






主要说Java语言的日志生态,主要有日志框架和日志门面
日志框架(Log4j、Logback):主要用来进行日志的输出的,比如输出到哪个文件,日志格式如何等;
日志门面(slf4j,commons-logging):是门面模式的一个典型的应用。就是为了在应用中屏蔽掉底层日志框架的具体实现,主要一套通用的API,用来屏蔽各个日志框架之间的差异的。
其核心为:外部与一个子系统的通信必须通过一个统一的外观对象进行,使得子系统更易于使用。
每一种日志框架都有自己单独的API,要使用对应的框架就要使用其对应的API,这就大大的增加应用程序代码对于日志框架的耦合性。
为了解决这个问题,就是在日志框架和应用程序之间架设一个沟通的桥梁,对于应用程序来说,无论底层的日志框架如何变,都不需要有任何感知。只要门面服务做的足够好,随意换另外一个日志框架,应用程序不需要修改任意一行代码,就可以直接上线。
在软件开发领域有这样一句话:计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决。而门面模式就是对于这句话的典型实践。
这样做的最大好处,就是业务层的开发不需要关心底层日志框架的实现及细节,在编码的时候也不需要考虑日后更换框架所带来的成本。这也是门面模式所带来的好处。
那我换一个日志框架可以吗?
前面提到过一个需要日志门面重要的原因,就是为了在应用中屏蔽掉底层日志框架的具体实现。这样的话,即使有一天要更换代码的日志框架,只需要修改jar包,最多再改改日志输出相关的配置文件就可以了。这就是解除了应用和日志框架之间的耦合。
有人或许会问了,如果我换了日志框架了,应用是不需要改了,那日志门面不还是需要改的吗?
不一定,如果换了一个日志框架,对于一个设计的全面、完善的日志门面来说,他也应该是天然就兼容了多种日志框架的。所以,底层框架的更换,日志门面几乎不需要改动。尽管我改用了其他的日志框架,对于同一个日志的结构细节仍然需要日志门面来解决。就是日志门面的一个比较重要的好处——解耦。
一、为什么需要日志系统?
-
问题追踪:快速定位系统异常或业务故障(如订单支付失败)。
-
行为审计:满足合规要求(如金融行业的操作留痕)。
-
性能分析:统计接口耗时、数据库查询性能等。
-
安全监控:检测恶意攻击(如频繁登录失败)。
-
数据恢复:结合Binlog实现数据回滚(如MySQL误删恢复)。
二、主流日志框架对比
| 框架 | 特点 | 适用场景 |
|---|---|---|
| Log4j 2 | 异步写入、高性能插件体系(Gelf、JSON) | Java高并发应用(如电商后端) |
| Logback | Spring Boot默认集成,兼容SLF4J | 需要与Spring生态无缝集成的项目 |
| SLF4J | 日志门面,可绑定具体实现(解耦)(Simple Logging Facade for Java,缩写SLF4J) | 多日志框架统一管理的系统,SLF4J其实只是一个门面服务而已,他并不是真正的日志框架,真正的日志的输出相关的实现还是要依赖Log4j、logback等日志框架的。 |
| Zap (Go) | 高性能结构化日志(如JSON输出) | Golang微服务 |
| Winston | Node.js多传输支持(文件、数据库、MQ) | 全栈JavaScript应用 |
三、分布式日志系统核心概念
1. 什么是分布式日志系统?
现在,很多应用都是集群部署的,一次请求会因为负载均衡而被路由到不同的服务器上面,这就导致一个应用的日志会分散在不同的服务器上面。
当我们要向通过日志做数据分析,问题排查的时候,就需要分别到每台机器上去查看日志,这样就太麻烦了。
于是就有了分布式日志系统,他可以做分布式系统中的日志的统一收集、存储及管理。并且提供好的可用性、扩展性。
在微服务/分布式架构中,集中采集、存储和分析所有节点的日志,提供统一视图。
一个好的分布式日志系统,应该具备数据采集、数据加工、查询分析、监控报警、日志审计等功能
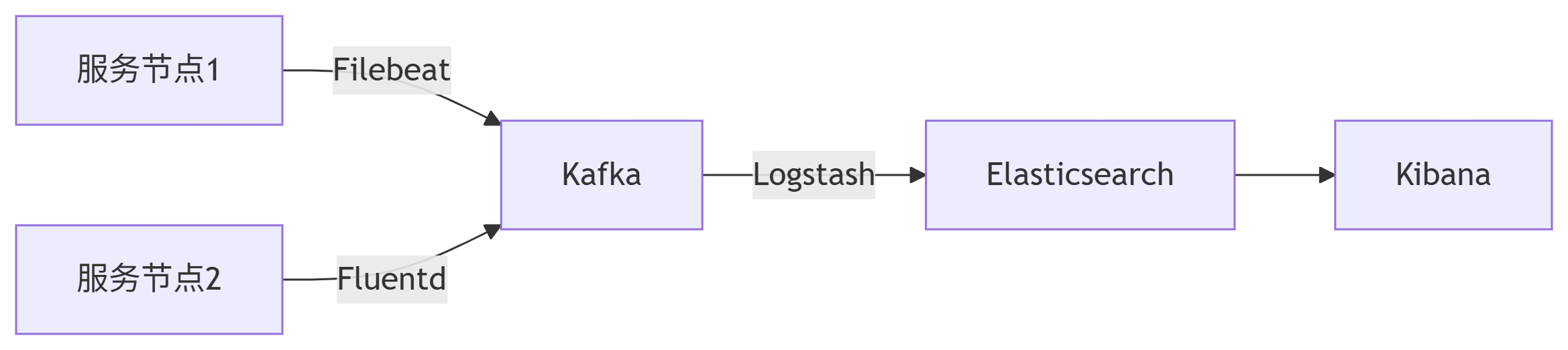
典型组件:
-
采集端:Filebeat、Fluentd
-
传输层:Kafka、RabbitMQ
-
存储层:Elasticsearch、Loki
-
可视化:Kibana、Grafana
2. 工作原理
3:日志管理系统
比较主流的这类日志管理系统有ELK、Graylog、Apache Flume,还有很多类似的云产品,如阿里云的SLS。
ELK:ELasticSearch, Logstash, Kibana。组成
Elasticsearch是个开源分布式搜索引擎,提供分析、存储数据等功能。
Logstash主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。
Kibana也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
所以,通常是使用Logstash做日志的采集与过滤,ES做分析和查询,Kibana做图形化界面。
四、日志系统对性能的影响与优化
1. 性能瓶颈
| 环节 | 影响因素 | 典型表现 |
|---|---|---|
| 日志生成 | 同步写入、频繁I/O | 应用RT(响应时间)上升 |
| 日志传输 | 网络带宽、序列化开销 | 日志延迟堆积 |
| 日志存储 | 磁盘I/O压力、索引性能 | ES集群CPU/内存飙升 |
2. 优化方案
解决日志慢的问题,主要有两种方案,一个是异步,一个是降级。
目前常用的日志框架,如Log4j2、Logback等都是支持异步日志的。都提供了AsyncAppender来实现异步的日志写入。
(1)日志生成阶段
-
异步日志:使用
AsyncAppender(Log4j 2)或AsyncLogger(Logback)。<!-- Log4j2异步配置示例 --> <AsyncLogger name="com.example" level="INFO" includeLocation="true"> <AppenderRef ref="FileAppender"/> </AsyncLogger>
-
降级日志采样:对DEBUG日志按比例输出(如10%)。
-
降级,日志降级一般用的也不多,但是在大促场景中,也是会用到的,一般是配合预案一起做,就是在极端情况下,通过开关来调节, 让日志直接不输出。或者只打印ERROR级别的日志。
if (Math.random() < 0.1) log.debug("Debug message");
或者做的更加精细一点,就是采样打印日志,比如采样1%进行日志输出,但是其实用的比较少,很多时候,采样和直接不打差别也不大。
(2)日志传输阶段
-
批量发送:调整Filebeat的
bulk_max_size(默认50条)。# Filebeat配置 output.kafka: bulk_max_size: 200 compression: gzip
-
选择性采集:忽略健康检查等无用日志。
processors: - drop_event: when: contains: ["message", "GET /health"]
(3)日志存储阶段
-
冷热分离:
-
热数据存SSD(近7天日志),冷数据存HDD(历史归档)。
-
ES索引生命周期管理(ILM):
PUT _ilm/policy/logs_policy { "policy": { "phases": { "hot": {"actions": {"rollover": {"max_size": "50GB"}}}, "delete": {"min_age": "30d", "actions": {"delete": {}}} } } }
-
-
压缩存储:
-
ES启用
best_compression,Kafka启用snappy压缩。
-
关于为什么logger.warn()之前要使用logger.isWarnEnabled()?
主要是在很多框架源码上有体现,如Spring;dubbo。
很多框架,在执行warn()、debug()等方法前,都会额外的调用一下isWarnEnabled()和isDebugEnabled()等方法,这是为什么呢?
isWarnEnabled、isDebugEnabled等方法,其实是判断当前日志级别是否开启的,如果开启则返回true,否则返回false。
其实,之所以要提前调用一次isWarnEnabled,主要是为了提升性能的,因为在记录日志时,生成日志消息的过程可能会涉及方法的执行、字符串的拼接、对象的序列化等操作。而这些操作都是比较耗费时间的。
通过logger.isWarnEnabled做一次前置判断,那么就可以在warn级别不生效时,能避免 JSON.toJSONString(loginRequest)方法的执行,也能避免"This is a message with: " + JSON.toJSONString(loginRequest)这个字符串拼接操作的执行。
所以,使用logger.isXxxEnabled()用于检查日志Xxx级别是否启用,可以在需要时避免不必要的开销,提高应用程序的性能。这种做法特别在记录频繁的日志消息时,尤为重要。
五、典型问题与解决方案
1. 日志丢失风险
-
问题:服务崩溃时内存中的日志未持久化。
-
解决:
-
同步写入本地文件 + 定期
fsync(牺牲部分性能)。 -
使用
LMAX Disruptor无锁队列(Log4j 2默认)。
-
2. 日志爆炸式增长
-
问题:一个错误循环打印日志占满磁盘。
-
解决:
-
限流控制:Logback的
TurboFilter限制单位时间日志量。 -
动态降级:根据系统负载自动关闭DEBUG日志。
-
3. 分布式追踪困难
在很多时候,我们会在日志中打印一个链路追踪的信息,如trace_id,但是因为这里是异步打印的,ThreadLocal中存储的trace_id就无法获取了,就会导致日志中无法记录trace_id了。
-
问题:跨服务请求链路无法关联。
-
解决:
-
方法一:TraceID注入:通过MDC(Mapped Diagnostic Context)传递。
MDC.put("traced", UUID.randomUUID().toString());或者
MDC.put("traceId", threadPoolTaskData.toString());
-
结构化日志:统一输出JSON格式,便于分析。
{ "timestamp": "2023-08-20T12:00:00Z", "level": "ERROR", "traceId": "abc123", "service": "order-service", "message": "Payment failed" }方法二:使用阿里开源的TTL(TransmittableThreadLocal),来解决threadlocal父子线程直接的参数传递问题。
-
首先
InheritableThreadLocal是用于主子线程之间参数传递的,但是,这种方式有一个问题,那就是必须要是在主线程中手动创建的子线程才可以,而现在池化技术非常普遍了,很多时候线程都是通过线程池进行创建和复用的,这时候InheritableThreadLocal就不行了。
- TransmittableThreadLocal这个类继承并加强InheritableThreadLocal类。用来实现线程之间的参数传递,分布式跟踪系统 或 全链路压测(即链路打标)和日志收集记录系统上下文。
关于InheritableThreadLocal实现父子线程参数传递的底层原理
InheritableThreadLocal 是 Java 标准库提供的类,它通过以下方式实现父子线程值传递:
-
当父线程创建子线程时,子线程会复制父线程中所有 InheritableThreadLocal 变量的值
InheritableThreadLocal<String> itl = new InheritableThreadLocal<>(); itl.set("parent_value"); // 存储在父线程的ThreadLocalMap中
如果父线程创建子线程时,会发生以下关键步骤:
// Thread 构造方法关键部分
public Thread(Runnable target) {
init(null, target, "Thread-" + nextThreadNum(), 0);
}
private void init(ThreadGroup g, Runnable target, String name, long stackSize) {
init(g, target, name, stackSize, null, true);
}
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc,
boolean inheritThreadLocals) {
// ...
// 关键代码:如果父线程有inheritableThreadLocals,则复制到子线程
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
// ...
}
这个复制过程发生在 Thread 构造期间
ThreadLocal.createInheritedMap() 方法的实现:复制的过程
static ThreadLocalMap createInheritedMap(ThreadLocalMap parentMap) {
// 创建新的ThreadLocalMap,并将父线程的所有InheritableThreadLocal值复制过来
return new ThreadLocalMap(parentMap);
}
// ThreadLocalMap的构造方法
private ThreadLocalMap(ThreadLocalMap parentMap) {
Entry[] parentTable = parentMap.table;
int len = parentTable.length;
setThreshold(len);
table = new Entry[len];
// 遍历父线程的所有Entry并复制
for (int j = 0; j < len; j++) {
Entry e = parentTable[j];
if (e != null) {
@SuppressWarnings("unchecked")
ThreadLocal<Object> key = (ThreadLocal<Object>) e.get();
if (key != null) {
// 关键点:这里调用childValue方法进行值复制
Object value = key.childValue(e.value);
Entry c = new Entry(key, value);
int h = key.threadLocalHashCode & (len - 1);
while (table[h] != null)
h = nextIndex(h, len);
table[h] = c;
size++;
}
}
}
}
默认实现是直接返回原值:
// InheritableThreadLocal类中的方法
protected T childValue(T parentValue) {
return parentValue;
}//这意味着默认情况下子线程获得的是父线程值的引用(对于对象类型)。如果要实现深拷贝,可以重写此方法。
子线程后续对这些变量的修改不会影响父线程的值,怎么实现的
关键在于 ThreadLocalMap 的存储结构:
-
每个线程有独立的存储:每个线程(Thread对象)都有自己的
inheritableThreadLocals字段(ThreadLocalMap类型) -
值存储位置不同:
-
父线程的值存储在父线程的ThreadLocalMap中
-
子线程复制得到的是值的副本,存储在自己的ThreadLocalMap中
-
-
访问时获取当前线程的值:
-
当调用
itl.get()时,实际上是获取当前线程的ThreadLocalMap中的值 -
不同线程访问同一个InheritableThreadLocal实例,会各自访问自己线程的存储
-
InheritableThreadLocal 的缺点?
线程池场景失效:线程池中的线程是复用的,当任务提交到线程池时,实际执行的线程可能早已创建完毕,导致无法获取提交任务时的上下文
单向传递:只能从父线程传递到子线程,无法反向传递
生命周期问题:线程池中的线程可能长期存活,导致 InheritableThreadLocal 的值长期存在,可能引发内存泄漏
异步链路断裂:在复杂的异步调用链中(如 CompletableFuture),无法正确传递上下文
关于TransmittableThreadLocal实现父子线程参数传递的底层原理
TTL 的核心思想是"捕获-传递-恢复"模式:
-
捕获:在任务提交时捕获当前线程的所有 TTL 值
-
传递:将捕获的值与任务一起传递
-
恢复:在任务执行时,在执行线程中恢复这些值
具体流程如下:非常复杂。
底层实现原理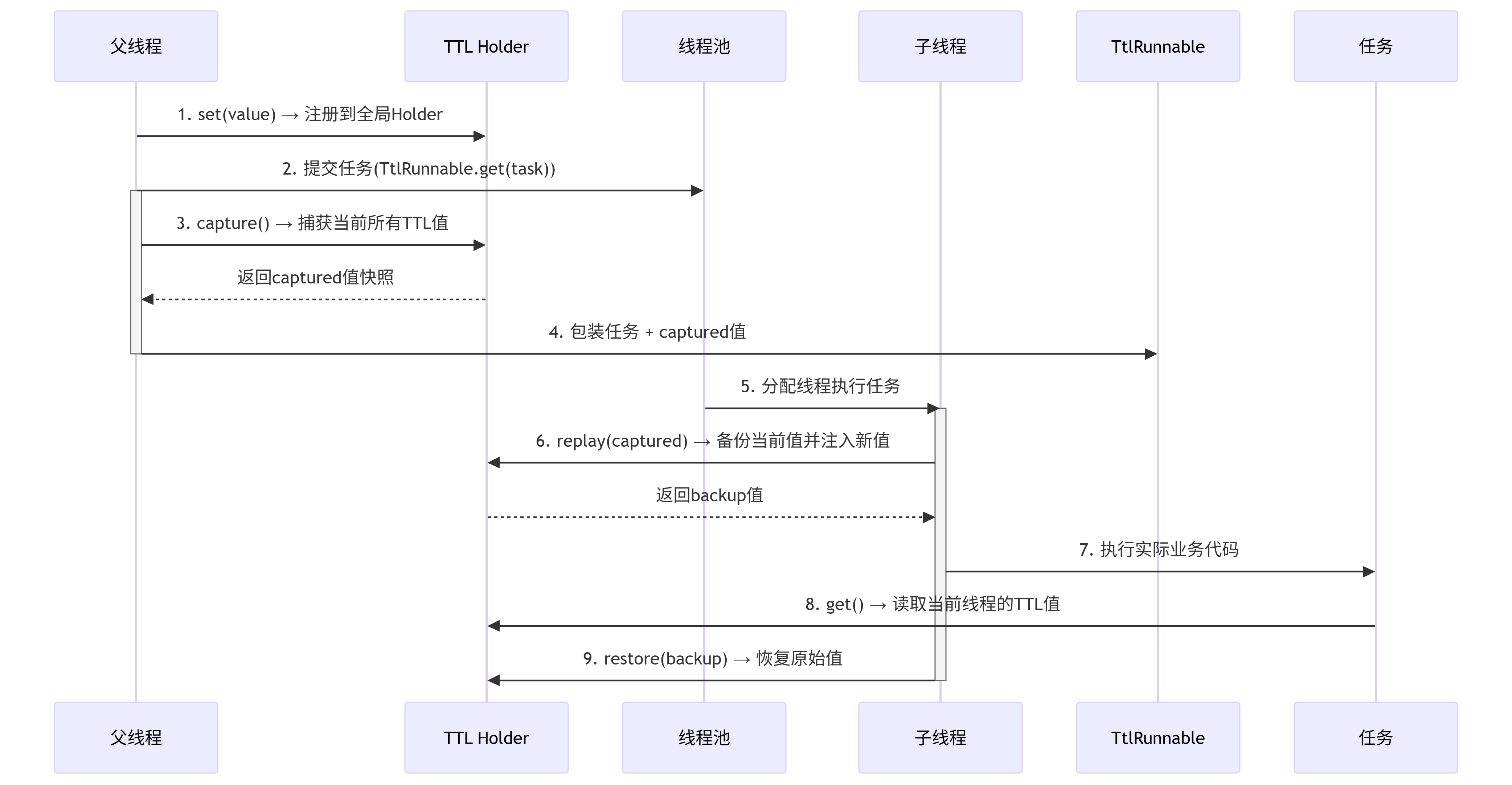
说一下关键步骤吧;
注册(注册到waekHashmap的holder中) ->
捕获(get(方法) + capture()方法遍历所有ttl) ->
包装(原始任务 + capture() 包装为ttlrunable) ->
恢复值(replay()获得captured值) ->
执行任务(其他业务get()方法获取值) ->
清理还原(finally 中 restore() 方法恢复原始值)
阶段一:任务提交时(解决线程池复用问题)
| 步骤 | TTL 机制 | 解决 InheritableThreadLocal 的问题 |
|---|---|---|
| 1. 注册值 | TTL.set() 将值存入父线程,同时注册到全局 WeakHashMap 的 Holder | 避免线程池线程无法获取最新值 |
| 2. 捕获快照 | TtlRunnable.get() 调用 capture(),遍历 Holder 中所有 TTL 实例,保存当前值 | 动态捕获而非依赖线程创建时的复制 |
| 3. 包装任务 | 将原始任务 + captured 值快照封装为 TtlRunnable | 确保任务与上下文绑定,而非与线程绑定 |
阶段二:任务执行时(解决异步链路断裂和内存泄漏)
| 步骤 | TTL 机制 | 解决 InheritableThreadLocal 的问题 |
|---|---|---|
| 4. 恢复值 | 线程池线程执行时,replay() 将 captured 值注入当前线程的 TTL | 线程池线程也能获取提交时的上下文 |
| 5. 执行任务 | 业务代码通过 TTL.get() 读取当前线程的值 | 透明使用,无感知传递 |
| 6. 清理还原 | finally 中调用 restore() 恢复线程原始值 | 避免污染线程池线程的下一次执行 |
1. TransmittableThreadLocal 类
public class TransmittableThreadLocal<T> extends InheritableThreadLocal<T> {
// 全局持有所有TTL实例的WeakReference
private static InheritableThreadLocal<WeakHashMap<TransmittableThreadLocal<Object>, ?>> holder =
new InheritableThreadLocal<WeakHashMap<TransmittableThreadLocal<Object>, ?>>() {
@Override
protected WeakHashMap<TransmittableThreadLocal<Object>, ?> initialValue() {
return new WeakHashMap<>();
}
};
@Override
public final T get() { /*...*/ }
@Override
public final void set(T value) {
super.set(value);
// 注册到holder中
if (null == value) removeValue();
else addValue();
}
// 其他关键方法...
}
2. 值传递的核心机制
TTL 通过包装 Runnable/Callable 实现值的传递:
// 包装Runnable
public static TtlRunnable get(Runnable runnable) {
if (null == runnable) return null;
// 捕获当前线程的所有TTL值
Object captured = capture();
return new TtlRunnable(runnable, captured);
}
private static Object capture() {
// 获取当前线程的所有TTL值
HashMap<TransmittableThreadLocal<Object>, Object> captured =
new HashMap<>();
for (TransmittableThreadLocal<Object> threadLocal : holder.get().keySet()) {
captured.put(threadLocal, threadLocal.copyValue());
}
return captured;
}
3. 任务执行时的值恢复
// TtlRunnable的执行逻辑
public void run() {
Object backup = replay(captured);
try {
runnable.run();
} finally {
restore(backup);
}
}
private static Object replay(Object captured) {
// 备份当前线程的TTL值
HashMap<TransmittableThreadLocal<Object>, Object> backup =
new HashMap<>();
// 恢复捕获的值
for (Map.Entry<TransmittableThreadLocal<Object>, Object> entry :
((HashMap<TransmittableThreadLocal<Object>, Object>) captured).entrySet()) {
backup.put(entry.getKey(), entry.getKey().get());
entry.getKey().set(entry.getValue());
}
return backup;
}
private static void restore(Object backup) {
// 恢复原来的值
for (Map.Entry<TransmittableThreadLocal<Object>, Object> entry :
((HashMap<TransmittableThreadLocal<Object>, Object>) backup).entrySet()) {
entry.getKey().set(entry.getValue());
}
}
如何解决 InheritableThreadLocal 的缺点
1. 线程池场景失效问题
解决方案:
-
通过 TtlRunnable/TtlCallable 包装任务,在任务执行前动态设置值
-
不依赖线程创建时的值复制,而是每次任务执行前都会设置正确的上下文
关键代码:
ExecutorService executor = Executors.newFixedThreadPool(1);
TransmittableThreadLocal<String> context = new TransmittableThreadLocal<>();
context.set("value-1");
executor.execute(TtlRunnable.get(() -> {
System.out.println(context.get()); // 输出 "value-1"
}));
context.set("value-2");
executor.execute(TtlRunnable.get(() -> {
System.out.println(context.get()); // 输出 "value-2"
}));
2. 异步链路断裂问题
解决方案:
-
支持各种异步编程模式(CompletableFuture、RxJava等)
-
提供 TtlWrappers 工具类包装各种异步组件
示例:
TransmittableThreadLocal<String> context = new TransmittableThreadLocal<>();
context.set("value");
CompletableFuture.supplyAsync(TtlWrappers.wrapSupplier(() -> {
System.out.println(context.get()); // 输出 "value"
return "result";
}));
3. 内存泄漏问题
解决方案:
-
使用 WeakHashMap 持有 TTL 实例,避免强引用
-
任务执行完成后自动恢复原来的值
-
提供 clear 方法手动清理
关键设计:
private static class TtlRunnable implements Runnable {
private final Runnable runnable;
private final Object captured;
public void run() {
Object backup = replay(captured);
try {
runnable.run();
} finally {
restore(backup); // 确保恢复原值
}
}
}
4. 单向传递问题
解决方案:
-
提供 Transmitter 类支持更复杂的传递模式
-
支持捕获当前上下文并在其他地方应用
示例:
TransmittableThreadLocal<String> context = new TransmittableThreadLocal<>();
context.set("value");
// 捕获当前上下文
Object captured = Transmitter.capture();
new Thread(() -> {
// 在另一个线程中恢复
Object backup = Transmitter.replay(captured);
try {
System.out.println(context.get()); // 输出 "value"
} finally {
Transmitter.restore(backup);
}
}).start();
高级特性
-
值拷贝策略:
-
默认是引用传递,可通过重写
copyValue方法实现深拷贝
TransmittableThreadLocal<MyObject> ttl = new TransmittableThreadLocal<MyObject>() { @Override protected MyObject copyValue(MyObject parentValue) { return parentValue.clone(); // 深拷贝 } }; -
-
生命周期回调:
-
提供
beforeExecute和afterExecute回调
TransmittableThreadLocal<String> ttl = new TransmittableThreadLocal<String>() { @Override protected void beforeExecute() { // 任务执行前的回调 } @Override protected void afterExecute() { // 任务执行后的回调 } }; -
-
线程池包装:
-
可以直接包装整个线程池
ExecutorService executor = Executors.newFixedThreadPool(1); ExecutorService ttlExecutor = TtlExecutors.getTtlExecutorService(executor); // 现在所有提交的任务都会自动包装
-
性能优化
-
懒加载:只有在真正需要传递时才捕获值
-
轻量级捕获:只捕获实际设置的TTL值
-
避免重复包装:已经包装过的Runnable不会重复包装
六、前沿技术演进
-
eBPF日志采集:
-
无需修改应用代码,通过内核层抓取日志(如Pixie)。
-
-
Serverless日志架构:
-
使用AWS Lambda或FaaS实时处理日志流。
-
-
AI日志分析:
-
异常检测(如Elastic ML)、日志聚类(如LogReduce)。
-
总结
-
选型建议:
-
单体应用:Logback + ELK
-
云原生架构:Fluentd + Loki + Grafana
-
-
核心原则:
-
可靠性 > 实时性 > 存储成本
-
生产环境务必启用异步日志和采样!
-
-
未来趋势:
-
日志与Metrics、Tracing的融合(OpenTelemetry)。
-
基于日志的主动运维(AIOps)。
-

















 1030
1030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









