






在AWS上快速构建检索增强生成(RAG)应用,可以结合以下服务和步骤实现高效、可扩展的解决方案。以下是基于AWS服务的详细构建流程:
1. RAG 核心架构
RAG(Retrieval-Augmented Generation)的核心流程包括:
-
数据准备:文档存储与处理
-
向量化:文本转换为向量嵌入(Embeddings)
-
检索:基于语义相似度的向量检索
-
生成:大语言模型(LLM)生成答案
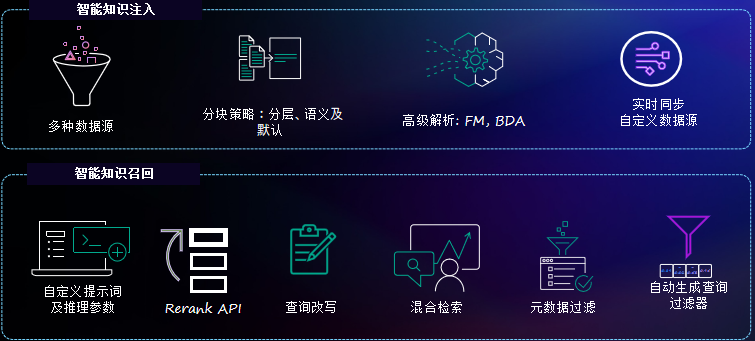
2. AWS 服务选型
(1) 数据存储与处理
-
Amazon S3
存储原始文档(PDF、TXT等),作为数据湖的核心存储。 -
Amazon Textract
提取非结构化文档(如PDF)中的文本。 -
Amazon Comprehend
文本分析(关键词提取、实体识别等)。
(2) 向量化与检索
-
Amazon OpenSearch Service
支持向量搜索的托管搜索引擎,用于存储向量和快速检索相似文本。 -
AWS Lambda
无服务器计算,处理文档分块、调用模型生成嵌入。 -
Amazon SageMaker
可选,用于部署自定义嵌入模型(如Sentence-BERT)。
(3) 大语言模型(LLM)
-
Amazon Bedrock
托管主流LLM(如Anthropic Claude、AI21 Labs),直接调用生成答案。 -
Amazon SageMaker JumpStart
部署开源模型(如Llama-2、Falcon)。
(4) 应用层
-
API Gateway + Lambda
构建RESTful API,处理用户查询并返回结果。 -
AWS Amplify
快速部署前端Web界面。
3. 实现步骤
步骤1:文档处理与向量化
-
将文档上传至S3。
-
使用Lambda触发Textract/Comprehend处理文档,生成纯文本。
-
对文本分块(如每段512 tokens),通过嵌入模型(如AWS Titan Embeddings)转换为向量。
-
向量数据存入OpenSearch的索引中。
示例Lambda处理逻辑(Python):
import boto3
def handler(event, context):
s3 = boto3.client('s3')
textract = boto3.client('textract')
# 从S3获取文档并提取文本
response = textract.detect_document_text(
Document={'S3Object': {'Bucket': 'my-bucket', 'Name': 'doc.pdf'}}
)
text = " ".join([item['Text'] for item in response['Blocks'] if item['BlockType'] == 'LINE'])
# 分块并生成向量
chunks = split_text(text)
embeddings = generate_embeddings(chunks) # 调用Bedrock或SageMaker
# 存储到OpenSearch
opensearch.index(index='rag-index', body={'vector': embeddings, 'text': chunks})
步骤2:语义检索
-
用户提问时,通过API Gateway触发Lambda。
-
Lambda将问题转换为向量,查询OpenSearch获取Top-K相似文本片段。
-
将检索结果与问题拼接为LLM的输入。
OpenSearch向量查询示例:
{
"size": 5,
"query": {
"knn": {
"vector_field": {
"vector": [0.1, 0.2, ..., 0.5], # 问题向量
"k": 5
}
}
}
}
步骤3:生成答案
调用Amazon Bedrock的LLM生成最终回答:
bedrock = boto3.client(service_name='bedrock-runtime')
prompt = f"基于以下上下文:{context},回答:{question}"
response = bedrock.invoke_model(
modelId='anthropic.claude-v2',
body=json.dumps({"prompt": prompt, "max_tokens_to_sample": 300})
)
answer = json.loads(response.get('body').read()).get('completion')
4. 优化与扩展
-
性能优化
-
使用OpenSearch的近似最近邻(ANN)索引加速检索。
-
对Lambda启用预置并发减少冷启动延迟。
-
-
成本控制
-
对S3启用生命周期策略归档旧数据。
-
使用Spot实例运行SageMaker(如果部署自定义模型)。
-
-
安全增强
-
通过IAM角色限制服务权限。
-
使用OpenSearch的加密存储和VPC隔离。
-
5. 参考架构图
用户请求 → API Gateway → Lambda → 生成问题向量
↓
OpenSearch(检索相似文本)
↓
Lambda整合上下文 → Bedrock(生成答案)
↓
返回结果 → 前端(Amplify)
6. 场景示例
问题:
“AWS的EC2实例有哪些类型?”
流程:
-
检索到关于EC2实例类型的文档片段(如通用型、计算优化型等)。
-
LLM生成结构化回答:
“AWS EC2实例主要分为:1. 通用型(M系列)... 2. 计算优化型(C系列)...”
AWS EC2 购买全流程详解 | 新手必看,3分钟快速上手云服务器!![]() https://mp.weixin.qq.com/s/xTlfBIHm-twUM2BYQeB2xQ
https://mp.weixin.qq.com/s/xTlfBIHm-twUM2BYQeB2xQ

















 1691
1691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









