







本文介绍了日本DNA数据库(DDBJ)的最新发展,特别是其对代谢组学数据的新存储库MetaboBank的更新。DDBJ是国际核酸序列数据库协作(INSDC)的创始成员之一,自1987年开始接收和分发注释的核苷酸序列数据,并协同美国国家生物技术信息中心(NCBI)和欧洲生物信息学研究所(EBI)。除了INSDC数据库外,DDBJ还提供功能基因组学、代谢组学和人类基因型及表型数据的数据库。
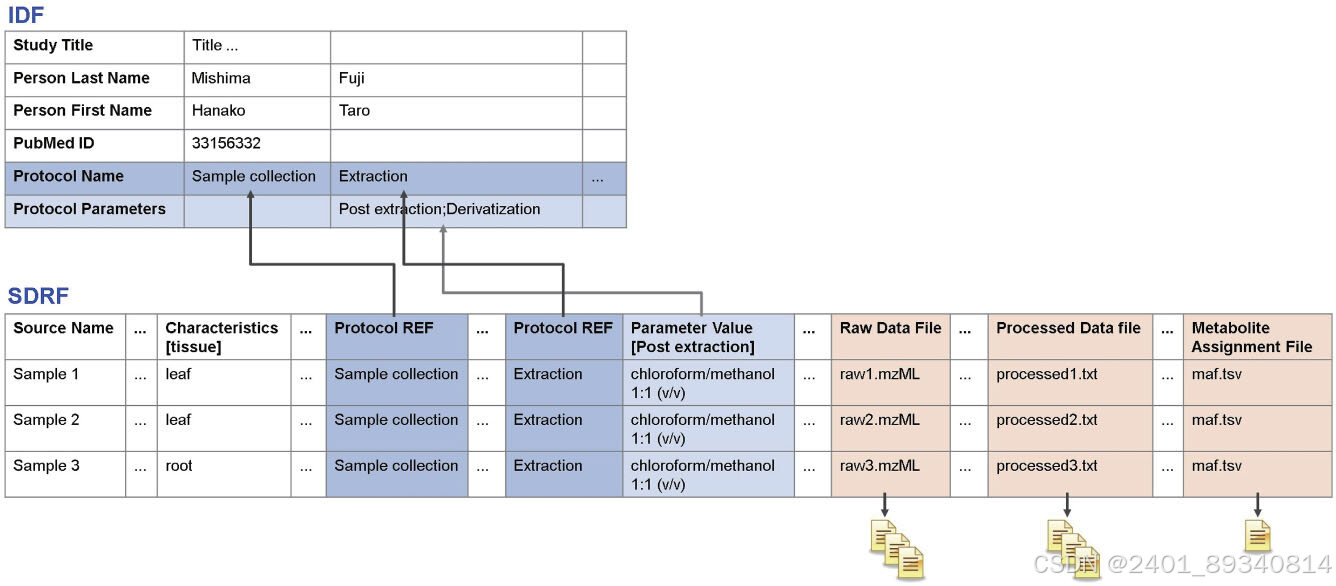
MetaboBank是一个为多组学大规模研究设计的代谢组学数据仓库,使用BioProject和BioSample进行元数据描述,提升了数据的可定位性和再利用率,与EBI的MetaboLights的合作提供了更多的协同作用。MetaboBank需要详细的符合MSI(代谢组学标准倡议)建议的元数据,并提供基于Excel的元数据模板,以支持用户友好的数据提交。
为了满足日益增长的数据需求,DDBJ使用NIG超级计算机来运营其各类存档数据库,并且对日本的生命科学研究人员开放以进行大规模数据分析。超级计算机的存储系统于2023年进行了增强,以适应不断增长的需求。
文章还介绍了DDBJ在支持大规模数据提交、自动化数据验证及增加元数据标准化方面的更新。通过这些努力,DDBJ正在推动其存档数据库向更灵活、易用和综合化的方向发展。这些更新提高了总体数据处理效率,并促进了与其他数据库的集成,支持更全面的生物医学研究。所有资源均可在DDBJ官网获取并下载。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









