






2025深度学习发论文&模型涨点之—— 可解释聚类
随着大数据驱动的决策范式在交叉学科中的深度渗透,聚类分析作为无监督学习的核心方法,其可解释性已成为制约算法可信度与领域应用价值的关键瓶颈。
传统聚类模型(如K-means、层次聚类)虽具有计算高效性优势,但普遍存在"黑箱化"特质,难以满足医疗诊断、金融风控等高可靠性场景对过程透明性与语义可追溯性的刚性需求。
近年来,可解释聚类研究通过融合约束优化、概念生成与可视化推理等多模态技术路径,试图构建兼具统计鲁棒性与认知相容性的新型分析框架。
我整理了一些 可解释聚类【论文+代码】合集,需要的同学公人人人号【AI创新工场】发525自取。
论文精选
论文1:
ExKMC: Expanding Explainable k-Means Clustering
ExKMC:可扩展的可解释k均值聚类
方法
决策树扩展:提出了一种新的可解释k均值聚类算法ExKMC,通过扩展决策树的叶子数量来在可解释性和聚类准确性之间进行权衡。
代理成本:引入了一个基于参考中心的代理成本,用于高效地扩展树,并为每个叶子分配聚类标签。
迭代优化:使用Iterative Mistake Minimization(IMM)算法构建初始决策树,然后逐步增加叶子数量以优化聚类结果。
动态规划:通过动态规划技术优化计算过程,减少运行时间。
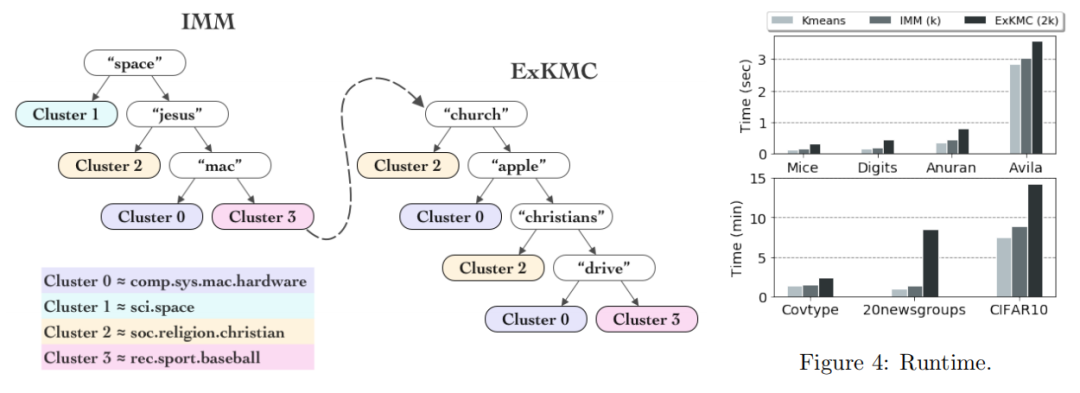
创新点
可扩展性与准确性:通过扩展决策树的叶子数量,ExKMC能够在保持可解释性的同时显著提高聚类的准确性。实验表明,使用2k到4k个叶子时,ExKMC的聚类成本能够接近标准k均值聚类成本的1%以内。
效率提升:通过使用代理成本而不是直接计算k均值成本,ExKMC在运行时间上比传统方法快1.5到2倍,尤其是在处理大型数据集时。
理论保证:证明了随着叶子数量k′的增加,代理成本是非增的,从而在理论上支持了可解释性和准确性之间的权衡。
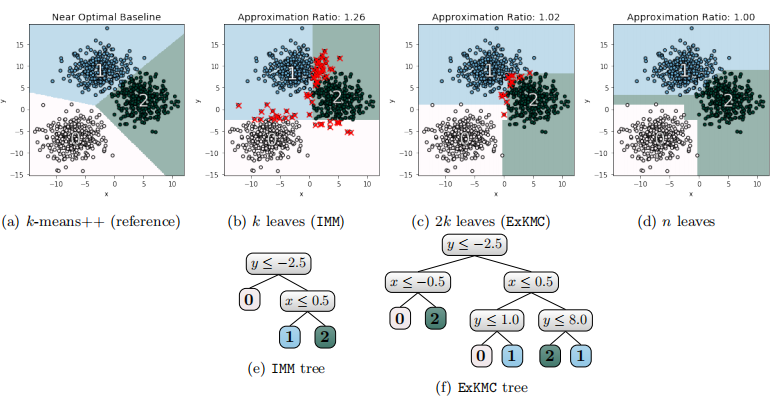
论文2:
Fast and explainable clustering based on sorting
基于排序的快速且可解释的聚类方法
方法
排序与聚合:通过沿数据点的第一主成分排序,然后使用贪婪聚合技术将数据点分组。
合并阶段:使用基于距离或密度的标准将聚合后的组合并为簇。
参数控制:通过两个标量参数(聚合距离和最小簇大小)控制聚类过程。
异常值处理:提供两种处理异常值的选项,包括重新分配到较大簇或单独标记。
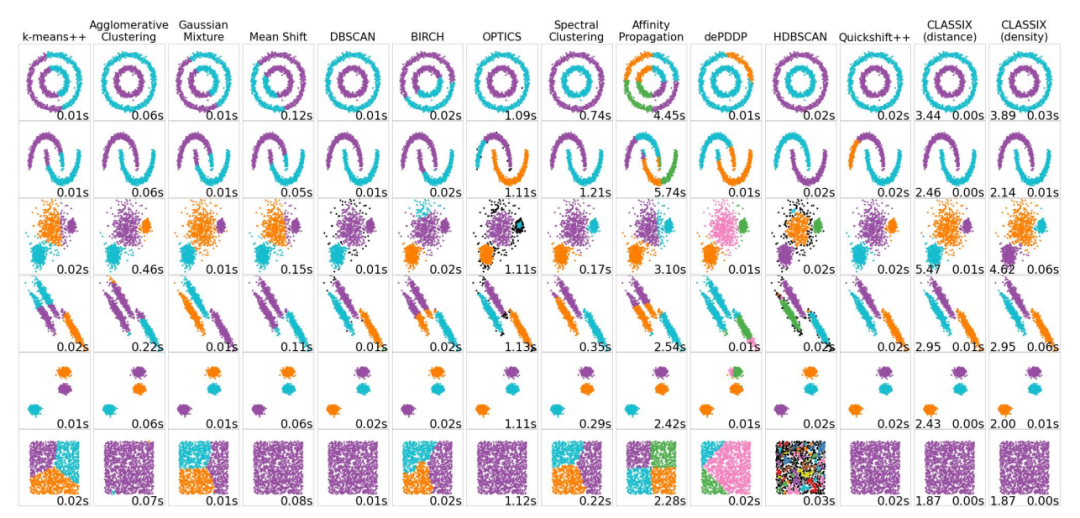
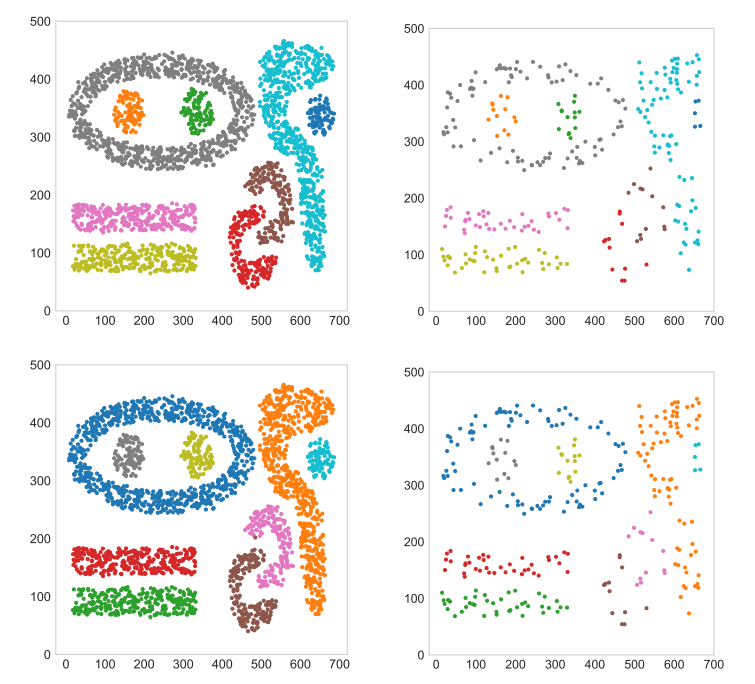
创新点
线性复杂度:通过排序减少了距离计算的数量,使得算法在实践中接近线性时间复杂度,比传统方法快2到3倍。
可解释性:算法的简单性使得聚类结果易于解释,能够生成直观的聚类解释。
性能提升:在多个真实和合成数据集上,CLASSIX的聚类质量与k-means++相当,但在运行时间上快1到2个数量级。
参数调整:参数调整相对简单,且在不同数据集上表现出良好的鲁棒性。
论文3:
Detection of extragalactic Ultra-Compact Dwarfs and Globular Clusters using Explainable AI techniques
利用可解释人工智能技术检测河外超致密矮星系和球状星团
方法
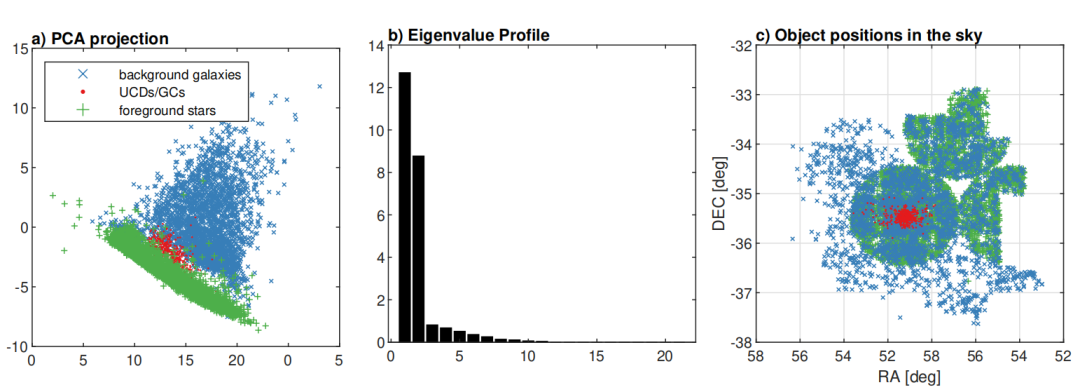
机器学习模型训练:使用Fornax星系团的多波段成像数据(u、g、r、i、J和Ks六个滤波器)训练模型,以区分超致密矮星系(UCDs)和球状星团(GCs)与前景恒星和背景星系。
类别不平衡处理:采用合成少数类过采样技术(SMOTE)和边界SMOTE(Borderline-SMOTE)来处理训练数据的类别不平衡问题。
分类器比较:比较了两种分类器——局部广义矩阵学习矢量量化(LGMLVQ)和随机森林(RF),评估其在检测UCDs/GCs方面的性能。
特征重要性分析:通过LGMLVQ和RF方法分析特征维度对分类的重要性,识别出对分类问题最有信息量的特征。
创新点
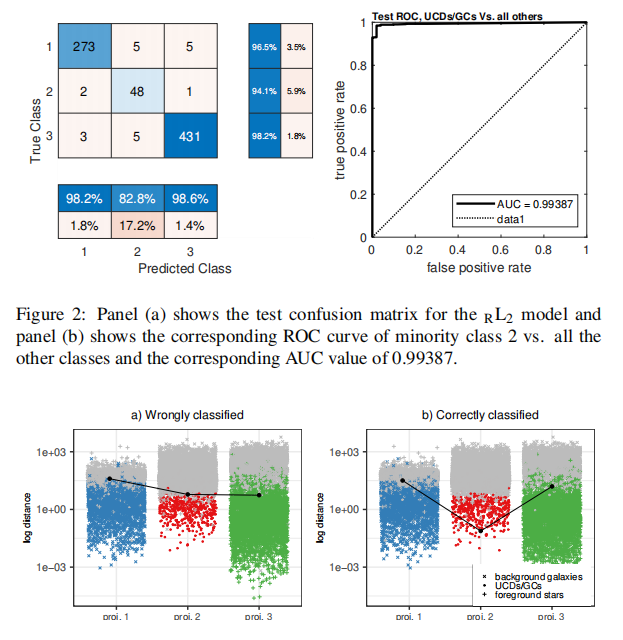
高精度分类:LGMLVQ和RF方法均能以超过93%的精确度和召回率识别UCDs/GCs。
特征重要性识别:发现角尺寸特征(如FWHM*g、FWHM*i等)对分类问题更为重要,尽管传统上认为u-i和i-Ks颜色指数是最重要的,但实验结果显示g-r等颜色特征更具信息量。
可解释性增强:LGMLVQ方法不仅提供了高精度的分类结果,还允许进一步解释模型的可解释性,包括特征重要性、类别代表样本和非线性可视化。
性能提升:通过使用SMOTE技术,UCDs/GCs类别的召回率提高了3.3%,尽管纯度略有下降,但这是可以接受的权衡。
论文4:
Goal-Driven Explainable Clustering via Language Descriptions
基于目标驱动和语言描述的可解释聚类
方法
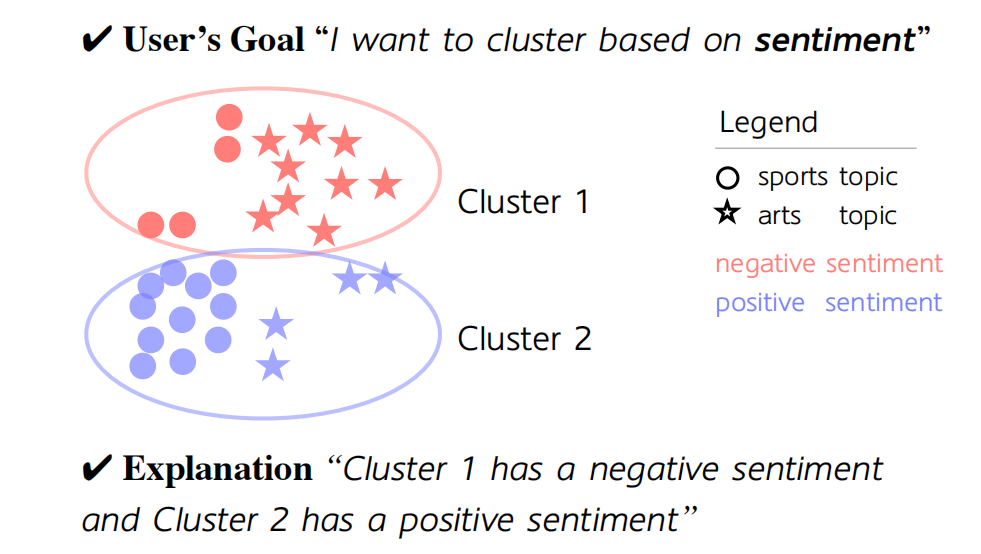
目标驱动聚类(GOALEX):提出了一种新的任务表述,将用户目标和聚类解释均表示为自由形式的语言描述。
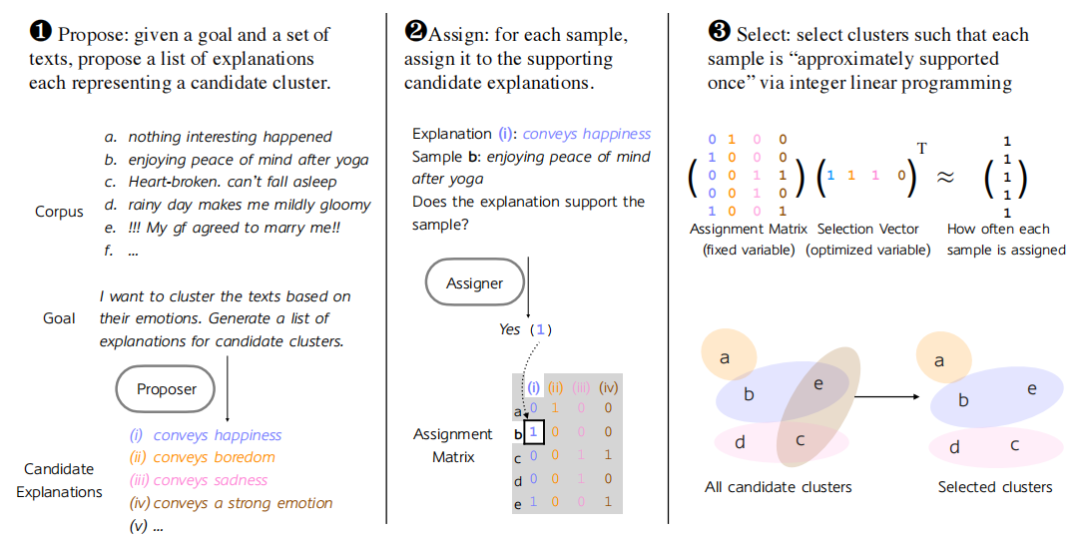
Propose-Assign-Select(PAS)算法:通过语言模型生成候选聚类的解释列表,然后根据解释将样本分类到聚类中,并使用整数线性规划选择一组候选聚类,以覆盖大多数样本并最小化重叠。
语言模型提示:在提案阶段,通过提示语言模型生成与目标相关的解释;在分配阶段,通过语言模型确定每个样本是否支持某个解释。
整数线性规划:在选择阶段,通过整数线性规划优化聚类选择,确保每个样本大致只被支持一次。
创新点
目标驱动聚类:首次提出基于用户目标的聚类方法,能够根据用户指定的目标(如情感、主题等)生成聚类和解释。
性能提升:在自动评估中,PAS方法在恢复已知聚类方面与传统方法相当,同时提供了准确的解释。在目标驱动的非主题聚类任务中,PAS的性能显著优于传统方法(如LDA和Instructor)。
解释准确性:在人类评估中,PAS的解释准确性达到80%,显著高于LDA(56%)和Instructor(71%)。
目标相关性:PAS的解释与用户目标的相关性更高,显著优于LDA和Instructor(p值均小于0.05)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









