






2025深度学习发论文&模型涨点之——神经网络求解PDE
基于神经网络的偏微分方程求解方法已成为计算数学与科学机器学习交叉领域的前沿研究方向。传统数值方法(如有限元、有限体积法)虽成熟但面临高维问题计算复杂度骤增("维度灾难")、复杂几何建模困难等固有局限。深度学习通过以下创新路径为PDE求解提供了新范式:
-
函数逼近理论视角:深度神经网络作为自适应基函数,通过Universal Approximation Theorem保证了对Sobolev空间函数的逼近能力(Yarotsky, 2017),其非线性表达能力显著优于传统谱方法。
-
无网格离散化:物理驱动神经网络(Physics-Informed Neural Networks, Raissi et al., 2019)通过自动微分构建微分算子,避免了传统方法的网格生成问题,特别适用于自由边界问题和移动边界问题。
-
高维突破:随机权重分配与傅里叶特征映射(FNO, Li et al., 2021)的结合,使神经网络在求解Boltzmann方程等高维PDE时计算复杂度仅多项式增长。
我整理了一些神经网络求解PDE【论文+代码】合集,需要的同学公人人人号【AI创新工场】发525自取。
论文精选
论文1:
[Nature子刊] Encoding physics to learn reaction-diffusion processes
编码物理知识以学习反应扩散过程
方法
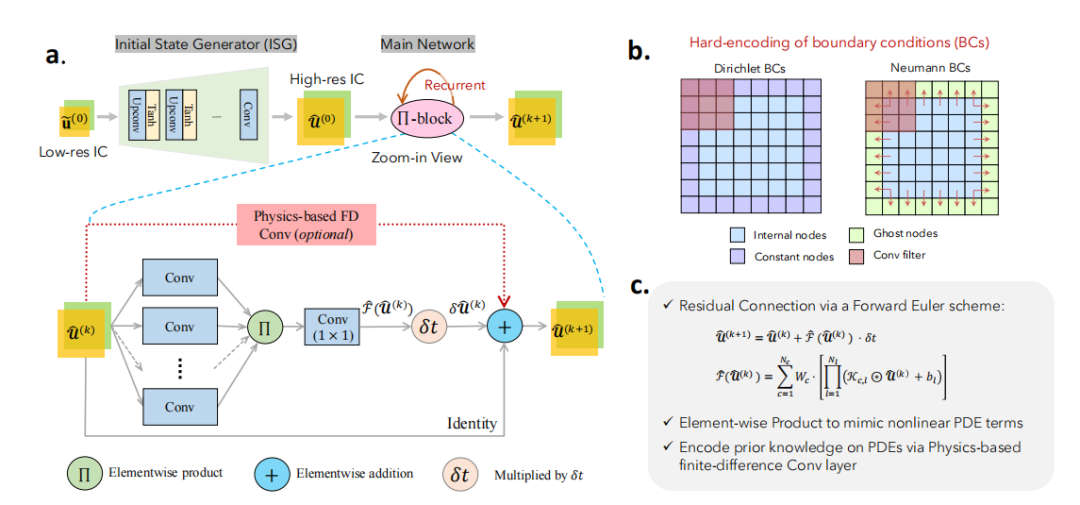
Physics-encoded Recurrent Convolutional Neural Network (PeRCNN):提出了一种新的深度学习框架PeRCNN,将物理知识编码到网络结构中,用于学习稀疏数据下的时空动力学。
Π-block(乘积块):网络的核心是Π-block,通过多个并行卷积层的输出进行逐元素乘法操作,用于捕捉系统的非线性动态。
时间步进与卷积网络结合:利用前向欧拉时间步进方案,将时间演化与卷积网络相结合,实现对反应扩散系统的时空预测。
边界条件编码:通过卷积操作对边界条件进行编码,确保网络预测严格满足物理边界条件。
创新点
物理知识编码:将已知的物理结构(如扩散项、边界条件)直接编码到网络架构中,避免了传统方法中通过惩罚项软约束物理定律的方式,显著提高了模型的准确性和可解释性。
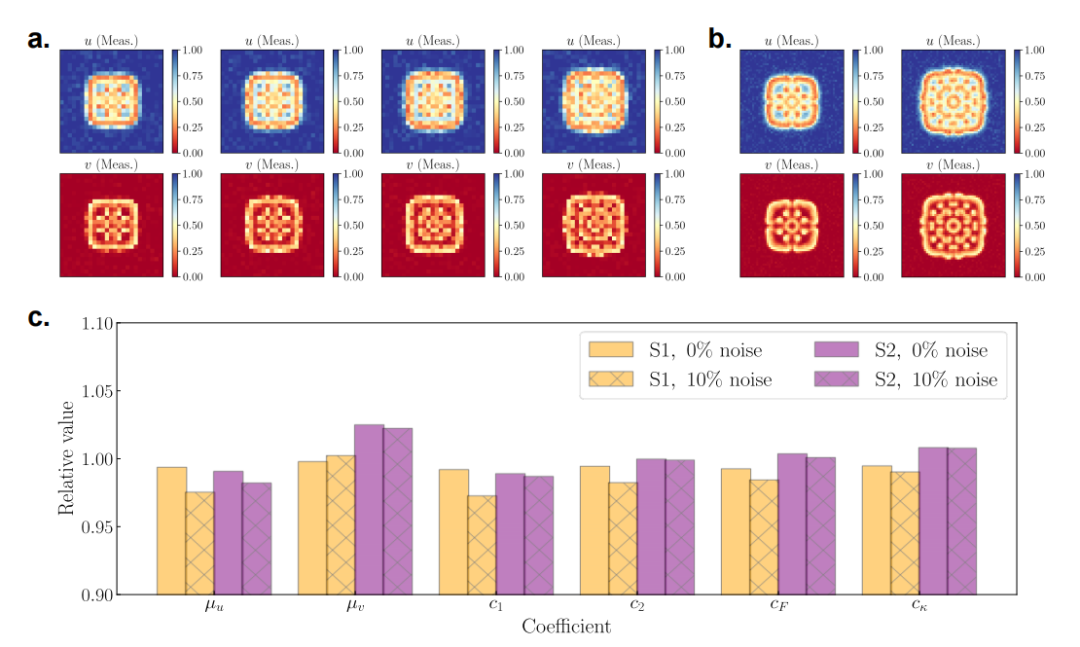
数据驱动建模能力:在仅有少量低分辨率和噪声数据的情况下,能够重建高分辨率的时空动力学,展示了强大的数据驱动建模能力。
性能提升:在多个反应扩散系统的测试中,PeRCNN在预测精度、外推能力和泛化能力上均优于现有的ConvLSTM和PINN方法。例如,在2D FitzHugh-Nagumo系统中,PeRCNN的均方根误差(RMSE)仅为1.2×10⁻⁴,而ConvLSTM和PINN分别为5.1×10⁻⁴和8.7×10⁻³。
可解释性:通过符号计算可以从训练好的PeRCNN模型中提取出明确的物理方程形式,使模型不仅能够预测,还能解释其背后的物理机制。
逆问题求解:能够通过将未知系数作为可训练变量,从有限的测量数据中准确识别出反应扩散方程中的未知参数,如在2D Gray-Scott系统中,即使在10%的噪声水平下,平均绝对相对误差(MARE)仅为1.61%。
论文2:
[Nature子刊] A computational framework for neural network-based variational Monte Carlo with Forward Laplacian
基于神经网络的变分蒙特卡洛方法的计算框架:前向拉普拉斯
方法
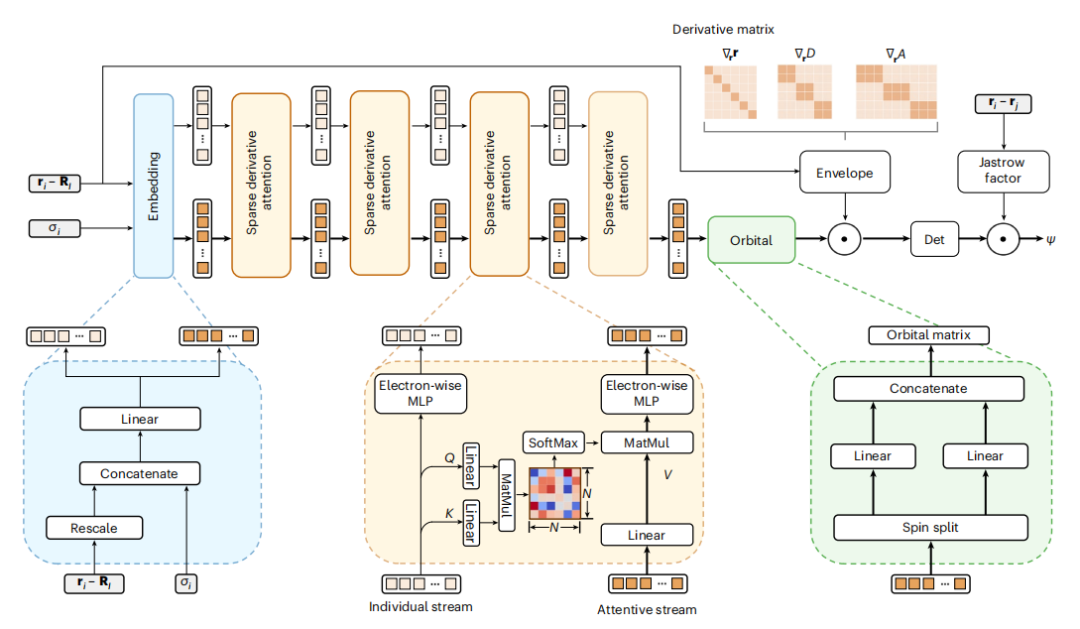
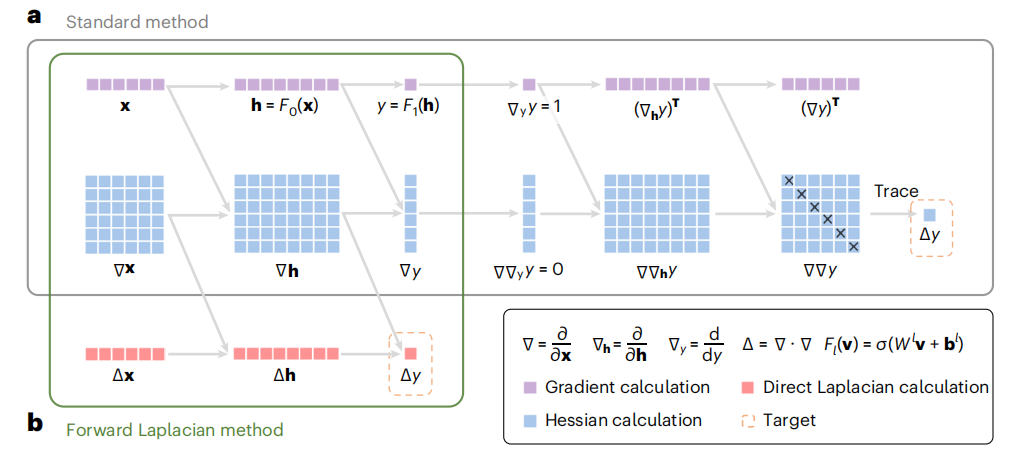
前向拉普拉斯框架(Forward Laplacian):提出了一种新的计算框架,直接通过前向传播过程计算神经网络的拉普拉斯算子,避免了传统的基于海森矩阵的计算方法。
稀疏导数矩阵优化:利用前向拉普拉斯框架中的稀疏性,优化了中间导数矩阵的存储和计算,显著提高了计算效率。
LapNet网络结构:设计了一种新的神经网络结构LapNet,通过引入稀疏导数注意力(SDA)块,进一步提高了前向拉普拉斯方法的效率。
波函数优化:基于Slater-Jastrow-Backflow ansatz,通过变分蒙特卡洛方法优化波函数,以最小化能量作为损失函数。
创新点
计算效率提升:与传统方法相比,前向拉普拉斯框架将拉普拉斯算子的计算成本大约降低了50%,例如在苯二聚体系统中,训练时间从约10,000 GPU小时缩短到1,800 GPU小时,加速比达到6倍。
大规模系统适用性:该方法能够扩展到更大的系统,如含有116个电子的尿嘧啶二聚体,而传统方法在处理如此大规模系统时面临巨大挑战。
能量估计精度:LapNet在估计绝对能量和相对能量方面表现出色,与实验结果和金标准计算方法(如CCSD(T))的平均差异仅为0.7 mHa,达到了化学精度。
性能提升:LapNet在多个分子系统上的测试中,不仅在能量估计上表现出色,还在离子化势、反应势垒高度和非共价相互作用能量的估计上达到了化学精度,例如在14个不同反应的势垒高度估计中,12个达到了化学精度。
论文3:
Recent advances in metasurface design and quantum optics applications with machine learning, physics-informed neural networks, and topology optimization methods
机器学习、物理信息神经网络和拓扑优化方法在超表面设计和量子光学应用中的最新进展
方法
机器学习方法:利用机器学习技术从大量已知数据集中学习模型变量与光学属性之间的复杂关系,以优化超表面结构。
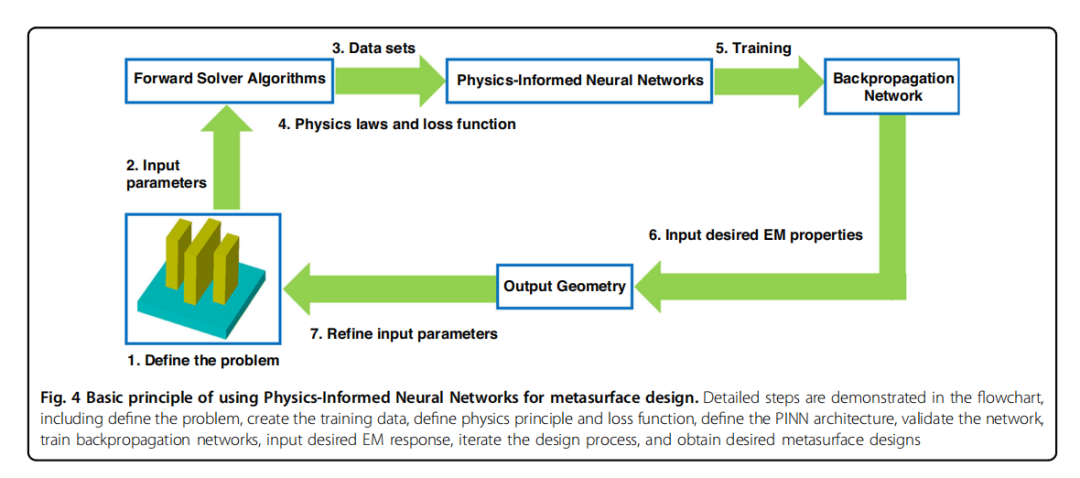
物理信息神经网络(PINN):将物理定律(如麦克斯韦方程)纳入神经网络训练过程中,通过损失函数中的物理约束来提高预测精度。
拓扑优化方法:结合光学理论(如严格耦合波分析,RCWA)和优化算法(如自动微分),在给定空间内优化结构的大小和形状。
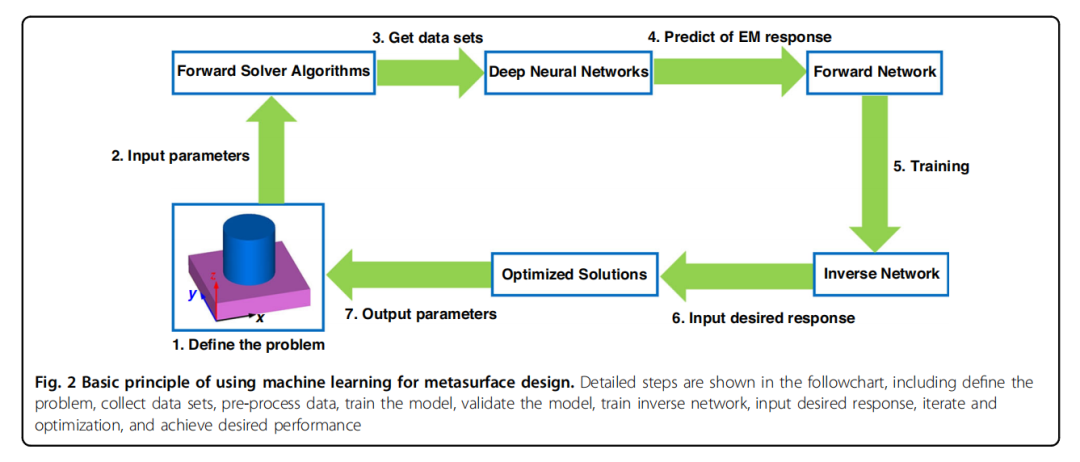
创新点
设计效率提升:与传统方法相比,机器学习方法显著减少了超表面设计的计算时间,例如在某些情况下,训练时间从数小时缩短到数分钟。
精度提升:物理信息神经网络通过引入物理约束,能够使用更少的数据样本训练出具有更好泛化能力的网络,提高了超表面设计的精度。
自由度增加:拓扑优化方法提供了更高的设计自由度,允许在空间中任意排列结构,从而设计出更复杂和高效的超表面结构。
性能提升:在量子光学应用中,通过这些智能设计方法优化的超表面能够实现更高的效率和更好的性能,例如在量子纠缠分发和量子态操控中表现出色。
应用拓展:这些方法不仅适用于超表面设计,还可以扩展到其他光学器件的设计,如光子晶体、光学腔和集成光子电路。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









