






1.有十个地址信号引脚的内存IC(集成电路)可以指定的地址范围是多少?
2.高级编程语言中的数据类型表示的是什么?
3.在32位内存地址的环境中,指针变量的长度是多少位?
4.与物理内存有着相同构造的数组的数据类型长度是多少?
5.用LIFO方式进行数据读写的数据结构称为什么?
6.根据数据的大小链表分叉成两个方向的数据结构称为什么?
1.用二进制数来表示的0000000000~1111111111(用十进制数来表示的话是0~1023)
2.占据内存区域的大小和存储在该内存区域的数据类型
3. 32位
4.1字节
5.栈
6.二叉查找树(binary search tree)
解析···
1. 地址信号引脚是十个时表示2=1024个地址。
2. 例如,C语言数据类型中的short类型,它表示的就是占据2字
节的内存区域,并且存储整数。
3. 指针指的是用于存储内存地址的变量。
4.物理内存是以字节为单位进行数据存储的。
5.栈是一种后入先出(LIFO=Last In First Out)式的数据结构。
6.二叉查找树指的是从节点分成两个叉的树状数据结构。
计算机是进行数据处理的设备,而程序表示的就是处理顺序和数据结构。由于处理对象数据是存储在内存和磁盘上的,因此程序必须能自由地使用内存和磁盘。
内存实际上是一种名为内存IC的电子元件。虽然内存IC包括DRAM、SRAM、ROM 等多种形式,但从外部来看,其基本机制都是一样的。内存IC中有电源、地址信号、数据信号、控制信号等用于输入输出的大量引脚(IC的引脚),通过为其指定地址(address),来进行数据的读写。
由此可见,内存IC的物理机制实质上是很简单的。总体来讲,内存IC内部有大量可以存储8位数据的地方,通过地址指定这些场所,之后即可进行数据的读写。

指针也是一种变量,它所表示的不是数据的值,而是存储着数据的内存的地址。通过使用指针,就可以对任意指定地址的数据进行读写。虽然前面所提到的假想内存IC中仅有10位地址信号,但大家在Windows 计算机上使用的程序通常都是32位(4字节)的内存地址。这种情况下,指针变量的长度也是32位。
数组是指多个同样数据类型的数据在内存中连续排列的形式。作为数组元素的各个数据会通过连续的编号被区分开来,这个编号称为索引(index)。指定索引后,就可以对该索引所对应地址的内存进行读写操作 。而索引和内存地址的变换工作则是由编译器自动实现的。

栈和队列,都可以不通过指定地址和索引来对数组的元素进行读写。需要临时保存计算过程中的数据、连接在计算机上的设备或者输入输出的数据时,都可以通过这些方法来使用内存。如果每次保存临时数据都需指定地址和索引,程序就会变得比较麻烦,因此要加以改进。
栈和队列的区别在于数据出入的顺序是不同的。在对内存数据进行读写时,栈用的是LIFO(Last Input First Out,后入先出)方式,而队列用的则是FIFO(First Input First Out,先入先出)方式。如果我们在内存中预留出栈和队列所需要的空间,并确定好写入和读出的顺序,就不用再指定地址和索引了。
如果要在程序中实现栈和队列,就需要以适当的元素数来定义一个用来存储数据的数组,以及对该数组进行读写的函数对。当然,在这些函数的内部,对数组的读写会涉及索引的管理,但从使用函数的角度来说,就没有必要考虑数组及索引了。
队列这一方式也称为排队。排队指的是买车票时在自动售票机前等候的队列等。排队时,站在最前面的乘客先买票,购买后率先从队列中走出来。当随机前来的购票乘客数量和自动售票机的处理速度不相符时,排队能起到很好的缓冲作用。程序中也是如此,为了协调好数据输入和处理时机间的关系,采用类似于排队的机制是很方便的。在内存上,实现这种机制的方式就是队列。当我们需要处理通讯中发送的数据时,或由同时运行的多个程序所发送过来的数据时,会用到这种对队列中存储的不规则数据进行处理的方法。
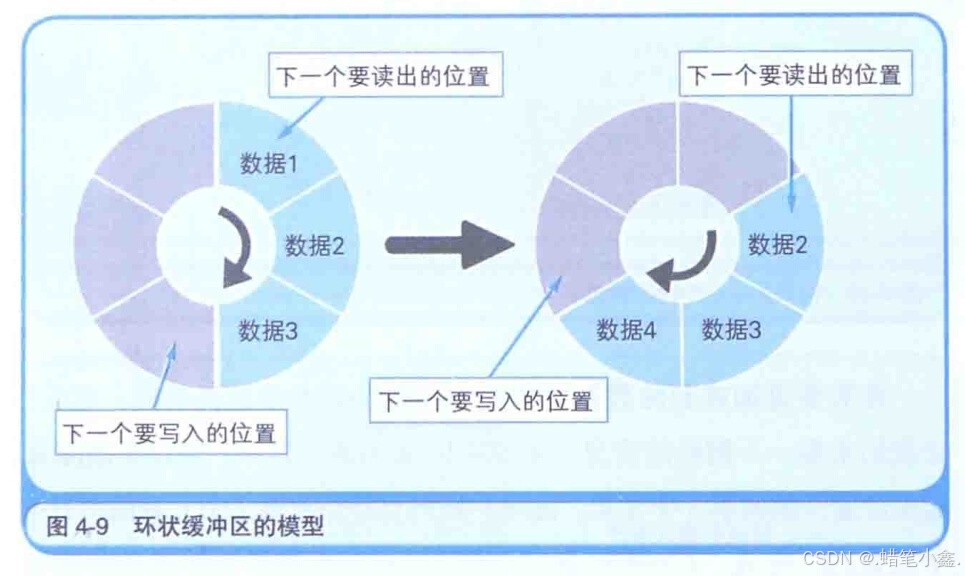
队列一般是以环状缓冲区(ring buffer)的方式来实现。也就是本章标题中所说的“熟练使用有棱有角的内存”。例如,假设我们要用有6个元素的数组来实现一个队列。这时可以从数组的起始位置开始有序地存储数据,然后再按照存储时的顺序把数据读出。在数组的末尾写入数据后,后一个数据就会被写入数组的起始位置(此时数据已经被读出所以该位置是空的)。这样,数组的末尾就和开头连接了起来,数据的写入和读出也就循环起来了。
链表和二叉查找树,都是不用考虑索引的顺序就可以对数组元素进行读写的方式。通过使用链表,可以更加高效地对数组数据(元素)进行追加和删除处理。而通过使用二叉查找树,则可以更加高效地对数组数据进行检索。
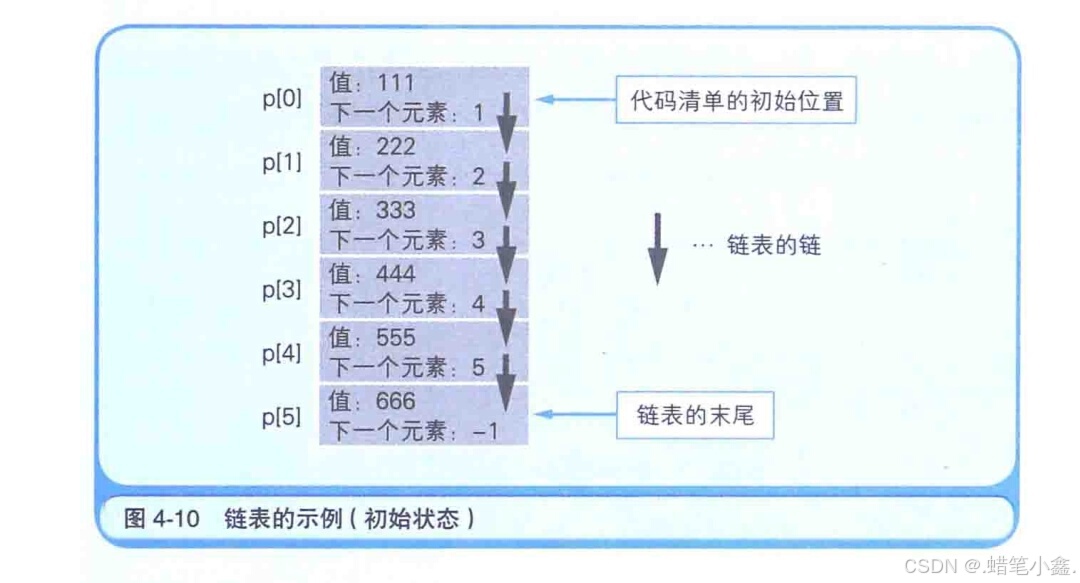
如果不使用链表数组,那么中途删除或追加元素时,其后的元素就必须要全部移动。
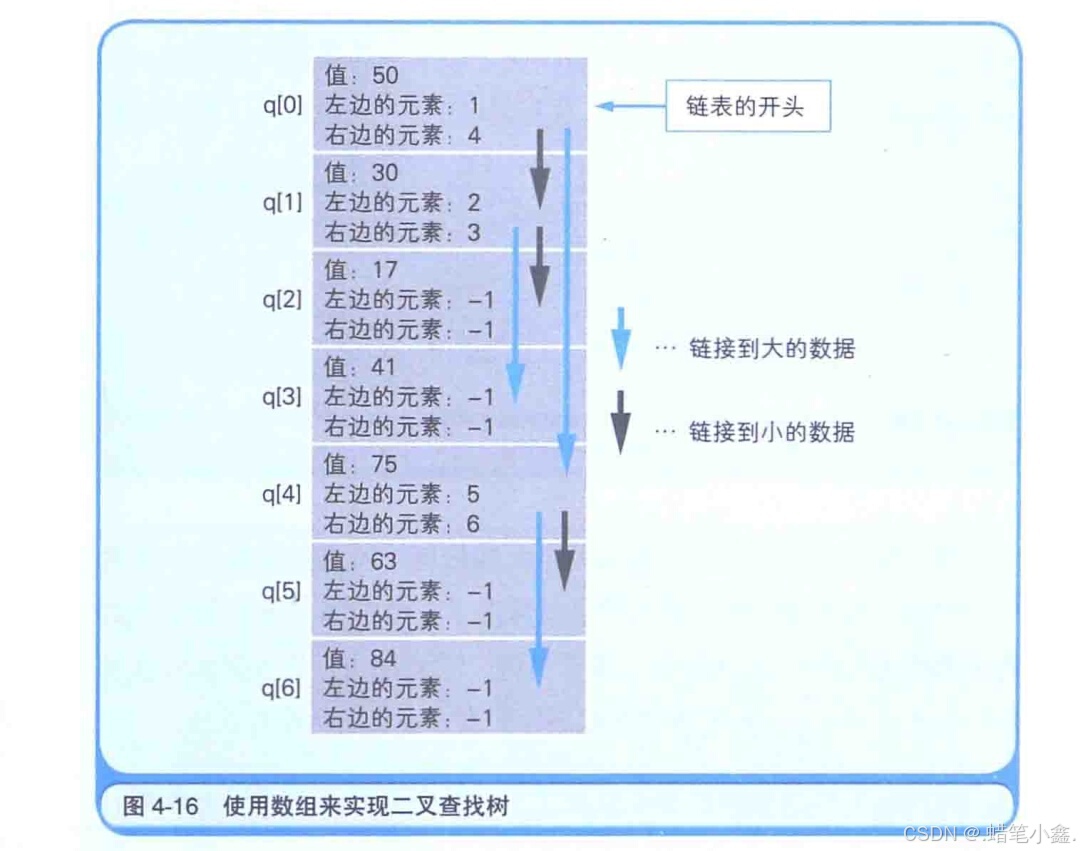
二叉查找树 是指在链表的基础上往数组中追加元素时,考虑到数据的大小关系,将其分成左右两个方向的表现形式。例如,假设我们事先把50这个值保存到了数组中。那么,如果接下来的值比先前保存的数值大的话,就要将其放到右边,反之如果小的话就放在左边。但实际的内存并不会分成两个方向,这是在程序逻辑上实现的。
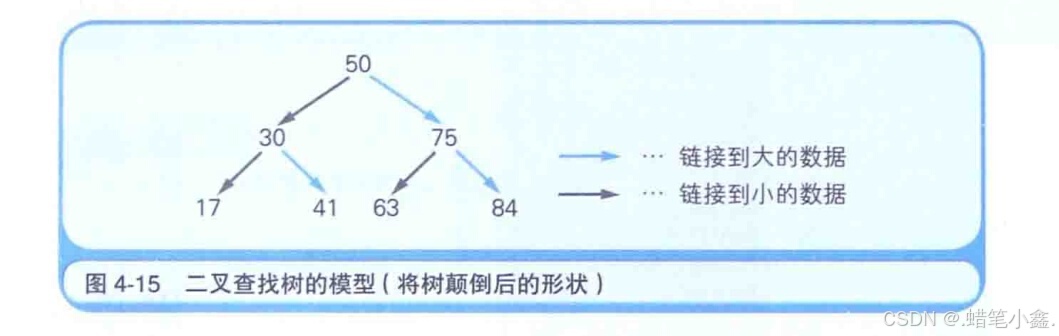
使用二叉查找树的便利之处在于可以使数据的搜索等更有效率。在使用一般的数组时,必须从数组的开头按照索引顺序来查找目标数据。而使用二叉查找树时,当目标数据比现在读出来的数据小时就可以转到左侧,反之目标数据较大时即可转到链表的右侧,这样就加快了找到目标数据的速度。

















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









