






 本文探讨了Hadoop和Spark的大数据处理生态系统,包括Hadoop的核心组件、Spark的重要组件及其与MapReduce的区别,以及Linux操作系统的基本命令和结构化与非结构化数据的区分。此外,还介绍了数据库备份策略如冷备、热备和温备的概念。
本文探讨了Hadoop和Spark的大数据处理生态系统,包括Hadoop的核心组件、Spark的重要组件及其与MapReduce的区别,以及Linux操作系统的基本命令和结构化与非结构化数据的区分。此外,还介绍了数据库备份策略如冷备、热备和温备的概念。
一、介绍Hadoop生态圈配图加文字
Hadoop是目前应用最为广泛的分布式大数据处理框架,其具备可靠性、高效性、可伸缩性等特点。
Hadoop的核心组件是HDFS、MapReduce。随着处理的任务不同,各种组件的相继出现,有着丰富的Hadoop生态圈。
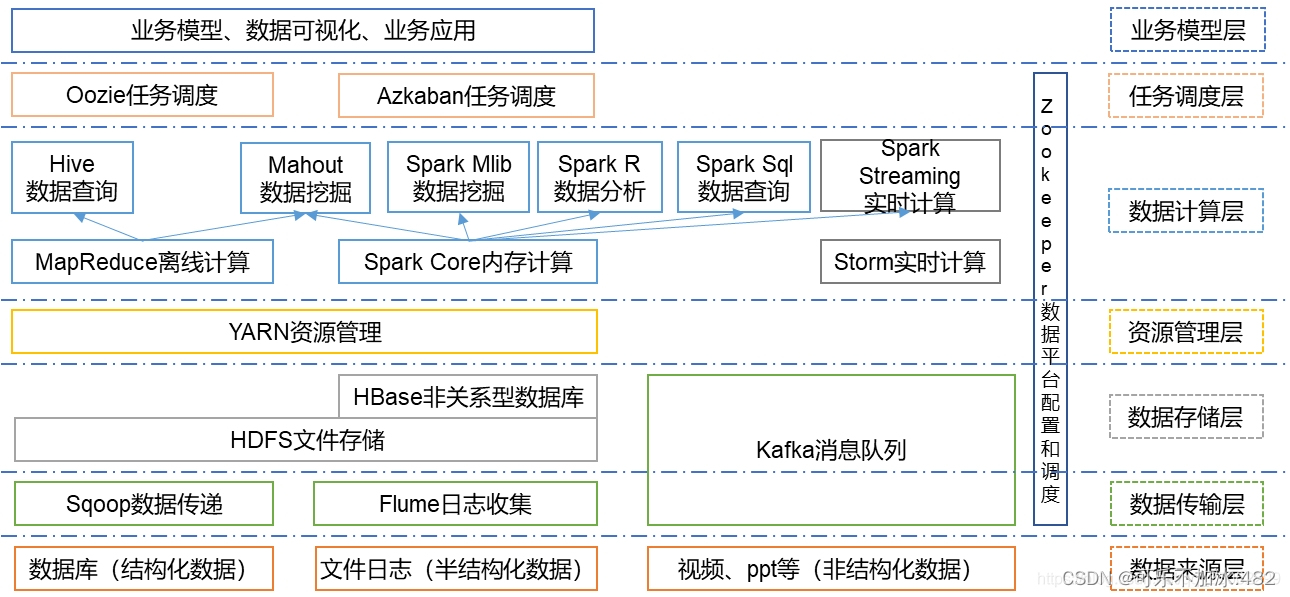 根据服务对象和层次分为:数据来源层、数据传输层、数据存储层、资源管理层、数据计算层、任务调度层、业务模型层
根据服务对象和层次分为:数据来源层、数据传输层、数据存储层、资源管理层、数据计算层、任务调度层、业务模型层
二、详细介绍spark的生态圈,特点
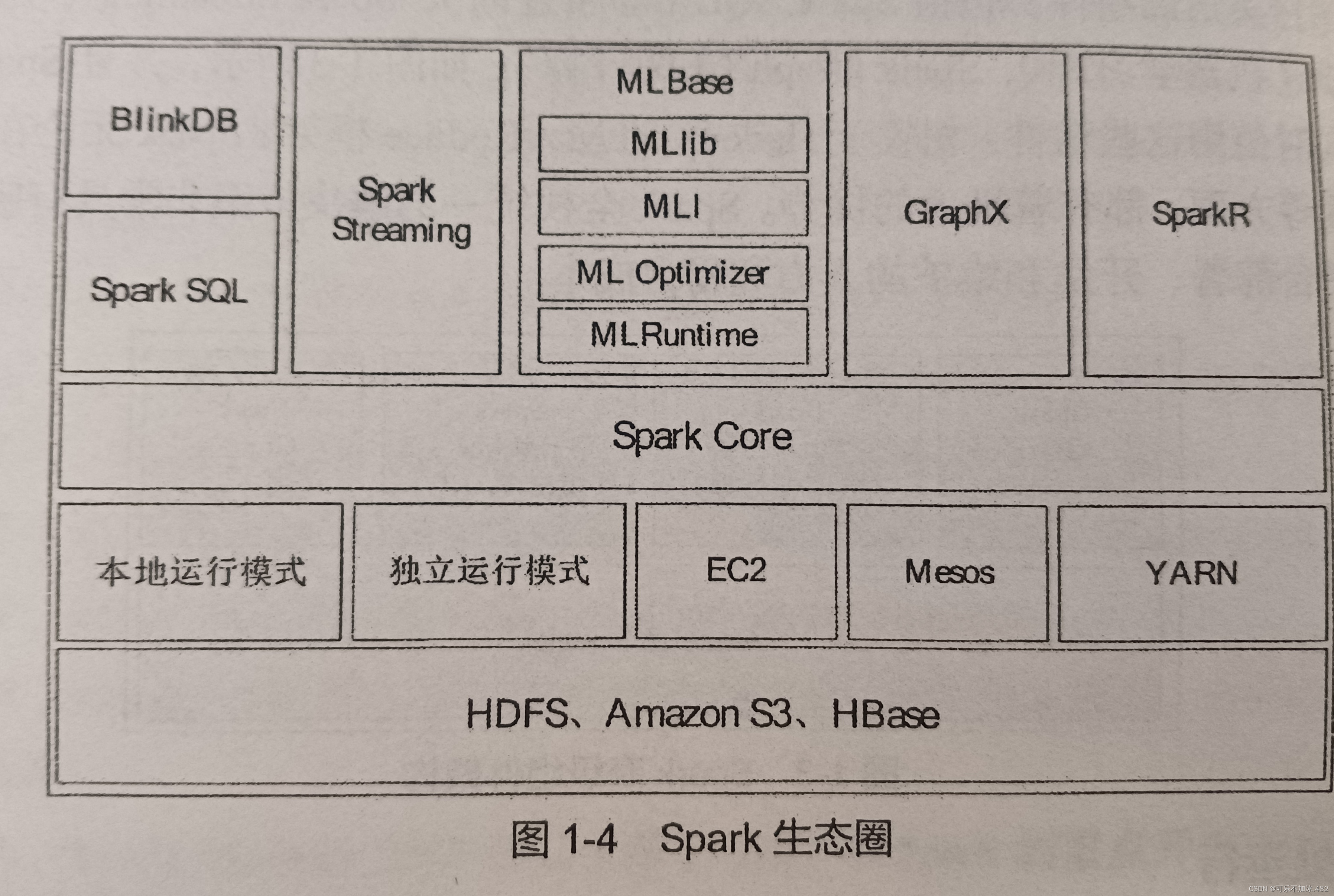
Spark生态圈中重要组件的简要介绍如下。
(1) Spark Core: Spark的核心,提供底层框架及核心支持。
(2) BlinkDB: -一个用于在海量数据上进行交互式SQL查询的大规模并行查询引擎,允许用户通过权衡数据精度缩短查询响应时间,数据的精度将被控制在允许的误差范围内。
(3 ) Spark SQL: 可以执行SQL查询,支持基本的SQL语法和HiveQL语法,可读取的数据源包括Hive、HDFS、关系数据库(如MySQL)等。
(4 ) Spark Streaming:可以进行实时数据流式计算。例如,一个网站的流量是每时每刻都有可能产生的,如果想要分析过去15分钟或1小时的流量,则可以使用Spark Streaming组件解决这个问题。
(5) MLBase: MLBase是Spark生态圈的一部分,专注于机器学习领域,学习门槛较低。因此,即使是一些可能并不了解机器学习的用户也可以方便地使用MLBase。MLBase由4部分组成: MLib MLI ML Opimier和MIRuntme
(6) GraphX:图计算的应用在很多情况下处理的数据量都是很庞大的。如果用户需要自行编写相关的图计算算法,并且在集群中应用,难度是非常大的。而使用GraphX 即可解决这个问题,因为它内置了许多与图相关的算法,如在移动社交关系分析中可使用图计算相关算法进行处理和分析。
(7) SparkR: SparkR 是AMPLab发布的一一个R语言开发包,使得R语言编写的程序不只可以在单机运行,也可以作为Spark 的作业运行在集群上,极大地提升了R语言的数据处理能力。
三、详细介绍mapreduce的运行框架并于spark做对比
spark和Mapreduce的简单介绍
MapReduce:MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
spark:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。
spark是借鉴了Mapreduce,并在其基础上发展起来的,继承了其分布式计算的优点并进行了改进,spark生态更为丰富,功能更为强大,性能更加适用范围广,mapreduce更简单,稳定性好。主要区别
(1)spark把运算的中间数据(shuffle阶段产生的数据)存放在内存,迭代计算效率更高,mapreduce的中间结果需要落地,保存到磁盘
(2)Spark容错性高,它通过弹性分布式数据集RDD来实现高效容错,RDD是一组分布式的存储在 节点内存中的只读性的数据集,这些集合石弹性的,某一部分丢失或者出错,可以通过整个数据集的计算流程的血缘关系来实现重建,mapreduce的容错只能重新计算
(3)Spark更通用,提供了transformation和action这两大类的多功能api,另外还有流式处理sparkstreaming模块、图计算等等,mapreduce只提供了map和reduce两种操作,流计算及其他的模块支持比较缺乏 。
(4)Spark框架和生态更为复杂,有RDD,血缘lineage、执行时的有向无环图DAG,stage划分等,很多时候spark作业都需要根据不同业务场景的需要进行调优以达到性能要求,mapreduce框架及其生态相对较为简单,对性能的要求也相对较弱,运行较为稳定,适合长期后台运行。
(5)Spark计算框架对内存的利用和运行的并行度比mapreduce高,Spark运行容器为executor,内部ThreadPool中线程运行一个Task,mapreduce在线程内部运行container,container容器分类为MapTask和ReduceTask.程序运行并行度高
(6)Spark对于executor的优化,在JVM虚拟机的基础上对内存弹性利用:storage memory与Execution memory的弹性扩容,使得内存利用效率更高。
四、Linux操作系统简单命令实训演习
1.ls 命令 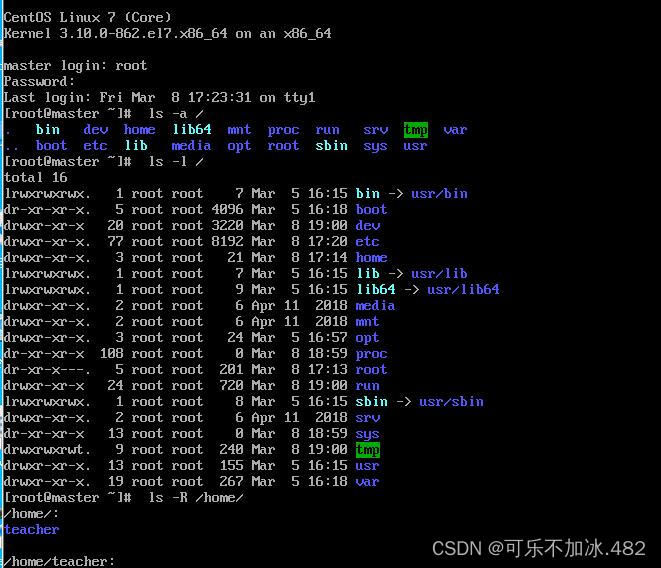 2.cd 命令
2.cd 命令 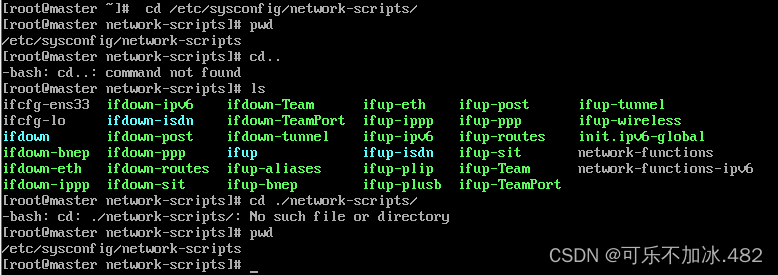 3.mkdir 命令
3.mkdir 命令  4.rm 命令
4.rm 命令  5.cp 命令
5.cp 命令 6.mv 命令
6.mv 命令 7.cat 命令
7.cat 命令 
8.tar 命令 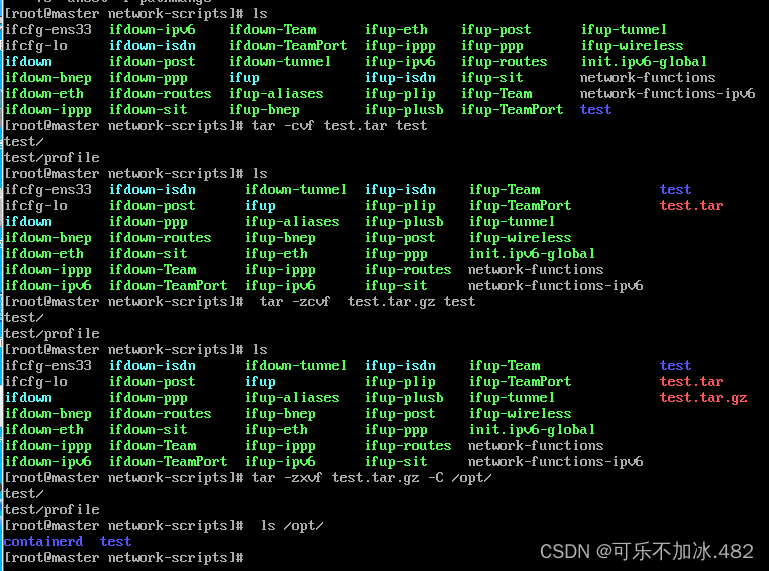
9.useradd 命令  10.passwd 命令
10.passwd 命令 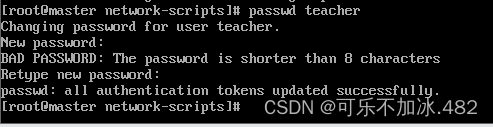 11.chown 命令
11.chown 命令 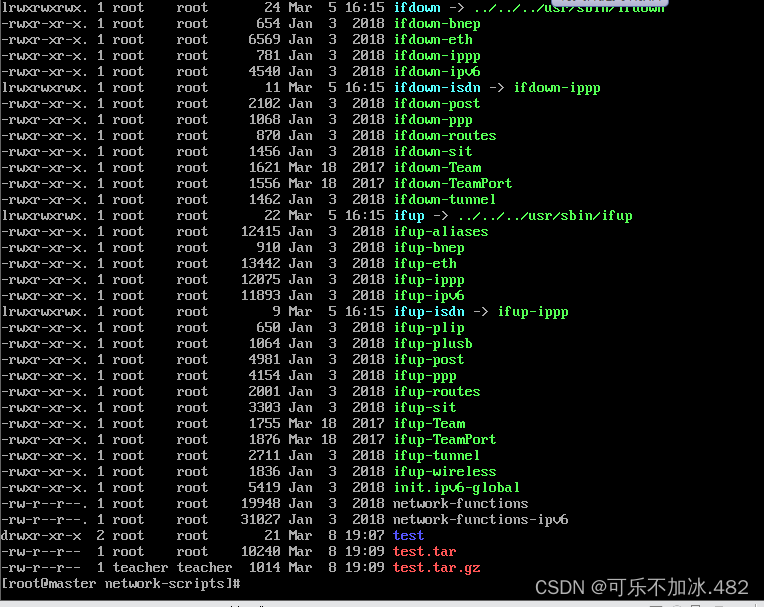 12.chmod 命令
12.chmod 命令 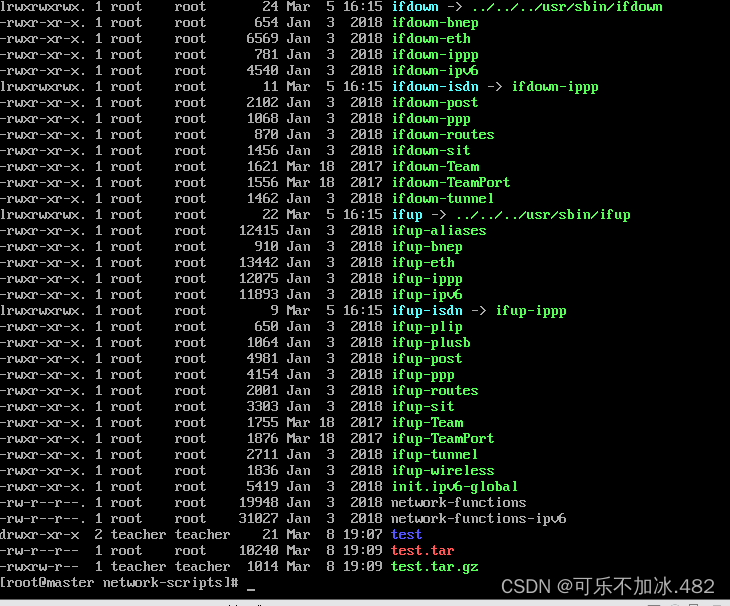
13.su 命令 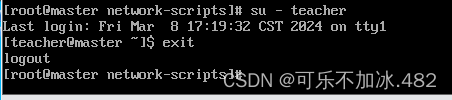
五、解释结构化数据和非结构化数据
结构化数据:指关系模型数据,即以关系数据库表形式管理的数据,结合到典型场景中更容易理解,比如企业ERP、OA、HR里的数据。
非结构化数据:指数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。如word、pdf、ppt及各种格式的图片、视频等。
六、解释冷备,热备和温备
热备:在数据库运行状态下进行备份,备份时不需要停止数据库的服务。但是,由于备份时需要访问数据库文件,因此备份过程中可能会影响数据库的正常运行。
冷备:在关闭数据库的情况下进行备份。这种备份方式不影响数据库的正常运行,但是需要停止数据库的服务。适用于小型数据量、备份频繁及服务器空闲时进行备份。
温备:同样是在数据库运行中进行的,但是会对当前数据库的操作有所影响,备份时 仅支持读操作,不支持写操作。















 319
319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









