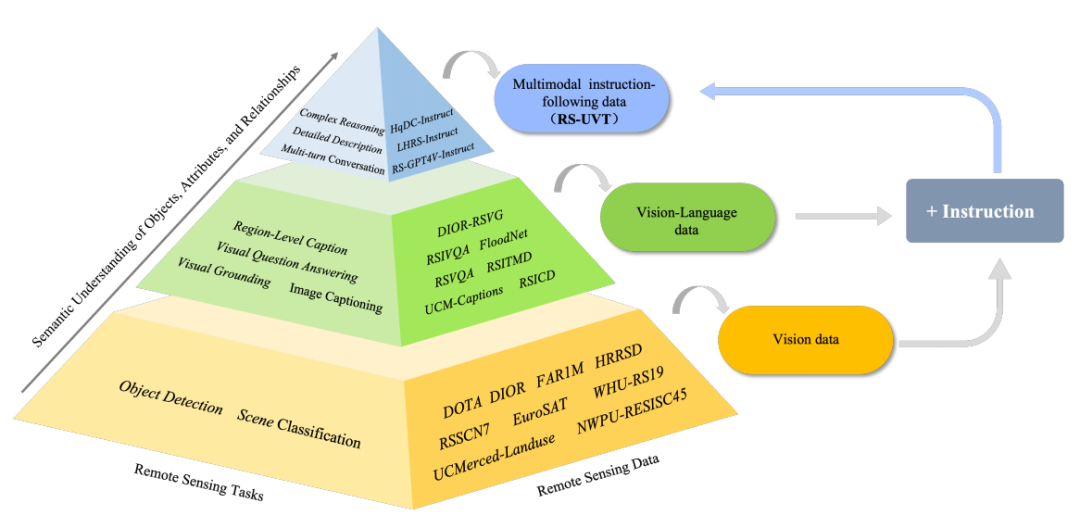
统一数据格式:采用(问题,答案)对作为统一格式,支持图像描述、视觉问答、复杂场景理解等多种任务。
指令-注释适配:将现有视觉语言数据集的注释转换为指令数据集,增强数据集的多样性和统一性。
指令-响应生成:利用GPT-4V生成详细的指令描述和响应,确保生成的指令具有足够的复杂性和多样性。
多轮对话和复杂推理:设计多轮对话和复杂推理任务,提升模型的推理能力。
创新点
任务统一性:首次提出一个统一的数据集支持多种遥感视觉语言任务,显著提升了模型的泛化能力。
复杂场景理解:通过分层指令描述方法,模型在复杂场景理解任务中的性能显著提升,例如在RS-GPT4V-Instruct数据集上的复杂推理任务中,得分从5.194提升到6.304。
多轮对话能力:支持多轮对话任务,提升了模型在复杂交互场景中的表现,例如在RS-GPT4V-Instruct数据集上的多轮对话任务中,得分从2.599提升到6.156。
数据质量和多样性:通过手动校正和高级模型生成,确保数据的高质量和多样性,显著提升了模型在多种任务中的表现。

论文2:
Towards a multimodal framework for remote sensing image change retrieval and captioning
面向遥感图像变化检索和描述的多模态框架研究
方法
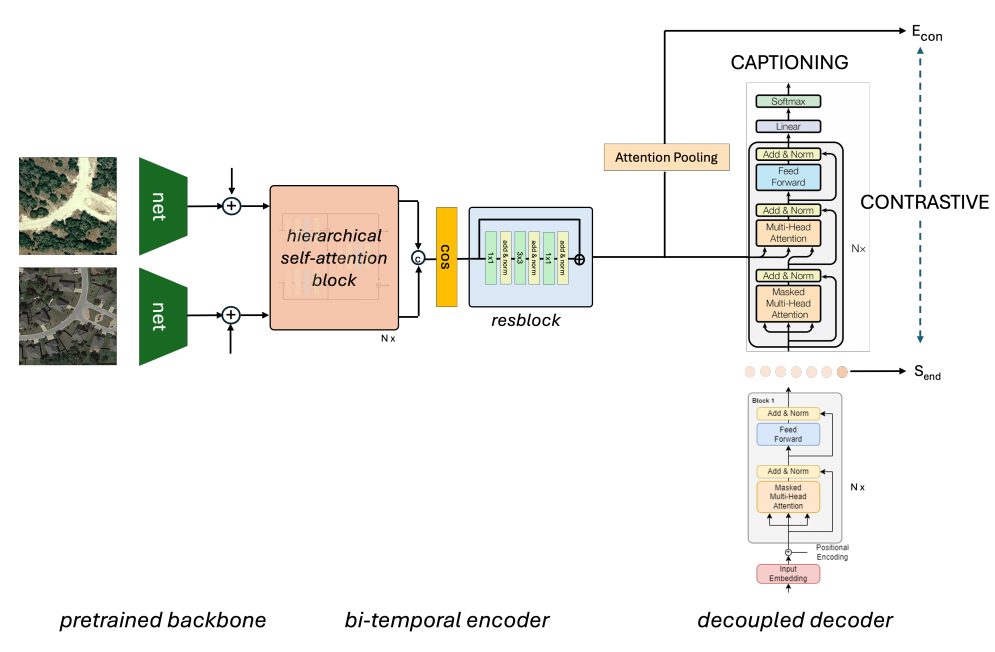
双时相图像编码器:采用预训练的双时相图像编码器,结合层次化注意力机制,将两幅图像的特征合并为单一表示。
对比学习:通过InfoNCE损失函数,联合优化视觉和文本编码器,实现图像对与文本描述之间的对比学习。
解码器设计:解码器分为单模态和多模态两部分,单模态部分仅编码文本输入,多模态部分结合文本和视觉特征生成描述。
虚假负样本处理:引入虚假负样本消除(FNE)和吸引(FNA)策略,解决对比学习中的虚假负样本问题。
创新点
多任务能力:首次提出一个模型同时处理双时相遥感图像的描述和文本-图像检索任务,显著提升了模型的多任务能力。
虚假负样本处理:通过FNA策略,模型在对比学习中的召回率(R@5)从60.92%提升到62.99%,同时保持较高的精确率(P@5)。
预训练模型的应用:采用Remote-CLIP作为预训练模型,显著提升了检索任务的性能,例如R@5从1.2%提升到2.85%。
对比学习的正向影响:对比学习不仅提升了检索性能,还对描述任务有正向影响,例如BLEU-1从69.38提升到82.34。

论文3:
Multimodal Fusion Transformer for Remote Sensing Image Classification
用于遥感图像分类的多模态融合Transformer
方法
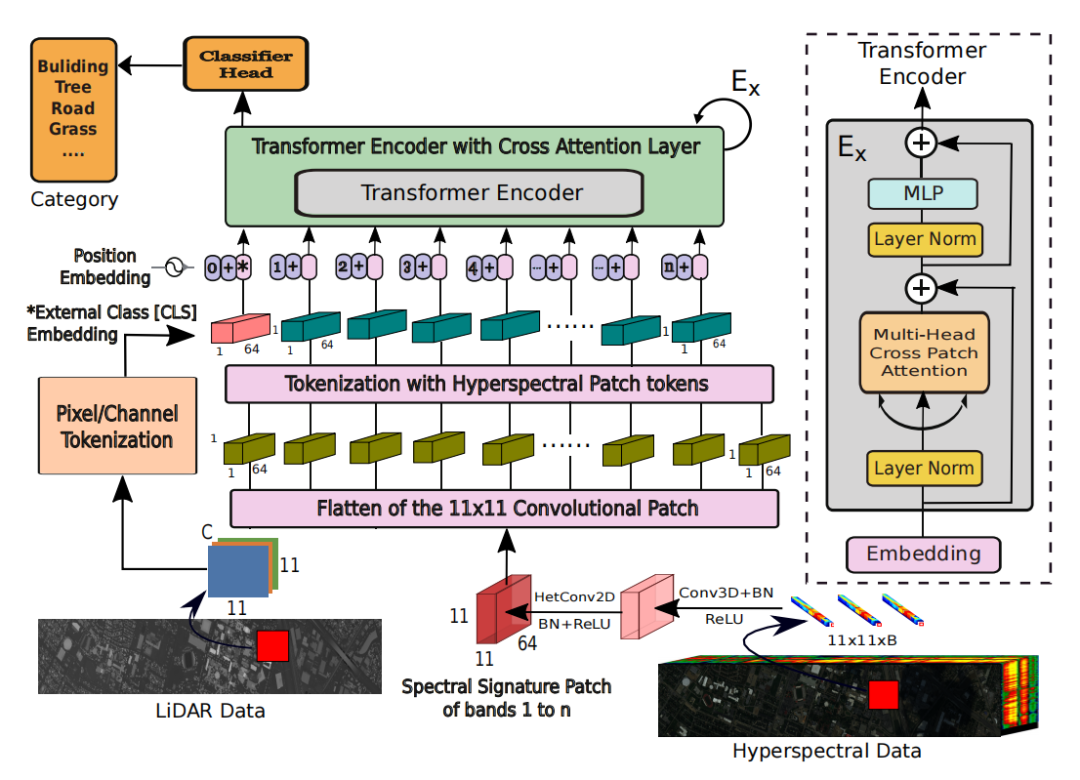
多模态融合Transformer(MFT):提出了一种新的多模态融合Transformer网络,用于高光谱图像(HSI)的土地覆盖分类。
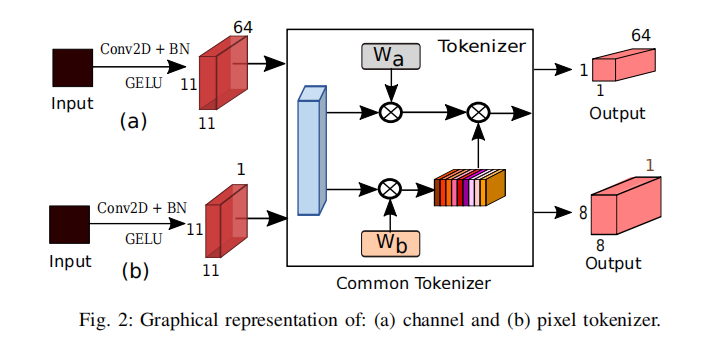
多头交叉补丁注意力(mCrossPA):引入多头交叉补丁注意力机制,将HSI与其他多模态数据(如LiDAR、MSI、SAR和DSM)结合,通过标记化生成类别(CLS)和HSI补丁标记。
特征学习与标记化:通过CNN提取HSI和LiDAR数据的特征,并将特征标记化为补丁标记,用于Transformer编码器的输入。
位置嵌入与Transformer编码器:为补丁标记添加位置嵌入,并通过Transformer编码器进行特征融合和分类。
创新点
多模态融合性能提升:通过引入多模态数据(如LiDAR、MSI、SAR和DSM),显著提升了遥感图像分类的性能。例如,在University of Houston数据集上,结合HSI和LiDAR数据时,OA(总体精度)提升了约5.33%,AA(平均精度)提升了约1.57%,κ系数提升了约0.59%。
mCrossPA机制:提出的多头交叉补丁注意力机制能够高效融合HSI和多模态数据的特征,显著优于传统方法。在MUUFL数据集上,结合HSI和LiDAR数据时,OA提升了约2.40%,AA提升了约0.48%,κ系数提升了约0.21%。
计算效率优化:通过避免传统Transformer中复杂的线性投影计算,MFT在保持高性能的同时减少了计算开销。
通用性与可扩展性:该方法不仅适用于HSI和LiDAR数据,还可以扩展到其他多模态数据(如MSI、SAR和DSM),在多个数据集上验证了其有效性。
论文4:
Mini-InternVL: A Flexible-Transfer Pocket Multimodal Model with 5% Parameters and 90% Performance
Mini-InternVL:一种轻量级多模态模型,仅用5%的参数实现90%的性能
方法
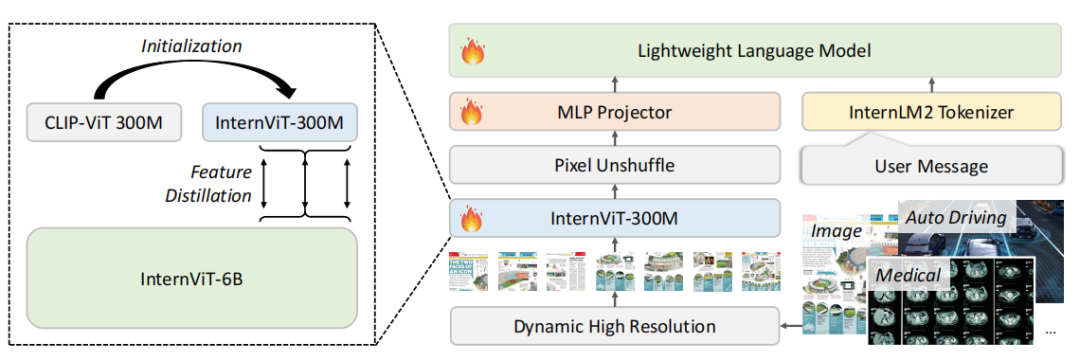
知识蒸馏:通过从InternViT-6B中进行知识蒸馏,将强大的视觉知识注入到轻量级视觉编码器InternViT-300M中。
多模态融合:将InternViT-300M与预训练的语言模型(如Qwen2-0.5B、InternLM2-1.8B和Phi-3Mini)结合,形成Mini-InternVL系列模型。
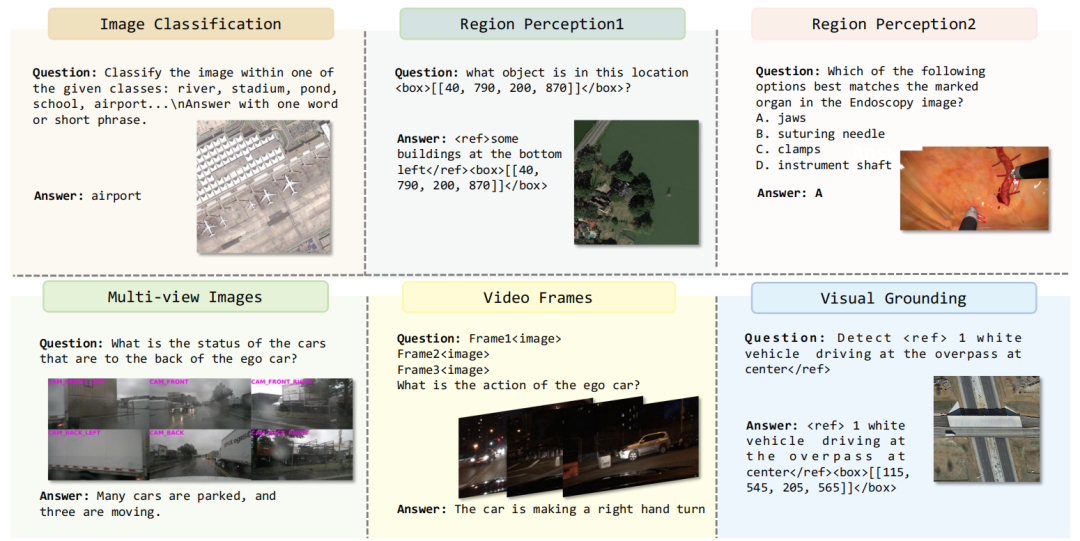
迁移学习框架:提出了一种统一的迁移学习框架,使模型能够高效地适应自动驾驶、医学图像和遥感等特定领域的下游任务。
动态分辨率输入:采用动态分辨率输入策略,提升模型对细粒度细节的捕捉能力。
创新点
性能提升:Mini-InternVL-4B在多模态基准测试中实现了与76B参数模型相当的90%性能,仅使用了5%的参数。例如,在MMBench数据集上,Mini-InternVL-4B的平均分数达到了72.8%,接近InternVL2-Llama3-76B的81.4%。
知识蒸馏效果:通过知识蒸馏,InternViT-300M继承了InternViT-6B的强大视觉知识,显著提升了模型在多模态任务中的表现。
迁移学习效率:通过统一的迁移学习框架,Mini-InternVL在特定领域的下游任务中表现出色,例如在自动驾驶任务中,Mini-InternVL-DA-4B的最终得分达到了0.5821,与InternVL4Drive-v2相当,但参数减少了约10倍。
轻量化与高效性:Mini-InternVL系列模型在保持高性能的同时,显著减少了参数规模和计算开销,使其更适合在资源受限的环境中部署。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









