







在生物信息学研究中,经常会出现即便是最先进的工具也无法为某些基因或基因产物分配功能的情况。在生物技术底盘生物体Pseudomonas putida中,功能未知的蛋白占据了蛋白质组的14%,这严重影响了对该菌在生物工程中应用的分析。
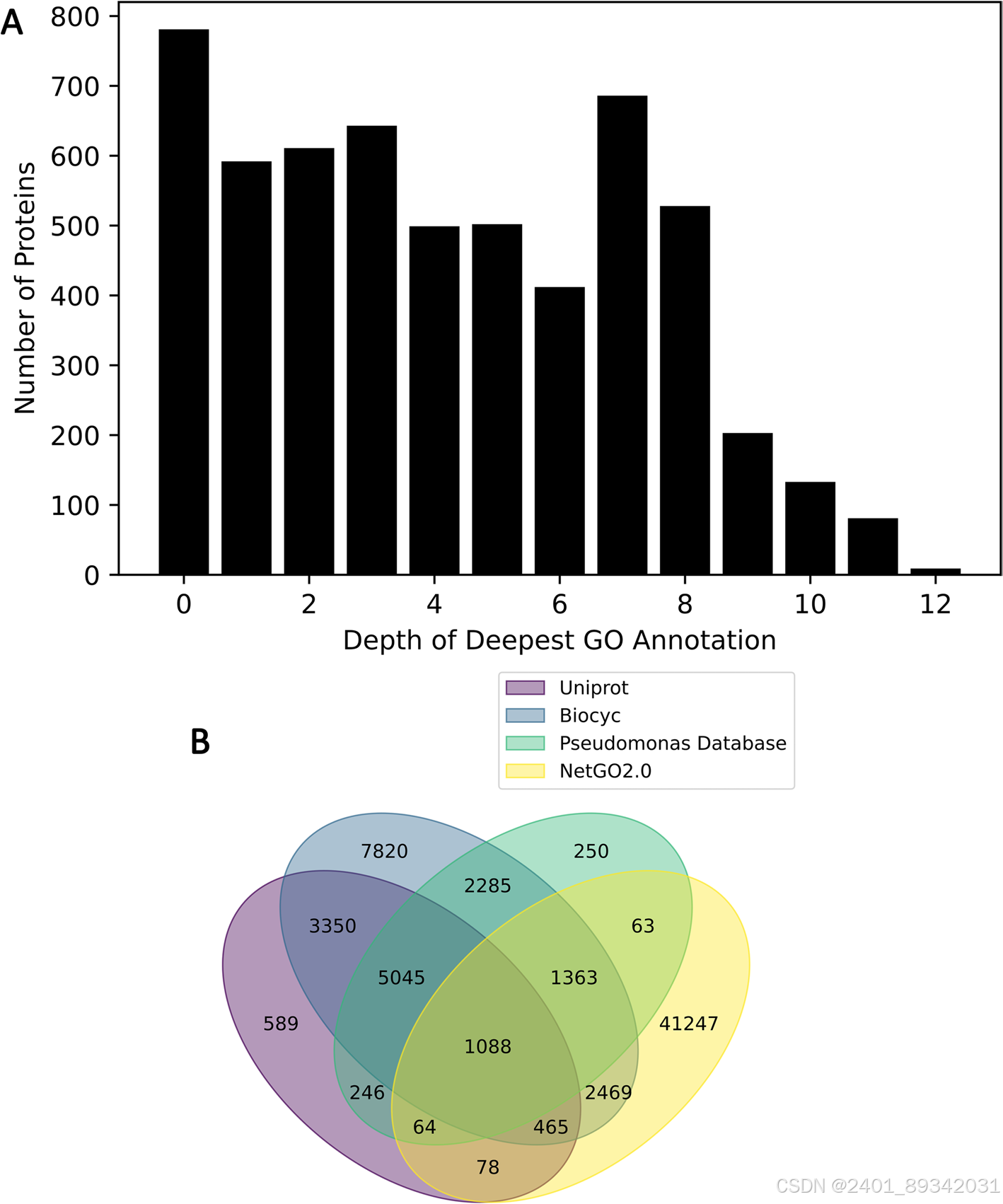
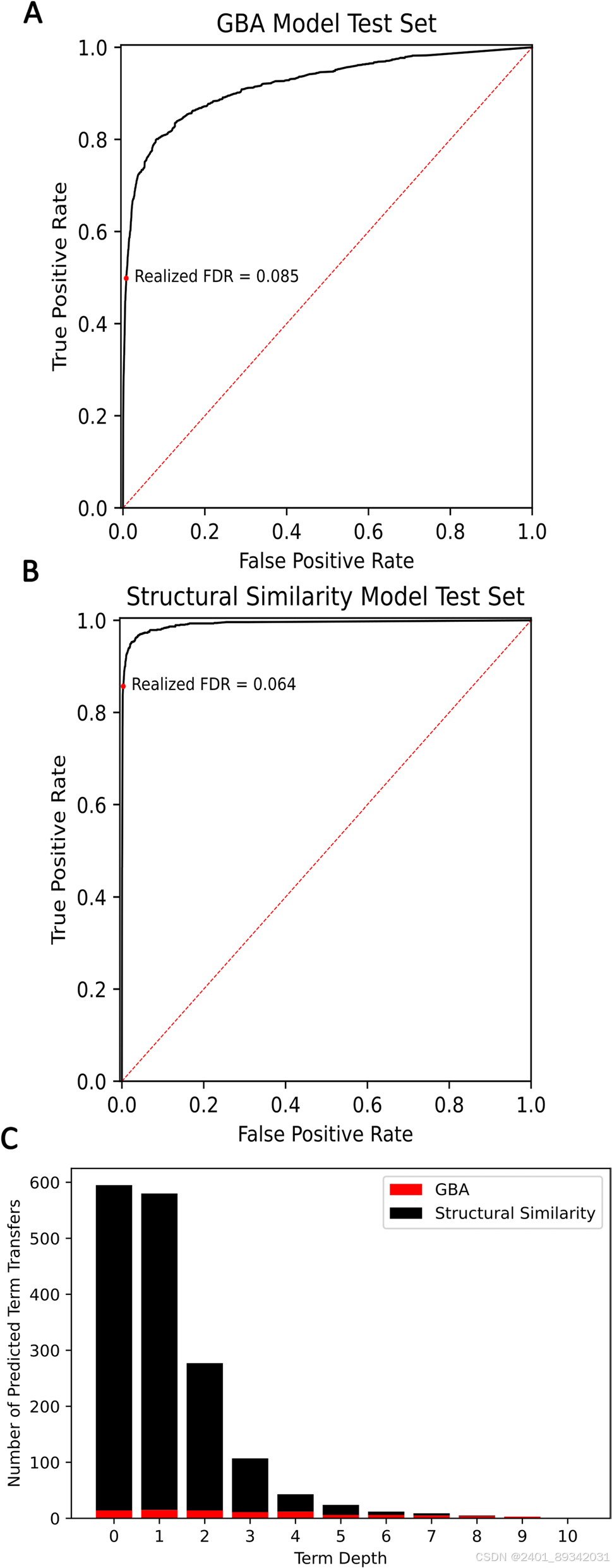
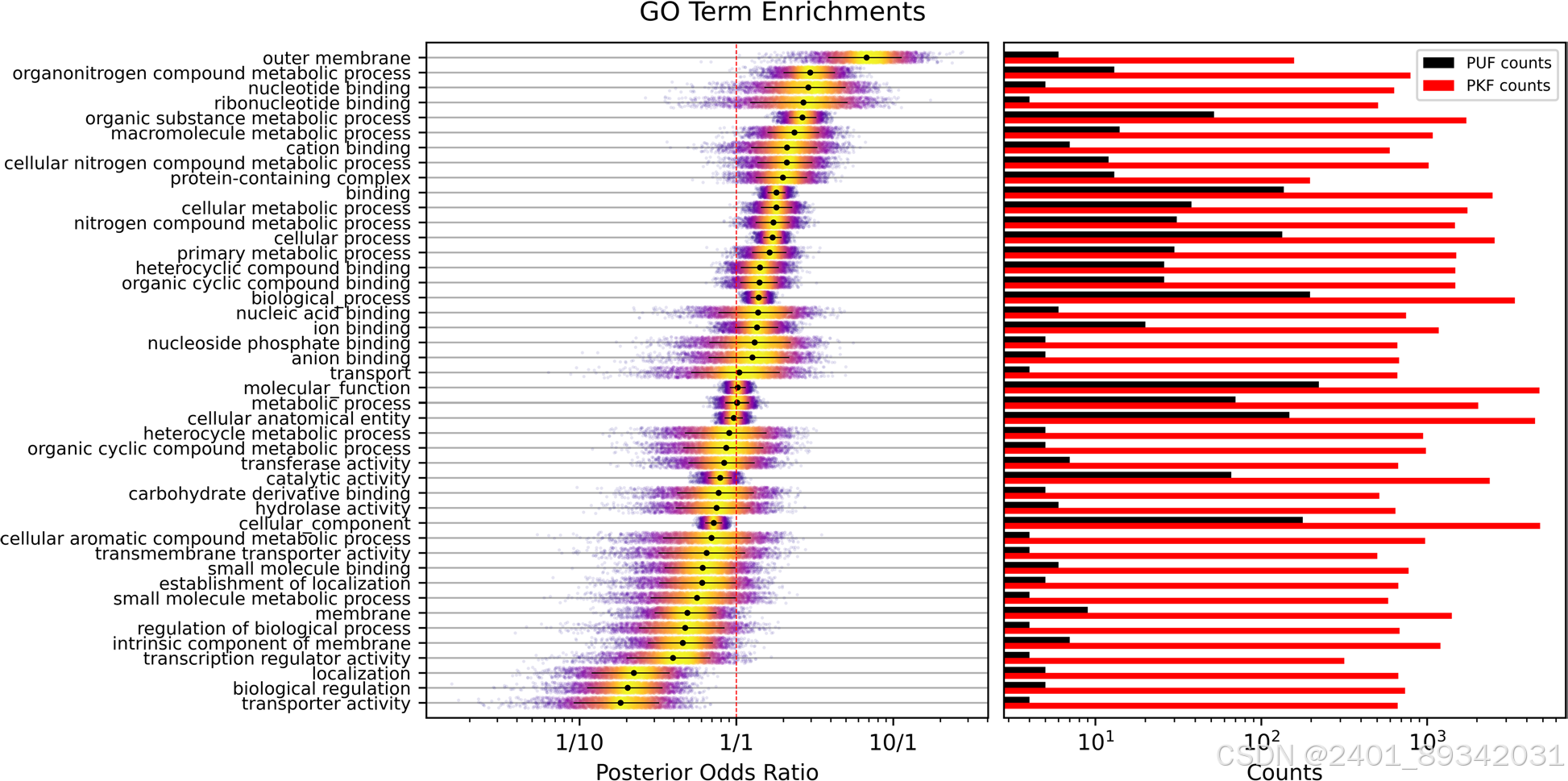
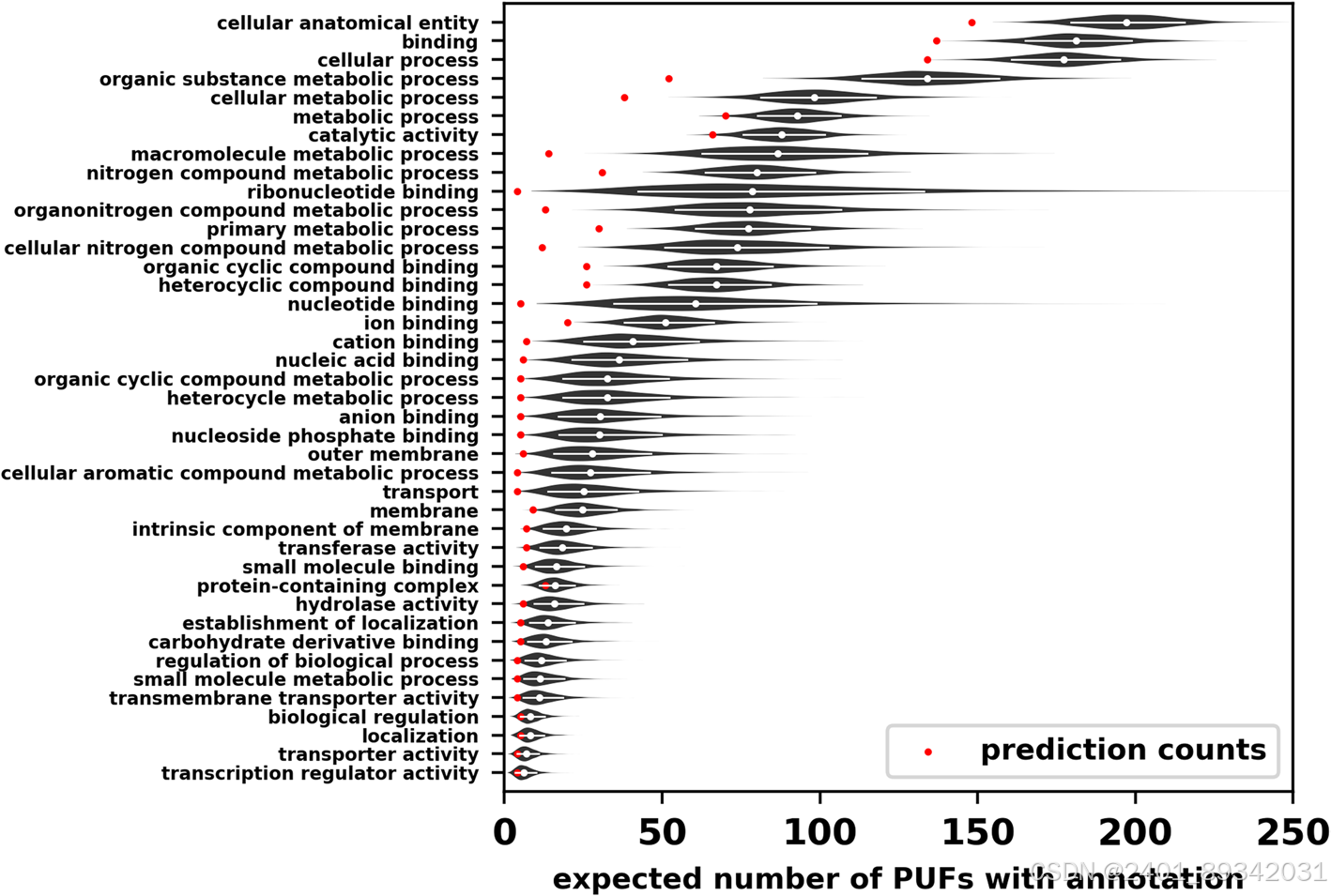
为了解决这一问题,作者设计了一种基于多组学数据和机器学习的方法,用于预测Pseudomonas putida中功能未知蛋白的功能,从而注释了213种蛋白上的1079个术语。这些预测揭示,氮代谢和大分子处理相关的蛋白存在显著过表达的现象。这些发现通过对选定蛋白的手动分析得到验证,并识别出了未注释的功能操纵子,该操纵子可能编码了莽草酸途径的一个分支。
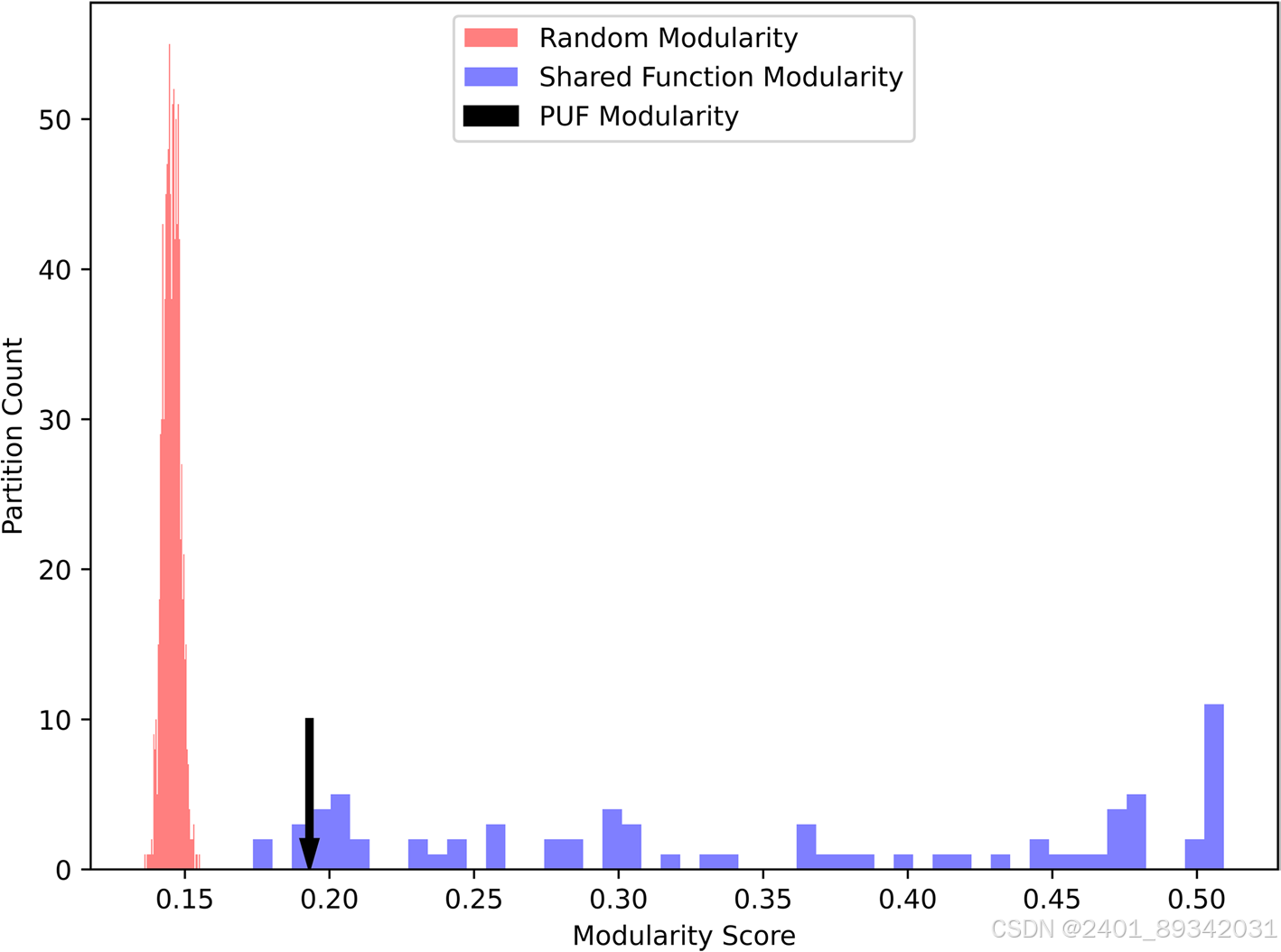
通过利用不同的证据线索,包括进化分析、在线数据库、序列及结构相似性,以及共表达数据,作者构建了一种特别的预测模型。预测模型的两部分分别利用了种内蛋白质组规模数据和Alphafold的结构预测。研究结果表明,PUFs的功能分布与常规蛋白不同,丰富于氮代谢及代谢物结合相关路径,对生物技术研究具有重要参考价值。
这一研究不仅拓展了对P. putida自动化GO注释的理解,也在整合多来源信息用于功能预测方面展示了潜力和优势,尤其有助于生物技术领域中基因工程项目的进展。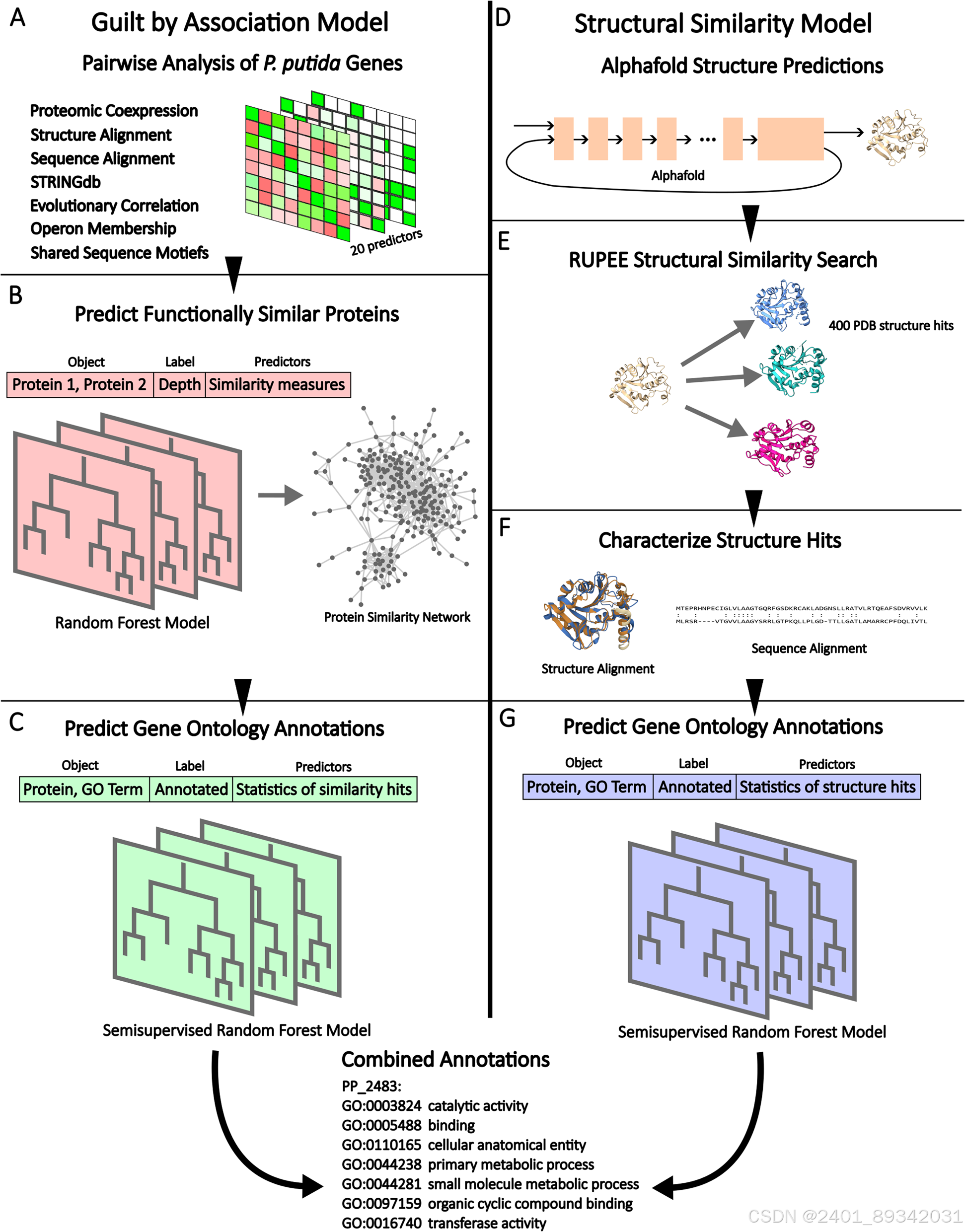


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









