







【机器学习|评价指标8】混淆矩阵(Confusion Matrix)、Cohen‘s Kappa 系数、详解,平均交并比(mIoU)、列联表(Contingency Table)附代码。
【机器学习|评价指标8】混淆矩阵(Confusion Matrix)、Cohen‘s Kappa 系数、详解,平均交并比(mIoU)、列联表(Contingency Table)附代码。
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/147776758
前言
- 真正例(True Positive, TP):模型正确地将正类样本预测为正类。
- 假正例(False Positive, FP):模型错误地将负类样本预测为正类。
- 真负例(True Negative, TN):模型正确地将负类样本预测为负类。
- 假负例(False Negative, FN):模型错误地将正类样本预测为负类。
混淆矩阵(Confusion Matrix)
概念
- 混淆矩阵用于评估分类模型的性能,通过比较预测标签与真实标签的关系,统计 TP(真正例)、FP(假正例)、FN(假负例)和 TN(真负例)的数量。
Python 示例
from sklearn.metrics import confusion_matrix
# 假设的真实标签和预测标签
y_true = [0, 1, 1, 0, 1, 0]
y_pred = [0, 1, 0, 0, 1, 1]
# 计算混淆矩阵
cm = confusion_matrix(y_true, y_pred)
print("Confusion Matrix:")
print(cm)
Cohen’s Kappa 系数(Cohen’s Kappa Coefficient)
概念
- Cohen’s Kappa 系数用于衡量两个分类器或评估者之间的一致性,考虑了偶然一致的可能性。
数学公式
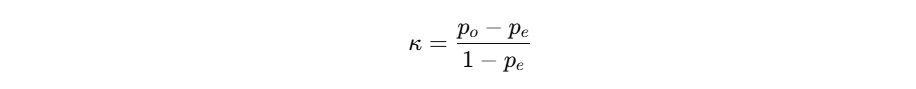
其中:
- p o p_o po 是观察到的一致性(即准确率)
- p e p_e pe是预期的一致性(即随机一致的概率)
Python 示例
from sklearn.metrics import cohen_kappa_score
# 假设的两个评估者的分类结果
rater1 = [0, 1, 1, 0, 1, 0]
rater2 = [0, 1, 0, 0, 1, 1]
# 计算 Cohen's Kappa 系数
kappa = cohen_kappa_score(rater1, rater2)
print(f"Cohen's Kappa: {kappa:.2f}")
平均交并比(Mean Intersection over Union, mIoU)
定义
- 平均交并比(mIoU)是语义分割任务中常用的评价指标,衡量预测区域与真实区域的重叠程度。
数学公式
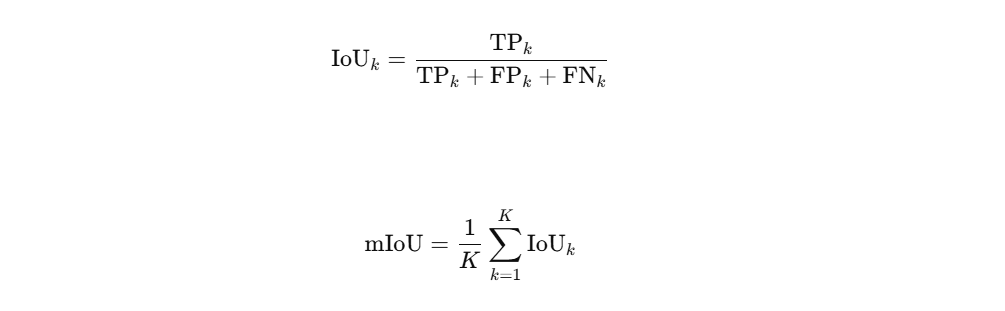
其中:
- T P k TP_k TPk 是第 k k k 类的真正例数,
- F P k FP_k FPk 是第 k k k 类的假正例数,
- F N k FN_k FNk 是第 k k k 类的假负例数,
- K K K 是类别总数。
Python 示例
import numpy as np
from sklearn.metrics import confusion_matrix
def compute_miou(y_true, y_pred, num_classes):
cm = confusion_matrix(y_true, y_pred, labels=range(num_classes))
intersection = np.diag(cm)
union = cm.sum(axis=1) + cm.sum(axis=0) - intersection
iou = intersection / np.maximum(union, 1)
miou = np.mean(iou)
return miou
# 示例数据
y_true = [0, 1, 2, 1, 0]
y_pred = [0, 2, 1, 1, 0]
# 计算 mIoU
miou = compute_miou(y_true, y_pred, num_classes=3)
print(f"mIoU: {miou:.2f}")
列联表(Contingency Table)
概念
- 列联表用于展示两个或多个分类变量之间的关系,常用于统计分析中检验变量之间的独立性。
Python 示例
import pandas as pd
# 示例数据
data = {'Gender': ['Male', 'Female', 'Male', 'Female', 'Male'],
'Purchased': ['Yes', 'No', 'Yes', 'No', 'Yes']}
df = pd.DataFrame(data)
# 创建列联表
contingency_table = pd.crosstab(df['Gender'], df['Purchased'])
print("Contingency Table:")
print(contingency_table)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











