






从原型到企业级genAI:Informatica和亚马逊云
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, 生成式AI, CLAIRE, Enterprise Context, Metadata Intelligence, Data Quality, Governance Security, Data Integration]
导读
成功在生产环境中采用企业级生成式AI应用程序取决于一个强大且可信的数据基础。一个坚实的数据基础需要具备可扩展性、数据质量、无缝集成、治理和安全性,以确保生成式AI应用程序产生相关、准确、可信且无偏见的结果。作为数据专业人士,了解Informatica的蓝图如何帮助您在亚马逊云科技上设计企业级生成式AI应用程序。探索如何利用Informatica智能数据管理云(IDMC)内的语义智能,以及其无代码/低代码框架与Amazon Bedrock的集成,来创建对您的业务有全面理解的企业级AI应用程序。本演示由亚马逊云科技合作伙伴Informatica为您带来。
演讲精华
以下是小编为您整理的本次演讲的精华。
在令人着迷的企业计算领域,从AI原型到企业级生成AI应用程序的投产之旅,是一段充满错综复杂挑战和细致架构考量的奥德赛。这次演讲汲取了过去一年半与客户密切合作的经验教训,阐明了在企业环境中成功部署生成AI应用程序所需的复杂要求和架构基础。
构建健壮的生成AI应用程序的核心基石有五大支柱。首先,确立性(groundedness)是一项关键要求,将模型与渗透企业生态系统的事实信息和数据相关联。通过严格的培训过程,涉及企业的事实,这些模型被赋予对企业知识库的深刻理解。然而,出现幻觉(hallucinations)的情况是一个巨大挑战——模型生成的响应虽然合理,但在事实上却是不正确的,可能会在企业环境中产生负面影响。微调(Fine-tuning)可能是一种解决方案,尽管存在成本影响,并需要谨慎管理以确保一致性。
第二大支柱是语境化(contextualization),它认识到企业内部存在独特的语言环境。企业通常会发展出自己的术语、语言和语义细微差别,这些都深深植根于其运营之中。因此,确保提示语(prompts)融入了这种业务语境变得至关重要,因为它使生成AI应用程序能够生成真正适用于企业特定领域的响应,而不是依赖通用语境。
质量是第三大支柱,它强调了一个基本事实:并非所有数据都是平等创造的。在企业内部,数据存在不同的质量水平,输入生成AI应用程序的数据质量直接影响生成的摘要和响应的准确性和适用性。在精确性至关重要的环境中,确保数据符合所需的质量标准是一个不可或缺的要求,因为大多数企业要求其生成AI应用程序提供准确的响应。
第四大支柱是开发和部署的便利性,它认识到生成AI领域快速变化的步伐。敏捷性成为关键词,需要一个健壮的系统来促进生成AI应用程序的轻松开发、部署和管理。有限的手工编码,更多的是编排和工具利用,在这方面是关键的推动力,促进了新兴AI技术在企业环境中的快速采用。这种方法还有助于快速采用以惊人的速度推出的新AI技术,正如行业会议所强调的那样。
最后,第五大支柱——治理和安全性——是一个至关重要的考虑因素。在构建企业级生成AI应用程序时,透明度、数据可追溯性和血统变得不可或缺。在受监管行业或合规性至关重要的企业环境中,遵守监管要求和数据访问政策至关重要。此外,必须实施成本和使用控制机制,以确保这些应用程序在生产环境中可持续和高效运行,因为无控制的使用可能会导致成本激增。
Informatica解决这些要求的方法是通过创建企业上下文和元数据智能来构建成功的基础。作为数据管理领域的领导者,Informatica利用其在数据发现、集成、隐私、安全、治理、质量管理和分析等领域的专业知识,为企业采用生成AI铺平了道路。
演讲深入探讨了支撑Informatica企业级生成AI产品的七大支柱。首先,数据转换和与矢量数据库和知识库的集成的可扩展性,确保企业能够无缝地大规模摄取和处理大量结构化、非结构化和半结构化数据。
其次,执行数据质量和可观察性至关重要,因为只有当底层数据符合严格的质量标准时,才能实现准确、无偏差和可靠的响应。Informatica的解决方案使企业能够监控和维持所需的数据质量水平。
第三大支柱围绕着可解释性和可追溯性。在企业环境中,能够理解AI生成响应背后的血统和基本原理至关重要。元数据在这方面发挥着关键作用,提供必要的上下文和透明度。
此外,Informatica通过特定领域的语义智能来指导LLM,将模型植根于企业独特的术语和上下文。这种方法确保生成的响应与企业的领域知识相关和一致。
解决敏感数据问题是另一个关键考虑因素,因为企业必须遵守严格的数据治理和访问管理政策。Informatica的解决方案使企业能够执行这些政策,确保以最大的谨慎和合规性处理敏感数据。
创建统一的主数据存储库是第六大支柱,使企业能够通过从单一权威数据源获取信息来生成一致、可信和全面的响应。这种方法类似于主数据管理和360度视图,提高了生成AI应用程序的可靠性和连贯性。
最后,Informatica通过无代码/低代码编排和跨LLM支持,简化了AI应用程序的开发。这种方法不仅加快了开发过程,而且还为应用程序的未来发展做好了准备,使企业能够随着技术环境的发展,无缝集成和利用多个LLM。
Informatica的Intelligent Data Management Cloud是一个基于SaaS的平台,部署在亚马逊云科技上,为企业中的生成AI应用程序提供动力。该平台包括一套服务,包括连接到大量企业数据源的连接器、提供元数据智能和自动化功能的AI引擎(CLAIRE),以及智能数据管理功能。
演讲接着深入探讨了检索增强生成(Retrieval-Augmented Generation,RAG)框架,该框架已成为构建生成AI原型的理想方法。RAG将信息检索技术与LLM相结合,通过以下三个关键步骤生成上下文感知的答复:从文档、数据库和知识库中检索相关数据;用额外的上下文增强查询;生成连贯的摘要和响应。
虽然RAG在原型阶段表现出色,但向生产环境过渡存在一些挑战。由于上下文碎片化和依赖于来自运营系统的可能已过时或不完整的数据,幻觉和不准确性可能会削弱生成响应的可靠性。此外,企业内数据量的指数级增长也引发了对检索系统的可扩展性和效率的质疑。
此外,在原型阶段常常被忽视的数据安全和合规性要求,在生产环境中变成了关键考虑因素。企业必须确保严格执行数据访问政策和监管要求,随着基于RAG的应用程序数量的增加,这项任务变得越来越复杂。一位客户强调,虽然他们使用RAG开发了120个原型应用程序,但由于这些挑战,只有不到两个进入了生产阶段。
成本管理也成为一个重大挑战,因为如果不加以仔细监控和控制,维护和扩展基于RAG的应用程序所涉及的运营成本可能会迅速攀升。
演讲还涉及了RAG向自主智能体(autonomous agents)的演进,这是一种更加动态和面向任务的解决问题方法。这些智能体能够与各种API系统集成、接受迭代反馈并自动化决策过程,从而提高了其在生产环境中的适用性。Informatica观察到,与简单的RAG原型相比,这些智能体在生产采用方面的成功率更高。
为了解决企业级生成AI应用程序的挑战和要求,Informatica提出了一个利用其在数据管理和元数据智能方面的专业知识的架构蓝图。该蓝图包括以下关键组件:
- 智能体子流程:该组件负责根据用户的查询或提示来理解用户的意图。然后,它构建一个优化的计划,确定需要查询哪些相关系统和数据源以满足用户的请求。关键的是,智能体子流程还会将这些系统的元数据上下文传递给LLM,使其能够生成更加明智和相关的响应。
- 编排器:编排器执行由智能体子流程生成的计划。它调用专门的执行器,负责从特定系统或数据源检索数据。编排器还管理这些执行器之间的状态和数据流,确保计划的无缝协调执行。
- 执行器:这些专门的组件旨在从企业内部的特定系统或数据源中检索数据。Informatica利用加速器和配方(即标准化的构建模块)来简化这些执行器的开发和部署。这种方法使企业能够快速构建和标准化跨各种系统和领域的数据检索流程。
- 治理和安全:Informatica的云数据访问管理服务(SOCDAMS)在执行数据访问策略和确保符合监管要求方面发挥着关键作用。该服务充当代理,拦截所有对底层系统的调用,并根据定义的策略和用户访问权限对其进行评估。通过将最终用户详细信息传递给SOCDAMS,系统可以根据用户的权限和企业的合规性要求,就是否检索或扣留数据做出明智决定。
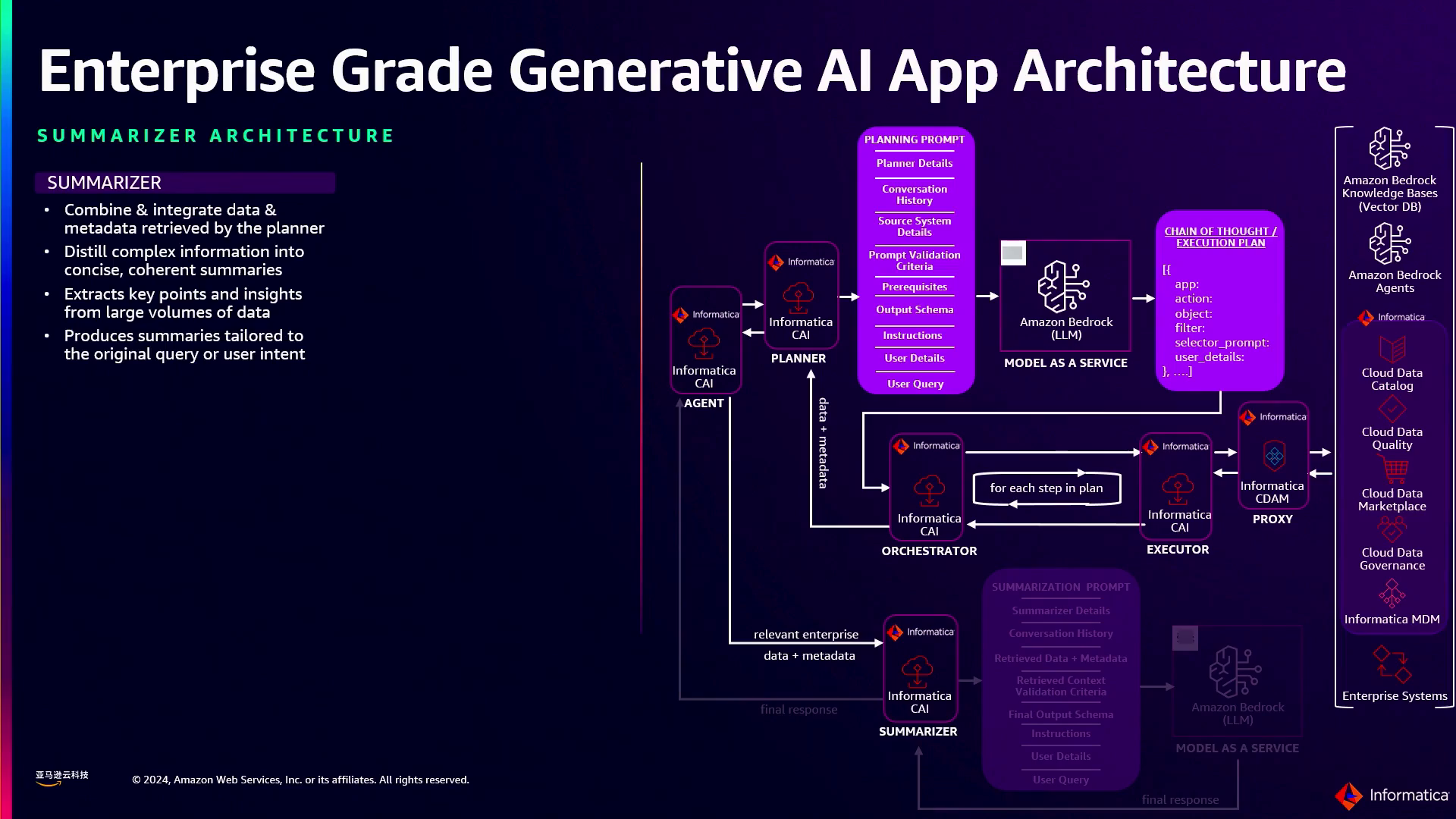
- 总结器:一旦从各种系统中检索到相关数据,总结器组件就会将这些复杂的信息提炼成一种连贯且易于理解的格式。它通过结合企业特定的行话、术语和上下文来构建可解释性,确保生成的响应量身定制于企业的领域,并且易于其用户理解。
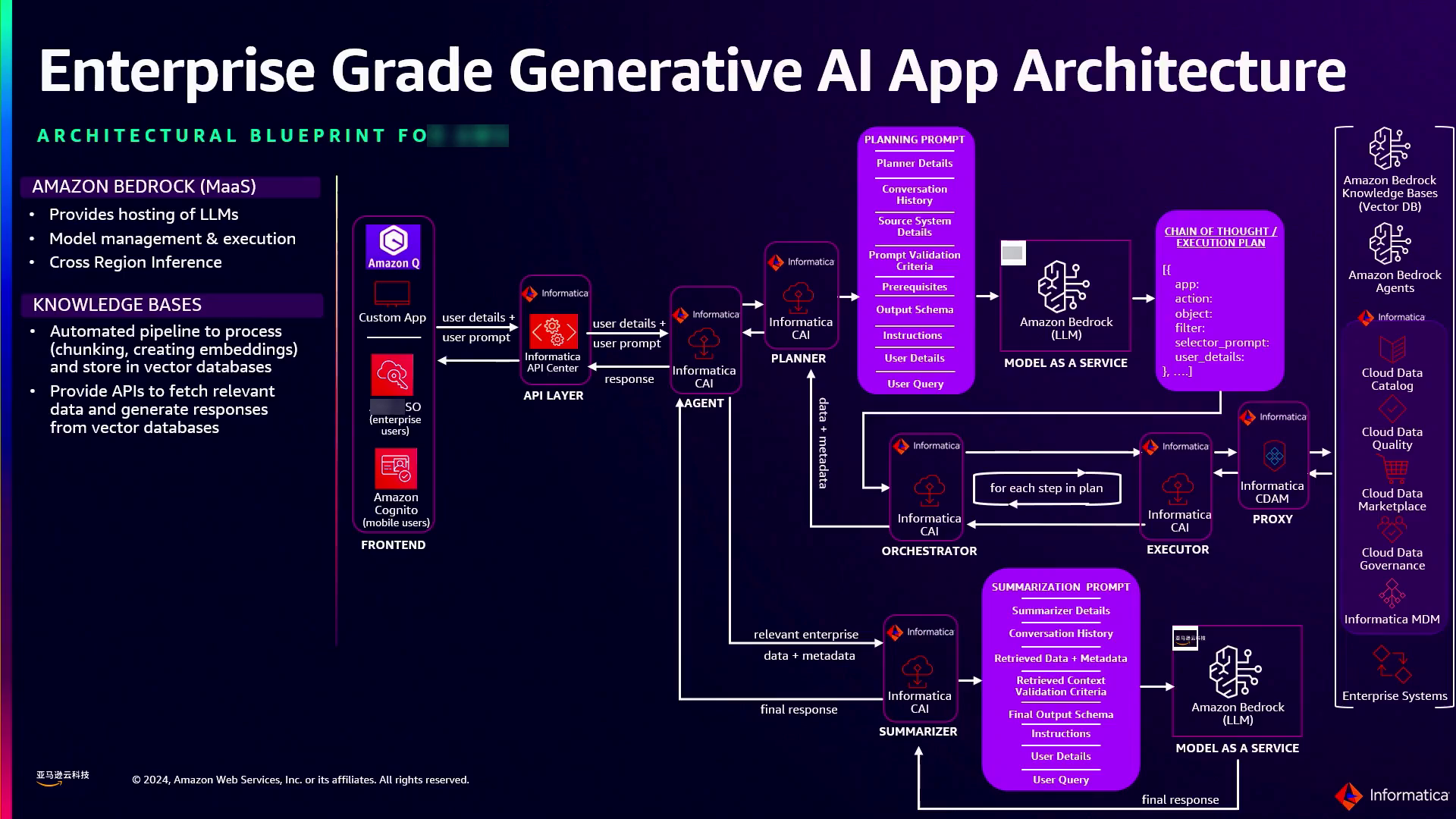
- 前端层:该层处理身份验证、授权和速率限制机制,确保只有经过授权的用户才能访问gen AI应用程序,并且使用情况受到控制,以有效管理成本。Informatica的蓝图利用Amazon Bedrock提供的跨区域推理功能,使工作负载能够动态分布在不同区域,从而缓解意外的流量高峰,并确保性能一致。
- 与知识库集成:Informatica的框架支持统一的API,以无缝集成Amazon Bedrock支持的各种向量数据库和知识库。这种方法为解决方案提供了未来发展的空间,使企业能够轻松整合新的知识库。
- 配方和加速器:为进一步简化和加速gen AI应用程序的开发,Informatica提供了配方和加速器,这些都是可以作为构建模块使用的预构建组件和最佳实践。这些加速器可以在整个企业内标准化和共享,促进协作,并使团队能够快速启动开发工作。
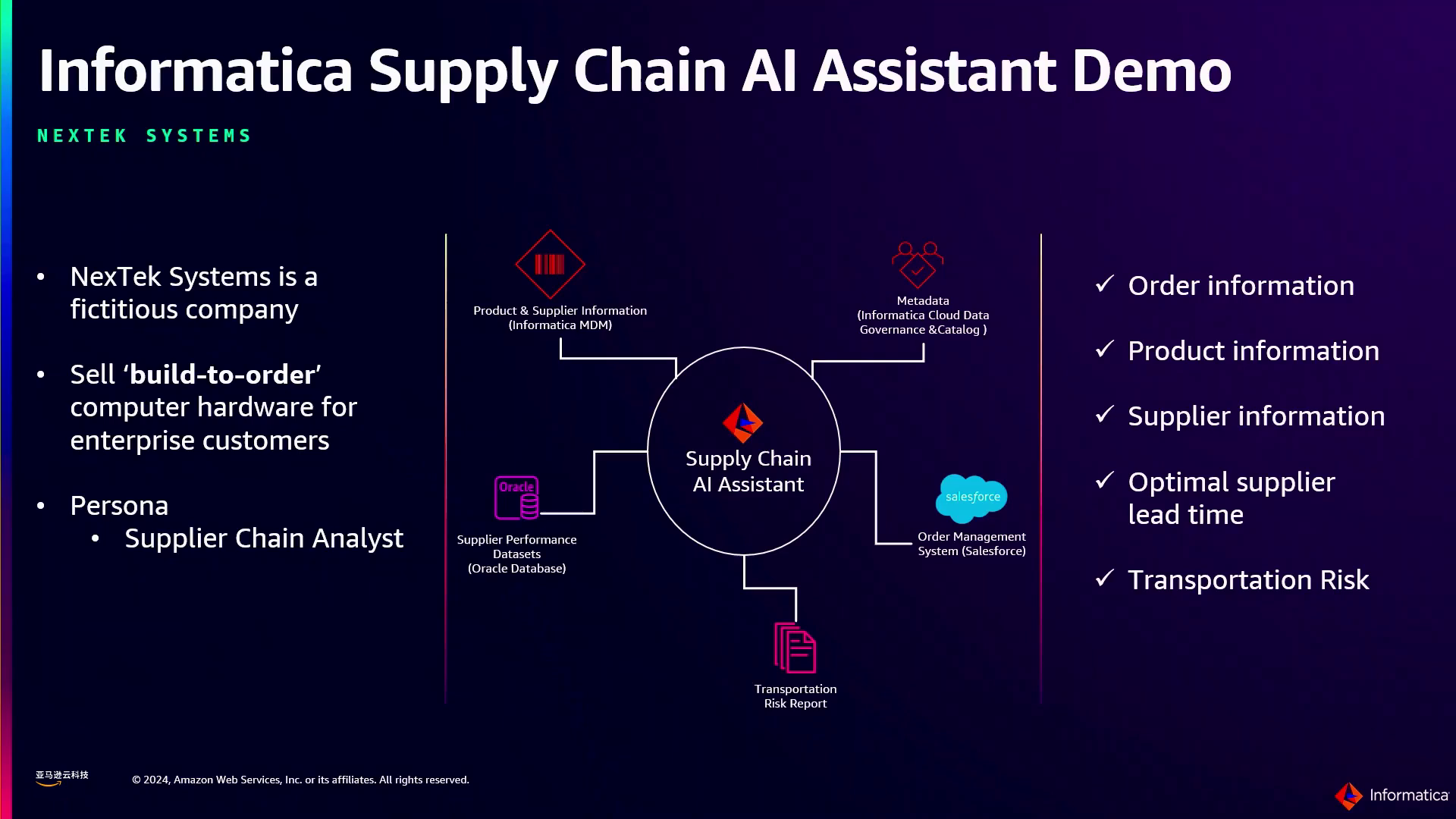
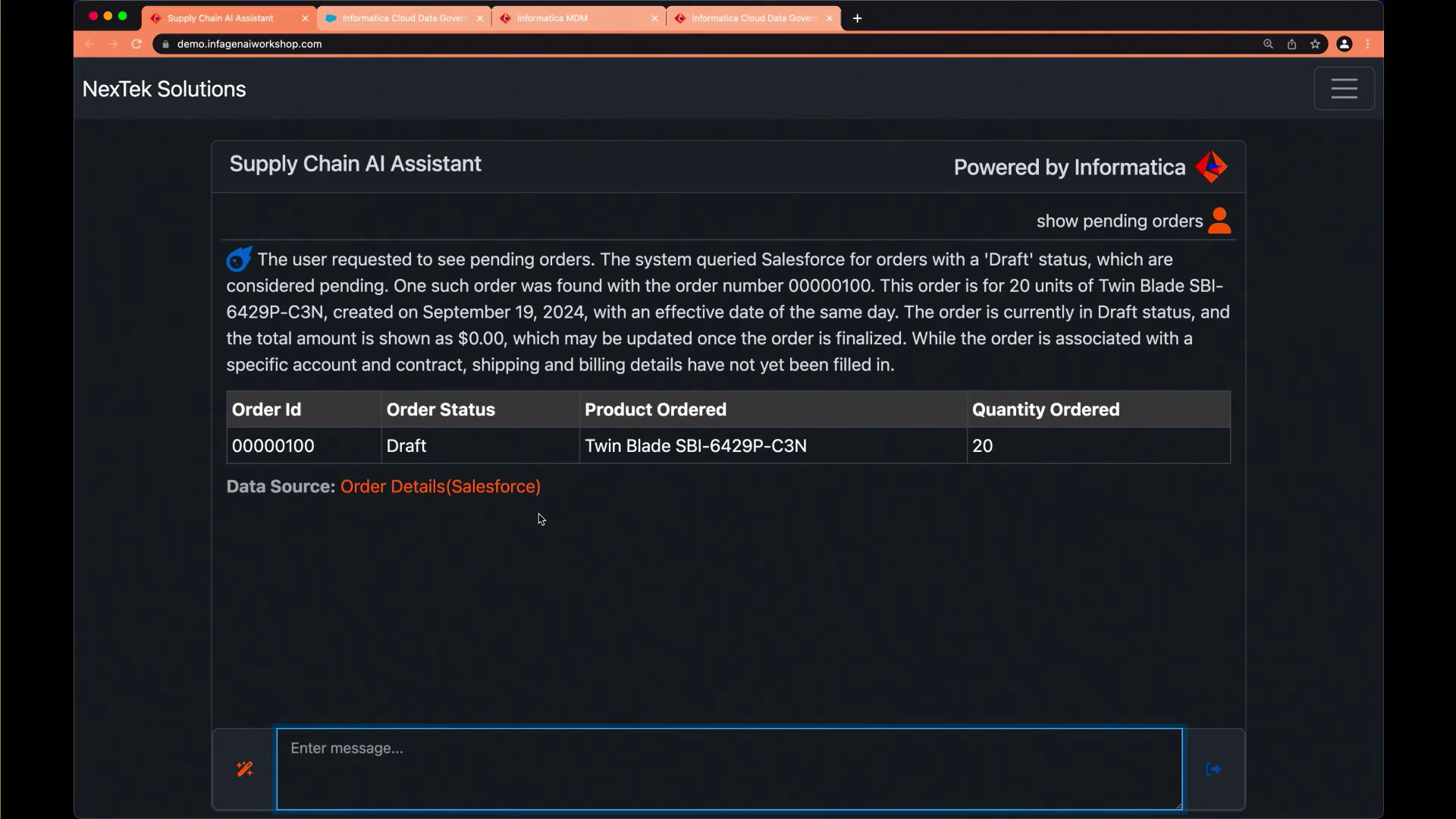
演示包括了一个现场演示,展示了Informatica架构蓝图在供应链用例中的强大功能。演示以一家虚构的公司NextTech为例,该公司销售定制计算机硬件。假设供应链分析师的角色,演示说明了代理子流程如何根据用户意图动态生成计划,并从多个系统(包括Salesforce(订单信息)、Informatica Supplier 360和Product 360(高质量、可信的供应商和产品数据)、治理服务(元数据和数据质量信息)以及Oracle系统(供应商绩效和交货时间数据))检索相关信息。
演示的一个关键亮点是能够将元数据和业务定义纳入生成的响应中。例如,在处理企业特定的自定义对象模型时,系统可以从数据目录中检索并结合相关元数据,确保LLM具有生成准确和有意义响应所需的上下文。
基于质量阈值的动态数据选择是另一个值得注意的演示特性。系统可以评估不同数据源的质量分数,并根据预定义的阈值自动选择最合适的源。例如,在查询供应商交货时间时,系统会通知用户最新报告的数据质量分数为81.57,并提供使用另一个质量分数为100%但日期较旧的数据源的选项。
演示还展示了系统在应用程序本身内提供可解释性和指导的能力。例如,在处理供应链领域特有的生僻术语或缩略语(如CLT(承诺交货时间)和OLT(运营交货时间))时,系统可以从企业的治理词汇表中检索并呈现定义,增强用户的理解,并支持更明智的决策。
在整个演示过程中,主讲人强调了将来自多个系统的数据集成在一起的重要性,而不是仅仅依赖向量数据库。这种方法反映了企业环境的现实情况,即数据通常分散在各种运营系统中,在推理时检索和集成数据的能力对于生成准确和全面的响应至关重要。演示展示了系统如何无缝查询四个不同的系统(Informatica CDGC用于元数据、Supplier 360用于供应商信息、Oracle用于交货时间数据,以及向量数据库用于额外上下文),以提供全面的响应。
主讲人还强调了考虑延迟和选择同步或异步数据检索的重要性。虽然演示展示了同步查询以简化操作,但该框架支持两种模式,使企业能够根据特定需求优化性能和用户体验。
为了提供架构蓝图的幕后一瞥,主讲人介绍了执行器流程和元数据智能组件。他们演示了规划器如何根据用户意图生成优化计划、协调器如何查询各种系统(如Informatica MDM和Oracle数据库)并将检索到的数据传递给总结器、以及如何使用元数据查询和LLM调用来动态生成SQL查询并将元数据上下文纳入响应中。
主讲人还强调了云数据访问管理(CDAMS)代理在执行数据访问策略方面的作用,确保用户只能检索他们根据定义的合规性和安全策略被授权访问的数据。
在整个演示过程中,重点放在Informatica全面的方法上,以解决企业级gen AI应用程序的关键要求,包括可靠性、上下文化、质量、开发便利性以及治理和安全性。架构蓝图和现场演示展示了他们将数据管理、元数据智能和AI技术相结合,构建出健壮、可扩展且符合企业独特需求的合规gen AI应用程序的能力。
总之,这次演示让我们一窥从AI原型到企业级生成AI应用程序投入生产的旅程。它强调了企业必须应对的错综复杂的挑战和要求,并展示了Informatica创新的解决方案和架构蓝图,以应对这些挑战。通过利用他们在数据管理、元数据智能和AI技术方面的专业知识,Informatica旨在让企业释放gen AI应用程序的全部潜力,同时确保合规性、安全性和可扩展性。
下面是一些演讲现场的精彩瞬间:
引入了代理框架中的新安全和合规层,使SOCDAMS能够管理数据访问策略并通过代理为企业用户强制执行这些策略。
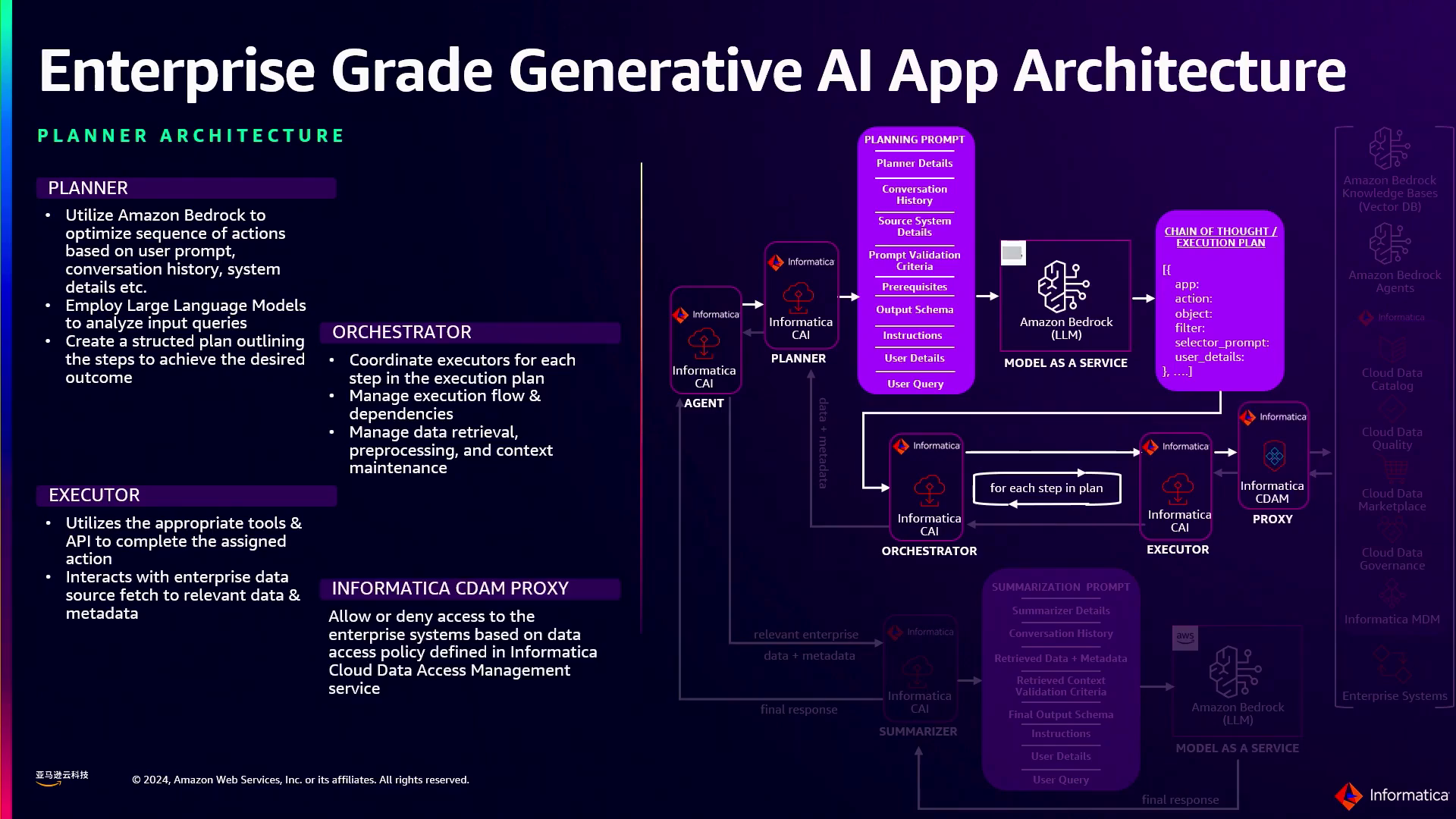
演讲者解释了总结器在提炼复杂信息和使用企业术语构建可解释性方面的作用,随后是前端层处理身份验证、授权和为成本控制进行速率限制。
亚马逊的框架通过支持跨区域推理、与知识库和统一API集成以及为代理架构的不同组件提供加速器,简化了构建生成式AI应用程序的过程。
一位供应链分析师演示了如何根据用户的意图从各种系统(如Salesforce、Informatica Supplier 360和Product 360)生成数据,以获取有关订单和产品的信息。
AI助手展示了理解用户请求产品详细信息的意图并从企业内各种系统(如Informatica Product 360)中检索相关信息的能力,无缝集成来自不同来源的数据。
演讲者表达了分享学习经验的兴奋,并邀请观众前往他们的1432号展位了解更多技术细节和激动人心的内容。

总结
在这场引人入胜的演讲中,来自Informatica的Gofi Sunkaran和Regiv Stinnivasin深入探讨了从AI原型到企业级生成式AI(genAI)应用程序投入生产的转型之旅。他们揭示了一个全面的蓝图,解决了企业成功采用genAI的关键要求,包括确定性、上下文化、数据质量、开发和部署的便利性、治理和安全性。
Gofi强调了从检索增强生成(RAG)原型过渡到生产就绪应用程序时面临的挑战,如幻觉、上下文碎片化、数据量增长和合规性要求。他介绍了RAG向自主智能体的演进,这些智能体是与企业系统集成的动态、面向任务的问题解决者。
Regiv随后介绍了Informatica的架构蓝图,这是一个健壮的框架,可协调整个genAI应用程序生命周期。关键组件包括理解用户意图并生成优化计划的规划器、从各种企业系统检索数据的执行器、用于数据访问策略的治理层以及将复杂信息浓缩为连贯、上下文感知响应的总结器。
通过现场演示,Regiv展示了这一蓝图在供应链场景中的强大功能,无缝集成来自多个系统的数据,包括Salesforce、Informatica MDM、Oracle和向量数据库。演示突出了基于质量的动态数据选择、元数据智能的融入以及跨域切换和提供可解释的AI响应与企业上下文的能力。
Gofi最后强调了这种企业级genAI方法的重要性,它将Informatica在数据管理方面的专业知识与前沿AI技术相结合。他邀请与会者在他们的展位体验一个游戏化的供应链系统,亲身体验genAI应用程序在企业环境中的变革潜力。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。

















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









