






首先,第一反应就是把打开歌曲链接,f12审查元素.
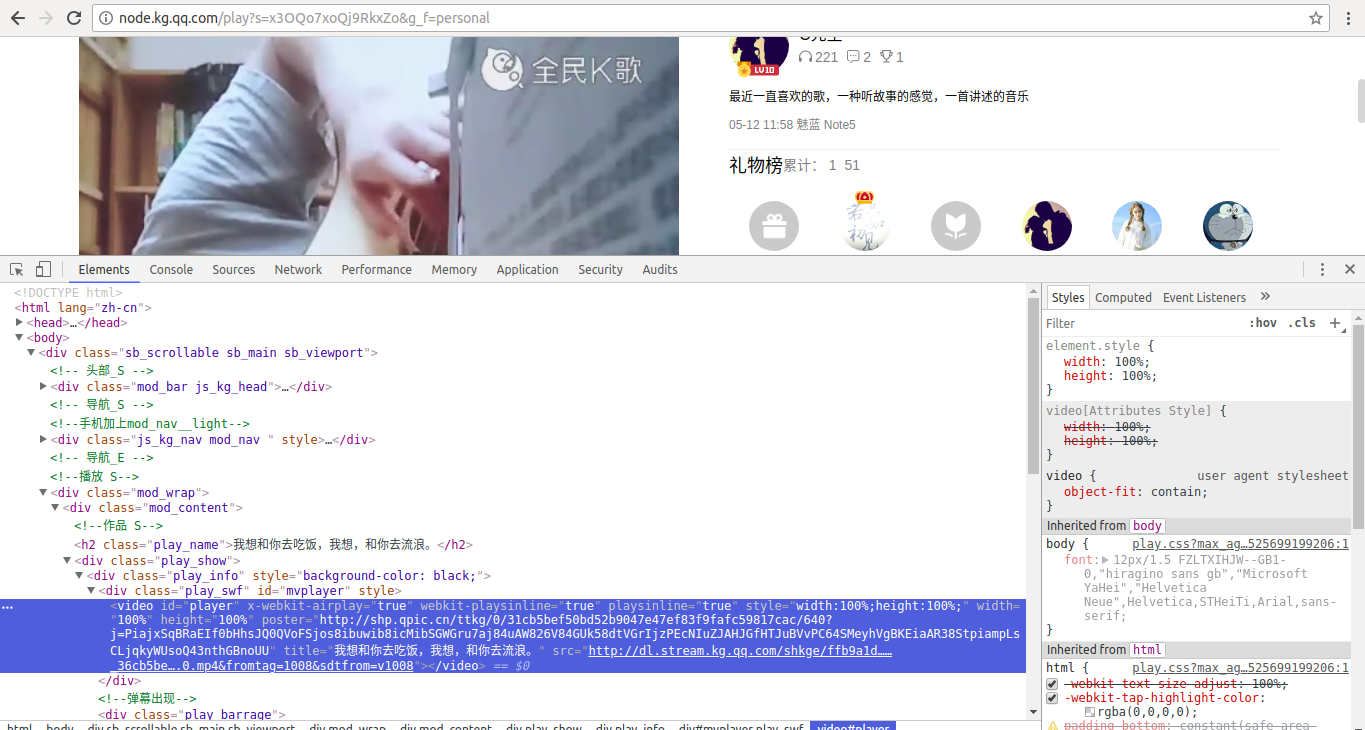
会发现,我们的视频链接在一个video 标签内的src 里面,那这不就简单了?直接爬整个页面的html 代码,然后正则匹配拿到src 里面的链接不就好了吗?
结果呢,爬下来发现根本没有video 这个标签!
后来自己有开了一个音频,看了一下元素,发现原来video 标签的地方变成了audio 标签,这说明啥?说明人家的页面是动态生成的啊,然后跑去看了一下人家的js ,的确如此.
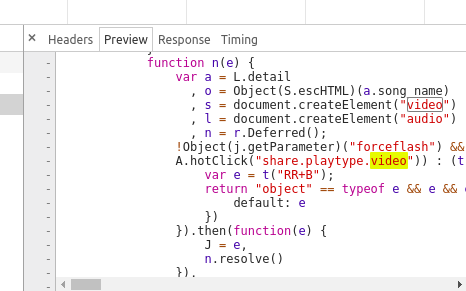
那可咋整?小编也是初学,以前爬过百度图片的动态页面,知道用带有请求数据访问然后得到json 的data数据,再把 data里面自己要用的数据拿出来就好了.但是这个…好像有点不一样.翻遍了所有的包都没找到有用的data数据
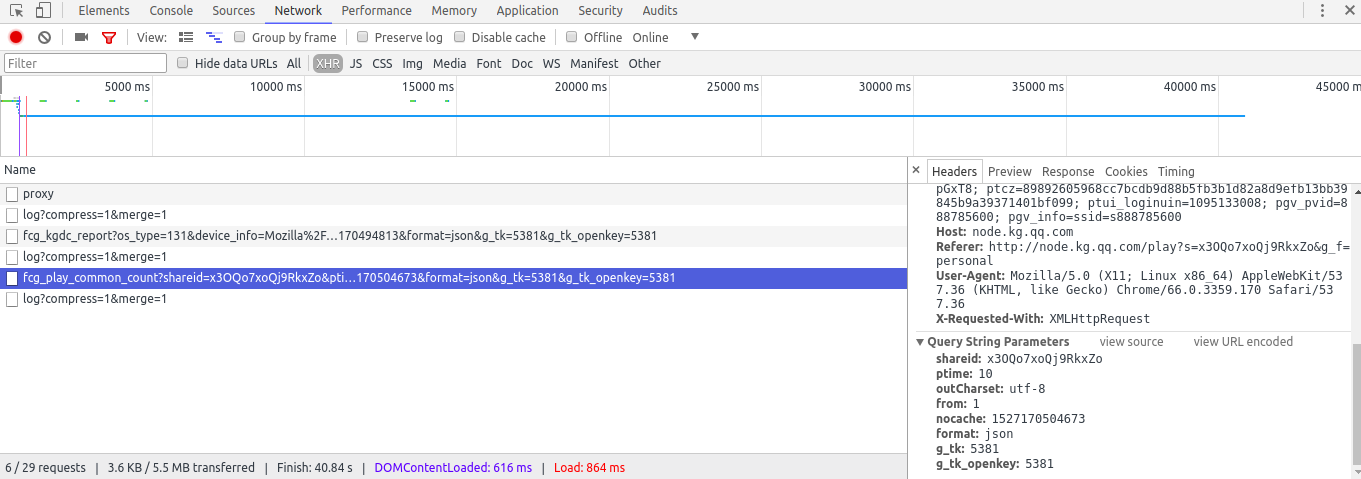
结果发现这个请求参数有点意思,有一个shareid 就是网址中s=key 的key,当然啦 这两个肯定是要一样的,但是问题是我们拿到的链接就已经包含了这个shareid ,也就是说,我们不需要再向url 中添加其他的请求参数,我们就可以拿到视频加载后的html 代码了,不过这个video 标签我该怎么让他通过js 生成出来呢…
百度啊!!!Selenium+PhantomJS 跑一遍,就能得到动态页面加载完成后的html 代码了.啊!也就简单的几步,被自己搞了好久,不过还是要多踩坑才能学到东西嘛~~
废话说到这,直接贴代码了:
# coding = utf-8
# author YongGuang Li by 2018/05/24
import urllib.request
import re
import requests
import json
from selenium import webdriver
#1.0版本还只是针对mv的链接下载,对于音频的下载其实也大同小异,改一下正则表达式就好了.
#通过输入的url 获取动态生成后的页面html 代码
def getHtml(url):
driver=webdriver.PhantomJS()
driver.get(url)
page = driver.page_source
#print(page)
return page
#在html 代码里面通过正则匹配获取到视频的下载链接
def getVideo(html,path):
reg = 'src="(.+?)"></video>' #正则匹配 拿到vedio 标签内的下载链接
vediore = re.compile(reg)
vedios = re.findall(vediore, html)
x=1
for video in vedios:
video=video.replace(';','&') #获取的到的video 下载链接所有的'&'变成了';' 本人还不清楚原因,不过转换一下就好了
print("正在下载:%s" %video)
urllib.request.urlretrieve(video, path+'/%d.mp4'%x)
print("已下载完成:%s"%video)
x = x+1
yield video
#write 仅仅用来测试,作用就是将链接写到文件里
def write(html):
with open("/home/cxiansheng/文档/a.txt",'w') as f:
for h in html:
f.write(h)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









