







一、版权与责任归属风险
1.1 训练数据合规路径
| 数据来源类型 | 法律风险 | 合规方案 |
|---|---|---|
| 公开爬取数据 | 著作权侵权 | 签署CC协议内容过滤 |
| 商业授权数据 | 高成本 | 建立数据权益交易平台 |
| 合成生成数据 | 真实性争议 | 添加水印+元数据 |
# 训练数据版权过滤实现
def check_copyright(text):
nlp = spacy.load("en_core_web_lg")
doc = nlp(text)
for ent in doc.ents:
if ent.label_ in ["WORK_OF_ART", "LAW"]:
return False
return True
1.2 生成内容责任界定
-
用户提示责任:记录完整交互日志
-
平台审核义务:建立三级内容过滤机制
-
技术可追溯性:区块链存证+数字水印
二、隐私保护技术方案
2.1 跨模态匿名化流程
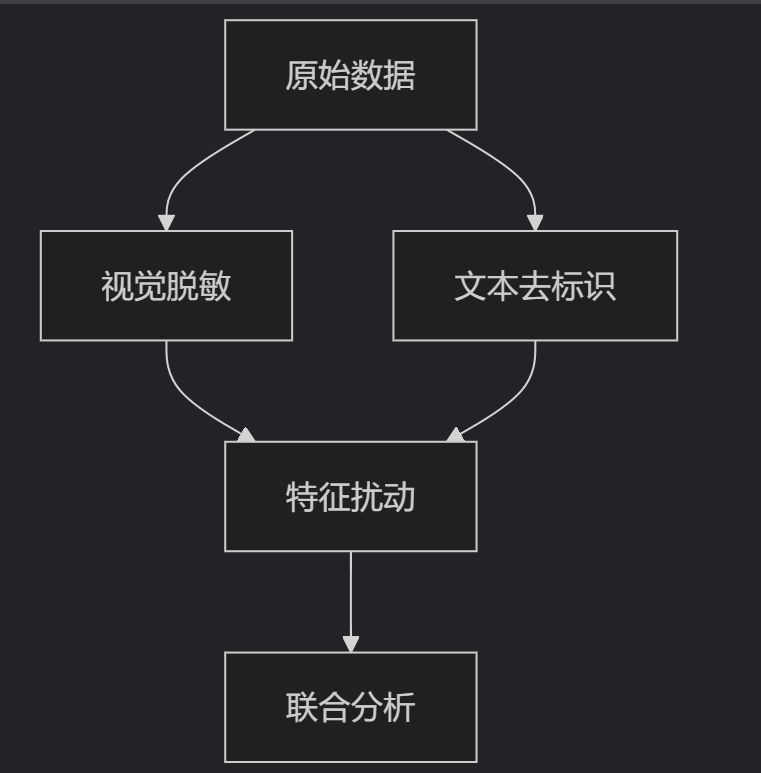
2.2 关键技术实现
| 技术 | 医疗场景应用 | 金融场景要求 |
|---|---|---|
| 差分隐私 | 添加高斯噪声(σ=0.1) | 满足GDPR标准 |
| 联邦学习 | 医院间模型协同 | 跨机构数据隔离 |
| 同态加密 | 基因数据分析 | 交易记录保护 |
# 图像差分隐私处理
def add_noise(image, epsilon=0.5):
noise = torch.randn_like(image) * epsilon
return image + noise
三、伦理风险防控体系
3.1 偏见检测与消除
检测指标:
-
性别职业关联度
-
种族描述均衡性
-
地域经济偏见指数
修正方案:
# 去偏见损失函数
def debias_loss(output, target):
base_loss = F.cross_entropy(output, target)
bias_penalty = calculate_group_fairness(output)
return base_loss + 0.3*bias_penalty
3.2 深度伪造防御
| 技术手段 | 检测准确率 | 适用场景 |
|---|---|---|
| 心跳检测 | 92.3% | 视频认证 |
| 频谱分析 | 88.7% | 音频验证 |
| 神经水印 | 95.1% | 图像溯源 |
四、企业合规实践
4.1 伦理审查委员会架构
CEO │ ├── 技术伦理组(算法安全) ├── 法律合规组(政策解读) └── 社会影响组(公众沟通)
4.2 透明化报告要素
-
训练数据来源占比
-
模型偏差测试结果
-
用户投诉处理流程
-
第三方审计报告
五、全球政策动态
5.1 欧盟AI法案要点
| 风险等级 | 多模态应用示例 | 合规要求 |
|---|---|---|
| 不可接受 | 社会信用评分 | 禁止 |
| 高风险 | 医疗诊断辅助 | CE认证+人工监督 |
| 有限风险 | 广告生成 | 内容标注义务 |
5.2 中国生成式AI新规
-
备案要求:算法备案+数据安全评估
-
内容标识:统一生成内容标识符
-
实名管理:开发者后台实名认证
六、实施路线图
-
合规评估阶段(1-2月)
-
数据资产审计
-
风险等级划分
-
-
技术整改阶段(3-6月)
-
部署隐私增强技术
-
建立内容审核API
-
-
制度完善阶段(持续)
-
制定AI使用伦理章程
-
开展员工合规培训
-
合规工具推荐:


















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









