









1. 基础概念:为什么需要深/浅拷贝?
在编程中,对象(如Java的类实例、JavaScript的Object)通常包含基本类型数据(如数字、字符串)和引用类型数据(如数组、其他对象)。拷贝对象时,若未正确处理引用类型,可能导致数据意外共享,引发难以追踪的Bug。
浅拷贝:仅复制对象的“表层”数据,引用类型的字段仍指向原对象的内存地址。
深拷贝:递归复制所有层级的数据,新旧对象完全独立。
2. 底层原理:内存模型与流程图解析
内存模型
-
栈(Stack):存储基本类型值和引用类型的地址指针深浅拷贝的解决方案。
-
堆(Heap):存储引用类型的实际数据。
浅拷贝流程
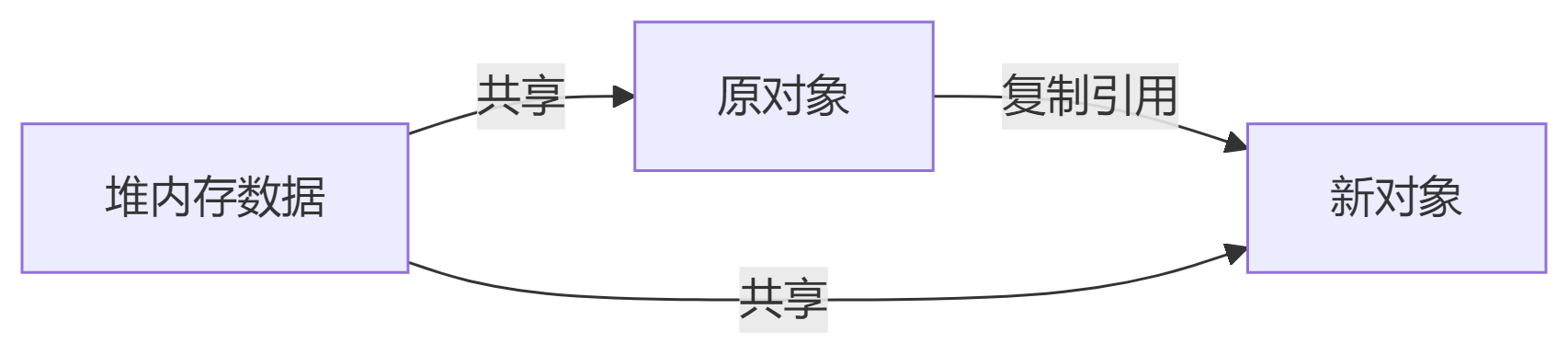
问题:修改任一对象的引用字段,另一对象同步变化。
深拷贝流程
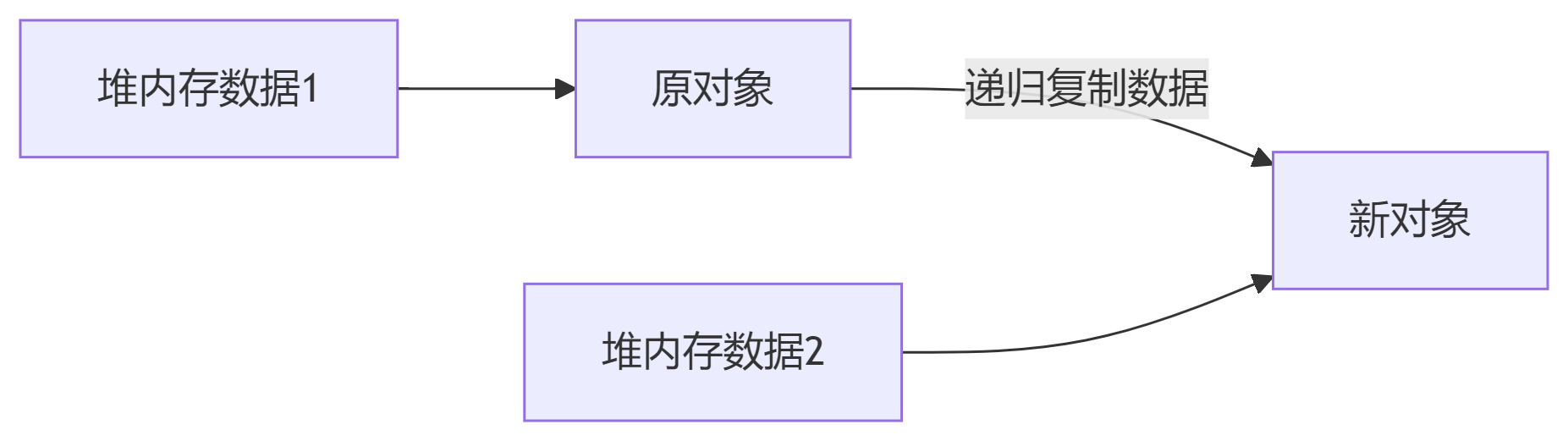
优势:新旧对象完全独立,互不影响。
3. 代码示例:不同语言的实现与陷阱
场景1:Java中的浅拷贝
class Student implements Cloneable {
String name;
int[] scores;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone(); // 默认浅拷贝
}
}
public class Main {
public static void main(String[] args) throws Exception {
Student s1 = new Student();
s1.scores = new int[]{90, 85};
Student s2 = (Student) s1.clone();
s2.scores[0] = 100; // 修改s2会影响s1的scores数组
System.out.println(s1.scores[0]); // 输出100
}
} 陷阱:默认clone()方法仅实现浅拷贝,需手动处理引用字段 浅拷贝和深拷贝在Java中的常见误解
场景2:JavaScript中的深拷贝
// 浅拷贝示例
const original = { name: "Alice", hobbies: ["reading", "coding"] };
const shallowCopy = { ...original };
shallowCopy.hobbies.push("gaming");
console.log(original.hobbies); // ["reading", "coding", "gaming"]
// 深拷贝方案1:JSON方法(无法处理函数和循环引用)
const deepCopy1 = JSON.parse(JSON.stringify(original));
// 深拷贝方案2:递归实现
function deepClone(obj) {
if (typeof obj !== 'object' || obj === null) return obj;
const clone = Array.isArray(obj) ? [] : {};
for (let key in obj) {
clone[key] = deepClone(obj[key]);
}
return clone;
} 陷阱:JSON方法会丢失函数和undefined字段。
4. 开发中的常见误区与解决方案
误区1:误以为浅拷贝足够安全
-
案例:使用
Object.assign()或扩展运算符拷贝多层嵌套对象,导致内部引用共享。 -
解决方案:始终检查对象结构,优先使用深拷贝方法。
误区2:依赖默认的clone()方法
-
案例:Java中未重写
clone()方法,导致浅拷贝引发数据污染。 -
解决方案:手动实现深拷贝逻辑或使用序列化。
误区3:忽视循环引用问题
-
案例:对象A引用对象B,对象B又引用对象A,递归深拷贝导致栈溢出。
-
解决方案:使用
WeakMap缓存已拷贝对象,或借助第三方库(如Lodash的_.cloneDeep())最全的深拷贝方案。
5. 深拷贝的终极解决方案
方案1:递归 + 类型处理
function deepClone(obj, map = new WeakMap()) {
if (obj === null || typeof obj !== 'object') return obj;
if (map.has(obj)) return map.get(obj); // 解决循环引用
let clone = Array.isArray(obj) ? [] : {};
map.set(obj, clone);
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
clone[key] = deepClone(obj[key], map);
}
}
return clone;
} 优点:支持循环引用和复杂类型(如Date、RegExp)深浅拷贝的解决方案。
方案2:序列化与反序列化
// Java示例:通过序列化实现深拷贝
public static <T extends Serializable> T deepCopy(T obj) {
try (ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(bos)) {
out.writeObject(obj);
try (ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream in = new ObjectInputStream(bis)) {
return (T) in.readObject();
}
} catch (Exception e) {
throw new RuntimeException(e);
}
} 限制:要求所有对象实现Serializable接口 浅拷贝和深拷贝的区别。
6. 总结:如何选择拷贝策略?
| 场景 | 推荐方案 | 注意事项 |
|---|---|---|
| 简单对象(无嵌套引用) | 浅拷贝(如扩展运算符) | 检查是否包含引用类型字段 |
| 复杂对象(多层嵌套) | 递归深拷贝 | 处理循环引用和特殊类型(如Date) |
| 高性能需求 | 第三方库(如Lodash) | 避免重复造轮子 |
| 不可变数据 | 浅拷贝 | 适用于Redux状态管理等场景 |
流程图:深拷贝决策树
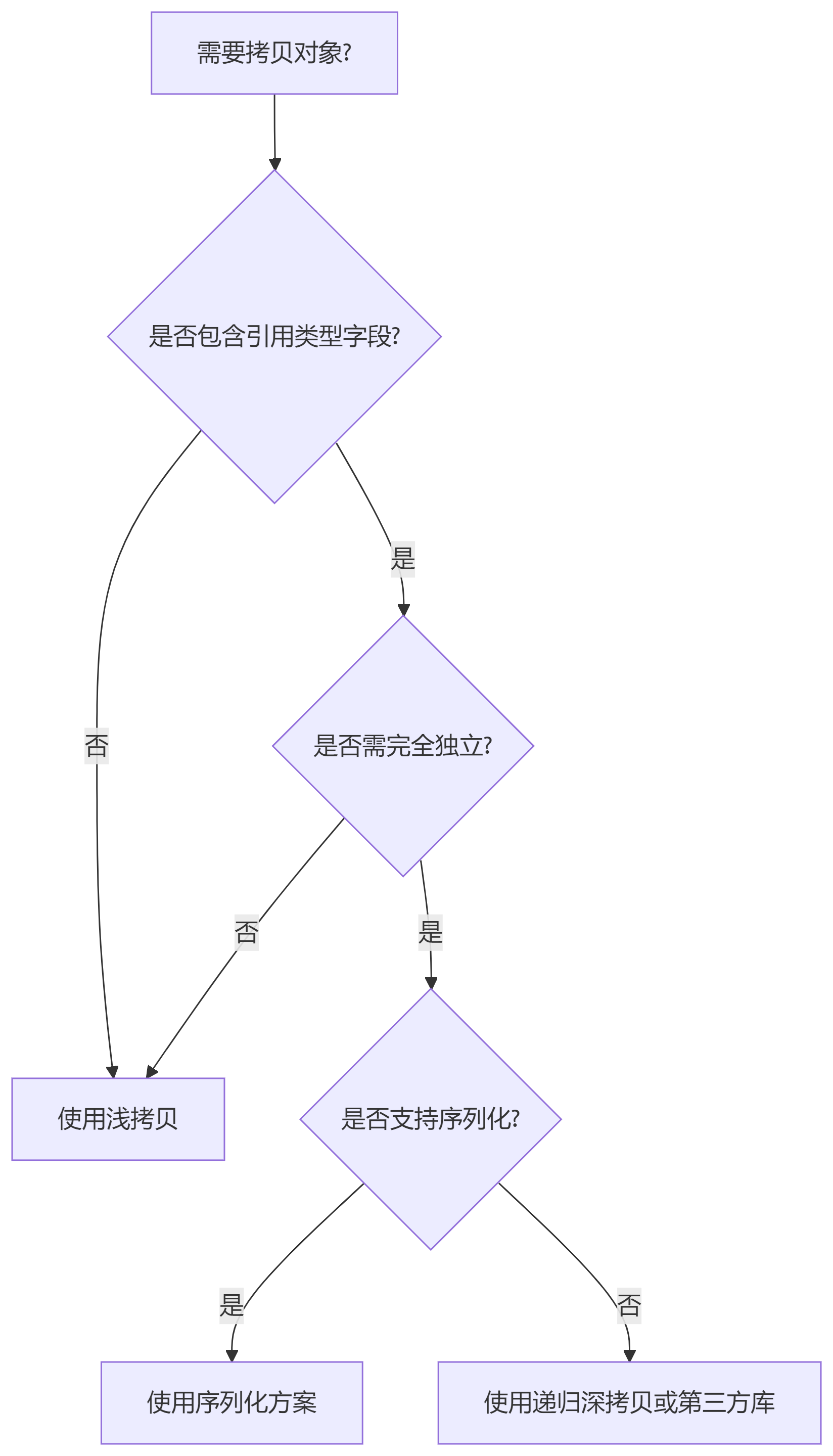
关键点:根据数据结构、性能需求和环境支持灵活选择策略。

















 1283
1283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









