






一,伪分布Hadoop的搭建
1,上传安装包并卸载jdk自带的包
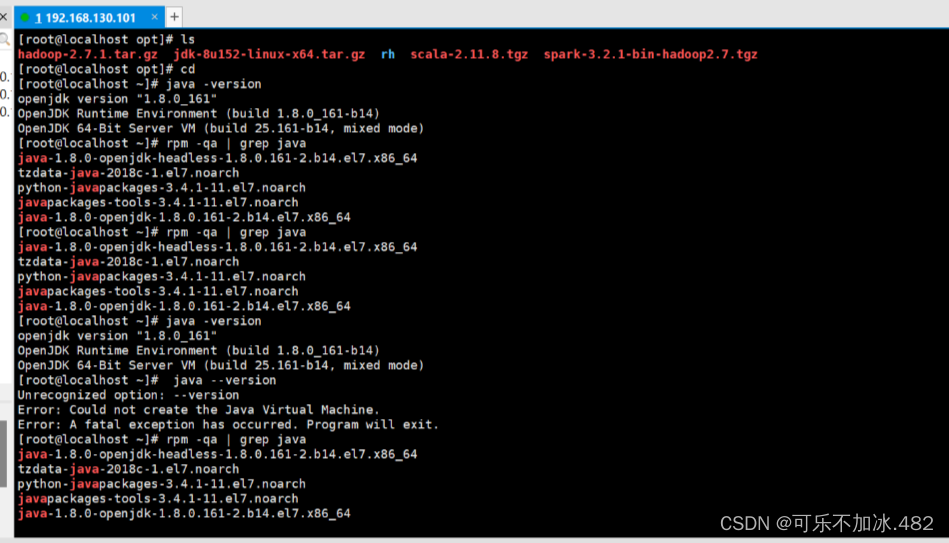
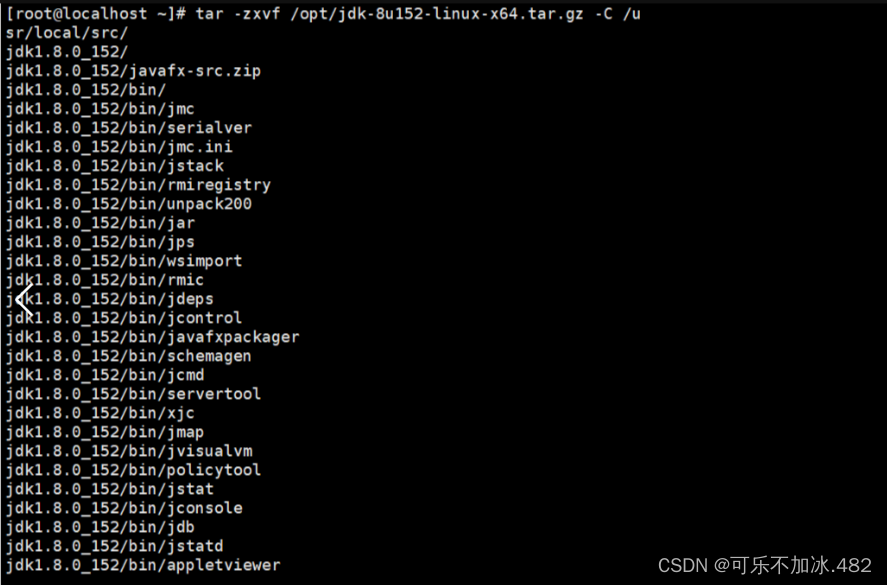
2,解压安装包到指定目录并编辑JDK环境
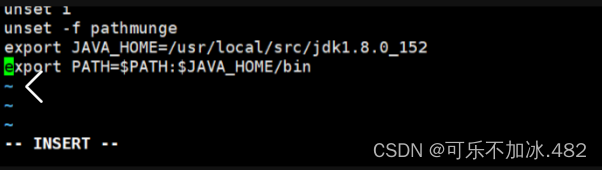
!!!编辑完要使它生效

3,Hadoop的环境配置
解压安装包并将名字改为Hadoop,及编写环境变量
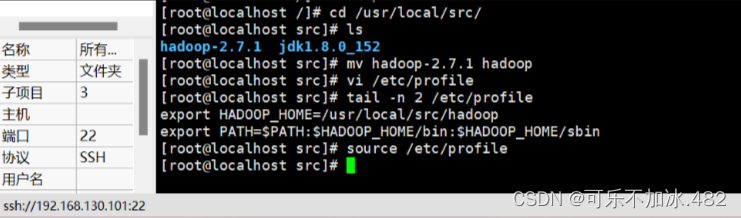
编辑其它配置文件
(1) 编写hadoop-env.sh


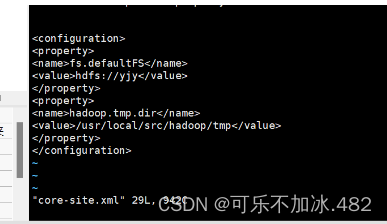
(2)编写core-site.xml

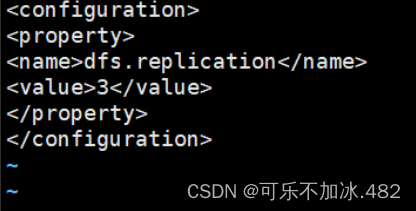
(3)编写hdfs-site.xml

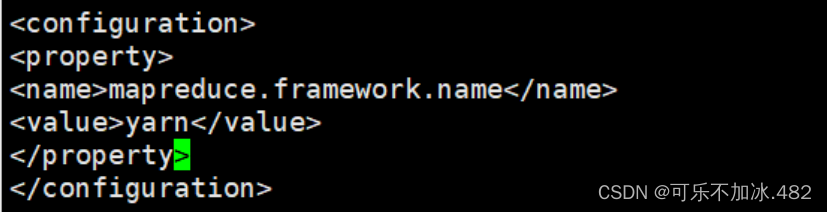
(4)改名并编辑mapred-site.xml
![]()
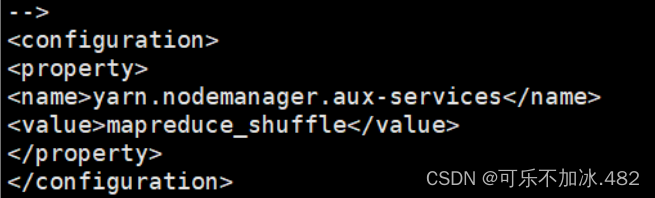
(5)编写yarn-site.xml
![]()
(6)编写salves
![]()
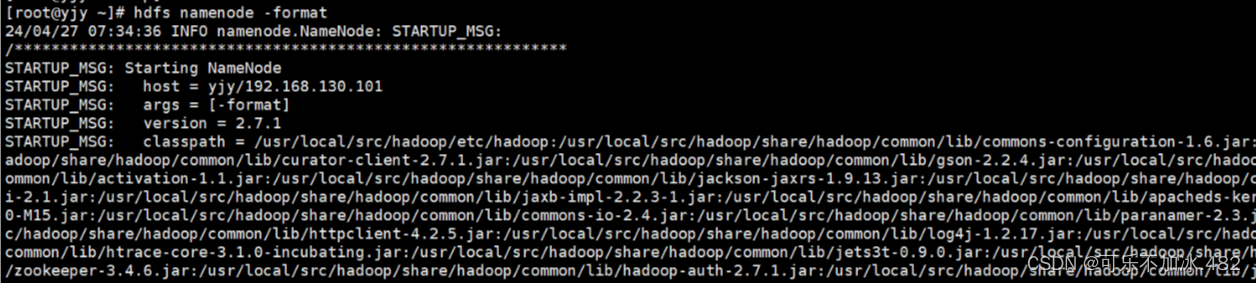
格式化 hdsf
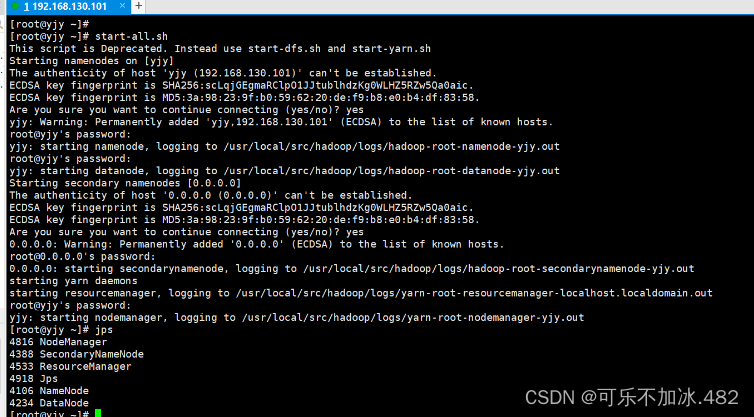
4,Hadoop的启动及集群的查看
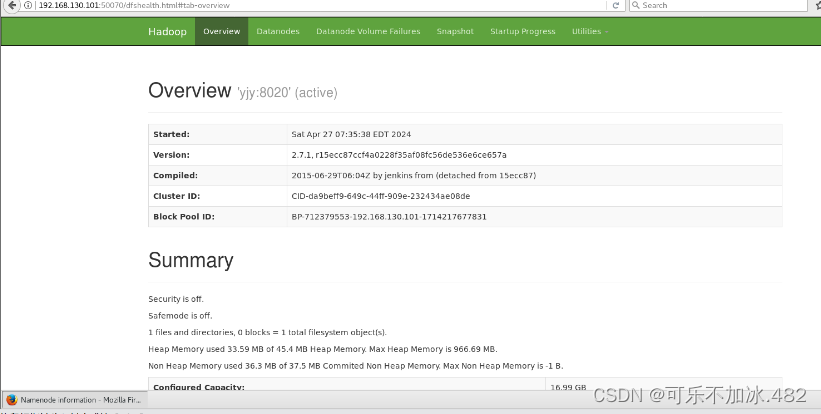
关于开启start -all.sh时Namenode和Datanode有时消失的解决办法
Namenode的解决办法
先查看端口,看是否被占用,如果被占直接kill - 9 端口号然后找到core-site.xml文件进行编写 将里面的端口号改为其它
Datanode的解决方法
大部分是由于多次启动或格式化导致DataNode和Namenode的ID号不同
1,首先关闭所有进程stop -all.sh
2,进入Hadoop的安装目录 找到存放data,name的目录(一般默认在Hadoop的tmp/dfs下)
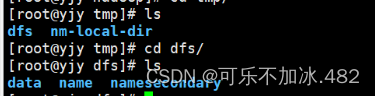
更改ID号使其data和name里的VERSION clusterID相同(name和data里的都要更改)
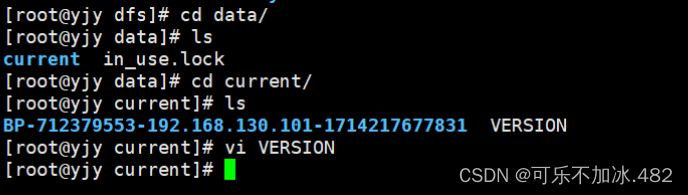
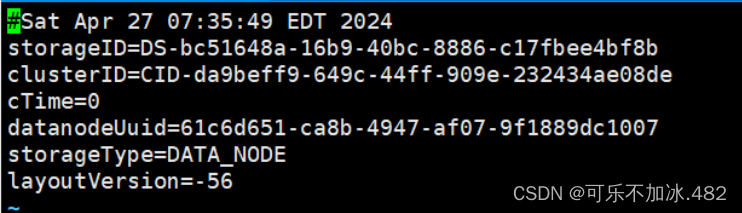
更改完成后重新启动再输入jps就可以看到有Namenode及DataNode了
二,伪分布Spark的搭建
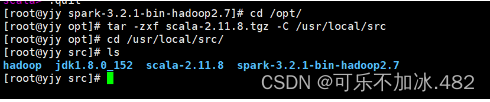
1,安装包解压

2,配置文件的改名及编写


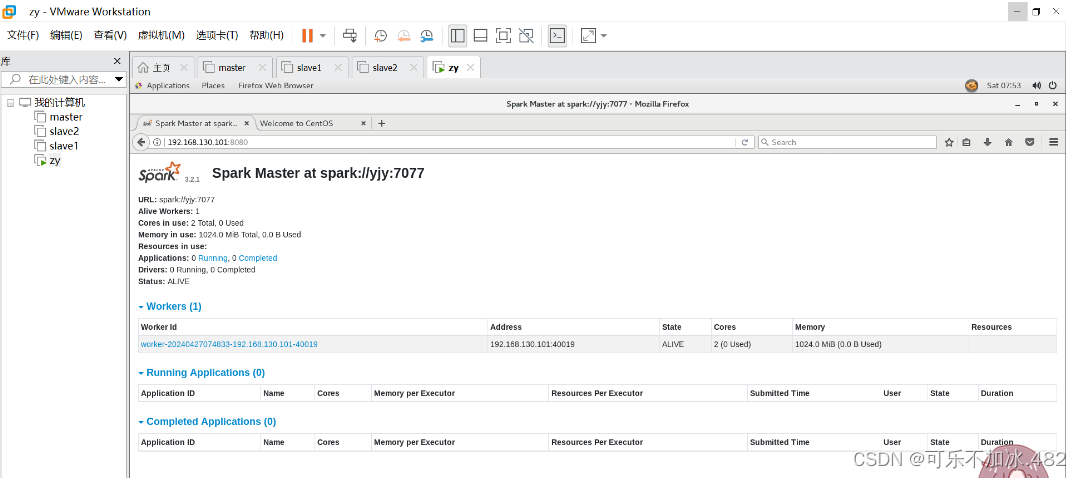
3,进入spark集群并查看
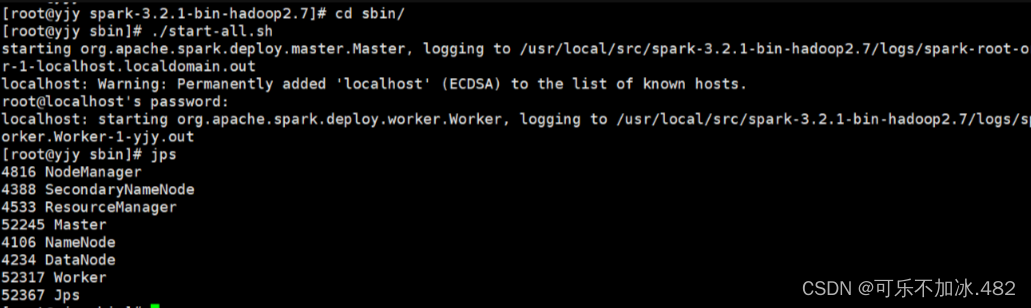
4,启动spark-shell
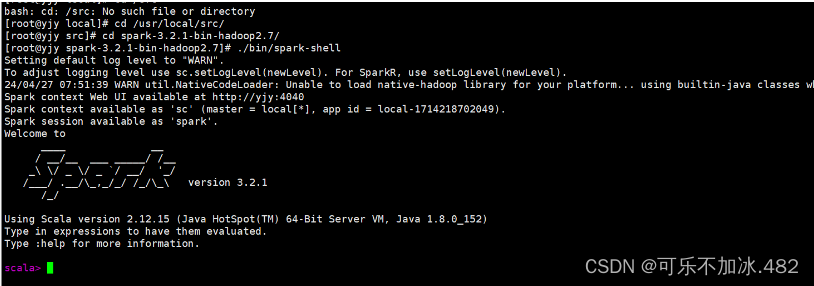
输入:quit即可退出spark-shell
三,伪分布Scala的搭建
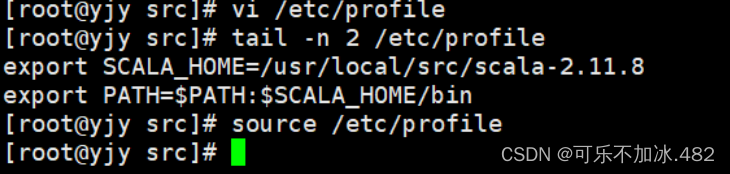
1,解压安装包并配置文件
2,Scala的运行

输入:quit即可退出Scala
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/m0_74038727/article/details/138244811















 2006
2006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









