







DriverDBv4是一个专为癌症驱动基因研究而设计的多组学集成数据库,旨在通过整合各种组学数据为癌症生物学提供深入洞见。随着高通量技术的发展,DriverDBv4进行了重大升级,包括样本数量由33组扩大至70组,覆盖约24000个样本,并纳入了蛋白质组数据。这些更新显著增强了数据库分析癌症驱动基因的能力。
DriverDBv4通过实施多种多组学算法,识别和解析癌症驱动因子,并提供新的可视化功能以简明总结高复杂度数据。其设计旨在促进对癌症异质性的理解,并支持个性化临床方法的发展。数据库不仅扩大了现有数据集的范围,还在“定制分析”中引入了两个新功能,以专门用于多组学驱动因子的识别和亚群表达分析。
高通量技术能够生成跨越多个组学层次的全面数据,推动了对癌症分子层面进行整体视角的研究。然而,传统统计模型在处理这些高维数据时存在不足。DriverDBv4通过采用如矩阵分解、机器学习、网络方法等新数学方法,显著提升了多组学集成技术。这些新方法有望为理解癌症的复杂性提供全面视野。
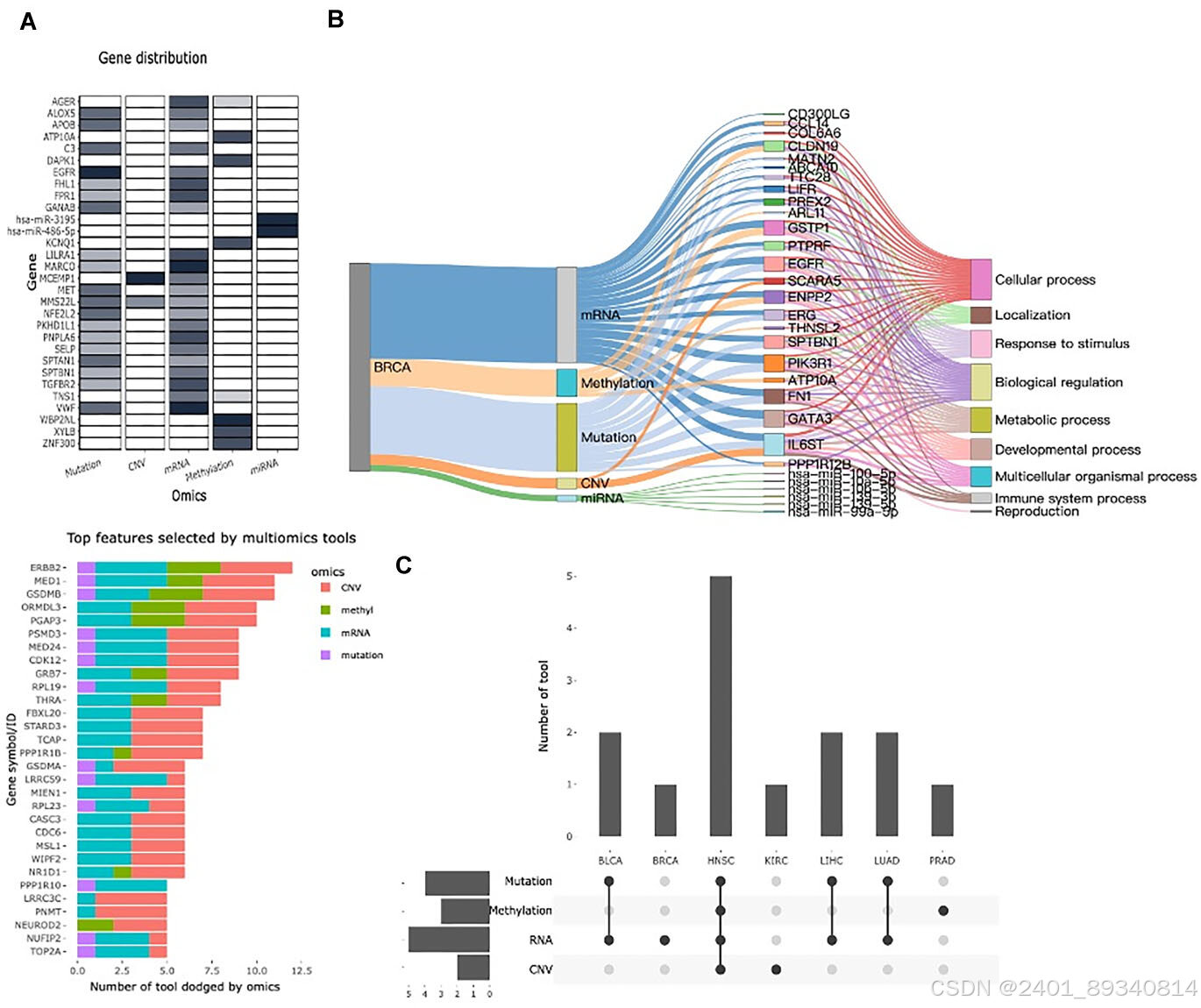
在数据整合方面,DriverDBv4收录了来自TCGA、ICGC、TARGET等多个项目的25509个癌症患者样本。数据库使用了八种多组学集成算法,包括CoMEt、DawnRank、MOFA等,帮助用户解读多组学驱动特征。同时,还提供了新的用户界面和可视化工具。
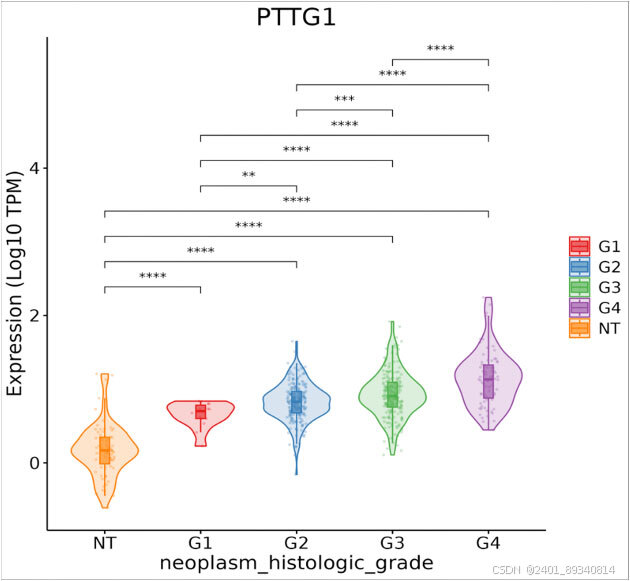
研究结果显示,DriverDBv4提供了“癌症”、“基因”和“定制分析”三个部分用于解析癌症的多种分子特征,新功能的加入促进了个人组学数据集的整合。尤其在“定制分析”中,新增的多组学驱动分析和亚组表达分析功能,帮助研究者发现不同癌症患者群体之间的底层多组学差异。
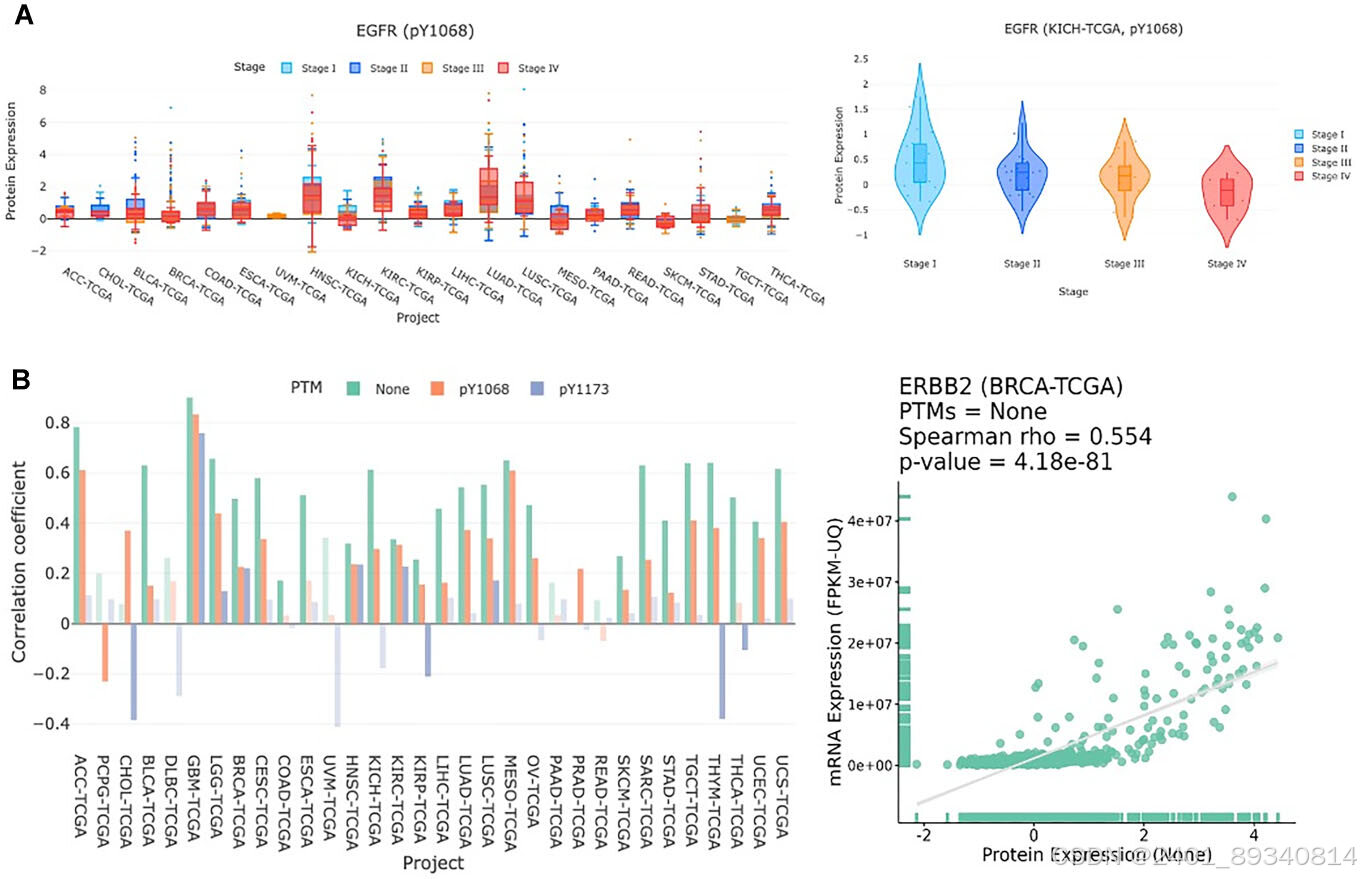
DriverDBv4对现有癌症驱动基因数据库如IntOGen和OncoVar进行了更新,扩展了数据集范围,纳入了蛋白质组数据,并提供了多组学集成分析。其不仅帮助研究人员识别癌症的复杂特征,还通过蛋白质组分析弥补了转录水平与蛋白质水平表达差异的不足。
总而言之,通过多组学数据的全面整合和创新的分析功能,DriverDBv4为研究人员提供了一个强大的工具,以揭示癌症的多维特征和推动精准治疗的发展。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









